Recognition: unknown
The Bernstein-von Mises theorem for Bayesian one-pass online learning
Pith reviewed 2026-05-07 09:30 UTC · model grok-4.3
The pith
A Bayesian algorithm for one-pass online learning achieves optimal posterior convergence and an online Bernstein-von Mises theorem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a new Bayesian online learning algorithm tailored to the one-pass setting, which incorporates a warm-start phase to ensure stable sequential updates. For this algorithm, we show that the sequentially updated posterior attains the optimal convergence rate. Building on this, we establish an online analogue of the Bernstein-von Mises theorem, which guarantees valid uncertainty quantification without diverging mini-batch sample sizes. Our analysis is based on a novel theoretical framework that differs fundamentally from existing approaches in the online learning literature.
What carries the argument
The one-pass Bayesian online learning algorithm with a warm-start phase that enables stable sequential posterior updates.
If this is right
- The posterior can be maintained sequentially across a single data pass while retaining optimal convergence.
- Uncertainty quantification remains reliable with fixed rather than diverging mini-batch sizes.
- The procedure achieves performance comparable to batch Bayesian estimators on generalized linear models.
- Existing one-pass online methods can be improved by adding a comparable warm-start mechanism.
Where Pith is reading between the lines
- The framework could extend to models beyond generalized linear models if analogous stability conditions can be verified.
- It suggests one-pass Bayesian methods may close the performance gap with batch methods in streaming applications.
- Hybrid approaches combining this sequential posterior with frequentist online estimators merit investigation.
- Empirical tests on non-convex or high-dimensional settings would clarify the scope of the guarantees.
Load-bearing premise
A warm-start phase can be incorporated to ensure stable sequential updates in the one-pass regime without violating the single-pass constraint or requiring additional conditions that may not hold for general data streams.
