Recognition: unknown
VitaLLM: A Versatile, Ultra-Compact Ternary LLM Accelerator with Dependency-Aware Scheduling
Pith reviewed 2026-05-07 09:00 UTC · model grok-4.3
The pith
VitaLLM shows that a co-designed accelerator overcomes ternary LLM bottlenecks on edge devices with dual-core processing and dependency-aware scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
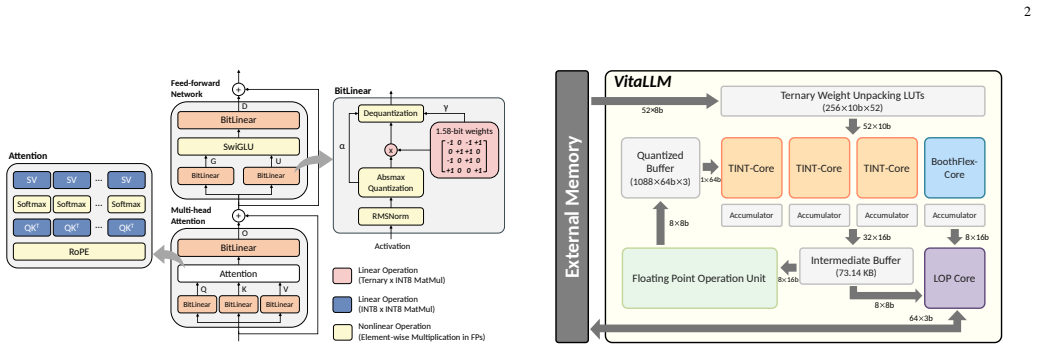
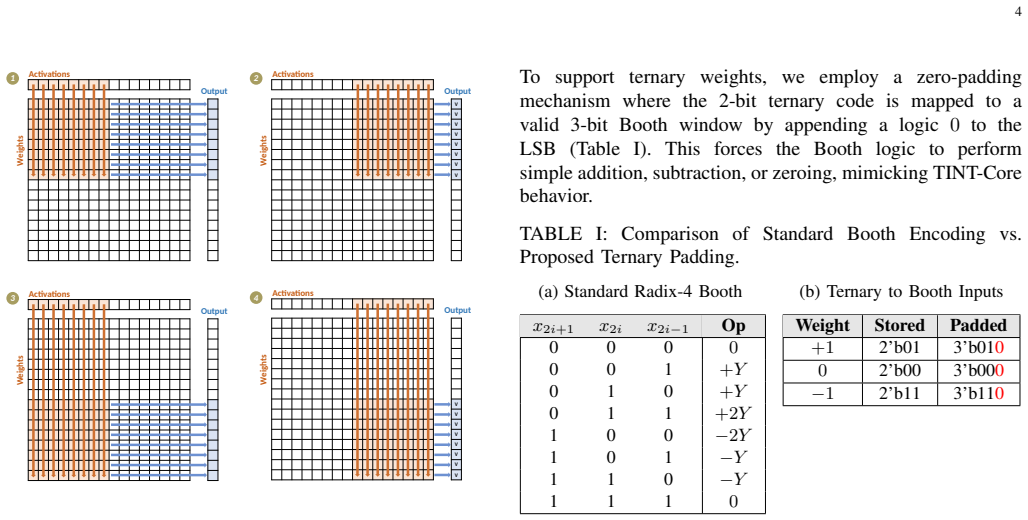
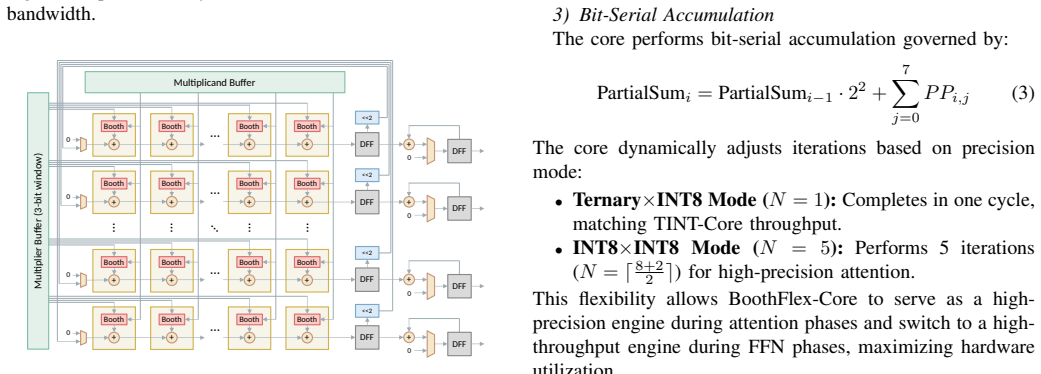
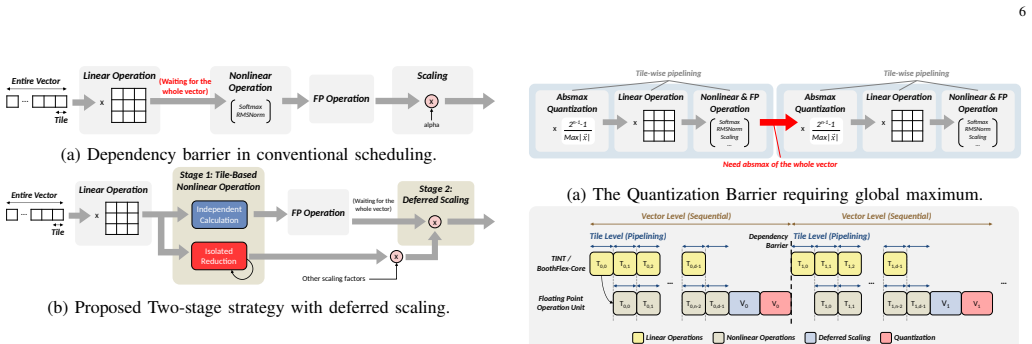
VitaLLM is a hardware-software co-designed accelerator for ternary LLMs that employs a heterogeneous Dual-Core Compute Strategy to assign ternary projections to TINT-Cores and mixed-precision attention to a BoothFlex-Core, together with Leading One Prediction to prune redundant KV cache fetches and Dependency-Aware Scheduling to hide nonlinear operation latency, delivering 70.70 tokens/s decode throughput in 0.223 mm² area at 65.97 mW power and 17.4 TOPS/mm²/W FOM when fabricated in TSMC 16nm, plus an optional bit-serial extension for precision flexibility.
What carries the argument
Heterogeneous Dual-Core Compute Strategy that routes ternary projections to dedicated cores and attention to a unified mixed-precision core, reinforced by Leading One Prediction for KV cache pruning and Dependency-Aware Scheduling to mask operation latencies.
If this is right
- High hardware utilization is maintained through both compute-bound prefill and bandwidth-bound decode phases.
- Memory bandwidth demands drop via selective KV cache pruning during attention.
- The architecture supports an extended bit-serial variant for precision-agile inference without major redesign.
- The resulting figure of merit exceeds that of prior accelerators in the same technology node.
Where Pith is reading between the lines
- Similar dependency-aware scheduling may reduce stalls in other memory-bound attention accelerators beyond ternary models.
- The pruning approach could generalize to cut traffic in any KV-cache-heavy decoder architecture.
- The dual-core split suggests a template for handling mixed compute and memory phases in future edge AI designs.
Load-bearing premise
The dual-core strategy and leading-one prediction will maintain high utilization and effective cache pruning across both prefill and decode phases without hidden overheads or undisclosed workload-specific tuning.
What would settle it
Silicon measurements from the TSMC 16nm implementation showing decode throughput below 70 tokens per second or power consumption above 66 mW on standard LLM benchmarks would disprove the efficiency claims.
