Recognition: unknown
Sparse-View 3D Gaussian Splatting in the Wild
Pith reviewed 2026-05-07 08:55 UTC · model grok-4.3
The pith
A new method for 3D Gaussian splatting enables high-quality novel view synthesis from sparse unconstrained images containing distractors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
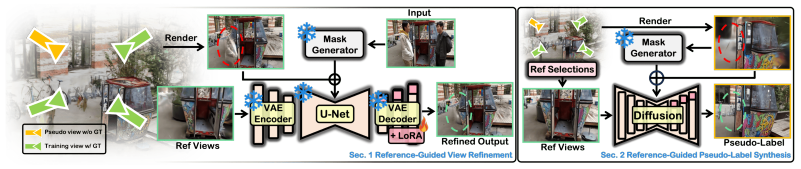
The authors claim that by applying reference-guided view refinement with a diffusion model that incorporates a transient mask and a reference image, and by using pseudo-view generation together with sparsity-aware Gaussian replication, their approach can effectively process sparse unconstrained image collections and deliver superior 3D rendering results compared to previous techniques.
What carries the argument
Reference-guided diffusion refinement using transient masks and reference images for artifact mitigation, combined with pseudo-view generation and sparsity-aware replication to densify the Gaussian field.
If this is right
- Outperforms prior methods with improvements of 17.2% in PSNR, 10.8% in SSIM, and 4.0% in LPIPS on public datasets.
- Achieves high-fidelity 3D rendering in unconstrained scenarios with distractors.
- Reduces reliance on labor-intensive dense image acquisition for real-world 3D modeling.
- Handles sparse image sets more effectively than existing Gaussian splatting approaches.
Where Pith is reading between the lines
- Applying this to video sequences could allow 3D reconstruction of scenes with moving people or vehicles by treating motion as transients.
- The replication strategy might be adapted to other 3D representation methods like neural radiance fields for similar sparsity issues.
- Future work could test the method on even sparser inputs, such as 3-5 images, to determine the minimum viable number for good results.
Load-bearing premise
The method assumes that reliable transient masks and reference images can be obtained or generated to guide the diffusion model without introducing additional artifacts, and that pseudo-view generation accurately identifies and fills sparse Gaussian regions without distorting the underlying geometry.
What would settle it
If experiments on a dataset with known ground-truth geometry show that incorrect transient masks lead to lower performance metrics or visible distortions compared to baselines, that would indicate the claim does not hold.
Figures









read the original abstract
We propose a 3D novel sparse-view synthesis framework for unconstrained real-world scenarios that contain distractors. Unlike existing methods that primarily perform novel-view synthesis from a sparse set of constrained images without transient elements or leverage unconstrained dense image collections to enhance 3D representation in real-world scenarios, our method not only effectively tackles sparse unconstrained image collections, but also shows high-quality 3D rendering results. To do this, we introduce reference-guided view refinement with a diffusion model using a transient mask and a reference image to enhance the 3D representation and mitigate artifacts in rendered views. Furthermore, we address sparse regions in the Gaussian field via pseudo-view generation along with a sparsity-aware Gaussian replication strategy to amplify Gaussians in the sparse regions. Extensive experiments on publicly available datasets demonstrate that our methodology consistently outperforms existing methods (e.g., PSNR - 17.2%, SSIM - 10.8%, LPIPS - 4.0%) and provides high-fidelity 3D rendering results. This advancement paves the way for realizing unconstrained real-world scenarios without labor-intensive data acquisition. Our project page is available at $\href{https://robotic-vision-lab.github.io/SaveWildGS/}{here}$
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sparse-view 3D Gaussian Splatting framework for unconstrained real-world scenes with distractors. It introduces reference-guided view refinement via a diffusion model conditioned on transient masks and reference images to mitigate artifacts, combined with pseudo-view generation and sparsity-aware Gaussian replication to handle sparse regions in the Gaussian field. Experiments on public datasets are claimed to show consistent outperformance over prior methods, with example gains of 17.2% PSNR, 10.8% SSIM, and 4.0% LPIPS.