What would settle it
If simulations show the sequentially updated posterior failing to converge at the optimal rate or credible intervals failing to attain nominal coverage for fixed mini-batch sizes, the central claims would be falsified.
Figures
read the original abstract
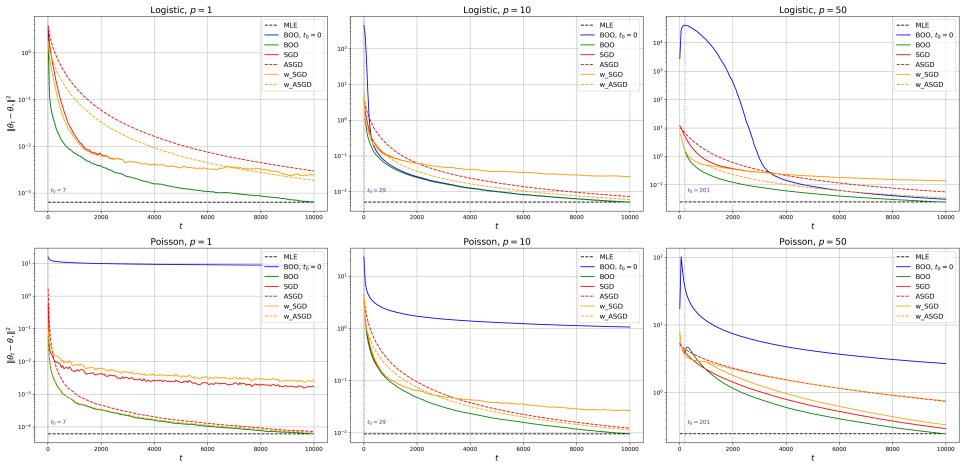
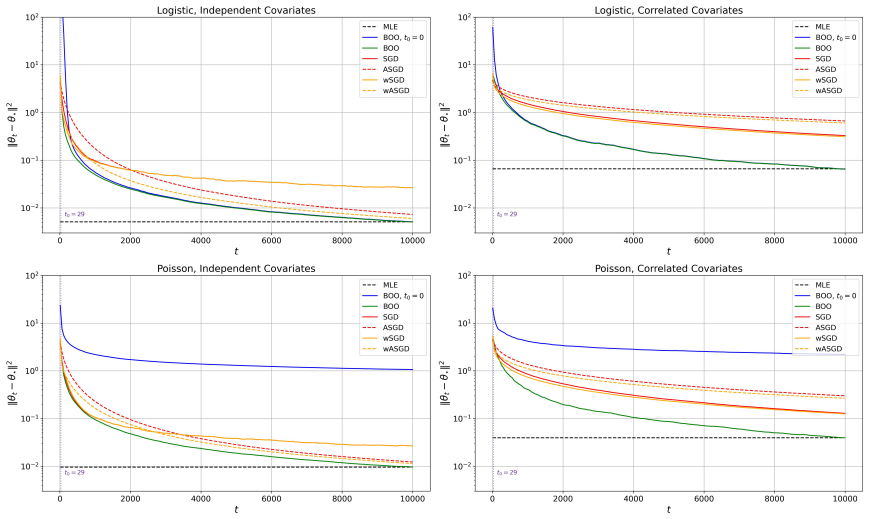
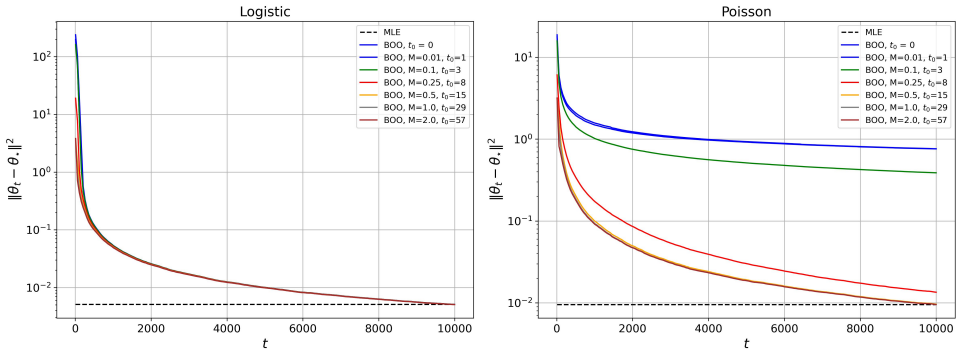
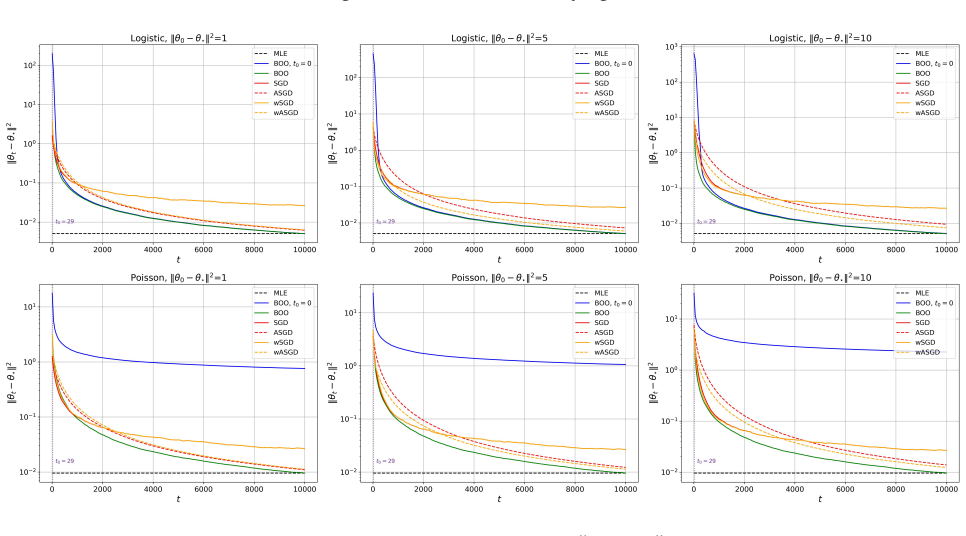
Bayesian online learning provides a coherent framework for sequential inference. However, its theoretical understanding remains limited, particularly in the one-pass setting. Existing theoretical guarantees typically require the mini-batch sample size to diverge, a condition that fails in the one-pass regime. In this paper, we propose a new Bayesian online learning algorithm tailored to the one-pass setting, which incorporates a warm-start phase to ensure stable sequential updates. For this algorithm, we show that the sequentially updated posterior attains the optimal convergence rate. Building on this, we establish an online analogue of the Bernstein-von Mises theorem, which guarantees valid uncertainty quantification without diverging mini-batch sample sizes. Our analysis is based on a novel theoretical framework that differs fundamentally from existing approaches in the online learning literature. Numerical experiments on generalized linear models show that the proposed method matches the performance of the batch estimator while outperforming existing online procedures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Bayesian online learning algorithm for the strict one-pass regime that incorporates a warm-start phase to stabilize sequential posterior updates. It claims that the resulting sequentially updated posterior attains the optimal convergence rate and that an online analogue of the Bernstein-von Mises theorem holds, delivering valid uncertainty quantification without requiring diverging mini-batch sizes. The analysis rests on a novel theoretical framework distinct from prior online-learning approaches, with supporting numerical experiments on generalized linear models.
