Recognition: unknown
Improving Graph Few-shot Learning with Hyperbolic Space and Denoising Diffusion
Pith reviewed 2026-05-07 09:48 UTC · model grok-4.3
The pith
Graph few-shot learning improves when nodes are embedded in hyperbolic space and support distributions are enriched by denoising diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that node representations learned in hyperbolic space capture the latent hierarchical structure of graphs more faithfully than Euclidean embeddings, while denoising diffusion mechanisms reduce the mismatch between the empirical distribution formed by few support samples and the true task distribution; together these changes produce a tighter generalization bound and higher empirical performance across multiple graph few-shot benchmarks.
What carries the argument
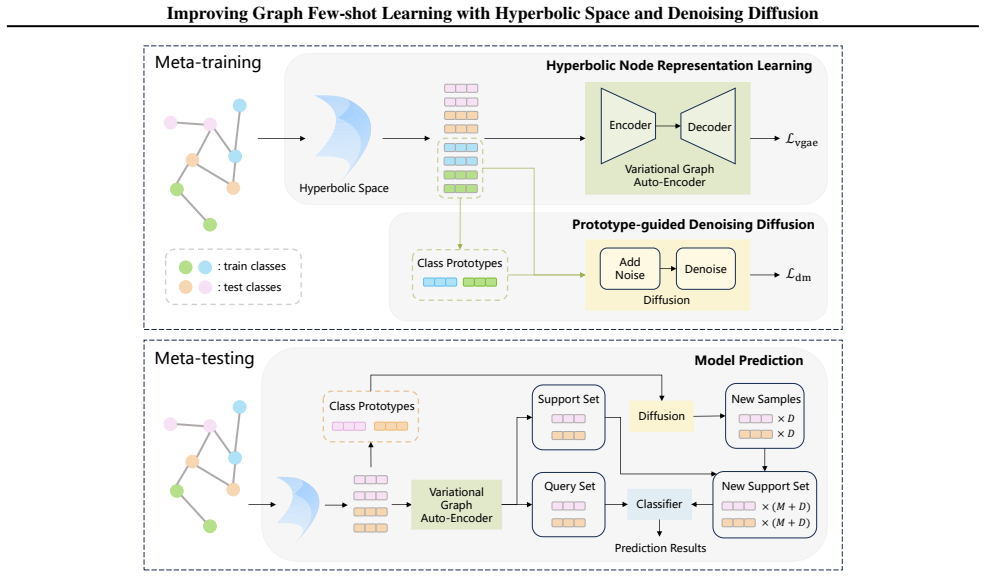
The IMPRESS framework, which performs representation learning inside hyperbolic space and augments the few-shot support distribution through iterative denoising diffusion.
If this is right
- A tighter generalization bound holds under the combined hyperbolic and diffusion design.
- The method outperforms standard Euclidean meta-learning baselines on multiple graph few-shot datasets.
- Hierarchical structure is better preserved in the learned node representations.
- Support-set distribution shift is mitigated during the meta-testing phase.
Where Pith is reading between the lines
- Hyperbolic embeddings may help other graph tasks that involve tree-like or hierarchical patterns even outside the few-shot setting.
- Denoising diffusion could serve as a general corrective tool whenever meta-learning relies on very small support sets.
- The interaction between curvature choice in hyperbolic space and the number of diffusion steps offers a natural direction for further tuning.
Load-bearing premise
Real-world graphs contain hierarchical structure that Euclidean space represents poorly, and the distribution estimated from a few support samples can be corrected toward the true distribution by denoising diffusion.
What would settle it
On a graph dataset lacking hierarchical organization, the hyperbolic version would show no accuracy gain over its Euclidean counterpart, or adding the diffusion step would fail to reduce distribution mismatch and would not raise task performance.
