Recognition: unknown
SpatialGrammar: A Domain-Specific Language for LLM-Based 3D Indoor Scene Generation
Pith reviewed 2026-05-07 07:54 UTC · model grok-4.3
The pith
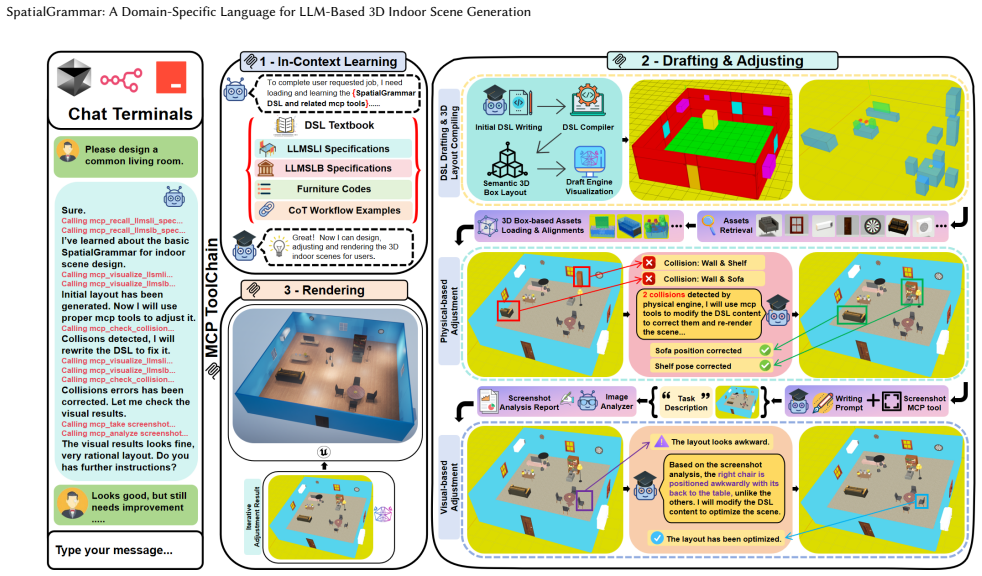
SpatialGrammar encodes 3D indoor scenes as grid placements that compile deterministically to valid geometry, letting LLMs produce layouts with fewer spatial errors and collisions than raw coordinates or code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpatialGrammar represents gravity-aligned indoor layouts as bird's-eye-view grid placements with deterministic compilation to 3D geometry. This representation supports verifiable constraint checking, which in turn powers SG-Agent's closed-loop refinement that enforces collision-free results and SG-Mini's training on synthetic validated data. Across 159 test scenes in five scenarios, the approach yields higher spatial fidelity and physical plausibility than prior LLM baselines, with the compact model remaining competitive in single-pass generation.
What carries the argument
SpatialGrammar, the domain-specific language that encodes indoor scenes as gravity-aligned bird's-eye-view grid placements with automatic deterministic compilation to 3D geometry for constraint verification.
If this is right
- SG-Agent can iteratively correct scenes using direct compiler feedback on collisions and constraints.
- SG-Mini trained solely on compiler-validated data matches larger models on single-shot generation tasks.
- The grid representation directly reduces spatial errors and physical violations across scenes of varying complexity.
- Deterministic compilation from the DSL guarantees that output geometry satisfies the checked constraints.
Where Pith is reading between the lines
- The same grid-plus-compiler pattern could be applied to other structured generation problems such as 2D floor-plan layout or robotic task planning.
- Small specialized models trained on validated synthetic data may lower the cost of creating large collections of virtual environments for downstream AI training.
- If the grid assumption proves broad enough, the method could simplify integration between language-based scene generators and physics simulators used in embodied AI.
Load-bearing premise
Typical indoor scenes can be fully captured by placing objects on a flat gravity-aligned grid without losing important spatial relationships or physical constraints.
What would settle it
A benchmark containing scenes with non-grid-aligned furniture, multi-level stacking, or objects that require precise 3D overhangs or rotations would show whether the generated outputs degrade sharply in fidelity or validity compared with coordinate-based baselines.
