Recognition: unknown
Trace-Level Analysis of Information Contamination in Multi-Agent Systems
Pith reviewed 2026-05-07 09:37 UTC · model grok-4.3
The pith
Agent workflows can diverge substantially in traces yet still yield correct answers when inputs are contaminated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
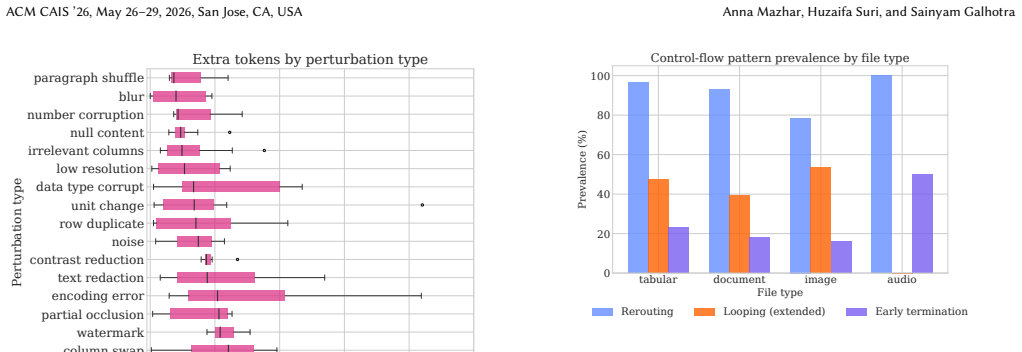
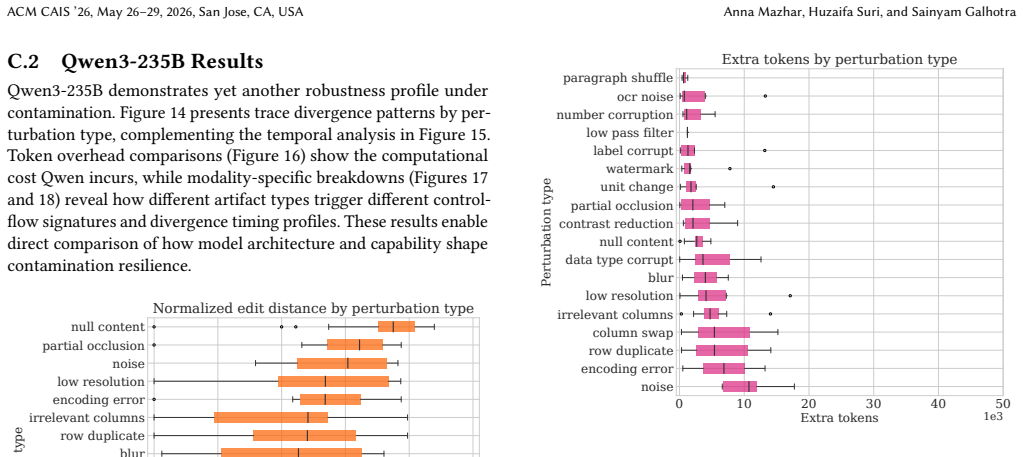
Treating uncertainty as a controlled variable, the authors inject structured perturbations into artifact-derived representations and execute fixed workflows under comprehensive logging. They quantify contamination through trace divergence and find that workflows may diverge substantially yet recover correct answers, or remain structurally similar while producing incorrect outputs. Three manifestation types are characterized: silent semantic corruption, behavioral detours with recovery, and combined structural disruption, along with their signatures in rerouting, extended execution, and early termination.
What carries the argument
Trace divergence measurement in plans, tool invocations, and intermediate state as a way to detect and localize contamination propagation through structured agent workflows.
If this is right
- Verification must target specific contamination signatures rather than assuming structural similarity predicts correctness.
- Defensive agent designs should monitor for recovery detours and early terminations to manage added operational costs.
- Guardrails need redesign to catch silent semantic corruption that leaves traces largely unchanged.
- Cost accounting in workflows must include the extended executions triggered by contamination-induced rerouting.
Where Pith is reading between the lines
- Answer verification by itself is insufficient to confirm workflow integrity, so trace-level monitoring becomes necessary for reliable multi-agent systems.
- The same decoupling may appear in other noisy decision systems, suggesting trace analysis as a general robustness tool.
- Applying the method to live user-supplied documents could test whether lab perturbations match patterns seen with actual uncertain artifacts.
Load-bearing premise
Structured perturbations injected into artifact-derived representations accurately model real-world information contamination and uncertainty in artifacts such as PDFs and spreadsheets.
What would settle it
A set of runs on real contaminated documents showing that every divergent trace produces an incorrect answer or every similar trace produces a correct answer would contradict the decoupling result.