Significance. If the results hold under rigorous validation, the work would meaningfully extend 3D Gaussian Splatting to practical, sparse, unconstrained captures, lowering barriers to high-fidelity novel-view synthesis in robotics, AR, and wild-environment modeling without requiring dense clean data.
major comments (4)
- [Abstract] Abstract: The stated quantitative gains (PSNR +17.2%, SSIM +10.8%, LPIPS +4.0%) are presented without naming the datasets, exact baseline methods, input view counts, or absolute metric values, preventing assessment of whether the improvements are load-bearing or reproducible.
- [Method (reference-guided refinement)] Reference-guided view refinement section: No quantitative evaluation (e.g., mask IoU, precision-recall, or failure-case analysis) is supplied for transient mask accuracy or reference-image quality on the target unconstrained datasets; mask errors would allow diffusion to preserve distractors or hallucinate, directly undermining the claimed rendering gains.
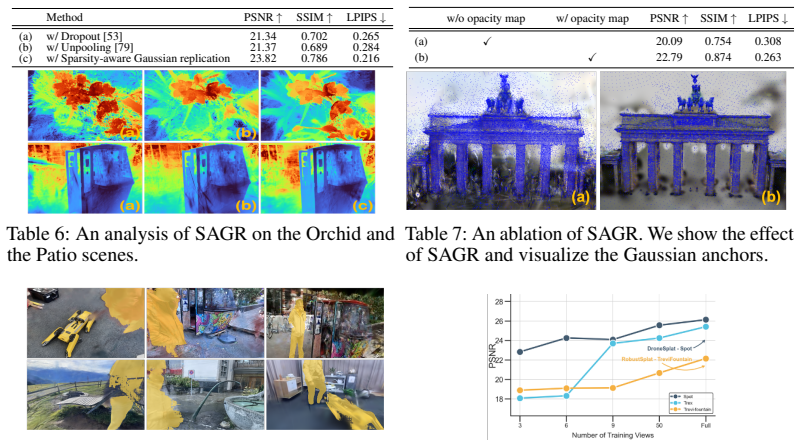
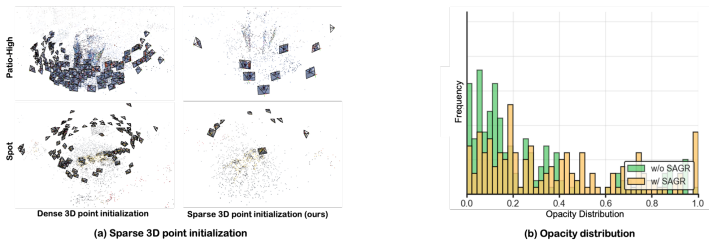
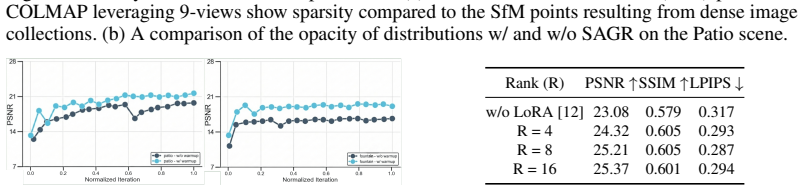
- [Method (sparsity-aware replication)] Sparsity-aware replication subsection: The pseudo-view generation and Gaussian replication strategy lacks an ablation or geometry-error metric (e.g., depth consistency or point-cloud alignment) showing that replication fills sparse regions without distorting scene geometry; this is a core assumption for the sparse-region handling claim.
- [Experiments] Experiments section: No error analysis, variance across runs, or per-scene breakdown is reported despite the reader's note on missing experimental details, making it impossible to verify that the pipeline supports the central claim under realistic distractor conditions.
minor comments (3)
- [Abstract] Abstract: The notation 'PSNR - 17.2%' is ambiguous (dash likely intends improvement); clarify as relative gains with absolute baseline values.
- [Figures] Figure captions: Transient-mask and pseudo-view visualizations would benefit from explicit labels indicating success/failure cases to aid reader interpretation.
