Recognition: unknown
Reproducing Adaptive Reranking for Reasoning-Intensive IR
Pith reviewed 2026-05-07 08:01 UTC · model grok-4.3
The pith
Graph-based adaptive reranking boosts reasoning-intensive retrieval with minimal overhead
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GAR addresses the bounded recall problem by modifying the reranking process itself through iterative exploration of a corpus graph. Replicated on the BRIGHT reasoning-intensive retrieval benchmark, GAR boosts the effectiveness of retrieval across a variety of models while contributing minimally to computational overheads. The quality of the reranker's signal plays an important role in identifying additional relevant documents within the corpus graph.
What carries the argument
Graph-based Adaptive Reranking (GAR), a reranking technique that uses iterative traversal of a corpus graph guided by the reranker's relevance scores to expand the candidate set beyond the initial retrieval results.
If this is right
- GAR improves retrieval metrics on the BRIGHT benchmark for reasoning-intensive queries.
- The improvements apply to both reasoning and non-reasoning reranking models.
- The method adds only minimal computational overhead compared to standard reranking.
- It serves as a low-cost way to mitigate bounded recall without enhancing the first-stage retriever.
Where Pith is reading between the lines
- The findings imply that investing in higher-quality rerankers may yield compounding benefits when combined with graph-based adaptation.
- This approach could be extended to other retrieval benchmarks involving multi-step or complex reasoning queries.
- In production systems, GAR offers a modular addition that improves handling of diverse query difficulties without full pipeline retraining.
Load-bearing premise
The reranker's relevance scores remain reliable enough to direct productive exploration through the corpus graph even for queries that require substantial reasoning.
What would settle it
A direct replication experiment on BRIGHT showing no statistically significant gains in effectiveness metrics like nDCG or recall when GAR is applied, or a measured inference time increase that exceeds the minimal overhead reported.
Figures

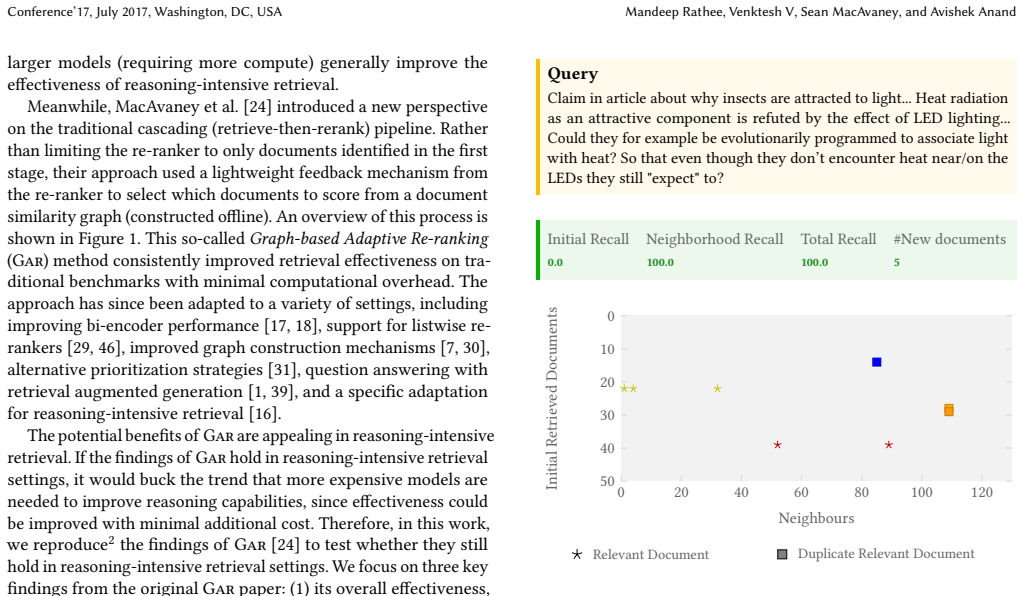
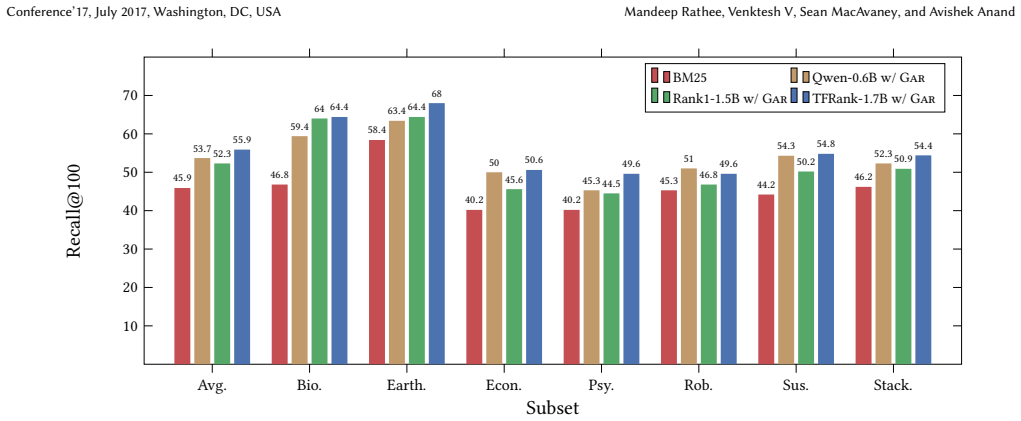




read the original abstract
The classical cascading pipeline of retrieve--rerank suffers from a bounded recall problem, stemming from limitations of the first-stage retriever. Most current approaches address the bounded recall problem by improving the first-stage retriever, but this incurs substantial training and inference costs, especially to handle queries that require substantial reasoning. To circumvent the computational costs of reasoning-based retrievers, we replicate the findings of GAR, Graph-based Adaptive Reranking, on the BRIGHT