Recognition: unknown
FMCL: Class-Aware Client Clustering with Foundation Model Representations for Heterogeneous Federated Learning
Pith reviewed 2026-05-07 10:07 UTC · model grok-4.3
The pith
FMCL uses class-level prototypes from a frozen foundation model to perform one-shot client clustering before federated training begins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
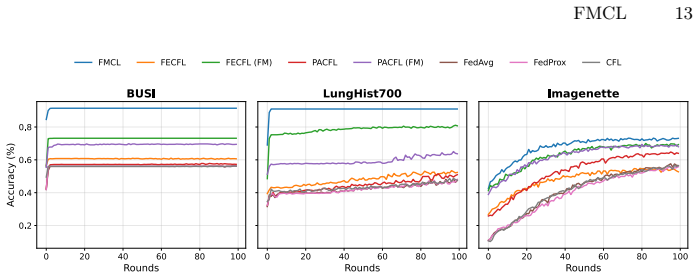
FMCL builds semantic client signatures by computing class-level embedding prototypes with a frozen foundation model, then applies one-shot clustering via cosine similarity on these prototypes prior to federated optimization, yielding improved accuracy and more stable groupings under non-identically distributed data.
What carries the argument
Class-level embedding prototypes extracted by a frozen foundation model, with cosine distance serving as the similarity metric for one-shot client clustering.
If this is right
- Clustering adds no communication rounds during the federated training phase itself.
- The approach works with any downstream model architecture since it never inspects or alters model parameters.
- Accuracy gains appear on multiple heterogeneous benchmarks relative to prior clustering techniques.
- Cluster assignments remain more consistent than those derived from raw data statistics or model updates.
Where Pith is reading between the lines
- The same frozen-model signatures could support client grouping in other distributed settings that lack shared labels.
- Re-running the one-shot step with an updated foundation model would require only local recomputation and no extra rounds.
- Hybrid pipelines might combine these fixed prototypes with light client-specific adaptation when domain gaps are large.
- The method could apply to privacy-sensitive scenarios where semantic grouping is needed without exchanging raw examples.
Load-bearing premise
That representations from a frozen foundation model capture class-level semantic structure reliably enough across heterogeneous domains for cosine similarity to produce useful client clusters without any adaptation.
What would settle it
An experiment on a heterogeneous benchmark where the foundation-model prototypes produce clusters that either fail to raise accuracy or change substantially across repeated runs compared with existing clustering baselines.
Figures

read the original abstract
Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, yet its performance deteriorates under statistical heterogeneity. Clustered Federated Learning addresses this challenge by grouping similar clients and training separate models per cluster. However, existing clustering strategies often rely on raw data statistics, model parameters, or heuristic similarity measures that fail to capture class-level semantic structure across heterogeneous domains and frequently require iterative coordination. We propose FMCL, a one-shot, class-aware client clustering framework that leverages foundation model representations to construct semantic client signatures. Using a frozen foundation model, FMCL computes class-level embedding prototypes for each client and measures similarity via cosine distance between their class-aware representations. Clustering is performed once prior to training, introducing no additional communication during federated optimization and remaining agnostic to the downstream model architecture. Extensive experiments across heterogeneous benchmarks demonstrate that FMCL improves federated performance and yields more stable clustering behavior compared to existing clustering-based methods under non-identically distributed data partitioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FMCL, a one-shot client clustering framework for heterogeneous federated learning. It extracts class-level embedding prototypes from each client's local data using a frozen foundation model, measures inter-client similarity via cosine distance on these class-aware representations, and performs clustering once before federated training begins. The method is presented as architecture-agnostic and communication-free during optimization. The central claim is that this yields improved federated accuracy and more stable clusters than prior clustering-based FL approaches on non-IID benchmarks.