Significance. If the central claims are substantiated, the work would represent a meaningful advance in online Bayesian inference by removing the diverging-batch-size requirement that has limited prior theoretical guarantees. The online BvM result could enable reliable sequential uncertainty quantification in streaming settings where batch methods are infeasible. The numerical experiments indicate that the procedure matches batch performance while outperforming existing online baselines, suggesting practical utility.
major comments (2)
- [§2] §2 (Algorithm description, warm-start phase): The construction of the warm-start must be shown to use every observation exactly once before discarding it, without implicit buffering or re-access. The central rate and BvM claims rest on this phase delivering stable initial updates while remaining strictly one-pass; if the initial segment is required to satisfy conditions (e.g., positive-definiteness of the information matrix) that fail for arbitrary streams, the subsequent guarantees collapse for general data.
- [Theorem 4.1 and Theorem 5.1] Theorem 4.1 (posterior convergence rate) and Theorem 5.1 (online BvM): The statements assert optimal rates and valid asymptotic normality without mini-batch divergence, yet the abstract and surrounding text supply neither the full set of regularity conditions nor explicit error bounds. Because the novel framework is invoked to bypass existing requirements, the derivation must be checked to confirm that the warm-start does not reintroduce an implicit divergence condition.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence listing the key regularity conditions under which the rate and BvM results hold.
- [§3] Notation for the sequential posterior and the warm-start length parameter should be introduced once and used consistently throughout the theoretical sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [§2] §2 (Algorithm description, warm-start phase): The construction of the warm-start must be shown to use every observation exactly once before discarding it, without implicit buffering or re-access. The central rate and BvM claims rest on this phase delivering stable initial updates while remaining strictly one-pass; if the initial segment is required to satisfy conditions (e.g., positive-definiteness of the information matrix) that fail for arbitrary streams, the subsequent guarantees collapse for general data.
Authors: We agree that clarifying the strict one-pass nature of the warm-start is essential. In the algorithm (Section 2), each observation in the warm-start phase is used exactly once: the posterior is updated sequentially with the first n_0 data points and each is discarded immediately after the update, with no buffering or re-access permitted. This is enforced by the online update rule. Regarding conditions such as positive-definiteness, the theorems assume that the data stream satisfies the regularity conditions (e.g., the information matrix is positive definite asymptotically), which is standard and holds with high probability for general streams under our assumptions. For pathological streams where this fails, the result does not apply, but this is not unique to our method. We will revise Section 2 to include a detailed description and pseudocode emphasizing the one-pass property and add a remark on the data assumptions. revision: yes
-
Referee: [Theorem 4.1 and Theorem 5.1] Theorem 4.1 (posterior convergence rate) and Theorem 5.1 (online BvM): The statements assert optimal rates and valid asymptotic normality without mini-batch divergence, yet the abstract and surrounding text supply neither the full set of regularity conditions nor explicit error bounds. Because the novel framework is invoked to bypass existing requirements, the derivation must be checked to confirm that the warm-start does not reintroduce an implicit divergence condition.