reasoning-intensive retrieval benchmark. GAR addresses the bounded recall problem by modifying the reranking process itself through iterative exploration of a corpus graph, but it was previously only tested on models designed for topical and question-answering-style queries. Hence, reproduce GAR in reasoning-intensive settings with reasoning and non-reasoning reranking models. We observe that the quality of the reranker's signal plays an important role in identifying additional relevant documents within the corpus graph. Overall, we find that GAR boosts the effectiveness of reasoning-intensive retrieval across a variety of models while contributing minimally to computational overheads. Ultimately, this work enables more practical deployment of retrieval systems that can address reasoning-intensive queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a reproduction study of Graph-based Adaptive Reranking (GAR) applied to the BRIGHT benchmark, which focuses on reasoning-intensive information retrieval. The authors claim that GAR successfully addresses the bounded recall issue in retrieve-rerank pipelines for such queries by iteratively exploring a corpus graph, leading to improved effectiveness across different reranking models with only minimal added computational overhead. They further observe that the reranker's signal quality is key to the success of this graph-based exploration in surfacing additional relevant documents.
Significance. Should the reproduction be confirmed with rigorous ablations and quantitative evidence, the findings would hold moderate significance for the IR community. They suggest a cost-effective alternative to developing specialized reasoning retrievers, potentially broadening access to high-performance retrieval for complex queries in applications like scientific literature search or legal document retrieval. The work also highlights the transferability of GAR to new query types.
major comments (2)
- [Abstract] The central observation that reranker signal quality plays an important role lacks any reported ablation, correlation analysis, or control experiment on the BRIGHT dataset. Without testing a low-quality reranker variant or measuring signal strength vs. gain, the mechanistic claim remains unverified and could be confounded by first-stage retriever properties or dataset specifics.
- [Results] The abstract provides no quantitative results, error bars, ablation details, or statistical tests to support the claim that GAR boosts effectiveness across models. Full details on metrics, improvements, and variability are required to evaluate the practical impact and robustness.
minor comments (2)
- [Methods] Provide more details on the specific reasoning and non-reasoning reranking models used, as well as the exact configuration of the corpus graph construction and iteration parameters for GAR.