Figures






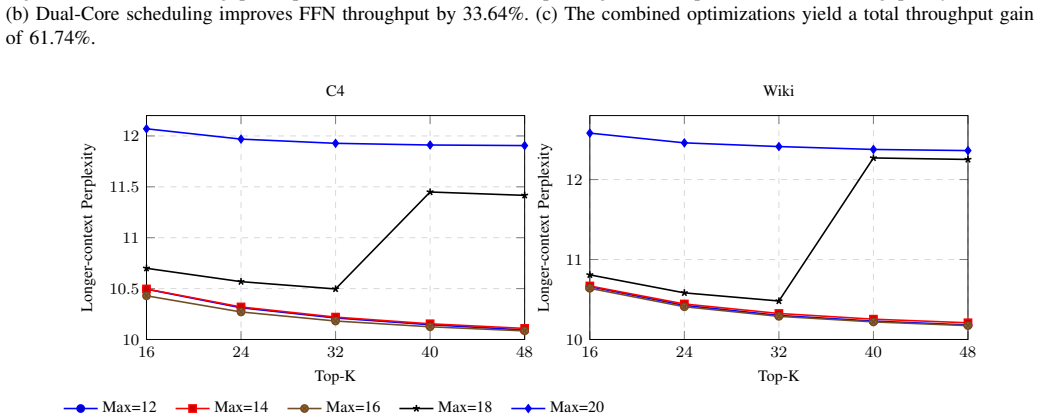
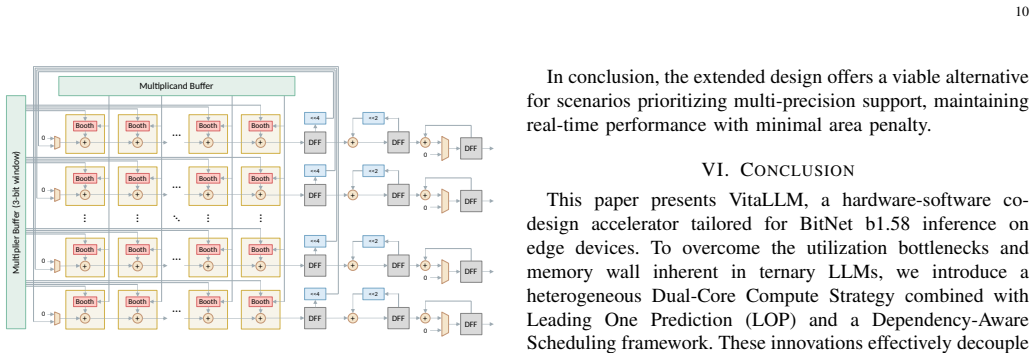
read the original abstract
Deploying Large Language Models (LLMs) on resource-constrained edge devices faces critical bottlenecks in memory bandwidth and power consumption. While ternary quantization (e.g., BitNet b1.58) significantly reduces model size, its direct deployment on general-purpose hardware is hindered by workload imbalance, bandwidth-bound decoding, and strict data dependencies. To address these challenges, we propose \textbf{VitaLLM}, a hardware-software co-designed accelerator tailored for efficient ternary LLM inference. We introduce a heterogeneous \textbf{Dual-Core Compute Strategy} that synergizes specialized TINT-Cores for massive ternary projections with a unified BoothFlex-Core for mixed-precision attention, ensuring high utilization across both compute-bound prefill and bandwidth-bound decode stages. Furthermore, we develop a \textbf{Leading One Prediction (LOP)} mechanism to prune redundant Key-Value (KV) cache fetches and a \textbf{Dependency-Aware Scheduling} framework to hide the latency of nonlinear operations. Implemented in TSMC 16nm technology, VitaLLM achieves a decoding throughput of 70.70 tokens/s within an ultra-compact area of 0.223 mm$^2$ and a power consumption of 65.97 mW. The design delivers a superior Figure of Merit (FOM) of 17.4 TOPS/mm$^2$/W, significantly outperforming state-of-the-art accelerators. Finally, we explore an extended bit-serial design (BoothFlex-BS) to demonstrate the architecture's adaptability for precision-agile inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VitaLLM, a hardware-software co-designed accelerator for ternary LLM inference on edge devices. It introduces a heterogeneous Dual-Core Compute Strategy combining TINT-Cores for ternary projections with a BoothFlex-Core for mixed-precision attention, a Leading One Prediction (LOP) mechanism to prune redundant KV cache accesses, and a Dependency-Aware Scheduling framework to hide nonlinear operation latencies. Post-layout results in TSMC 16nm report a decoding throughput of 70.70 tokens/s, area of 0.223 mm², power of 65.97 mW, and FOM of 17.4 TOPS/mm²/W, outperforming prior accelerators; an extended bit-serial BoothFlex-BS variant is also explored for precision-agile inference.
Significance. If the reported metrics are accurate, this constitutes a meaningful contribution to efficient edge deployment of quantized LLMs by directly tackling memory bandwidth and power bottlenecks through specialized heterogeneous cores, cache pruning, and latency-hiding scheduling. The ultra-compact area and competitive FOM could inform future designs for resource-constrained ternary models such as BitNet variants.
major comments (1)
- The central performance claims (throughput, area, power, and FOM superiority) rest on post-layout simulation results without reported error bars, sensitivity analysis, or explicit workload characterization; the Implementation Results section should include these to substantiate that the Dual-Core strategy and LOP deliver the claimed benefits without undisclosed overheads across prefill and decode phases.
minor comments (3)
- Clarify in the abstract and Implementation section whether results are post-layout simulation or post-silicon measurement, as 'implemented' terminology is ambiguous without fabrication details.