- [Related Work] Related work: Add explicit comparison to recent diffusion-based novel-view methods and unconstrained Gaussian Splatting variants to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each major comment point-by-point below. Where the concerns identify gaps in the current version, we commit to revisions that strengthen the paper without misrepresenting the existing results or experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The stated quantitative gains (PSNR +17.2%, SSIM +10.8%, LPIPS +4.0%) are presented without naming the datasets, exact baseline methods, input view counts, or absolute metric values, preventing assessment of whether the improvements are load-bearing or reproducible.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will explicitly name the evaluation datasets, the baseline methods, the input view counts used for each experiment, and report both absolute metric values and the relative gains so that readers can directly assess the magnitude and reproducibility of the improvements. revision: yes
-
Referee: [Method (reference-guided refinement)] Reference-guided view refinement section: No quantitative evaluation (e.g., mask IoU, precision-recall, or failure-case analysis) is supplied for transient mask accuracy or reference-image quality on the target unconstrained datasets; mask errors would allow diffusion to preserve distractors or hallucinate, directly undermining the claimed rendering gains.
Authors: We acknowledge that the current manuscript does not include quantitative metrics such as mask IoU or precision-recall for the transient masks. Ground-truth transient masks are unavailable for the real-world unconstrained datasets, which precludes standard IoU computation. We will add a dedicated failure-case analysis subsection with qualitative examples of mask and reference-image quality, together with visual inspection of how mask errors propagate (or do not) into final renderings, to provide stronger supporting evidence for the refinement module. revision: partial
-
Referee: [Method (sparsity-aware replication)] Sparsity-aware replication subsection: The pseudo-view generation and Gaussian replication strategy lacks an ablation or geometry-error metric (e.g., depth consistency or point-cloud alignment) showing that replication fills sparse regions without distorting scene geometry; this is a core assumption for the sparse-region handling claim.
Authors: We agree that an explicit ablation and geometry-preservation metric would strengthen the sparsity-aware replication claim. In the revision we will include an ablation study isolating the replication component and report geometry-related metrics (depth consistency on rendered views and alignment error against the original point cloud) to demonstrate that replication improves coverage without introducing geometric distortion. revision: yes
-
Referee: [Experiments] Experiments section: No error analysis, variance across runs, or per-scene breakdown is reported despite the reader's note on missing experimental details, making it impossible to verify that the pipeline supports the central claim under realistic distractor conditions.
Authors: We will expand the experiments section to provide per-scene quantitative breakdowns for all reported metrics. Because each training run is computationally expensive, we performed single runs per scene; we will explicitly note this limitation and report any observed run-to-run variance on a representative subset of scenes where multiple seeds were feasible. These additions will allow readers to assess consistency under realistic distractor conditions. revision: yes
Circularity Check
Empirical pipeline with independent algorithmic components; no circular derivations
full rationale
The paper introduces a practical framework for sparse-view 3D Gaussian splatting in unconstrained scenes, relying on reference-guided diffusion refinement (using transient masks and reference images) plus pseudo-view generation with sparsity-aware replication. These are presented as new algorithmic steps evaluated through experiments on public datasets, with performance gains reported via direct comparisons (PSNR/SSIM/LPIPS). No equations, derivations, or uniqueness claims reduce by construction to fitted inputs, self-referential definitions, or load-bearing self-citations; the central claims remain externally falsifiable via the reported metrics and do not loop back to the method's own parameters.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transient masks and reference images can be obtained or generated to guide diffusion refinement without new artifacts