Significance. If the empirical results hold after proper validation, FMCL would offer a lightweight, pre-training-leveraging alternative to parameter- or heuristic-based clustering in FL, reducing coordination overhead while addressing statistical heterogeneity through semantic client signatures derived from general-purpose models.
major comments (2)
- [Abstract] Abstract: The central claim of performance gains and improved stability is asserted without any quantitative results, baseline comparisons, statistical tests, ablation studies, or experimental protocol details, leaving the empirical contribution unsupported at the level needed for assessment.
- [Method] Method (clustering step): The one-shot cosine clustering on frozen FM class prototypes assumes that these embeddings reliably capture class semantics and produce meaningful client groups across heterogeneous partitions without domain adaptation or refinement; no analysis, sensitivity checks, or validation on out-of-distribution client data is provided to support this load-bearing assumption.
minor comments (2)
- [Method] Clarify how class prototypes are exactly computed (e.g., averaging, weighting) and whether the foundation model choice is fixed or explored.
- [Experiments] Ensure all figures and tables in the experimental section include error bars, multiple random seeds, and direct numerical comparisons to the cited baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from more concrete empirical support and that additional analysis would strengthen the validation of the clustering assumption. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of performance gains and improved stability is asserted without any quantitative results, baseline comparisons, statistical tests, ablation studies, or experimental protocol details, leaving the empirical contribution unsupported at the level needed for assessment.
Authors: We agree that the abstract presents the claims at a high level. In the revised version, we will update the abstract to include key quantitative highlights from our experiments, such as the observed improvements in federated accuracy and measures of clustering stability across non-IID benchmarks. The full experimental protocol, baseline comparisons (including methods such as IFCA and parameter-based clustering), ablation studies, and any statistical tests are already provided in detail in Sections 4 and 5. This change will better align the abstract with the empirical content of the paper. revision: yes
-
Referee: [Method] Method (clustering step): The one-shot cosine clustering on frozen FM class prototypes assumes that these embeddings reliably capture class semantics and produce meaningful client groups across heterogeneous partitions without domain adaptation or refinement; no analysis, sensitivity checks, or validation on out-of-distribution client data is provided to support this load-bearing assumption.
Authors: The assumption is indeed central to the approach. Our experiments on multiple heterogeneous benchmarks demonstrate that the resulting clusters yield performance gains and greater stability relative to prior methods, providing indirect empirical support for the semantic quality of the frozen foundation model prototypes. We acknowledge the absence of explicit sensitivity analysis or dedicated out-of-distribution validation. In the revision, we will add sensitivity checks on foundation model choice and further discussion of robustness under distribution shifts. The non-IID partitions used already incorporate substantial heterogeneity that serves as a practical test of the assumption. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FMCL as a procedural pipeline: a frozen foundation model computes class-level embedding prototypes per client, cosine similarity is applied once to form clusters before any federated training, and the process is architecture-agnostic with no additional communication. No equations, fitted parameters, or predictions are described that reduce the claimed performance gains to the inputs by construction. The abstract and method summary contain no self-citations of prior author results used as load-bearing uniqueness theorems, no smuggled ansatzes, and no renaming of known results as novel derivations. The central claim rests on direct computation from external foundation-model representations and empirical benchmarks, making the approach self-contained against external data without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen foundation model representations preserve class-level semantic similarities across heterogeneous client domains
Reference graph
Works this paper leans on
-
[1]
In: In- ternational Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy
2021
-
[2]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Fallah, A., Mokhtari, A., Ozdaglar, A.: Personalized federated learning with the- oretical guarantees: A model-agnostic meta-learning approach. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neu- ral Information Processing Systems. vol. 33, pp. 3557–3568. Curran Associates, Inc. (2020),https://proceedings.neurips.cc/p...
