Recognition: unknown
Uni-HOI:A Unified framework for Learning the Joint distribution of Text and Human-Object Interaction
Pith reviewed 2026-05-07 09:36 UTC · model grok-4.3
The pith
Uni-HOI learns the joint distribution of text, human motion, and object motion to handle multiple HOI tasks in one model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Uni-HOI learns the joint distribution among text, human motion, and object motion by leveraging large language models and two motion-specific vector quantized variational autoencoders to convert heterogeneous motion data into token sequences compatible with LLM inputs, enabling seamless integration and joint modeling of all three modalities through a two-stage training strategy of multi-task learning on a large-scale HOI dataset followed by task-specific fine-tuning.
What carries the argument
Two motion-specific VQ-VAEs that encode human and object motions into discrete token sequences for LLM processing, allowing the model to treat text and both motion types as a unified sequence for joint distribution learning.
If this is right
- The model performs text-driven HOI generation, object motion-driven human motion generation with optional text, and human motion-driven object motion prediction without needing separate architectures.
- Multi-task pretraining on a large HOI dataset captures underlying correlations among the three modalities before fine-tuning.
- The same trained weights support all listed conditional inputs and outputs in a single forward pass after fine-tuning.
- Removing task-specific designs reduces the engineering overhead for deploying multiple HOI capabilities.
Where Pith is reading between the lines
- The tokenization approach could extend to other paired sequence data such as audio with video or sensor streams with language.
- Sharing the LLM backbone across modalities may reduce the total parameters needed compared with maintaining independent models for each task.
- If inference speed scales well, the framework could support interactive VR scenarios where users supply mixed text and partial motion inputs.
Load-bearing premise
Converting heterogeneous motion data into token sequences via two motion-specific VQ-VAEs preserves enough detail for accurate joint modeling with text inside an LLM.
What would settle it