- domain assumption Pseudo-view generation plus sparsity-aware replication accurately fills under-sampled regions of the Gaussian field
Reference graph
Works this paper leans on
-
[1]
Atp: Adaptive threshold pruning for efficient data encoding in quantum neural networks
Mohamed Afane, Gabrielle Ebbrecht, Ying Wang, Juntao Chen, and Junaid Farooq. Atp: Adaptive threshold pruning for efficient data encoding in quantum neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20427–20436, 2025
2025
-
[2]
Distractor-free generalizable 3d gaussian splatting.arXiv preprint arXiv:2411.17605, 2024
Yanqi Bao, Jing Liao, Jing Huo, and Yang Gao. Distractor-free generalizable 3d gaussian splatting.arXiv preprint arXiv:2411.17605, 2024
-
[3]
Nerf-hugs: Improved neural radi- ance fields in non-static scenes using heuristics-guided segmentation
Jiahao Chen, Yipeng Qin, Lingjie Liu, Jiangbo Lu, and Guanbin Li. Nerf-hugs: Improved neural radi- ance fields in non-static scenes using heuristics-guided segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19436–19446, 2024
2024
-
[4]
Hallucinated neural radiance fields in the wild
Xingyu Chen, Qi Zhang, Xiaoyu Li, Yue Chen, Ying Feng, Xuan Wang, and Jue Wang. Hallucinated neural radiance fields in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12943–12952, 2022
2022
-
[5]
Hac: Hash-grid assisted context for 3d gaussian splatting compression
Yihang Chen, Qianyi Wu, Weiyao Lin, Mehrtash Harandi, and Jianfei Cai. Hac: Hash-grid assisted context for 3d gaussian splatting compression. InProceedings of the European Conference on Computer Vision, pages 422–438. Springer, 2024
2024
-
[6]
Hac++: Towards 100x compression of 3d gaussian splatting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yihang Chen, Qianyi Wu, Weiyao Lin, Mehrtash Harandi, and Jianfei Cai. Hac++: Towards 100x compression of 3d gaussian splatting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[7]
Yuxin Cheng, Binxiao Huang, Taiqiang Wu, Wenyong Zhou, Chenchen Ding, Zhengwu Liu, Graziano Chesi, and Ngai Wong. Perspective-aware 3d gaussian inpainting with multi-view consistency.arXiv preprint arXiv:2510.10993, 2025
-
[8]
Depth-regularized optimization for 3d gaussian splatting in few-shot images
Jaeyoung Chung, Jeongtaek Oh, and Kyoung Mu Lee. Depth-regularized optimization for 3d gaussian splatting in few-shot images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 811–820, 2024
2024
-
[9]
Eap-gs: Efficient augmentation of pointcloud for 3d gaussian splatting in few-shot scene reconstruction
Dongrui Dai and Yuxiang Xing. Eap-gs: Efficient augmentation of pointcloud for 3d gaussian splatting in few-shot scene reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16498–16507, 2025
2025
-
[10]
Chuanyu Fu, Yuqi Zhang, Kunbin Yao, Guanying Chen, Yuan Xiong, Chuan Huang, Shuguang Cui, and Xiaochun Cao. Robustsplat: Decoupling densification and dynamics for transient-free 3dgs.arXiv preprint arXiv:2506.02751, 2025
-
[11]
Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting
Wanshui Gan, Fang Liu, Hongbin Xu, Ningkai Mo, and Naoto Yokoya. Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 28980–28990, 2025
2025
-
[12]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InProceedings of the International Conference on Learning Representations, 2022
2022
-
[13]
No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse views
Ranran Huang and Krystian Mikolajczyk. No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse views. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27947–27957, 2025
2025
-
[14]
Enerverse: Envisioning embodied future space for robotics manipulation
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Yue Liao, Zhengkai Jiang, Yue Hu, Peng Gao, Hongsheng Li, Maoqing Yao, and Guanghui Ren. Enerverse: Envisioning embodied future space for robotics manipulation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[15]
Gaussiannexus: Room- scale real-time ar/vr telepresence with gaussian splatting
Xincheng Huang, Dieter Frehlich, Ziyi Xia, Peyman Gholami, and Robert Xiao. Gaussiannexus: Room- scale real-time ar/vr telepresence with gaussian splatting. InProceedings of the ACM Symposium on User Interface Software and Technology, pages 1–18, 2025
2025
-
[16]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):139–1, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):139–1, 2023
2023
-
[17]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[18]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4026, 2023. 10
2023
-
[19]
Generative sparse-view gaussian splatting