- The FOM definition and exact comparison methodology against SOTA accelerators (including workload, precision, and technology normalization) should be stated explicitly in the Evaluation section for reproducibility.
- Ensure all utilization and pruning-rate figures include complete axis labels, legends, and error indicators for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the major comment below and have revised the manuscript to provide the requested additional characterization.
read point-by-point responses
-
Referee: The central performance claims (throughput, area, power, and FOM superiority) rest on post-layout simulation results without reported error bars, sensitivity analysis, or explicit workload characterization; the Implementation Results section should include these to substantiate that the Dual-Core strategy and LOP deliver the claimed benefits without undisclosed overheads across prefill and decode phases.
Authors: We appreciate this observation. Post-layout simulations yield deterministic results for the reported area, power, and throughput under fixed conditions and workloads, which is standard practice for such hardware designs and does not involve stochastic measurement noise that would require error bars. Nevertheless, to strengthen the substantiation of our claims, the revised Implementation Results section now includes explicit workload characterization with separate breakdowns for prefill and decode phases. This details core utilization for the heterogeneous Dual-Core strategy, the KV cache access reductions achieved by LOP, and confirms no significant undisclosed overheads. We have also added sensitivity analysis across varying sequence lengths and model configurations to demonstrate consistent benefits of the proposed techniques. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reports hardware implementation results from TSMC 16nm post-layout simulation: decoding throughput of 70.70 tokens/s, area of 0.223 mm², power of 65.97 mW, and FOM of 17.4 TOPS/mm²/W. These are direct measurements/simulations of the proposed Dual-Core Compute Strategy, LOP pruning, and Dependency-Aware Scheduling, supported by explicit timing diagrams, utilization breakdowns, and architectural details. No equations, fitted parameters, or predictions reduce to inputs by construction. No self-citations serve as load-bearing justification for the performance claims; the FOM is computed from reported metrics and compared externally to SOTA. The derivation chain is self-contained engineering evidence without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (3)
-
TINT-Cores
no independent evidence
-
BoothFlex-Core
no independent evidence
-
Leading One Prediction (LOP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MobileLLM: Optimizing sub-billion parameter language models for on-device use cases,
Z. Liu, C. Zhao, Y . Xiong, E. Chang, F. Iandola, C. Lai, Y . Tian, I. Fedorov, Y . Shi, R. Krishnamoorthiet al., “MobileLLM: Optimizing sub-billion parameter language models for on-device use cases,” in Proceedings of the 41st International Conference on Machine Learning (ICML), Jul 2024
2024
-
[2]
S. Ma, H. Wang, L. Ma, L. Wang, W. Wang, S. Huang, L. Dong, R. Wang, J. Xue, and F. Wei, “The era of 1-bit LLMs: All large language models are in 1.58 bits,”arXiv preprint arXiv:2402.17764, Feb 2024
-
[3]
Bitnet b1.58 2b4t technical report,
S. Ma, H. Wang, S. Huang, X. Zhang, Y . Hu, T. Song, Y . Xia, and F. Wei, “BitNet b1.58 2B4T technical report,”arXiv preprint arXiv:2504.12285, Apr 2025
-
[4]
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs,
J. Wang, H. Zhou, T. Song, S. Mao, S. Ma, H. Wang, Y . Xia, and F. Wei, “1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs,”arXiv preprint arXiv:2410.16144, Oct 2024
-
[5]
A Survey on Hardware Accelerators for Large Language Models,
C. Kachris, “A Survey on Hardware Accelerators for Large Language Models,”arXiv preprint arXiv:2401.09890, Jan 2024
-
[6]
Slim-Llama: A 4.69mW large-language- model processor with binary/ternary weights for billion-parameter Llama model,
S. Kim, J. Lee, and H.-J. Yoo, “Slim-Llama: A 4.69mW large-language- model processor with binary/ternary weights for billion-parameter Llama model,” inIEEE International Solid-State Circuits Conference (ISSCC), Feb 2025, pp. 422–422