Figures

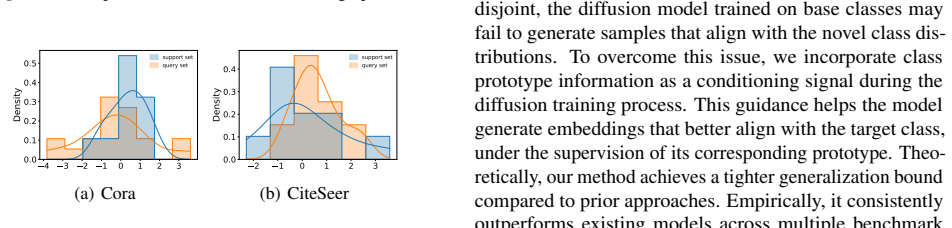

read the original abstract
Graph few-shot learning, which focuses on effectively learning from only a small number of labeled nodes to quickly adapt to new tasks, has garnered significant research attention. Despite recent advances in graph few-shot learning that have demonstrated promising performance, existing methods still suffer from several key limitations. First, during the meta-training phase, these methods typically perform node representation learning in Euclidean space, which often fails to capture the inherently hierarchical structure existing in real-world graph data. Second, during the meta-testing phase, they usually fit an empirical target distribution derived from only a few support samples, even when this distribution significantly deviates from the true underlying distribution. To address these issues, we propose IMPRESS, a novel framework that IMproves graPh few-shot learning with hypeRbolic spacE and denoiSing diffuSion. Specifically, our model learns node representations in a hyperbolic space and enriches the support distribution through denoising diffusion mechanisms. Theoretically, IMPRESS achieves a tighter generalization bound. Empirically, IMPRESS consistently outperforms competitive baselines across multiple benchmark datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IMPRESS, a framework for graph few-shot learning that performs node representation learning in hyperbolic space to capture inherent hierarchical structures and applies denoising diffusion to enrich the empirical support distribution during meta-testing. It claims that these components yield a tighter generalization bound than prior Euclidean approaches and deliver consistent empirical outperformance over competitive baselines on multiple benchmark datasets.
Significance. If the tighter bound and performance gains are substantiated, the work would advance graph few-shot learning by addressing Euclidean limitations on hierarchical data and small-sample distribution mismatch, offering a geometrically motivated alternative with potential benefits for applications involving tree-like or hierarchical graphs such as citation networks or molecular structures.
major comments (1)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The claim that IMPRESS achieves a tighter generalization bound is not accompanied by an explicit side-by-side derivation of the corresponding bound for a Euclidean graph few-shot baseline under identical assumptions (same meta-learning setup, Lipschitz constants, and covering numbers). Without this comparison, it is impossible to verify that the hyperbolic geometry terms or diffusion correction reduce the leading bound terms rather than merely reparameterizing graph-specific factors such as node degree or diameter.
minor comments (1)
- [Abstract] The abstract would benefit from briefly naming the specific benchmark datasets and the categories of baselines (e.g., Euclidean meta-learning methods) to give readers immediate context for the claimed outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the sole major comment on the theoretical analysis below and will incorporate the requested comparison in the revision.
read point-by-point responses
-
Referee: The claim that IMPRESS achieves a tighter generalization bound is not accompanied by an explicit side-by-side derivation of the corresponding bound for a Euclidean graph few-shot baseline under identical assumptions (same meta-learning setup, Lipschitz constants, and covering numbers). Without this comparison, it is impossible to verify that the hyperbolic geometry terms or diffusion correction reduce the leading bound terms rather than merely reparameterizing graph-specific factors such as node degree or diameter.
