Recognition: unknown
Assessing Pancreatic Ductal Adenocarcinoma Vascular Invasion: the PDACVI Benchmark
Pith reviewed 2026-05-07 09:55 UTC · model grok-4.3
The pith
Methods that model expert disagreement produce more reliable vascular invasion maps for pancreatic cancer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A densely annotated dataset with five independent expert annotations per case, paired with an evaluation framework that combines volumetric metrics, probabilistic calibration, and interface-specific analysis, demonstrates that uncertainty-aware methods outperform binary segmentation approaches by maintaining performance in low-consensus ambiguous regions.
What carries the argument
The multi-annotation dataset that captures inter-rater variability at tumor-vessel boundaries, used within a multi-metric framework to separate global accuracy from localized clinical utility.
Load-bearing premise
The five independent expert annotations faithfully capture diagnostic ambiguity at tumor-vessel interfaces and the multi-metric framework reflects surgical decision utility.
What would settle it
A validation study in which uncertainty-modeling methods fail to demonstrate superior calibration or robustness when compared to binary methods against actual surgical findings or additional expert consensus.
Figures





read the original abstract
Surgical resection remains the only potentially curative treatment for pancreatic ductal adenocarcinoma (PDAC), and eligibility depends on accurate assessment of vascular invasion (VI), i.e., tumor extension into adjacent critical vessels. Despite its importance for preoperative staging and surgical planning, computational VI assessment remains underexplored. Two major challenges are the lack of public datasets and the diagnostic ambiguity at the tumor-vessel interface, which leads to substantial inter-rater variability even among expert radiologists. To address these limitations, we introduce the CURVAS-PDACVI Dataset and Challenge, an open benchmark for uncertainty-aware AI in PDAC staging based on a densely annotated dataset with five independent expert annotations per scan. We also propose a multi-metric evaluation framework that extends beyond spatial overlap to include probabilistic calibration and VI assessment. Evaluation of six state-of-the-art methods shows that strong global volumetric overlap does not necessarily translate into reliable performance at clinically critical tumor-vessel interfaces. In particular, methods optimized for binary segmentation perform competitively on average overlap metrics, but often degrade in high-complexity cases with low expert consensus, either collapsing in volume or overextending at uncertain boundaries. In contrast, methods that model inter-rater disagreement produce better calibrated probabilistic maps and show greater robustness in these ambiguous cases. The benchmark highlights the limitations of volumetric accuracy as a proxy for localized surgical utility, motivating uncertainty-aware probabilistic models for preoperative decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CURVAS-PDACVI Dataset and Challenge, an open benchmark consisting of CT scans for pancreatic ductal adenocarcinoma (PDAC) vascular invasion (VI) assessment, each with five independent expert annotations to capture inter-rater variability at tumor-vessel interfaces. It proposes a multi-metric evaluation framework extending beyond volumetric overlap to include probabilistic calibration and localized interface-specific metrics. Evaluation of six state-of-the-art methods demonstrates that binary segmentation approaches achieve competitive global overlap but degrade in high-ambiguity cases, whereas disagreement-modeling methods yield better-calibrated probabilistic maps and greater robustness at uncertain boundaries. The work concludes that standard overlap metrics are poor proxies for localized surgical utility and motivates uncertainty-aware models for preoperative staging.
Significance. If the empirical comparisons hold, this provides a valuable public resource addressing the scarcity of densely annotated datasets for PDAC VI, a clinically critical task determining surgical resectability. The multi-annotation design and extended metrics (calibration plus interface assessment) are strengths that enable more nuanced benchmarking than typical Dice-focused evaluations. The findings offer concrete evidence favoring probabilistic modeling in ambiguous medical segmentation scenarios, with potential to guide development of AI tools that better reflect diagnostic uncertainty.