Hanyang Kong, Xingyi Yang, and Xinchao Wang. Generative sparse-view gaussian splatting. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26745–26755, 2025
2025
-
[20]
Wildgaussians: 3d gaussian splatting in the wild.arXiv preprint arXiv:2407.08447, 2024
Jonas Kulhanek, Songyou Peng, Zuzana Kukelova, Marc Pollefeys, and Torsten Sattler. Wildgaussians: 3d gaussian splatting in the wild.arXiv preprint arXiv:2407.08447, 2024
-
[21]
Compact 3d gaussian representation for radiance field
Joo Chan Lee, Daniel Rho, Xiangyu Sun, Jong Hwan Ko, and Eunbyung Park. Compact 3d gaussian representation for radiance field. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21719–21728, 2024
2024
-
[22]
Ms-gs: Multi-appearance sparse-view 3d gaussian splatting in the wild
Deming Li, Kaiwen Jiang, Yutao Tang, Ravi Ramamoorthi, Rama Chellappa, and Cheng Peng. Ms-gs: Multi-appearance sparse-view 3d gaussian splatting in the wild. InProceedings of the Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normalization
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, and Lin Gu. Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20775–20785, 2024
2024
-
[24]
Nerf-ms: Neural radiance fields with multi-sequence
Peihao Li, Shaohui Wang, Chen Yang, Bingbing Liu, Weichao Qiu, and Haoqian Wang. Nerf-ms: Neural radiance fields with multi-sequence. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18591–18600, 2023
2023
-
[25]
Yiqing Li, Xuan Wang, Jiawei Wu, Yikun Ma, and Zhi Jin. Sparsegs-w: Sparse-view 3d gaussian splatting in the wild with generative priors.arXiv preprint arXiv:2503.19452, 2025
-
[26]
Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, and Karsten Kreis. Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8576–8588, 2024
2024
-
[27]
3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors. InProceedings of the Advances in Neural Information Processing Systems, volume 37, pages 133305–133327, 2024
2024
-
[28]
Zhening Liu, Rui Song, Yushi Huang, Yingdong Hu, Xinjie Zhang, Jiawei Shao, Zehong Lin, and Jun Zhang. Feed-forward 3d gaussian splatting compression with long-context modeling.arXiv preprint arXiv:2512.00877, 2025
-
[29]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024
2024
-
[30]
Nerf in the wild: Neural radiance fields for unconstrained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7210–7219, 2021
2021
-
[31]
Local light field fusion: Practical view synthesis with prescriptive sampling guidelines.ACM Transactions on Graphics, 38(4):1–14, 2019
Ben Mildenhall, Pratul P Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines.ACM Transactions on Graphics, 38(4):1–14, 2019
2019
-
[32]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[33]
Compressed 3d gaussian splatting for accelerated novel view synthesis
Simon Niedermayr, Josef Stumpfegger, and Rüdiger Westermann. Compressed 3d gaussian splatting for accelerated novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10349–10358, 2024
2024
-
[34]
Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs
Michael Niemeyer, Jonathan T Barron, Ben Mildenhall, Mehdi SM Sajjadi, Andreas Geiger, and Noha Radwan. Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5470–5480, 2021
2021
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
Avinash Paliwal, Xilong Zhou, Wei Ye, Jinhui Xiong, Rakesh Ranjan, and Nima Khademi Kalantari. Ri3d: Few-shot gaussian splatting with repair and inpainting diffusion priors.arXiv preprint arXiv:2503.10860, 2025. 11
-
[37]
Dropgaussian: Structural regularization for sparse-view gaus- sian splatting
Hyunwoo Park, Gun Ryu, and Wonjun Kim. Dropgaussian: Structural regularization for sparse-view gaus- sian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21600–21609, 2025
2025
-
[38]
Wongi Park, Myeongseok Nam, Siwon Kim, Sangwoo Jo, and Soomok Lee. Forestsplats: Deformable transient field for gaussian splatting in the wild.arXiv preprint arXiv:2503.06179, 2025
-
[39]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review arXiv 2022
-
[40]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12179–12188, 2021
2021
-
[41]
L4gm: Large 4d gaussian reconstruction model
Jiawei Ren, Cheng Xie, Ashkan Mirzaei, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, Huan Ling, et al. L4gm: Large 4d gaussian reconstruction model. InProceedings of the Advances in Neural Information Processing Systems, volume 37, pages 56828–56858, 2024
2024
-
[42]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review arXiv 2024
-
[43]
Nerf on-the-go: Exploiting uncertainty for distractor-free nerfs in the wild