A direct comparison showing that task-specific HOI models still achieve higher scores on standard metrics such as FID for text-conditioned generation or lower error for motion prediction than the unified Uni-HOI on the same test sets.
Figures


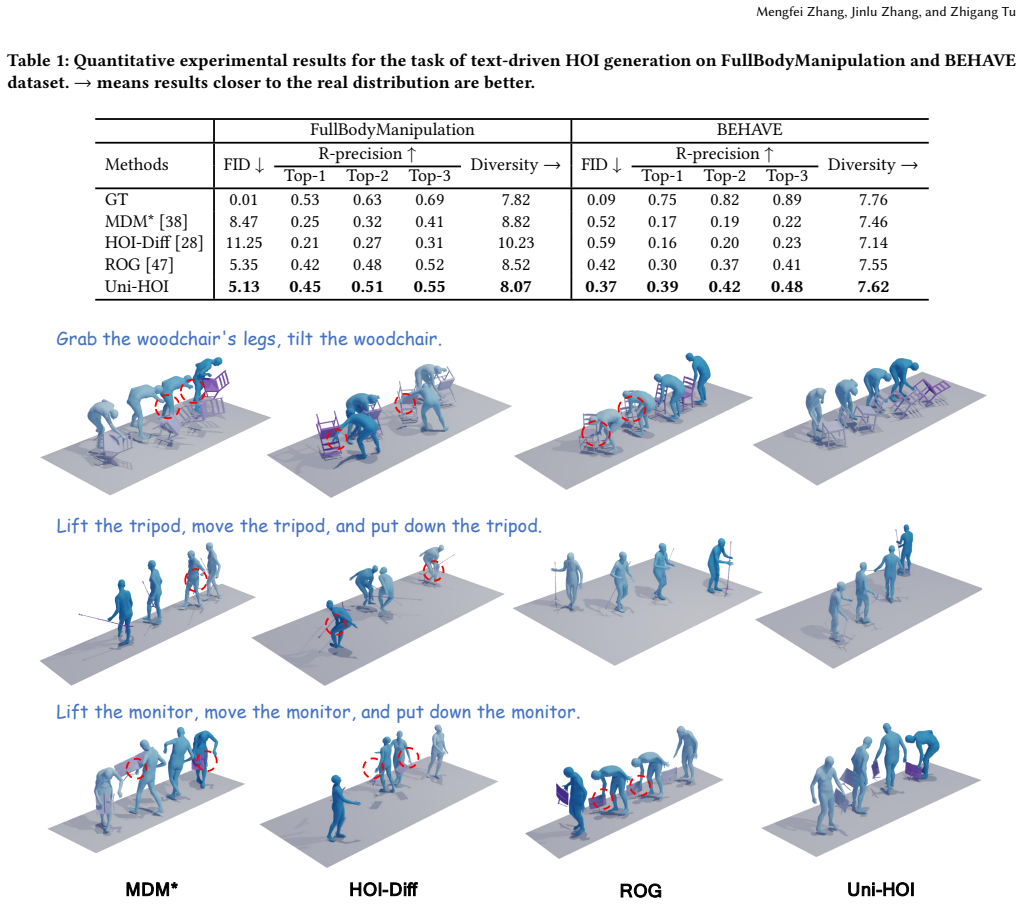
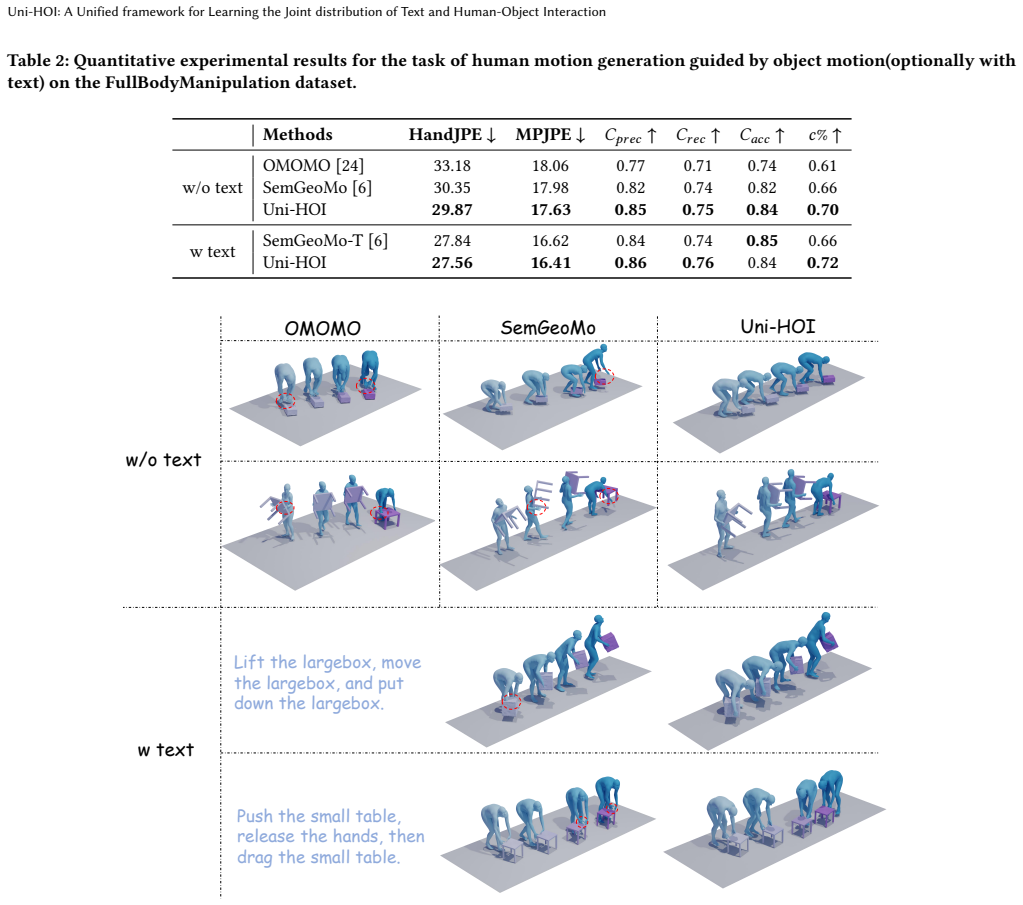


read the original abstract
Modeling 4D human-object interaction (HOI) is a compelling challenge in computer vision and an essential technology powering virtual and mixed-reality applications. While existing works have achieved promising results on specific HOI tasks-such as text-conditioned HOI generation and human motion generation from object motion, they typically rely on task-specific architectures and lack a unified framework capable of handling diverse conditional inputs. Building on this, we propose Uni-HOI, a unified framework that learns the joint distribution among text, human motion, and object motion. By leveraging large language models (LLMs) and two motion-specific vector quantized variational autoencoders (VQ-VAEs), we convert heterogeneous motion data into token sequences compatible with LLM inputs, enabling seamless integration and joint modeling of all three modalities. We introduce a two-stage training strategy: the first stage performs multi-task learning on a large-scale HOI dataset to capture the underlying correlations among the three modalities, while the second stage fine-tunes the model on specific tasks to further enhance performance. Extensive experiments demonstrate that Uni-HOI achieves remarkable performances on multiple HOI-related tasks including text-driven HOI generation, object motion-driven human motion generation (optionally with text) and human motion-driven object motion prediction within a unified framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Uni-HOI, a unified framework for learning the joint distribution over text, human motion, and object motion in 4D HOI. It tokenizes heterogeneous motion data using two modality-specific VQ-VAEs, feeds the resulting sequences together with text into an LLM, and trains via a two-stage procedure (multi-task pre-training on a large HOI corpus followed by task-specific fine-tuning). The framework is asserted to handle text-driven HOI generation, object-motion-driven human motion generation (with optional text), and human-motion-driven object motion prediction within a single model.