major comments (2)
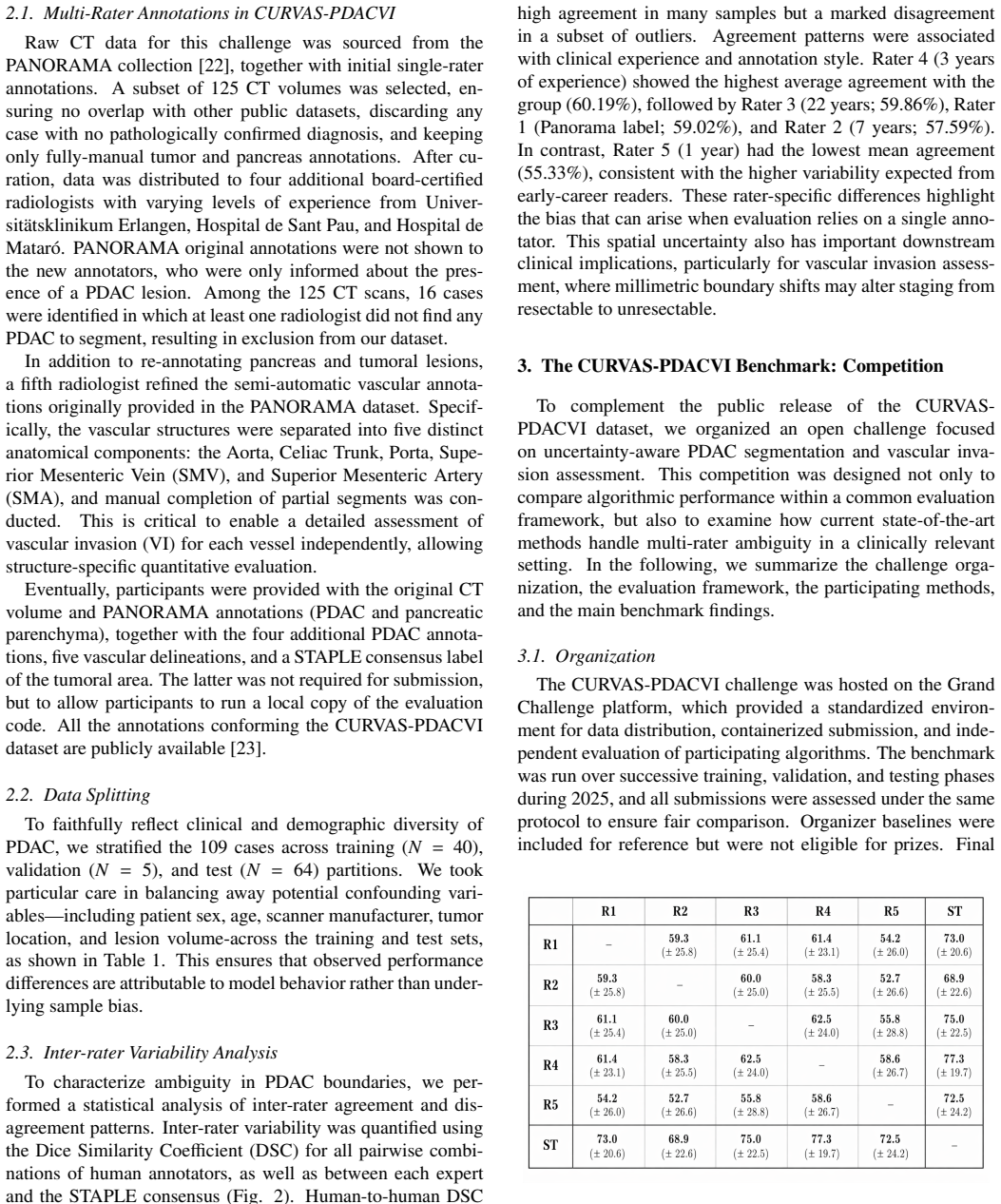
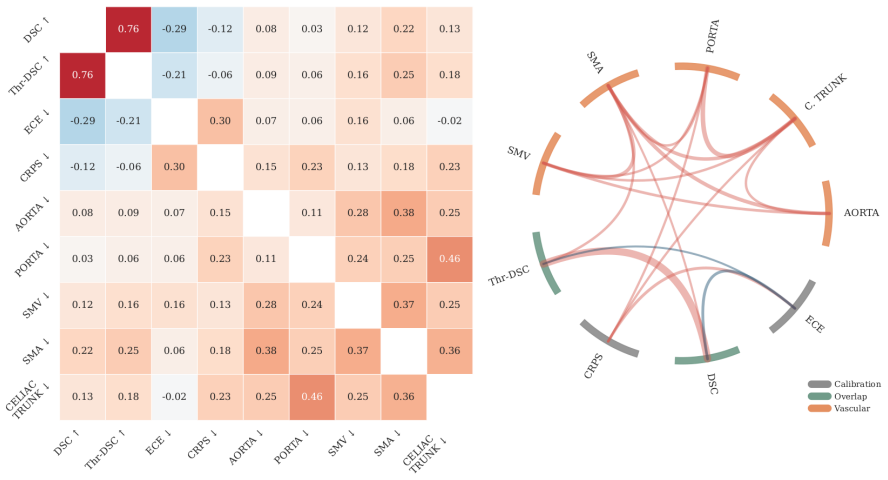
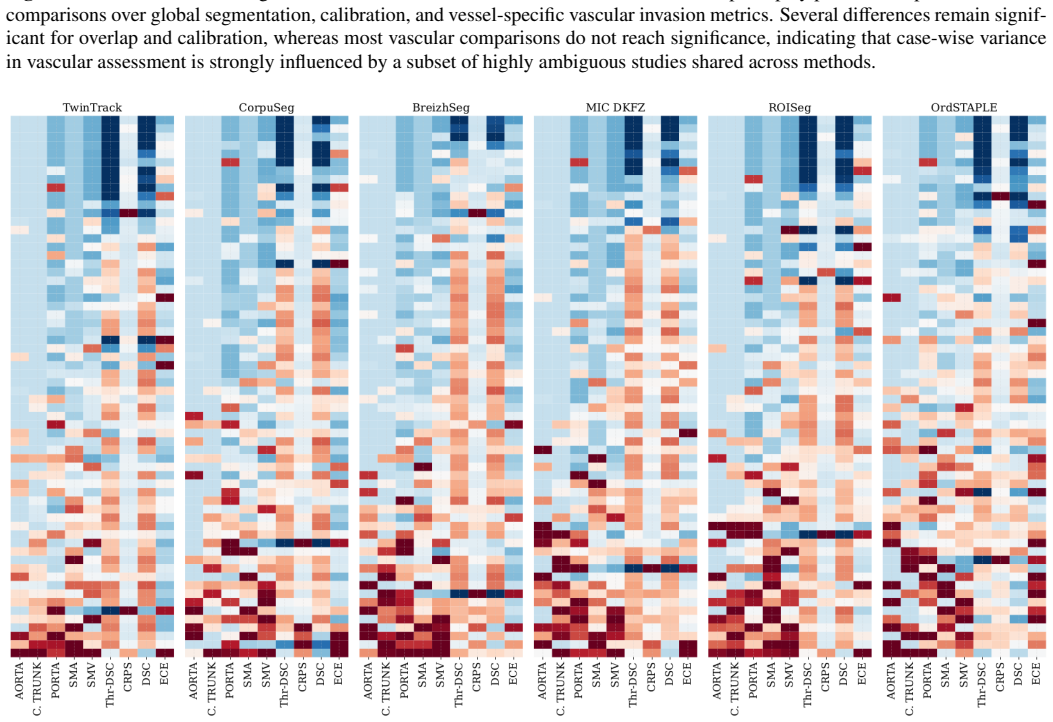
- Abstract and Results: The central claim that disagreement-modeling methods produce better calibrated maps and greater robustness at tumor-vessel interfaces depends on the multi-metric framework serving as a valid proxy for surgical decision utility. However, all evaluations are performed solely against the five expert annotations (majority vote or soft labels) with no external anchor such as actual surgical findings, resectability outcomes, or surgeon decision thresholds; this leaves open whether superior calibration reflects true VI status or merely annotation distribution matching.
