Recognition: unknown
Personalizing Cancer Models under Data Scarcity via Parameter Decomposition
Pith reviewed 2026-05-07 10:21 UTC · model grok-4.3
The pith
Splitting model parameters into a shared population part and a patient-specific part lets cancer models calibrate accurately even with very little individual data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a parameter decomposition framework improves personalization of dynamical cancer models under data scarcity. Selected parameters are split into a common component, shared across patients and estimated once from population-level data, and a personalized component that is updated for each patient using their limited measurements. The common component acts as a fixed prior that guides rapid calibration of the patient-specific part, leading to more reliable fits than calibrating all parameters independently when data is scarce, as shown on synthetic realizations of logistic growth models with optimized interventions.
What carries the argument
Parameter decomposition, which splits selected model parameters into a common population-level component estimated once and a patient-specific component updated per individual, to supply an informed prior for calibration.
If this is right
- Cancer models personalize reliably even when each new patient supplies only a few measurements.
- Medical digital twins can be updated continuously as longitudinal data arrive without full recalibration from scratch.
- The shared component reduces the data burden needed to reach usable patient-specific predictions.
- Calibration performance improves in limited-data regimes compared with treating every parameter as fully patient-specific.
Where Pith is reading between the lines
- The same split could be tried on other biological dynamical systems where population data is abundant but individual trajectories are short.
- Choosing which parameters to decompose may require either prior biological knowledge or an auxiliary selection step on the population data.
- Real clinical datasets would provide a stronger test than the synthetic logistic-growth cases used here.
Load-bearing premise
Estimating a common component once from population-level data will reliably provide an informed prior enabling rapid and accurate personalization for new patients with scarce data.
What would settle it
Measure the calibration error and forward prediction accuracy on held-out synthetic patients supplied with only one to five data points; the decomposition method should produce lower error than full-parameter calibration without the shared component.
Figures
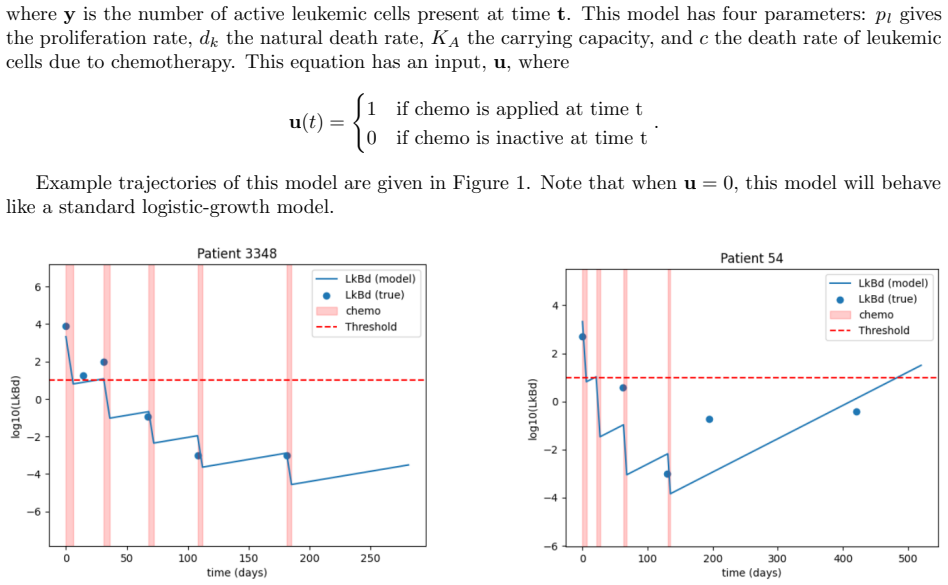


read the original abstract
Personalized cancer modeling for clinical applications requires robust and efficient parameter calibration, particularly in settings with limited patient data. This need is especially critical for medical digital twins (MDTs), which are virtual representations of disease continuously updated using longitudinal patient measurements. In this work, we propose a novel parameter personalization framework for dynamical cancer models under data scarcity. Our approach decomposes selected model parameters into a common component, shared across patients, and a personalized component, which is patient-specific and can be updated as new data become available. The common component captures population-level structure and is estimated once, providing an informed prior that enables rapid and accurate personalization. We demonstrate the effectiveness of this framework using synthetic data generated from canonical dynamical systems, such as logistic growth models with optimized treatment interventions. Our results show that parameter decomposition significantly improves calibration performance in limited-data regimes, facilitating fast and reliable personalization and supporting the development of patient-specific cancer models and MDTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a parameter decomposition framework for personalizing dynamical cancer models under data scarcity. Selected parameters are split into a common component (estimated once from population-level data to capture shared structure) and a patient-specific component (updated with new measurements). The common component is intended to serve as an informed prior enabling rapid and accurate calibration for new patients. Effectiveness is demonstrated on synthetic trajectories generated from logistic-growth models with optimized treatment interventions, with the claim that this yields significantly improved calibration in limited-data regimes and supports medical digital twins (MDTs).
Significance. If the central claim holds beyond the current evaluation, the framework could provide a practical route to patient-specific cancer models when longitudinal data are scarce, directly addressing a bottleneck in MDT development. The decomposition idea is conceptually clean and leverages population structure without requiring full re-estimation per patient. However, the narrow synthetic matched-data setting limits the assessed significance at present.
major comments (2)
- [Abstract / Results] Abstract and results: the assertion that 'parameter decomposition significantly improves calibration performance in limited-data regimes' is stated without any quantitative metrics (e.g., RMSE, calibration error, log-likelihood values), baseline comparisons, or statistical details. This absence leaves the central empirical claim unsupported by verifiable evidence.