- Consider adding a table summarizing the main results with baseline comparisons, including standard deviations if multiple runs were performed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our reproduction study. We address each major comment below and will incorporate revisions to improve the clarity and rigor of the manuscript, particularly in the abstract and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] The central observation that reranker signal quality plays an important role lacks any reported ablation, correlation analysis, or control experiment on the BRIGHT dataset. Without testing a low-quality reranker variant or measuring signal strength vs. gain, the mechanistic claim remains unverified and could be confounded by first-stage retriever properties or dataset specifics.
Authors: We agree that a more explicit analysis would strengthen the mechanistic claim. Our experiments do compare GAR performance across rerankers with varying reasoning capabilities on BRIGHT, which provides indirect evidence for the importance of signal quality. However, we did not include a dedicated correlation analysis or control with a deliberately low-quality reranker variant. In the revision, we will add a targeted analysis (e.g., correlating initial reranker effectiveness with GAR-induced gains) and, if feasible, results from a weakened reranker signal to help rule out confounding factors from the first-stage retriever or dataset. revision: yes
-
Referee: [Results] The abstract provides no quantitative results, error bars, ablation details, or statistical tests to support the claim that GAR boosts effectiveness across models. Full details on metrics, improvements, and variability are required to evaluate the practical impact and robustness.
Authors: We agree that the abstract would benefit from including key quantitative summaries. The full manuscript already reports metrics (e.g., nDCG and recall improvements), model-specific results, and computational overhead comparisons across rerankers. In the revision, we will update the abstract to include representative quantitative findings (such as average effectiveness gains), reference the presence of variability measures in the results, and ensure that error bars, ablation details, and any statistical tests are clearly highlighted in the main text and figures. revision: yes
Circularity Check
No circularity: empirical reproduction of external method on new benchmark
full rationale
The paper is a reproduction study applying the existing GAR method to the BRIGHT reasoning-intensive benchmark. No equations, derivations, fitted parameters, or predictions are introduced. All claims rest on empirical effectiveness metrics (e.g., retrieval performance across reranking models) rather than any self-referential construction. References to the original GAR work are external citations for the method being tested, not load-bearing self-citations or ansatzes smuggled in. The observation that reranker signal quality matters is presented as an empirical finding from the experiments, not a definitional or fitted tautology. The study is therefore self-contained against external benchmarks with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Akari Asai, Timo Schick, Patrick Lewis, Xilun Chen, Gautier Izacard, Sebastian Riedel, Hannaneh Hajishirzi, and Wen-tau Yih. 2023. Task-aware Retrieval with Instructions. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Can...
-
[3]
Sebastian Bruch, Siyu Gai, and Amir Ingber. 2023. An analysis of fusion functions for hybrid retrieval.ACM Transactions on Information Systems42, 1 (2023), 1–35
2023
-
[4]
Tao Chen, Mingyang Zhang, Jing Lu, Michael Bendersky, and Marc Najork. 2022. Out-of-domain semantics to the rescue! zero-shot hybrid retrieval models. In European Conference on Information Retrieval. Springer, 95–110
2022
-
[5]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Sahel Shar- ifymoghaddam, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, et al
-
[6]
InFirst Workshop on Multi-Turn Interactions in Large Language Models
BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent. InFirst Workshop on Multi-Turn Interactions in Large Language Models
-
[7]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval(Boston, MA, USA)(SIGIR ’09). Association for Computing Machinery, New York, NY, USA, 758–759...
-
[8]
Lachlan Dunn, Luke Gallagher, and Joel Mackenzie. 2025. Approximate Bag- of-Words Top-k Corpus Graphs. InAdvances in Information Retrieval, Claudia Hauff, Craig Macdonald, Dietmar Jannach, Gabriella Kazai, Franco Maria Nardini, Fabio Pinelli, Fabrizio Silvestri, and Nicola Tonellotto (Eds.). Springer Nature Switzerland, Cham, 174–182
2025
-
[9]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review arXiv 2024
- [10]
-
[11]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceed- ings of the 44th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval(<conf-loc>, <city>Virtual Event</city>, <coun- try>Canada</country>, </conf-loc>)(SIGIR ’21). Associati...