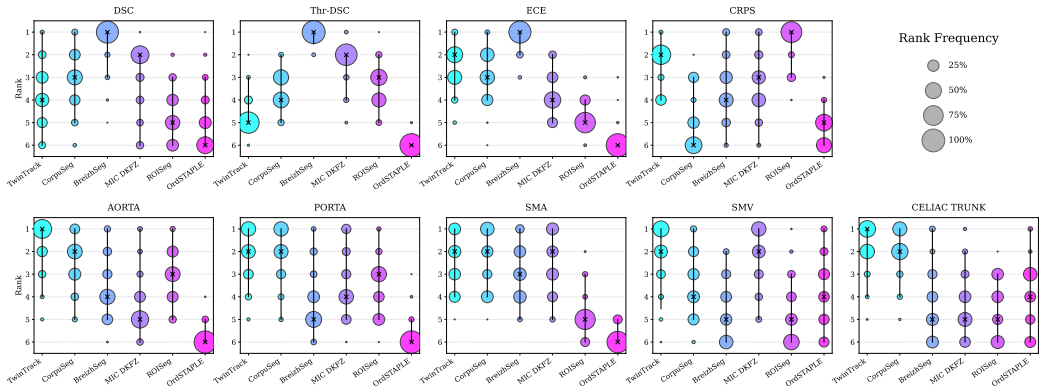
- Methods and Results: The selection and definition of 'high-complexity cases with low expert consensus' is not accompanied by explicit quantitative criteria, exclusion rules, or the number of such cases; without these details, the reported degradation of binary methods versus robustness of uncertainty-aware methods cannot be fully assessed for reproducibility or generalizability.
minor comments (3)
- Abstract: Inclusion of at least one or two concrete quantitative results (e.g., specific calibration error values or interface metric differences across the six methods) would strengthen the summarized comparative findings.
- The paper should clarify the exact implementation of the probabilistic calibration metric and interface-specific scores, including any hyperparameters or thresholds used.
- Ensure the dataset release includes clear documentation on annotation protocol, imaging parameters, and patient inclusion criteria to maximize utility for the community.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract and Results: The central claim that disagreement-modeling methods produce better calibrated maps and greater robustness at tumor-vessel interfaces depends on the multi-metric framework serving as a valid proxy for surgical decision utility. However, all evaluations are performed solely against the five expert annotations (majority vote or soft labels) with no external anchor such as actual surgical findings, resectability outcomes, or surgeon decision thresholds; this leaves open whether superior calibration reflects true VI status or merely annotation distribution matching.
Authors: We agree that direct validation against surgical outcomes or resectability data would provide stronger evidence of clinical utility. The current benchmark relies on multi-expert annotations to quantify inter-rater variability at ambiguous tumor-vessel interfaces, which is a core clinical challenge. The extended metrics (calibration and interface-specific) are designed to evaluate how well models reflect this uncertainty rather than assuming a single ground truth. We will revise the abstract, results, and discussion sections to explicitly frame these as annotation-based proxies and to note the absence of outcome-level validation as a limitation, while highlighting it as an important direction for future work. No new external data can be added at this stage. revision: partial
-
Referee: Methods and Results: The selection and definition of 'high-complexity cases with low expert consensus' is not accompanied by explicit quantitative criteria, exclusion rules, or the number of such cases; without these details, the reported degradation of binary methods versus robustness of uncertainty-aware methods cannot be fully assessed for reproducibility or generalizability.
Authors: We appreciate this observation and agree that explicit criteria are required. In the revised manuscript, we will expand the Methods section to define high-complexity cases using precise quantitative measures of inter-annotator disagreement (such as average pairwise overlap or voxel-wise entropy thresholds), specify any exclusion rules applied during case selection, and report the exact number of such cases within the dataset. These details will also be referenced in the Results when discussing performance differences, enabling full reproducibility and assessment of generalizability. revision: yes
- The absence of external validation against actual surgical findings, resectability outcomes, or surgeon decision thresholds, as this data is not part of the current benchmark dataset.