Significance. If the empirical results hold and the tokenization preserves interaction-critical dynamics, the work would offer a meaningful advance by replacing multiple task-specific architectures with one LLM-based model capable of flexible conditioning. This could reduce engineering overhead for VR/AR applications that require mixed text-motion control. The two-stage training strategy and explicit joint-distribution modeling are conceptually attractive, but their value hinges on whether the discrete codes retain the continuous correlations that define HOI.
major comments (2)
- [Abstract] Abstract: the claim that Uni-HOI 'achieves remarkable performances' on multiple tasks is unsupported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis. Without these, the central assertion that a single LLM+VQ-VAE model outperforms prior task-specific methods cannot be evaluated.
- [Method] Method section (VQ-VAE and tokenization pipeline): the two motion-specific VQ-VAEs are trained with standard per-modality reconstruction objectives; no cross-modal consistency loss, interaction-specific regularization, or fidelity metric on contact points/relative velocities is described. If quantization error is high on these degrees of freedom, the LLM will model a distorted joint distribution regardless of the two-stage training, directly undermining the unified-framework claim.
minor comments (2)
- The abstract would be strengthened by including at least one key quantitative result (e.g., FID or success rate on the primary task) to allow readers to gauge the magnitude of improvement.
- Notation for the combined token sequence (text tokens + human-motion tokens + object-motion tokens) and the exact conditioning mechanism inside the LLM should be made explicit, preferably with a diagram or equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the paper to improve clarity and address the raised concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Uni-HOI 'achieves remarkable performances' on multiple tasks is unsupported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis. Without these, the central assertion that a single LLM+VQ-VAE model outperforms prior task-specific methods cannot be evaluated.
Authors: We agree that the abstract makes a qualitative claim without embedding specific numbers. The full manuscript provides quantitative results, baseline comparisons, ablation studies, and error analyses in the Experiments section. To directly support the claim within the abstract itself, we will revise it to include key performance metrics (e.g., FID, R-Precision, and task-specific accuracies) and note the outperformance over prior task-specific methods. This change will make the abstract self-contained while remaining concise. revision: yes
-
Referee: [Method] Method section (VQ-VAE and tokenization pipeline): the two motion-specific VQ-VAEs are trained with standard per-modality reconstruction objectives; no cross-modal consistency loss, interaction-specific regularization, or fidelity metric on contact points/relative velocities is described. If quantization error is high on these degrees of freedom, the LLM will model a distorted joint distribution regardless of the two-stage training, directly undermining the unified-framework claim.