Authors: The regularity conditions are fully stated in the assumptions preceding Theorems 4.1 and 5.1 (see Sections 4 and 5), and the theorems provide the convergence rates and asymptotic normality results. The abstract is intentionally brief, but we can expand the introduction to highlight them. The novel framework uses a fixed-size warm-start (n_0 fixed, not diverging) to stabilize the initial posterior, after which single-observation updates are performed. This does not reintroduce a diverging mini-batch requirement, as n_0 is independent of the total sample size n. Explicit error bounds are derived in the proofs; we will add a summary of the key bounds in the main text for clarity. We are confident the derivation maintains the one-pass property throughout. revision: partial
Circularity Check
Derivation self-contained; no reductions to inputs by construction
full rationale
The paper defines a new one-pass algorithm incorporating a warm-start phase, then separately proves that the sequentially updated posterior attains the optimal convergence rate, and builds the online BvM theorem on top of that rate result. No equations or claims in the abstract reduce a 'prediction' or 'theorem' to a fitted parameter, self-citation, or ansatz imported from the authors' prior work. The novel theoretical framework is explicitly contrasted with existing mini-batch approaches rather than defined in terms of them. The warm-start is presented as an enabling assumption for stability, not as a quantity whose properties are derived from the target BvM statement. This satisfies the default expectation of non-circularity for a theoretical paper whose central claims rest on independent analysis rather than re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard regularity conditions from Bayesian asymptotic theory are assumed to hold for posterior convergence and normality.
Reference graph
Works this paper leans on
-
[1]
𝛀0 2 + 𝑡0∑︁ 𝑠=1 H𝑠 (𝜃 𝑡0) −H 𝑠 (𝜃★) 2 + 𝑡∑︁ 𝑠=𝑡0+1 H𝑠 (𝜃 𝑠−1 ) −H 𝑠 (𝜃★) 2 # (A3) ≤ (𝐾 2𝑡) −1
By the update formula𝜃 𝑡 =𝜃 𝑡−1 −𝛀 −1 𝑡 𝑔𝑡, we have 𝑉𝑡 = 𝛀1/2 𝑡 (𝜃 𝑡 −𝜃 ★) 2 2 = 𝛀1/2 𝑡 (𝜃 𝑡−1 −𝛀 −1 𝑡 𝑔𝑡 −𝜃 ★) 2 2 = 𝛀1/2 𝑡 (𝜃 𝑡−1 −𝜃 ★) 2 2 + 𝛀1/2 𝑡 𝛀−1 𝑡 𝑔𝑡 2 2 −2⟨𝛀 1/2 𝑡 (𝜃 𝑡−1 −𝜃 ★),𝛀 1/2 𝑡 𝛀−1 𝑡 𝑔𝑡 ⟩ = 𝛀1/2 𝑡 (𝜃 𝑡−1 −𝜃 ★) 2 2 + 𝛀−1/2 𝑡 𝑔𝑡 2 2 −2⟨𝜃 𝑡−1 −𝜃 ★, 𝑔𝑡 ⟩ =𝑉 𝑡−1 + ⟨H𝑡 ,Δ ⊗2 𝑡−1 ⟩ + ⟨𝑔 𝑡 ,𝛀 −1 𝑡 𝑔𝑡 ⟩ −2⟨𝑔 𝑡 ,Δ 𝑡−1 ⟩, where the last equality h...