Circularity Check
No circularity: purely empirical benchmark with independent evaluation against held-out annotations
full rationale
This is an empirical benchmark paper introducing a dataset (CURVAS-PDACVI) with five expert annotations per case and a multi-metric framework (overlap, probabilistic calibration, interface-specific scores). All performance claims are measured directly against these external annotations as ground truth, with no equations, fitted parameters, derivations, or self-referential reductions. Methods are compared on held-out data; superior calibration or robustness in ambiguous cases is reported as an observed empirical outcome rather than derived by construction from the inputs. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the central results. The evaluation framework is defined independently of the tested methods and does not reduce to renaming or fitting the same quantities it claims to predict.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Five independent expert annotations per scan capture the diagnostic ambiguity at tumor-vessel interfaces
- domain assumption The multi-metric framework (volumetric overlap plus probabilistic calibration plus interface assessment) reflects surgical decision-making utility
Reference graph
Works this paper leans on
-
[1]
H. Sun, H. Ma, G. Hong, H. Sun, J. Wang, Survival improvement in patients with pancreatic cancer by decade: A period analysis of the SEER database, 1981–2010, Scientific Reports 4 (2014) 6747.doi: 10.1038/srep06747. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC5381379/
-
[2]
M. Br ¨ugel, E. J. Rummeny, M. Dobritz, Vascular invasion in pancre- atic cancer, Abdominal Imaging 29 (2) (2004) 239–245.doi:10.1007/ s00261-003-0102-2. URLhttps://doi.org/10.1007/s00261-003-0102-2
-
[3]
L. Yao, Z. Zhang, E. Keles, C. Yazici, T. Tirkes, U. Bagci, A review of deep learning and radiomics approaches for pancreatic cancer diagno- sis from medical imaging, Current Opinion in Gastroenterology 39 (5) (2023) 436–447.doi:10.1097/MOG.0000000000000966
-
[4]
Z. Alidina, A. A. M. Hussain, I. Banani, M. M. Khan, T. M. Pawlik, Ra- diomics for early detection of pancreatic cancer: a systematic review and meta-analysis, Journal of Gastrointestinal Surgery 30 (5) (2026) 102374. doi:10.1016/j.gassur.2026.102374. URLhttps://www.sciencedirect.com/science/article/pii/ S1091255X26000557
-
[5]
Y . Xia, Q. Yu, W. Shen, Y . Zhou, E. K. Fishman, A. L. Yuille, Detecting Pancreatic Ductal Adenocarcinoma in Multi-phase CT Scans via Align- ment Ensemble, in: A. L. Martel, P. Abolmaesumi, D. Stoyanov, D. Ma- teus, M. A. Zuluaga, S. K. Zhou, D. Racoceanu, L. Joskowicz (Eds.), Medical Image Computing and Computer Assisted Intervention – MIC- CAI 2020, Sp...
-
[6]
J. Zhao, J. Wang, Y . Gu, X. Huang, L. Wang, Diagnostic methods for pan- creatic cancer and their clinical applications (Review), Oncology Letters 30 (1) (2025) 370.doi:10.3892/ol.2025.15116. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC12150009/
-
[7]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, K. H. Maier-Hein, nnU- Net: a self-configuring method for deep learning-based biomedical image segmentation, Nature Methods 18 (2) (2021) 203–211.doi:10.1038/ s41592-020-01008-z
2021
-
[8]
J. I. Bereska, B. V . Janssen, C. Y . Nio, M. P. M. Kop, G. Kazemier, O. R. Busch, F. Struik, H. A. Marquering, J. Stoker, M. G. Besselink, I. M. Verpalen, for the Pancreatobiliary and Hepatic Artificial Intelli- gence Research (PHAIR) consortium, Artificial intelligence for assess- ment of vascular involvement and tumor resectability on CT in patients wi...
-
[9]
A. Jungo, R. Meier, E. Ermis, M. Blatti-Moreno, E. Herrmann, R. Wiest, M. Reyes, On the Effect of Inter-observer Variability for a Reliable Esti- mation of Uncertainty of Medical Image Segmentation, in: A. F. Frangi, J. A. Schnabel, C. Davatzikos, C. Alberola-L ´opez, G. Fichtinger (Eds.), Medical Image Computing and Computer Assisted Intervention – MIC- ...