Figures


















read the original abstract
Automatically generating interactive 3D indoor scenes from natural language is crucial for virtual reality, gaming, and embodied AI. However, existing LLM-based approaches often suffer from spatial errors and collisions, in part because common scene representations-raw coordinates or verbose code-are difficult for models to reason about 3D spatial relationships and physical constraints. We propose SpatialGrammar, a domain-specific language that represents gravity-aligned indoor layouts as BEV grid placements with deterministic compilation to valid 3D geometry, enabling verifiable constraint checking. Building on this representation, we develop (1) SG-Agent, a closed-loop system that uses compiler feedback to iteratively refine scenes and enforce collision constraints, and (2) SG-Mini, a 104M-parameter model trained entirely on compiler-validated synthetic data. Across 159 test scenes spanning five scenarios of different complexity, SG-Agent improves spatial fidelity and physical plausibility over prior methods, while SG-Mini performs competitively against larger LLM-based baselines on single-shot generation scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpatialGrammar, a domain-specific language that represents gravity-aligned indoor layouts as BEV grid placements with deterministic compilation to valid 3D geometry, enabling verifiable constraint checking. It develops SG-Agent, a closed-loop LLM system that uses compiler feedback to iteratively refine scenes and enforce collision constraints, and SG-Mini, a 104M-parameter model trained entirely on compiler-validated synthetic data. Across 159 test scenes spanning five scenarios of varying complexity, the paper claims SG-Agent improves spatial fidelity and physical plausibility over prior methods, while SG-Mini performs competitively against larger LLM-based baselines in single-shot generation.
Significance. If the results hold, the work provides a structured approach to mitigating spatial errors in LLM-based 3D scene generation through a verifiable DSL and feedback mechanism, which is relevant for VR, gaming, and embodied AI. The closed-loop refinement and training of a compact model on synthetic data demonstrate efficiency advantages. However, significance is conditional on whether the BEV representation adequately captures the full range of indoor spatial constraints; limitations here would restrict generalizability of the reported gains.
major comments (2)
- [§3 (SpatialGrammar DSL definition)] §3 (SpatialGrammar DSL definition): The central claim that the representation enables enforcement of all relevant physical constraints rests on gravity-aligned BEV grid placements with deterministic compilation. This may omit stacking and surface-support relations (e.g., objects on tables or shelves), as only floor-level (x,y) positions and orientations with fixed heights appear to be encoded. If so, the compiler feedback loop cannot detect or correct these constraints, limiting the physical plausibility improvements to a subset of the 159 scenes. The paper must clarify the grammar's expressiveness limits and confirm whether test scenes include hierarchical placements.
- [§5 (Experiments and evaluation)] §5 (Experiments and evaluation): The abstract reports quantitative gains on 159 scenes, but without details on exact metrics for spatial fidelity and physical plausibility, baseline implementations, error bars, statistical significance tests, or data exclusion criteria, the robustness of the improvements cannot be verified. This directly affects the soundness assessment; please add per-scenario tables, ablation results on the feedback loop, and full metric definitions.
minor comments (2)
- [Abstract] The abstract refers to 'five scenarios of different complexity' without naming or briefly describing them; this should be clarified in the abstract or introduction for immediate context.
- [§3] Notation and examples for the SpatialGrammar DSL could be expanded with additional concrete scene examples in the main text to improve readability for readers unfamiliar with the representation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us strengthen the clarity and rigor of the manuscript. We address each major comment below, providing point-by-point responses and indicating the revisions made to the paper.
read point-by-point responses
-
Referee: [§3 (SpatialGrammar DSL definition)] §3 (SpatialGrammar DSL definition): The central claim that the representation enables enforcement of all relevant physical constraints rests on gravity-aligned BEV grid placements with deterministic compilation. This may omit stacking and surface-support relations (e.g., objects on tables or shelves), as only floor-level (x,y) positions and orientations with fixed heights appear to be encoded. If so, the compiler feedback loop cannot detect or correct these constraints, limiting the physical plausibility improvements to a subset of the 159 scenes. The paper must clarify the grammar's expressiveness limits and confirm whether test scenes include hierarchical placements.