Authors: The VQ-VAEs are trained with standard per-modality reconstruction losses to produce discrete tokens from heterogeneous motion data, allowing the LLM to learn the joint distribution over the resulting sequences. We acknowledge that interaction-critical elements such as contact points and relative velocities are important for HOI fidelity. While the current manuscript emphasizes overall reconstruction quality and downstream task performance, we will add an analysis subsection in the revised version that reports quantization error specifically on contact points and relative velocities, along with any available fidelity metrics. This will help confirm that the discretization preserves the correlations needed for the unified framework. A cross-modal consistency loss was not included in the original design, as the two-stage training on the joint token sequences proved sufficient in our experiments, but we will discuss this design choice explicitly. revision: yes
Circularity Check
No circularity: architectural description with empirical validation
full rationale
The paper describes an architectural framework (LLM + two modality-specific VQ-VAEs + two-stage training) for joint modeling of text, human motion, and object motion. No equations, derivations, or first-principles results are presented that reduce to their own inputs by construction. Performance claims rest on experimental results across tasks rather than any self-referential prediction or fitted parameter renamed as output. Self-citations, if present, are not load-bearing for any core claim. The derivation chain is self-contained as a modeling proposal validated externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token sequences from motion-specific VQ-VAEs are compatible with LLM inputs for joint multi-modal modeling
Reference graph
Works this paper leans on
-
[1]
Bharat Lal Bhatnagar, Xianghui Xie, Ilya A Petrov, Cristian Sminchisescu, Chris- tian Theobalt, and Gerard Pons-Moll. 2022. Behave: Dataset and method for tracking human object interactions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15935–15946
2022
-
[2]
Xinhao Cai, Minghang Zheng, Xin Jin, and Yang Liu. 2025. InteractMove: Text- Controlled Human-Object Interaction Generation in 3D Scenes with Movable Objects. InProceedings of the 33rd ACM International Conference on Multimedia. 9491–9499
2025
- [3]
-
[4]
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. 2024. Text2hoi: Text-guided 3d motion generation for hand-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1577–1585
2024
-
[5]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models.Journal of Machine Learning Research25, 70 (2024), 1–53
2024
-
[6]
Peishan Cong, Ziyi Wang, Yuexin Ma, and Xiangyu Yue. 2025. Semgeomo: Dynamic contextual human motion generation with semantic and geometric guidance. InProceedings of the Computer Vision and Pattern Recognition Confer- ence. 17561–17570
2025
-
[7]
Sisi Dai, Wenhao Li, Haowen Sun, Haibin Huang, Chongyang Ma, Hui Huang, Kai Xu, and Ruizhen Hu. 2024. Interfusion: Text-driven generation of 3d human- object interaction. InEuropean Conference on Computer Vision. Springer, 18–35
2024
-
[8]
Christian Diller and Angela Dai. 2024. Cg-hoi: Contact-guided 3d human-object interaction generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19888–19901
2024
-
[9]
Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, and Jingbo Wang. 2025. Go to zero: Towards zero-shot motion generation with million-scale data. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 13336–13348
2025
-
[10]
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kauf- mann, Michael J Black, and Otmar Hilliges. 2023. ARCTIC: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12943–12954
2023
-
[11]
Zichen Geng, Zeeshan Hayder, Wei Liu, and Ajmal Saeed Mian. 2025. Auto- regressive diffusion for generating 3d human-object interactions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 3131–3139
2025
-
[12]
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. 2022. Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. InEuropean Conference on Computer Vision. Springer, 580–597
2022
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[14]
Hezhen Hu, Weichao Wang, Wei Zhou, Wei Zhao, Houqiang Li, and Guanbin Li. 2022. Hand-Object Interaction Image Generation. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. 23870–23883
2022
-
[15]
Yinghao Huang, Omid Taheri, Michael J Black, and Dimitrios Tzionas. 2024. InterCap: joint markerless 3D tracking of humans and objects in interaction from multi-view RGB-D images.International Journal of Computer Vision132, 7 (2024), 2551–2566
2024
-
[16]
Kai Jia, Yuxuan Liu, Yiming Yang, and He Wang. 2025. PrimHOI: Compositional Human-Object Interaction via Reusable Primitives. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). to appear
2025
-
[17]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. 2023. Mo- tiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems36 (2023), 20067–20079
2023
-
[18]
Nan Jiang, Tengyu Liu, Zhexuan Cao, Jieming Cui, Zhiyuan Zhang, Yixin Chen, He Wang, Yixin Zhu, and Siyuan Huang. 2023. Full-body articulated human- object interaction. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9365–9376
2023
-
[19]
Hwanhee Jung, Seungryul Lee, Seungryong Kim, and Sung Ju Hwang. 2025. Decoupled Generative Modeling for Human-Object Interaction Synthesis.arXiv preprint(2025). arXiv:2512.19049 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Jeonghwan Kim, Jisoo Kim, Jeonghyeon Na, and Hanbyul Joo. 2025. Parahome: Parameterizing everyday home activities towards 3d generative modeling of human-object interactions. InProceedings of the Computer Vision and Pattern Recognition Conference. 1816–1828