-
[10]
L. Joskowicz, D. Cohen, N. Caplan, J. Sosna, Inter-observer variability of manual contour delineation of structures in CT, European Radiology 29 (3) (2019) 1391–1399.doi:10.1007/s00330-018-5695-5
-
[11]
N. C. Buchs, M. Chilcott, P.-A. Poletti, L. H. Buhler, P. Morel, Vascular invasion in pancreatic cancer: Imaging modalities, preoperative diagno- sis and surgical management, World Journal of Gastroenterology : WJG 16 (7) (2010) 818–831.doi:10.3748/wjg.v16.i7.818. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC2825328/
-
[12]
R. K. G. Do, A. Kambadakone, Radiomics for CT Assessment of Vascular Contact in Pancreatic Adenocarcinoma, Radiology 301 (3) (2021) 623–624, publisher: Radiological Society of North America. doi:10.1148/radiol.2021211635. URLhttps://pubs.rsna.org/doi/full/10.1148/radiol. 2021211635
-
[13]
S. Warfield, K. Zou, W. Wells, Simultaneous truth and performance level estimation (STAPLE): an algorithm for the validation of image segmen- tation, IEEE Transactions on Medical Imaging 23 (7) (2004) 903–921. doi:10.1109/TMI.2004.828354. URLhttps://ieeexplore.ieee.org/document/1309714
-
[14]
M. H. Jensen, D. R. Jørgensen, R. Jalaboi, M. E. Hansen, M. A. Olsen, Improving Uncertainty Estimation in Convolutional Neural Networks Us- ing Inter-rater Agreement, in: D. Shen, T. Liu, T. M. Peters, L. H. Staib, C. Essert, S. Zhou, P.-T. Yap, A. Khan (Eds.), Medical Image Com- puting and Computer Assisted Intervention – MICCAI 2019, Springer Internatio...
2019
-
[15]
C. H. Sudre, B. G. Anson, S. Ingala, C. D. Lane, D. Jimenez, L. Haider, T. Varsavsky, R. Tanno, L. Smith, S. Ourselin, R. H. J ¨ager, M. J. Car- doso, Let’s Agree to Disagree: Learning Highly Debatable Multirater La- belling, in: D. Shen, T. Liu, T. M. Peters, L. H. Staib, C. Essert, S. Zhou, P.-T. Yap, A. Khan (Eds.), Medical Image Computing and Computer...
-
[16]
J. Zhang, Y . Zheng, Y . Shi, A Soft Label Method for Medical Image Seg- mentation with Multirater Annotations, Computational Intelligence and Neuroscience 2023 (2023) 1883597.doi:10.1155/2023/1883597
-
[17]
M. Islam, B. Glocker, Spatially Varying Label Smoothing: Capturing Un- certainty from Expert Annotations, in: A. Feragen, S. Sommer, J. Schn- abel, M. Nielsen (Eds.), Information Processing in Medical Imaging, Springer International Publishing, Cham, 2021, pp. 677–688.doi: 10.1007/978-3-030-78191-0_52
-
[18]
M. Riera-Mar ´ın, J. G. L ´opez, J. Rodr ´ıguez-Comas, M. A. G. Ballester, A. Galdran, Multi-Rater Calibration Error Estimation, in: C. H. Sudre, M. I. Hoque, R. Mehta, C. Ouyang, C. Qin, M. Rakic, W. M. Wells (Eds.), Uncertainty for Safe Utilization of Machine Learning in Med- ical Imaging, Springer Nature Switzerland, Cham, 2026, pp. 147–157. doi:10.100...
- [19]
-
[20]
H. K. Yang, M.-S. Park, M. Choi, J. Shin, S. S. Lee, W. K. Jeong, S. H. Hwang, S. H. Choi, Systematic review and meta-analysis of diag- nostic performance of CT imaging for assessing resectability of pancre- atic ductal adenocarcinoma after neoadjuvant therapy: importance of CT criteria, Abdominal Radiology (New York) 46 (11) (2021) 5201–5217. doi:10.1007...