Authors: We appreciate the referee's observation on the scope of the DSL. SpatialGrammar is explicitly designed for gravity-aligned, floor-level indoor layouts represented as BEV grid placements, where each object receives an (x, y) grid coordinate and orientation, with height and vertical extent determined deterministically by the compiler from object category metadata. This enables verifiable floor-plane collision and boundary constraint checking. The grammar does not encode stacking or surface-support relations (e.g., objects resting on tables or shelves), as these would require a hierarchical scene representation beyond the current flat grid model. We have revised §3 to include an explicit subsection stating the grammar's expressiveness limits and assumptions. All 159 test scenes across the five scenarios consist exclusively of floor-level placements with no hierarchical stacking or surface supports, as defined in the scenario specifications in §5. The reported gains in physical plausibility therefore apply fully within this floor-level scope. We have also added a limitations paragraph discussing extensions to hierarchical placements as future work. revision: yes
-
Referee: [§5 (Experiments and evaluation)] §5 (Experiments and evaluation): The abstract reports quantitative gains on 159 scenes, but without details on exact metrics for spatial fidelity and physical plausibility, baseline implementations, error bars, statistical significance tests, or data exclusion criteria, the robustness of the improvements cannot be verified. This directly affects the soundness assessment; please add per-scenario tables, ablation results on the feedback loop, and full metric definitions.
Authors: We agree that expanded experimental reporting is required for full verification. In the revised manuscript we have augmented §5 with the following: (1) complete mathematical definitions of spatial fidelity (collision rate, overlap ratio, boundary adherence) and physical plausibility (stability score, support validity) metrics in a new §5.1 subsection; (2) per-scenario tables (new Table 3) reporting means and standard deviations for each metric across all five scenarios, with corresponding error bars added to Figure 4; (3) results of paired t-tests with p-values to establish statistical significance; (4) detailed descriptions of baseline implementations in §5.2, including prompting strategies and model versions for prior methods; (5) ablation studies on the compiler feedback loop (new Table 4) comparing SG-Agent performance with and without iterative refinement; and (6) explicit statement that no scenes were excluded—all 159 test scenes were evaluated. Evaluation code and metric implementations have been added to the supplementary material to support reproducibility. revision: yes
Circularity Check
No load-bearing circularity; compiler feedback and held-out evaluation remain independent of model outputs.
full rationale
The paper defines SpatialGrammar as an external DSL whose grammar rules and deterministic compiler are specified independently of any LLM outputs or fitted parameters. SG-Agent's iterative refinement loop receives constraint violations from this compiler rather than from quantities defined in terms of the agent's own generations. SG-Mini is trained on synthetic scenes that have already passed compiler validation, but the test set of 159 scenes is held out and the reported metrics (spatial fidelity, physical plausibility) are computed against ground-truth layouts using the same external compiler. No equation or claim reduces a prediction to a fitted input by construction, and no uniqueness theorem or ansatz is smuggled via self-citation. The only minor self-reference is the authors' own prior DSL work, which is not load-bearing for the central empirical claim. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Indoor scenes can be adequately represented as gravity-aligned layouts on a BEV grid without loss of critical spatial information or physical constraints.