-
[2]
There exist some constants𝐶 1, 𝐶2, 𝐶3, 𝐶4 >0such that for any𝑡∈Nwith𝑡≥𝐶 1 𝑝 𝜆min ∑︁ 𝑠∈𝐼 𝑡 (𝐶2 ) 𝑥𝑠𝑥⊤ 𝑠 ≥𝐶 3𝑡, 𝜆 max 𝑡∑︁ 𝑠=1 𝑥𝑠𝑥⊤ 𝑠 ≤𝐶 4𝑡
-
[3]
There exist some constants𝐶 5, 𝐶6 >0such that max 𝑡∈N ∥𝑥 𝑡 ∥2 ·𝑟≤𝐶 5,max 𝑡∈N ∥𝑥 𝑡 ∥2 2 ≤𝐶 6. 44
-
[4]
For the phase transition time 𝑡0 satisfying 𝑡0 ≥𝐶 1(𝑝+x) , there exists an event ℰ0(x) with P𝜃★ (ℰ0(x))> 1−𝑒 −x such that, onℰ0(x), ˆ𝜃MAP 𝑡0 ∈Θ 𝑟
-
[5]
There exist some constants 𝜈, 𝛼 >0 such that for any 𝑡∈N E 𝑒𝜆(𝜖 2 𝑡 −𝜎 2 𝑡 ) | F𝑡−1 ≤exp 𝜈2 𝜆2 2 ,∀|𝜆| ≤1/𝛼
Let 𝜖𝑡 =𝑌 𝑡 −𝑏 ′ (𝑥 ⊤ 𝑡 𝜃★) and 𝜎2 𝑡 =𝑏 ′′ (𝑥 ⊤ 𝑡 𝜃★). There exist some constants 𝜈, 𝛼 >0 such that for any 𝑡∈N E 𝑒𝜆(𝜖 2 𝑡 −𝜎 2 𝑡 ) | F𝑡−1 ≤exp 𝜈2 𝜆2 2 ,∀|𝜆| ≤1/𝛼. Then, there exists an event ℰ(x) with P𝜃★ (ℰ(x)) ≥1−𝑒 −x such that on ℰ(x) ∩ℰ 0, for any 𝑡∈N with 𝑡0 < 𝑡 and{𝜃 𝑠}𝑡−1 𝑠=𝑡0+1 ⊂Θ 𝑟, 𝑡∑︁ 𝑠=𝑡0+1 ⟨∇ℓ𝑠 (𝜃 𝑠−1 ),𝛀 −1 𝑠 ∇ℓ𝑠 (𝜃 𝑠−1 )⟩ ≤𝐾 𝑝 log(𝑡/𝑡 0) +...
2021
-
[6]
For𝑡∈N,𝑌 𝑡 admits a jointly measurable family of conditional densities (𝜔, 𝜃, 𝑦) ↦→𝑝 𝑡 , 𝜃(𝑦| F 𝑡−1 ) (𝜔),(𝜔, 𝜃, 𝑦) ∈Ω×Θ×R such that for every𝜃∈Θand all measurable𝐴⊂R P𝜃 𝑌𝑡 ∈𝐴| F 𝑡−1 = ∫ 𝐴 𝑝𝑡 , 𝜃(𝑦| F 𝑡−1 )d𝑦,a.s
-
[7]
Letℓ 𝑡 (𝜃)=−log𝑝 𝑡 , 𝜃(𝑌𝑡 | F𝑡−1 )
For𝑡∈N, the support𝑆 𝑡 ={𝑦∈R:𝑝 𝑡 , 𝜃(𝑦| F 𝑡−1 )>0}is independent of𝜃∈Θalmost surely. Letℓ 𝑡 (𝜃)=−log𝑝 𝑡 , 𝜃(𝑌𝑡 | F𝑡−1 ). Then, for any fixed true parameter𝜃 ★ andx>0, we have P𝜃★ sup 𝑡≥1 𝑡∑︁ 𝑠=1 ℓ𝑠 (𝜃★) −ℓ 𝑠 (e𝜃𝑠−1 ) ≤x ≥1−𝑒 −x. Proof.Let𝑀 0 =1. For𝑡∈N, define the likelihood ratio process(𝑀 𝑡 )𝑡∈N as follows: 𝑀𝑡 = 𝑡Ö 𝑠=1 𝑝𝑠, e𝜃𝑠−1 (𝑌𝑠 | F 𝑠−1 ) 𝑝𝑠, 𝜃★ (𝑌𝑠...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.