-
[21]
Y . N. Shen, X. L. Bai, G. G. Li, T. B. Liang, Review of radiological classifications of pancreatic cancer with peripancreatic vessel invasion: are new grading criteria required?, Cancer Imaging 17 (2017) 14.doi: 10.1186/s40644-017-0115-7. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC5420088/
-
[22]
N. Alves, M. Schuurmans, D. Rutkowski, D. Yakar, I. Haldorsen, M. Liedenbaum, A. Molven, P. Vendittelli, G. Litjens, J. Hermans, H. Huisman, The PANORAMA Study Protocol: Pancreatic Cancer Di- agnosis - Radiologists Meet AI, Tech. rep., Zenodo (Jan. 2024).doi: 10.5281/zenodo.10599559. URLhttps://zenodo.org/records/10599559
-
[23]
CURVAS-PDACVI : A pancreatic ductal adenocarcinoma imaging dataset, November 2025
M. Riera-Mar ´ın, S. O K, M. M. Duh, A. Aubanell, R. de Figueiredo Car- doso, S. Egger-Hackenschmidt, M. S. May, S. Bernaus Tom ´e, J. Rodr´ıguez-Comas, M. ´A. Gonz´alez Ballester, J. Garcia L´opez, Curvas- pdacvi dataset (Nov. 2025).doi:10.5281/zenodo.17552201. URLhttps://doi.org/10.5281/zenodo.17552201
-
[24]
TwinTrack: Post-hoc Multi-Rater Calibration for Medical Image Segmentation
T. Kirscher, A. Ertl, K. Maier-Hein, X. Coubez, P. Meyer, S. Faisan, Twin- Track: Post-hoc Multi-Rater Calibration for Medical Image Segmenta- tion, arXiv:2604.15950 [cs] (Apr. 2026).doi:10.48550/arXiv.2604. 10 15950. URLhttp://arxiv.org/abs/2604.15950
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604 2026
-
[25]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, C. Blundell, Simple and scalable pre- dictive uncertainty estimation using deep ensembles, in: Proceedings of the 31st International Conference on Neural Information Processing Sys- tems, NIPS’17, Curran Associates Inc., Red Hook, NY , USA, 2017, pp. 6405–6416
2017
-
[26]
M. P. Naeini, G. F. Cooper, M. Hauskrecht, Obtaining well calibrated probabilities using bayesian binning, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, AAAI Press, Austin, Texas, 2015, pp. 2901–2907
2015
-
[27]
R. E. Barlow, D. J. Bartholomew, J. M. Bremner, H. D. Brunk, Statistical inference under order restric- tions, Statistica Neerlandica 27 (4) (1973) 189–189, eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1467- 9574.1973.tb00228.x.doi:10.1111/j.1467-9574.1973.tb00228. x. URLhttps://onlinelibrary.wiley.com/doi/abs/10.1111/j. 1467-9574.1973.tb00228.x
-
[28]
Vbench: Comprehensive benchmark suite for video generative models
G. Franchi, O. Laurent, M. Legu ´ery, A. Bursuc, A. Pilzer, A. Yao, Make Me a BNN: A Simple Strategy for Estimating Bayesian Uncertainty from Pre-trained Models, in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 12194–12204, iSSN: 2575- 7075.doi:10.1109/CVPR52733.2024.01159. URLhttps://ieeexplore.ieee.org/document/10656702
-
[29]
C. H ´emon, B. Texier, C. Lafond, J.-C. Nunes, A. Barateau, Towards trustworthy AI in radiotherapy: a comprehensive review of uncertainty- aware techniques, Physics in Medicine and Biology 71 (1) (Dec. 2025). doi:10.1088/1361-6560/ae2a9f
-
[30]
URLhttps://github.com/SYCAI-Technologies/ curvas-challenge/tree/main/CURVAS-PDACVI_2025
curvas-challenge/CURV AS-PDACVI 2025 at main · SYCAI- Technologies/curvas-challenge (2025). URLhttps://github.com/SYCAI-Technologies/ curvas-challenge/tree/main/CURVAS-PDACVI_2025
2025
-
[31]
Appendix 6.1. Dataset Supplementary Details The original PANORAMA CT scans used in this work are available athttps://zenodo.org/records/11034178, and the CURV AS-PDACVI benchmark release, including the multi-rater annotations and evaluation resources, is available at https://zenodo.org/records/15401568. In the released repository, each case follows a stan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.