invented entities (1)
-
SpatialGrammar DSL
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rio Aguina-Kang, Maxim Gumin, Do Heon Han, Stewart Morris, Seung Jean Yoo, Aditya Ganeshan, R Kenny Jones, Qiuhong Anna Wei, Kailiang Fu, and Daniel Ritchie. 2024. Open-universe indoor scene generation using llm program synthesis and uncurated object databases.arXiv preprint arXiv:2403.09675(2024)
-
[2]
Anthropic. 2024. Introducing the Model Context Protocol. Model Context Protocol
2024
- [3]
-
[4]
Wei Deng, Mengshi Qi, and Huadong Ma. 2025. Global-local tree search in vlms for 3d indoor scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 8975–8984
2025
-
[5]
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. 2023. Layoutgpt: Compositional visual planning and generation with large language models. Advances in Neural Information Processing Systems36 (2023), 18225–18250
2023
-
[6]
Rao Fu, Zehao Wen, Zichen Liu, and Srinath Sridhar. 2024. Anyhome: Open- vocabulary generation of structured and textured 3d homes. InEuropean Confer- ence on Computer Vision. Springer, 52–70
2024
-
[7]
Zeqi Gu, Yin Cui, Zhaoshuo Li, Fangyin Wei, Yunhao Ge, Jinwei Gu, Ming-Yu Liu, Abe Davis, and Yifan Ding. 2025. ArtiScene: Language-Driven Artistic 3D Scene Generation Through Image Intermediary. InProceedings of the Computer Vision and Pattern Recognition Conference. 2891–2901
2025
-
[8]
Maxim Gumin, Do Heon Han, Seung Jean Yoo, Aditya Ganeshan, R Kenny Jones, Kailiang Fu, Rio Aguina-Kang, Stewart Morris, and Daniel Ritchie. 2025. Procedural Scene Programs for Open-Universe Scene Generation: LLM-Free Error Correction via Program Search. InProceedings of the SIGGRAPH Asia 2025 Conference Papers. 1–11
2025
-
[9]
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nießner
-
[10]
Text2room: Extracting textured 3d meshes from 2d text-to-image models. InProc. of ICCV. 7909–7920
-
[11]
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A Ross, Cordelia Schmid, and Alireza Fathi. 2024. SceneCraft: An LLM Agent for Synthe- sizing 3D Scenes as Blender Code. InProc. of ICML. 19252–19282
2024
-
[12]
Ian Huang, Yanan Bao, Karen Truong, Howard Zhou, Cordelia Schmid, Leonidas Guibas, and Alireza Fathi. 2025. Fireplace: Geometric refinements of llm common sense reasoning for 3d object placement. InProceedings of the Computer Vision and Pattern Recognition Conference. 13466–13476
2025
-
[13]
Yinhao Li, Han Bao, Zheng Ge, Jinrong Yang, Jianjian Sun, and Zeming Li. 2023. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. InProc. of the AAAI. 1486–1494
2023
- [14]
-
[15]
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or
-
[16]
Latent-nerf for shape-guided generation of 3d shapes and textures. InProc. of CVPR. 12663–12673
-
[17]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM65 (2021), 99–106
2021
-
[18]
Başak Melis Öcal, Maxim Tatarchenko, Sezer Karaoğlu, and Theo Gevers. 2024. SceneTeller: Language-to-3D Scene Generation. InEuropean Conference on Com- puter Vision. Springer, 362–378
2024
-
[19]
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D using 2D Diffusion.arXiv:2209.14988(2022)
work page internal anchor Pith review arXiv 2022
- [20]
- [21]
-
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[23]
Learning transferable visual models from natural language supervision. In Proc. of ICML. 8748–8763
-
[24]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
- [25]
-
[26]
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. 2019. Habitat: A platform for embodied ai research. InProc. of ICCV. 9339–9347
2019
-
[27]
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. 2023. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In Proc. of ICCV. 21729–21740
2023
-
[28]
Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. 2018. Gibson env: Real-world perception for embodied agents. InProc. of CVPR. 9068–9079
2018
-
[29]
Chenyu Yang, Yuntao Chen, Hao Tian, Chenxin Tao, Xizhou Zhu, Zhaoxiang Zhang, Gao Huang, Hongyang Li, Yu Qiao, Lewei Lu, et al. 2023. BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision. InProc. of the CVPR. 17830–17839
2023
- [30]
-
[31]
Yixuan Yang, Zhen Luo, Tongsheng Ding, Junru Lu, Mingqi Gao, Jinyu Yang, Victor Sanchez, and Feng Zheng. 2025. Optiscene: Llm-driven indoor scene layout generation via scaled human-aligned data synthesis and multi-stage preference optimization.arXiv preprint arXiv:2506.07570(2025)
-
[32]
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. 2024. Holodeck: Language guided generation of 3d embodied ai environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16227– 16237
2024
-
[33]
Place an armchair in the center of the room, facing west
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations. Tang et al. Figure 10: Diverse display of scenes generated by our model and GT of instance segmentation & depth. Table 5: Summar...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.