2025
-
[21]
Taku Kudo and John Richardson. 2018. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 conference on empirical methods in natural language processing: System demonstrations. 66–71
2018
- [22]
-
[23]
Jiaman Li, Alexander Clegg, Roozbeh Mottaghi, Jiajun Wu, Xavier Puig, and C Karen Liu. 2024. Controllable human-object interaction synthesis. InEuropean Conference on Computer Vision. Springer, 54–72
2024
-
[24]
Jiaman Li, Jiajun Wu, and C Karen Liu. 2023. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG)42, 6 (2023), 1–11
2023
- [25]
-
[26]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review arXiv 2017
-
[27]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[28]
Xiaogang Peng, Yiming Xie, Zizhao Wu, Varun Jampani, Deqing Sun, and Huaizu Jiang. 2025. Hoi-diff: Text-driven synthesis of 3d human-object interactions using diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference. 2878–2888
2025
-
[29]
Ilya A Petrov, Riccardo Marin, Julian Chibane, and Gerard Pons-Moll. 2023. Object pop-up: Can we infer 3d objects and their poses from human interactions alone?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4726–4736
2023
-
[30]
Ilya A Petrov, Riccardo Marin, Julian Chibane, and Gerard Pons-Moll. 2025. Tridi: Trilateral diffusion of 3d humans, objects, and interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5523–5535
2025
-
[31]
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al . 2018. Improving language understanding by generative pre-training.OpenAI preprint (2018)
2018
-
[32]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[33]
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. 2019. Generating diverse high-fidelity images with vq-vae-2.Advances in neural information processing systems32 (2019)
2019
- [34]
-
[35]
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. 2024. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers. 1–11
2024
-
[36]
Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. 2022. Bailando: 3d dance generation by actor- critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11050–11059
2022
-
[37]
Omid Taheri, Nima Ghorbani, Michael J Black, and Dimitrios Tzionas. 2020. GRAB: A dataset of whole-body human grasping of objects. InEuropean confer- ence on computer vision. Springer, 581–600
2020
-
[38]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. 2022. Human motion diffusion model.arXiv preprint arXiv:2209.14916(2022)
work page internal anchor Pith review arXiv 2022
-
[39]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review arXiv 2023
-
[41]
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning.Advances in neural information processing systems30 (2017)
2017
-
[42]
Qianyang Wu, Ye Shi, Xiaoshui Huang, Jingyi Yu, Lan Xu, and Jingya Wang
-
[43]
Thor: Text to human-object interaction diffusion via relation intervention. arXiv preprint arXiv:2403.11208(2024)
-
[44]
Zhen Wu, Jiaman Li, Pei Xu, and C Karen Liu. 2025. Human-object interaction from human-level instructions. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11176–11186
2025
-
[45]
Sirui Xu, Dongting Li, Yucheng Zhang, Xiyan Xu, Qi Long, Ziyin Wang, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Akshat Gupta, et al. 2025. Interact: Advancing large-scale versatile 3d human-object interaction generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 7048–7060
2025
-
[46]
Sirui Xu, Zhengyuan Li, Yu-Xiong Wang, and Liang-Yan Gui. 2023. Interdiff: Generating 3d human-object interactions with physics-informed diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14928– 14940
2023
-
[47]
Sirui Xu, Ziyin Wang, Yu-Xiong Wang, and Liang-Yan Gui. 2024. Interdreamer: Zero-shot text to 3d dynamic human-object interaction.Advances in Neural Information Processing Systems37 (2024), 52858–52890. Mengfei Zhang, Jinlu Zhang, and Zhigang Tu
2024
-
[48]
Mengqing Xue, Yifei Liu, Ling Guo, Shaoli Huang, and Changxing Ding. 2025. Guiding human-object interactions with rich geometry and relations. InProceed- ings of the Computer Vision and Pattern Recognition Conference. 22714–22723
2025
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review arXiv 2025
-
[50]
Jie Yang, Xuesong Niu, Nan Jiang, Ruimao Zhang, and Siyuan Huang. 2024. F-hoi: Toward fine-grained semantic-aligned 3d human-object interactions. InEuropean Conference on Computer Vision. Springer, 91–110
2024
-
[51]
Juze Zhang, Haimin Luo, Hongdi Yang, Xinru Xu, Qianyang Wu, Ye Shi, Jingyi Yu, Lan Xu, and Jingya Wang. 2023. Neuraldome: A neural modeling pipeline on multi-view human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8834–8845
2023
-
[52]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. 2023. Generating human motion from textual descriptions with discrete representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14730–14740
2023
-
[53]
Wanyue Zhang, Rishabh Dabral, Vladislav Golyanik, Vasileios Choutas, Eduardo Alvarado, Thabo Beeler, Marc Habermann, and Christian Theobalt. 2025. Bimart: A unified approach for the synthesis of 3d bimanual interaction with articulated objects. InProceedings of the Computer Vision and Pattern Recognition Conference. 27694–27705
2025
- [54]
-
[55]
Chengfeng Zhao, Juze Zhang, Jiashen Du, Ziwei Shan, Junye Wang, Jingyi Yu, Jingya Wang, and Lan Xu. 2024. I’m hoi: Inertia-aware monocular capture of 3d human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 729–741
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.