Authors: We acknowledge the absence of an explicit side-by-side derivation in the current §4. The manuscript derives the generalization bound for IMPRESS by incorporating the hyperbolic distance (which yields smaller covering numbers due to negative curvature) and the diffusion-based enrichment of the support distribution (which reduces the discrepancy term). To directly verify the improvement, the revised version will add the parallel derivation for a Euclidean baseline under identical meta-learning assumptions, Lipschitz constants, and covering-number arguments. We will explicitly contrast the leading terms, showing that the hyperbolic geometry factor and diffusion correction strictly tighten the bound beyond any reparameterization of node degree or diameter. revision: yes
Circularity Check
No circularity: theoretical bound and empirical claims remain independent of inputs
full rationale
The abstract states a theoretical claim that IMPRESS achieves a tighter generalization bound and empirical outperformance on benchmarks, motivated by limitations of Euclidean space and few-shot distribution fitting. No equations, derivations, or self-citations are visible that reduce the bound to fitted parameters, rename known results, or import uniqueness via author-overlapping citations. The derivation chain is presented as self-contained against external benchmarks and assumptions, with no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hyperbolic space better captures hierarchical structures in graphs than Euclidean space
- domain assumption Denoising diffusion can enrich few-sample empirical distributions toward the true underlying distribution
Reference graph
Works this paper leans on
-
[1]
Kipf, T. N. and Welling, M. Semi-supervised classifica- tion with graph convolutional networks.arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review arXiv
-
[2]
Mernyei, P. and Cangea, C. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901,
-
[3]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[4]
Pitfalls of Graph Neural Network Evaluation
Shchur, O., Mumme, M., Bojchevski, A., and G¨unnemann, S. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868,
-
[5]
Task- adaptive few-shot node classification
Wang, S., Ding, K., Zhang, C., Chen, C., and Li, J. Task- adaptive few-shot node classification. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 1910–1919,
1910
-
[6]
Hicf: Hyper- bolic informative collaborative filtering
Yang, M., Li, Z., Zhou, M., Liu, J., and King, I. Hicf: Hyper- bolic informative collaborative filtering. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2212–2221, 2022a. Yang, M., Zhou, M., Li, Z., Liu, J., Pan, L., Xiong, H., and King, I. Hyperbolic graph neural networks: A review of methods and applications....
-
[7]
Table 6.Detailed descriptions of important symbols used in our work. Symbols Descriptions G,V,E graph, node set, and edge set X,A node features, adjacency matrix Ttra,T tes meta-training and meta-testing tasks Stest,Q test support and query sets in the meta-testing task X H hyperbolic node embeddings X T tangent node embeddings ˜H, ˜S refined node and set...
1985
-
[8]
It is a graph meta-learning framework that combines prototype-based initialization and scaling and shifting transformations to enable effective transferable knowledge learning and adaptation. TLP(Tan et al., 2022): It employs transductive linear probing by first pretraining a graph encoder via contrastive learning and subsequently utilizing it to generate...
2022
-
[9]
As can be clearly observed in Table 7, our model consistently achieves the best performance in hierarchical clustering, indicating that the node embeddings learned in hyperbolic space exhibit more pronounced hierarchical structures compared to the baselines trained in Euclidean space. A.7. Related Work A.7.1. GRAPHFEW-SHOTLEARNING Graph FSL aims to equip ...
2023
-
[10]
and metric-based (Ding et al., 2020; Liu et al., 2024; Yao et al., 2020). Optimization-based methods typically integrate graph neural networks (GNNs) with meta-learning algorithms such as MAML (Finn et al., 2017), enabling models to adapt their parameters efficiently across tasks. Metric-based methods focus on learning a task-general metric space that can...
2020
-
[11]
are introduced for learning symbolic representations within hyperbolic geometry and have shown strong capabilities in modeling hierarchical relationships. Following this, an alternative optimization approach based on the Lorentz model of hyperbolic space is proposed (Nickel & Kiela, 2018), which substantially improved embedding quality. Recent studies hav...
2018
-
[12]
is also proposed for learning GNNs in hyperbolic space. Inspired by these developments, our model leverages the Poincar ´e ball model to map node embeddings from Euclidean space into hyperbolic space, aiming to better preserve hierarchical structures in the latent space. A.7.3. DIFFUSIONMODELS Diffusion models are a class of generative approaches that lea...
2023
-
[13]
In recent years, diffusion models have been widely used in fields such as text-to-image generation (Rombach et al., 2022; Ramesh et al.,
improves diffusion models by performing the diffusion process in compressed latent space rather than pixel space, which significantly improves computational efficiency while preserving generation quality. In recent years, diffusion models have been widely used in fields such as text-to-image generation (Rombach et al., 2022; Ramesh et al.,
2022
-
[14]
Motivated by their strong generative capability and flexibility, we incorporate diffusion models into our framework to enhance the performance of graph FSL
and text-to-audio (Yang et al., 2023; Huang et al., 2022). Motivated by their strong generative capability and flexibility, we incorporate diffusion models into our framework to enhance the performance of graph FSL. 16
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.