2020
-
[3]
Ghosh, A., Chung, J., Yin, D., Ramchandran, K.: An efficient framework for clus- tered federated learning. IEEE Transactions on Information Theory68(12), 8076– 8091 (2022).https://doi.org/10.1109/TIT.2022.3192506
-
[4]
Hsu, T.M.H., Qi, H., Brown, M.: Measuring the effects of non-identical data dis- tribution for federated visual classification (2019),https://arxiv.org/abs/1909. 06335
2019
-
[5]
Pattern Recog- nition153, 110500 (2024).https://doi.org/https://doi.org/10.1016/j
Jiao, J., Zhou, J., Li, X., Xia, M., Huang, Y., Huang, L., Wang, N., Zhang, X., Zhou, S., Wang, Y., Guo, Y.: Usfm: A universal ultrasound foundation model generalized to tasks and organs towards label efficient image analysis. Medical Im- age Analysis96, 103202 (2024).https://doi.org/https://doi.org/10.1016/j. media.2024.103202,https://www.sciencedirect.c...
work page doi:10.1016/j 2024
-
[6]
In: International Conference on Machine Learning
Karimireddy, S.P., Kale, S., Mohri, M., Reddi, S., Stich, S., Suresh, A.T.: Scaffold: Stochastic controlled averaging for federated learning. In: International Conference on Machine Learning. pp. 5132–5143. PMLR (2020)
2020
-
[7]
Lao, G., Zhang, X., Li, Y., Gong, Y.J.: Lightweight clustered federated learning via feature extraction. In: ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5 (2025).https: //doi.org/10.1109/ICASSP49660.2025.10889437
-
[8]
Proceedings of Machine learning and sys- tems2, 429–450 (2020)
Li, T., Sahu, A.K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V.: Federated optimization in heterogeneous networks. Proceedings of Machine learning and sys- tems2, 429–450 (2020)
2020
-
[9]
In: Singh, A., Zhu, J
McMahan, B., Moore, E., Ramage, D., Hampson, S., Arcas, B.A.y.: Communication-Efficient Learning of Deep Networks from Decentralized Data. In: Singh, A., Zhu, J. (eds.) Proceedings of the 20th International Conference on Artifi- cial Intelligence and Statistics. Proceedings of Machine Learning Research, vol. 54, pp. 1273–1282. PMLR (20–22 Apr 2017),https:...
2017
-
[10]
Adaptive federated optimization,
Reddi, S., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konečn` y, J., Ku- mar, S., McMahan, H.B.: Adaptive federated optimization. arXiv preprint arXiv:2003.00295 (2020)
-
[11]
Sattler, F., Müller, K.R., Samek, W.: Clustered federated learning: Model-agnostic distributed multi-task optimization under privacy constraints. IEEE Transactions on Neural Networks and Learning Systems32(8), 3710–3722 (2021).https:// doi.org/10.1109/TNNLS.2020.3015958,http://dx.doi.org/10.1109/TNNLS. 2020.3015958 16 M. Ali et al
-
[12]
Vahidian, S., Morafah, M., Wang, W., Kungurtsev, V., Chen, C., Shah, M., Lin, B.: Efficient distribution similarity identification in clustered federated learning via principal angles between client data subspaces. In: Proceedings of the Thirty- Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Ar...
-
[13]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Wang, J., Liu, Q., Liang, H., Joshi, G., Poor, H.V.: Tackling the objective incon- sistency problem in heterogeneous federated optimization. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
2020
-
[14]
Nature634(8035), 970–978 (Oct 2024)
Wang, X., Zhao, J., Marostica, E., Yuan, W., Jin, J., Zhang, J., Li, R., Tang, H., Wang, K., Li, Y., Wang, F., Peng, Y., Zhu, J., Zhang, J., Jackson, C.R., Zhang, J., Dillon,D.,Lin,N.U.,Sholl,L.,Denize,T.,Meredith,D.,Ligon,K.L.,Signoretti,S., Ogino, S., Golden, J.A., Nasrallah, M.P., Han, X., Yang, S., Yu, K.H.: A pathology foundation model for cancer dia...
2024
- [15]
- [16]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.