Weining Ren, Zihan Zhu, Boyang Sun, Jiaqi Chen, Marc Pollefeys, and Songyou Peng. Nerf on-the-go: Exploiting uncertainty for distractor-free nerfs in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8931–8940, 2024
2024
-
[44]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6121–6132, 2025
2025
-
[45]
Spotlesssplats: Ignoring distractors in 3d gaussian splatting.arXiv preprint arXiv:2406.20055, 2024
Sara Sabour, Lily Goli, George Kopanas, Mark Matthews, Dmitry Lagun, Leonidas Guibas, Alec Jacobson, David J Fleet, and Andrea Tagliasacchi. Spotlesssplats: Ignoring distractors in 3d gaussian splatting.arXiv preprint arXiv:2406.20055, 2024
-
[46]
Zeronvs: Zero-shot 360-degree view synthesis from a single image
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, et al. Zeronvs: Zero-shot 360-degree view synthesis from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9420–9429, 2024
2024
-
[47]
Structure-from-motion revisited
Johannes L Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4104–4113, 2016
2016
-
[48]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InProceedings of the European Conference on Computer Vision, pages 501–518. Springer, 2016
2016
-
[49]
Gaussianshopvr: Facilitating immersive 3d authoring using gaussian splatting in vr
Yulin Shen, Boyu Li, Jiayang Huang, David Yip, and Zeyu Wang. Gaussianshopvr: Facilitating immersive 3d authoring using gaussian splatting in vr. InProceedings of the ACM Symposium on User Interface Software and Technology, pages 1–14, 2025
2025
-
[50]
arXiv preprint arXiv:2310.15110 , year=
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: A single image to consistent multi-view diffusion base model.arXiv preprint arXiv:2310.15110, 2023
-
[51]
Photo tourism: Exploring photo collections in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: Exploring photo collections in 3d. In Proceedings of the ACM SIGGRAPH Papers, pages 835–846. ACM, 2006
2006
-
[52]
Simplenerf: Regularizing sparse input neural radiance fields with simpler solutions
Nagabhushan Somraj, Adithyan Karanayil, and Rajiv Soundararajan. Simplenerf: Regularizing sparse input neural radiance fields with simpler solutions. InProceedings of the SIGGRAPH Asia Conference, pages 1–11, 2023
2023
-
[53]
Dronesplat: 3d gaussian splatting for robust 3d reconstruction from in-the-wild drone imagery
Jiadong Tang, Yu Gao, Dianyi Yang, Liqi Yan, Yufeng Yue, and Yi Yang. Dronesplat: 3d gaussian splatting for robust 3d reconstruction from in-the-wild drone imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 833–843, 2025
2025
-
[54]
Emergent correspondence from image diffusion
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion. InProceedings of the Advances in Neural Information Processing Systems, volume 36, pages 1363–1389, 2023. 12
2023
-
[55]
Nexussplats: Efficient 3d gaussian splatting in the wild.arXiv preprint arXiv:2411.14514, 2024
Yuzhou Tang, Dejun Xu, Yongjie Hou, Zhenzhong Wang, and Min Jiang. Nexussplats: Efficient 3d gaussian splatting in the wild.arXiv preprint arXiv:2411.14514, 2024
-
[56]
Vrsplat: Fast and robust gaussian splatting for virtual reality.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 8(1):1–22, 2025
Xuechang Tu, Lukas Radl, Michael Steiner, Markus Steinberger, Bernhard Kerbl, and Fernando de la Torre. Vrsplat: Fast and robust gaussian splatting for virtual reality.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 8(1):1–22, 2025
2025
-
[57]
Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[58]
Xiaobao Wei, Zhangjie Ye, Yuxiang Gu, Zunjie Zhu, Yunfei Guo, Yingying Shen, Shan Zhao, Ming Lu, Haiyang Sun, Bing Wang, et al. Parkgaussian: Surround-view 3d gaussian splatting for autonomous parking.arXiv preprint arXiv:2601.01386, 2026
-
[59]
Difix3d+: Improving 3d reconstructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26024–26035, 2025
2025
-
[60]
Bg-triangle: Bézier gaussian triangle for 3d vectorization and rendering
Minye Wu, Haizhao Dai, Kaixin Yao, Tinne Tuytelaars, and Jingyi Yu. Bg-triangle: Bézier gaussian triangle for 3d vectorization and rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16197–16207, 2025
2025
-
[61]
Reconfusion: 3d reconstruction with diffusion priors
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al. Reconfusion: 3d reconstruction with diffusion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21551– 21561, 2024
2024
-
[62]
Diffusionerf: Regularizing neural radiance fields with denoising diffusion models
Jamie Wynn and Daniyar Turmukhambetov. Diffusionerf: Regularizing neural radiance fields with denoising diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4180–4189, 2023
2023
-
[63]
SparseGS: Real-time 360 ◦ sparse view synthesis using gaussian splat- ting,