2025
-
[7]
TerEffic: Highly efficient ternary LLM inference on FPGA,
C. Yin, Z. Bai, P. Venkatram, S. Aggarval, Z. Li, and T. Mitra, “TerEffic: Highly efficient ternary LLM inference on FPGA,”arXiv preprint arXiv:2502.16473, May 2025
-
[8]
TeLLMe: An energy-efficient ternary LLM accelerator for prefill and decode on edge FPGAs,
Y . Qiao, Z. Chen, Y . Zhang, Y . Wang, and S. Huang, “TeLLMe: An energy-efficient ternary LLM accelerator for prefill and decode on edge FPGAs,”arXiv preprint arXiv:2504.16266, Apr 2025
-
[9]
Computing architecture for large language models (LLMs) and large multimodal models (LMMs),
B.-S. Liang, “Computing architecture for large language models (LLMs) and large multimodal models (LMMs),” inProceedings of the 2024 International Symposium on Physical Design (ISPD), 2024
2024
-
[10]
FACT: FFN-attention co-optimized transformer architecture with eager correlation prediction,
Y . Qin, Y . Wang, D. Deng, Z. Zhao, X. Yang, L. Liu, S. Wei, Y . Hu, and S. Yin, “FACT: FFN-attention co-optimized transformer architecture with eager correlation prediction,” inProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), Jun 2023, pp. 1–14
2023
-
[11]
SOFA: A compute-memory optimized sparsity accelerator via cross-stage coordinated tiling,
H. Wang, J. Fang, X. Tang, Z. Yue, J. Li, Y . Qin, S. Guan, Q. Yang, Y . Wang, C. Liet al., “SOFA: A compute-memory optimized sparsity accelerator via cross-stage coordinated tiling,”arXiv preprint arXiv:2407.10416, Jul 2024
-
[12]
k-degree parallel comparison-free hardware sorter for complete sorting,
S. S. Ray and S. Ghosh, “k-degree parallel comparison-free hardware sorter for complete sorting,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 42, no. 5, pp. 1438–1449, May 2023. 11
2023
-
[13]
Energon: Toward efficient acceleration of transformers using dynamic sparse attention,
Z. Zhou, J. Liu, Z. Gu, and G. Sun, “Energon: Toward efficient acceleration of transformers using dynamic sparse attention,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 42, no. 1, pp. 136–149, Jan 2023
2023
-
[14]
AttAcc! Unleashing the power of PIM for batched transformer- based generative model inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y . Kwon, N. S. Kim, and J. H. Ahn, “AttAcc! Unleashing the power of PIM for batched transformer- based generative model inference,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), vol. 2, Apr 2024, pp. 103–119
2024
-
[15]
FlashDecoding++: Faster large language model inference with asynchronization, flat GEMM optimization, and heuristics,
K. Hong, G. Dai, J. Xu, Q. Mao, X. Li, J. Liu, K. Chen, Y . Dong, and Y . Wang, “FlashDecoding++: Faster large language model inference with asynchronization, flat GEMM optimization, and heuristics,” in Proceedings of the 7th Conference on Machine Learning and Systems (MLSys), 2024
2024
-
[16]
Y . Qiao, Z. Chen, Y . Zhang, Y . Wang, and S. Huang, “TeLLMe v2: An efficient end-to-end ternary LLM prefill and decode accelerator with table-lookup matmul on edge FPGAs,”arXiv preprint arXiv:2510.15926, Oct 2025
-
[17]
Tenet: An efficient sparsity-aware lut-centric architecture for ternary llm inference on edge,
Z. Huang, R. Ma, S. Cao, R. Shu, I. Wang, T. Cao, C. Chen, and Y . Xiong, “Tenet: An efficient sparsity-aware lut-centric architecture for ternary llm inference on edge,”arXiv preprint arXiv:2509.13765, 2025
-
[18]
Tom: A ternary read-only memory accelerator for llm-powered edge intelligence,
H. Guan, Y . Zhang, W. Wang, Y . Gao, S. Cao, C. Zhang, and N. Xu, “Tom: A ternary read-only memory accelerator for llm-powered edge intelligence,”arXiv preprint arXiv:2602.20662, 2026
-
[19]
BitMoD: Bit-serial mixture-of-datatype LLM acceleration,
Y . Chen, A. F. AbouElhamayed, X. Dai, Y . Wang, M. Andronic, G. A. Constantinides, and M. S. Abdelfattah, “BitMoD: Bit-serial mixture-of-datatype LLM acceleration,” inProceedings of the 31st IEEE International Symposium on High-Performance Computer Architecture (HPCA), Mar 2025. Zi-Wei Linreceived the B.S. and M.S. degrees in electronic engineering from ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.