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
- [13]
-
[14]
Jardine and Cornelis Joost van Rijsbergen
N. Jardine and Cornelis Joost van Rijsbergen. 1971. The use of hierarchic clustering in information retrieval.Inf. Storage Retr.7, 5 (1971), 217–240. doi:10.1016/0020-0271(71)90051-9
-
[15]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Com...
- [16]
-
[17]
Jongho Kim, Jaeyoung Kim, Seung-won Hwang, Jihyuk Kim, Yu Jin Kim, and Moontae Lee. 2026. Adaptive Retrieval for Reasoning-Intensive Retrieval.arXiv preprint arXiv:2601.04618(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Hrishikesh Kulkarni, Nazli Goharian, Ophir Frieder, and Sean MacAvaney. 2024. LexBoost: Improving Lexical Document Retrieval with Nearest Neighbors. In Proceedings of the ACM Symposium on Document Engineering 2024(San Jose, CA, USA)(DocEng ’24). Association for Computing Machinery, New York, NY, USA, Article 16, 10 pages. doi:10.1145/3685650.3685658
-
[19]
Hrishikesh Kulkarni, Sean MacAvaney, Nazli Goharian, and Ophir Frieder. 2023. Lexically-Accelerated Dense Retrieval. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-Jou (Edward) Duh, Hen-Hsen Huang, Makoto P. Kato, Josiane Mo...
-
[20]
Junwei Lan, Jianlyu Chen, Zheng Liu, Chaofan Li, Siqi Bao, and Defu Lian
-
[21]
InThe Fourteenth International Conference on Learning Representations
Retro*: Optimizing LLMs for Reasoning-Intensive Document Retrieval. InThe Fourteenth International Conference on Learning Representations. https: //openreview.net/forum?id=0WGl8PNMSA
- [22]
-
[23]
Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. 2021. In-Batch Nega- tives for Knowledge Distillation with Tightly-Coupled Teachers for Dense Re- trieval. InProceedings of the 6th Workshop on Representation Learning for NLP, RepL4NLP@ACL-IJCNLP 2021, Online, August 6, 2021, Anna Rogers, Iacer Calixto, Ivan Vulic, Naomi Saphra, Nora Kassner, Oana-Maria Ca...
-
[24]
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine- tuning llama for multi-stage text retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2421–2425
2024
-
[25]
Sean MacAvaney, Franco Maria Nardini, Raffaele Perego, Nicola Tonellotto, Nazli Goharian, and Ophir Frieder. 2020. Expansion via Prediction of Importance with Contextualization. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Hua...
-
[26]
Sean MacAvaney, Nicola Tonellotto, and Craig Macdonald. 2022. Adaptive Re- Ranking with a Corpus Graph. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, Mohammad Al Hasan and Li Xiong (Eds.). ACM, 1491–1500. doi:10. 1145/3511808.3557231
-
[27]
Mackenzie, and Torsten Suel
Antonio Mallia, Michal Siedlaczek, Joel M. Mackenzie, and Torsten Suel. 2019. PISA: Performant Indexes and Search for Academia. InProceedings of the Open- Source IR Replicability Challenge co-located with 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, OSIRRC@SIGIR 2019, Paris, France, July 25, 2019 (CEUR Work...
2019
-
[28]
Niklas Muennighoff, Hongjin SU, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Aman- preet Singh, and Douwe Kiela. 2025. Generative Representational Instruction Tuning. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=BC4lIvfSzv
2025
-
[29]
Rodrigo Frassetto Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Document Ranking with a Pretrained Sequence-to-Sequence Model. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computationa...