- [Numerical Experiments / Discussion] Evaluation setup (synthetic data generation and experiments): all reported trajectories are generated from the identical logistic-growth dynamical system used for personalization. Under this matched condition the reported gain can occur by construction once the common component is fitted to the same family; the manuscript provides no experiments with inter-patient structural mismatch, differing noise models, or real clinical time-series. This directly tests the load-bearing assumption that the population-derived common component supplies a reliably informative prior for MDT use cases.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of empirical support and evaluation scope that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the assertion that 'parameter decomposition significantly improves calibration performance in limited-data regimes' is stated without any quantitative metrics (e.g., RMSE, calibration error, log-likelihood values), baseline comparisons, or statistical details. This absence leaves the central empirical claim unsupported by verifiable evidence.
Authors: We agree that the abstract and results presentation would be strengthened by explicit quantitative support. In the revised version we will update the abstract to include concrete metrics (e.g., RMSE reduction and log-likelihood improvement relative to non-decomposed baselines) drawn from the numerical experiments. We will also expand the results section with a dedicated table or figure panel that reports these values together with baseline comparisons and any statistical details already computed. revision: yes
-
Referee: [Numerical Experiments / Discussion] Evaluation setup (synthetic data generation and experiments): all reported trajectories are generated from the identical logistic-growth dynamical system used for personalization. Under this matched condition the reported gain can occur by construction once the common component is fitted to the same family; the manuscript provides no experiments with inter-patient structural mismatch, differing noise models, or real clinical time-series. This directly tests the load-bearing assumption that the population-derived common component supplies a reliably informative prior for MDT use cases.
Authors: We recognize that the matched synthetic setting limits the strength of the robustness claim. The current experiments were designed to isolate the benefit of decomposition under controlled conditions where the model family is known. In revision we will add an explicit limitations paragraph in the Discussion that acknowledges the matched-data assumption, discusses expected behavior under structural mismatch or altered noise, and states that real clinical time-series validation remains future work. We cannot, however, introduce new mismatched-model or real-data experiments within the scope of this manuscript. revision: partial
- Introduction of new experiments involving inter-patient structural mismatch or real clinical time-series data, which would require additional model families and patient datasets not available in the present study.
Circularity Check
No significant circularity; method and evaluation are self-contained
full rationale
The paper proposes a parameter decomposition into common and patient-specific components, estimates the common component once from population-level synthetic data, and uses it as a prior for personalizing new patients with scarce data. All demonstrations use independently generated synthetic trajectories from the same dynamical systems (e.g., logistic growth), but the reported calibration improvements do not reduce to the inputs by construction: the common-component fit is performed on a population subset, personalization occurs on held-out patient trajectories, and performance is measured against baselines without the decomposition. No equations, self-citations, or ansatzes are invoked that make the central claim equivalent to its own fitted quantities. The framework is therefore a standard empirical-Bayes-style regularization technique evaluated on matched synthetic data, with no load-bearing step that collapses to self-definition or forced prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamical systems such as logistic growth with treatment interventions accurately capture essential features of cancer progression for synthetic testing.
Reference graph
Works this paper leans on
-
[1]
Hoffmann, C
H. Hoffmann, C. Thiede, I. Glauche, M. Bornhaeuser, I. Roeder, Differential response to cytotoxic therapy explains treatment dynamics of acute myeloid leukaemia patients: insights from a mathematical modelling approach, Journal of the Royal Society Interface 17 (170) (2020) 20200091. 8
2020
-
[2]
B. P. Kovatchev, P. Colmegna, J. Pavan, J. L. Diaz Casta˜ neda, M. F. Villa-Tamayo, C. L. Koravi, G. Santini, C. Alix, M. Stumpf, S. A. Brown, Human-machine co-adaptation to automated insulin delivery: a randomised clinical trial using digital twin technology, npj Digital Medicine 8 (1) (2025) 253
2025
-
[3]
S. Wang, M. An, S. Lin, S. Kuy, D. Li, Artificial intelligence and digital twins: revolutionizing diabetes care for tomorrow (2025)
2025
-
[4]
K. Sel, D. Osman, F. Zare, S. Masoumi Shahrbabak, L. Brattain, J.-O. Hahn, O. T. Inan, R. Mukkamala, J. Palmer, D. Paydarfar, et al., Building digital twins for cardiovascular health: from principles to clinical impact, Journal of the American Heart Association 13 (19) (2024) e031981
2024
-
[5]
S. Qian, D. Ugurlu, E. Fairweather, L. D. Toso, Y. Deng, M. Strocchi, L. Cicci, R. E. Jones, H. Zaidi, S. Prasad, et al., Developing cardiac digital twin populations powered by machine learning provides electrophysiological insights in conduction and repolarization, Nature Cardiovascular Research 4 (5) (2025) 624–636
2025
-
[6]
P. M. Thangaraj, S. H. Benson, E. K. Oikonomou, F. W. Asselbergs, R. Khera, Cardiovascular care with digital twin technology in the era of generative artificial intelligence, European Heart Journal 45 (45) (2024) 4808–4821
2024
-
[7]
Kingma, J
D. Kingma, J. Ba, Adam: A method for stochastic optimization, in: International Conference for Learn- ing Representations, ICLR, 2015. 9
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.