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, and Achuta Kadambi. Sparsegs: Real-time 360 {\deg} sparse view synthesis using gaussian splatting.arXiv preprint arXiv:2312.00206, 2023
-
[64]
Jiacong Xu, Yiqun Mei, and Vishal M Patel. Wild-gs: Real-time novel view synthesis from unconstrained photo collections.arXiv preprint arXiv:2406.10373, 2024
-
[65]
Ad-gs: Object-aware b-spline gaussian splatting for self-supervised autonomous driving
Jiawei Xu, Kai Deng, Zexin Fan, Shenlong Wang, Jin Xie, and Jian Yang. Ad-gs: Object-aware b-spline gaussian splatting for self-supervised autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24770–24779, 2025
2025
-
[66]
Freenerf: Improving few-shot neural rendering with free frequency regularization
Jiawei Yang, Marco Pavone, and Yue Wang. Freenerf: Improving few-shot neural rendering with free frequency regularization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8254–8263, 2023
2023
-
[67]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371–10381, 2024
2024
-
[68]
Cross-ray neural radiance fields for novel-view synthesis from unconstrained image collections
Yifan Yang, Shuhai Zhang, Zixiong Huang, Yubing Zhang, and Mingkui Tan. Cross-ray neural radiance fields for novel-view synthesis from unconstrained image collections. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15901–15911, 2023
2023
-
[69]
Fewviewgs: Gaussian splatting with few view matching and multi-stage training
Ruihong Yin, Vladimir Yugay, Yue Li, Sezer Karaoglu, and Theo Gevers. Fewviewgs: Gaussian splatting with few view matching and multi-stage training. InProceedings of the Advances in Neural Information Processing Systems, volume 37, pages 127204–127225, 2024
2024
-
[70]
arXiv preprint arXiv:2508.09667 , year=
Xingyilang Yin, Qi Zhang, Jiahao Chang, Ying Feng, Qingnan Fan, Xi Yang, Chi-Man Pun, Huaqi Zhang, and Xiaodong Cun. Gsfixer: Improving 3d gaussian splatting with reference-guided video diffusion priors. arXiv preprint arXiv:2508.09667, 2025
-
[71]
Mip-splatting: Alias-free 3d gaussian splatting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19447–19456, 2024. 13
2024
-
[72]
Frequency-aware density control via reparameter- ization for high-quality rendering of 3d gaussian splatting
Zhaojie Zeng, Yuesong Wang, Lili Ju, and Tao Guan. Frequency-aware density control via reparameter- ization for high-quality rendering of 3d gaussian splatting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9833–9841, 2025
2025
-
[73]
Gaussian in the wild: 3d gaussian splatting for unconstrained image collections
Dongbin Zhang, Chuming Wang, Weitao Wang, Peihao Li, Minghan Qin, and Haoqian Wang. Gaussian in the wild: 3d gaussian splatting for unconstrained image collections. InProceedings of the European Conference on Computer Vision, pages 341–359. Springer, 2024
2024
-
[74]
Su-rgs: Relightable 3d gaussian splatting from sparse views under unconstrained illuminations
Qi Zhang, Chi Huang, Qian Zhang, Nan Li, and Wei Feng. Su-rgs: Relightable 3d gaussian splatting from sparse views under unconstrained illuminations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26859–26868, 2025
2025
-
[75]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018
2018
-
[76]
Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting
Zheng Zhang, Wenbo Hu, Yixing Lao, Tong He, and Hengshuang Zhao. Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting. InProceedings of the European Conference on Computer Vision, pages 326–342. Springer, 2024
2024
-
[77]
Self-ensembling gaussian splatting for few-shot novel view synthesis
Chen Zhao, Xuan Wang, Tong Zhang, Saqib Javed, and Mathieu Salzmann. Self-ensembling gaussian splatting for few-shot novel view synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4940–4950, 2025
2025
-
[78]
Drivedreamer4d: World models are effective data machines for 4d driving scene representation
Guosheng Zhao, Chaojun Ni, Xiaofeng Wang, Zheng Zhu, Xueyang Zhang, Yida Wang, Guan Huang, Xinze Chen, Boyuan Wang, Youyi Zhang, et al. Drivedreamer4d: World models are effective data machines for 4d driving scene representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12015–12026, 2025
2025
-
[79]
Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. Fsgs: Real-time few-shot view synthesis using gaussian splatting. InProceedings of the European Conference on Computer Vision, pages 145–163. Springer, 2024. 14 Appendix In this appendix, we provide an additional discussion, more experimental results, and other technical details. We organize the appe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.