2020
- [30]
-
[31]
Mandeep Rathee, Sean MacAvaney, and Avishek Anand. 2025. Guiding Retrieval Using LLM-Based Listwise Rankers. InAdvances in Information Retrieval, Claudia Hauff, Craig Macdonald, Dietmar Jannach, Gabriella Kazai, Franco Maria Nardini, Fabio Pinelli, Fabrizio Silvestri, and Nicola Tonellotto (Eds.). Springer Nature Switzerland, Cham, 230–246
2025
-
[32]
Mandeep Rathee, Sean MacAvaney, and Avishek Anand. 2025. Quam: Adaptive Retrieval through Query Affinity Modelling. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining(Hannover, Germany) (WSDM ’25). Association for Computing Machinery, New York, NY, USA, 954–962. doi:10.1145/3701551.3703584
-
[33]
Mandeep Rathee, Venktesh V, Sean MacAvaney, and Avishek Anand. 2025. Breaking the Lens of the Telescope: Online Relevance Estimation over Large Reproducing Adaptive Reranking for Reasoning-Intensive IR Conference’17, July 2017, Washington, DC, USA Retrieval Sets. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in I...
-
[34]
Stephen Robertson. 2008. On the history of evaluation in IR.J. Inf. Sci.34, 4 (2008), 439–456. doi:10.1177/0165551507086989
-
[35]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (apr 2009), 333–389. doi:10.1561/1500000019
-
[36]
Harrisen Scells, Shengyao Zhuang, and Guido Zuccon. 2022. Reduce, Reuse, Recycle: Green Information Retrieval Research. InProceedings of the 45th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2825–2837. doi:10.1145/3477495.3531766
-
[37]
Nilanjan Sinhababu, Andrew Parry, Debasis Ganguly, Debasis Samanta, and Pabitra Mitra. 2024. Few-shot Prompting for Pairwise Ranking: An Effective Non-Parametric Retrieval Model. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miam...
-
[38]
Hongjin SU, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han yu Wang, Liu Haisu, Quan Shi, Zachary S Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O Arik, Danqi Chen, and Tao Yu. 2025. BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval. InThe Thirteenth International Conference on Learning Representations....
2025
- [39]
-
[40]
Nandan Thakur, Jimmy Lin, Sam Havens, Michael Carbin, Omar Khattab, and Andrew Drozdov. 2025. FreshStack: Building Realistic Benchmarks for Evaluating Retrieval on Technical Documents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https: //openreview.net/forum?id=54TTgXlS2U
2025
-
[41]
Venktesh V, Mandeep Rathee, and Avishek Anand. 2025. SUNAR: Semantic Uncertainty based Neighborhood Aware Retrieval for Complex QA. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.)...
-
[42]
Lidan Wang, Jimmy Lin, and Donald Metzler. 2011. A cascade ranking model for efficient ranked retrieval. InProceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. 105–114
2011
-
[43]
Shuai Wang, Shengyao Zhuang, and Guido Zuccon. 2021. Bert-based dense retrievers require interpolation with bm25 for effective passage retrieval. In Proceedings of the 2021 ACM SIGIR international conference on theory of information retrieval. 317–324
2021
-
[44]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 248...
2022
-
[45]
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Ben- jamin Van Durme, Dawn Lawrie, and Luca Soldaini. 2025. FollowIR: Evalu- ating and Teaching Information Retrieval Models to Follow Instructions. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Languag...
-
[46]
Lawrie, Ashwin Paranjape, Yuhao Zhang, and Jack Hessel
Orion Weller, Benjamin Van Durme, Dawn J. Lawrie, Ashwin Paranjape, Yuhao Zhang, and Jack Hessel. 2025. Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=odvSjn416y
2025
- [47]
- [48]
-
[49]
Le Zhang, Bo Wang, Xipeng Qiu, Siva Reddy, and Aishwarya Agrawal. 2025. REARANK: Reasoning Re-ranking Agent via Reinforcement Learning. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics,...
2025
-
[50]
doi:10.18653/v1/2025.emnlp-main.125
-
[51]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[52]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review arXiv 2025
-
[53]
Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, and Guido Zuccon
-
[54]
Rank-r1: Enhancing reasoning in llm-based document rerankers via reinforcement learning, 2025
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning. arXiv:2503.06034 [cs.IR] https://arxiv.org/abs/2503. 06034
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.