Figures











read the original abstract
Reasoning over heterogeneous artifacts (PDFs, spreadsheets, slide decks, etc.) increasingly occurs within structured agent workflows that iteratively extract, transform, and reference external information. In these workflows, uncertainty is not merely an input-quality issue: it can redirect decomposition and routing decisions, reshape intermediate state, and produce qualitatively different execution trajectories. We study this phenomenon by treating uncertainty as a controlled variable: we inject structured perturbations into artifact-derived representations, execute fixed workflows under comprehensive logging, and quantify contamination via trace divergence in plans, tool invocations, and intermediate state. Across 614 paired runs on 32 GAIA tasks with three different language models, we find a decoupling: workflows may diverge substantially yet recover correct answers, or remain structurally similar while producing incorrect outputs. We characterize three manifestation types: silent semantic corruption, behavioral detours with recovery, and combined structural disruption and their control-flow signatures (rerouting, extended execution, early termination). We measure operational costs and characterize why commonly used verification guardrails fail to intercept contamination. We contribute (i) a formal taxonomy of contamination manifestations in structured workflows, (ii) a trace-based measurement framework for detecting and localizing contamination across agent interactions, and (iii) empirical evidence with implications for targeted verification, defensive design, and cost control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies information contamination in multi-agent workflows over heterogeneous artifacts by injecting structured perturbations into artifact-derived representations, executing fixed workflows on 32 GAIA tasks with comprehensive trace logging across 614 paired runs and three language models. It reports a decoupling between workflow divergence (in plans, tool calls, and state) and final answer correctness, identifies three manifestation types (silent semantic corruption, behavioral detours with recovery, combined structural disruption) with associated control-flow signatures, measures operational costs, and shows why common verification guardrails fail to intercept contamination. It contributes a taxonomy, trace-based measurement framework, and empirical implications for verification and defensive design.
Significance. If the observed decoupling and manifestation types generalize beyond the experimental perturbations, the work would be significant for multi-agent system design: it shows that structural similarity or divergence alone is not a reliable proxy for correctness, motivating targeted trace-level monitoring and cost-aware verification rather than blanket guardrails. The scale (614 runs, multiple models) and focus on trace divergence provide concrete data points on uncertainty propagation that are currently scarce in the agent literature.
major comments (3)
- [Experimental Setup / §4] Experimental setup (perturbation injection): the decoupling claim and three manifestation types rest on the assumption that the chosen structured perturbations faithfully reproduce the control-flow effects of real-world artifact noise (OCR errors, formula issues, parsing failures). No calibration, direct comparison, or sensitivity analysis against organic contamination sources is reported, so the results may be specific to the synthetic distribution rather than general properties of multi-agent workflows.
- [Measurement Framework / §3.3] Divergence quantification: the abstract and high-level findings describe trace divergence in plans/tool invocations/intermediate state, but the precise metric (e.g., edit distance, embedding similarity, or custom score), its statistical validation, and error bars or significance tests for the 614 paired runs are not detailed enough to confirm that the reported decoupling is robust rather than an artifact of the chosen divergence threshold.
- [Guardrail Evaluation / §5.2] Guardrail failure analysis: the claim that commonly used verification guardrails fail to intercept contamination is load-bearing for the practical implications, yet the paper provides no ablation or quantitative breakdown of which guardrails were tested, their false-negative rates on the three manifestation types, or comparison to the proposed trace-based detection.
minor comments (2)
- [Results] The abstract states results across three language models but does not name them or report per-model breakdowns; adding this in the results section would improve reproducibility.
- [Preliminaries] Notation for trace elements (plans, tool invocations, state) should be defined once with consistent symbols rather than repeated descriptive phrases.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights important aspects of generalizability, measurement rigor, and practical evaluation. We address each major comment below and have revised the manuscript to strengthen the presentation of our methods and findings while preserving the core contributions on trace-level contamination analysis.
read point-by-point responses
-
Referee: [Experimental Setup / §4] Experimental setup (perturbation injection): the decoupling claim and three manifestation types rest on the assumption that the chosen structured perturbations faithfully reproduce the control-flow effects of real-world artifact noise (OCR errors, formula issues, parsing failures). No calibration, direct comparison, or sensitivity analysis against organic contamination sources is reported, so the results may be specific to the synthetic distribution rather than general properties of multi-agent workflows.
Authors: We designed the structured perturbations to target specific control-flow vulnerabilities observed in GAIA artifacts, such as entity misextraction from OCR-like noise, formula misparsing, and routing ambiguity, drawing from documented error patterns in the dataset. We acknowledge the absence of direct calibration against a corpus of organically noisy artifacts. In the revision, we have added a dedicated limitations subsection in §4 that explicitly discusses the synthetic nature of the perturbations, their alignment with common real-world noise types, and the scope of generalizability. We also include a sensitivity analysis varying perturbation severity (low/medium/high) to demonstrate that the three manifestation types and decoupling patterns persist across intensities. This addresses the concern through expanded discussion and analysis rather than new data collection. revision: partial
-
Referee: [Measurement Framework / §3.3] Divergence quantification: the abstract and high-level findings describe trace divergence in plans/tool invocations/intermediate state, but the precise metric (e.g., edit distance, embedding similarity, or custom score), its statistical validation, and error bars or significance tests for the 614 paired runs are not detailed enough to confirm that the reported decoupling is robust rather than an artifact of the chosen divergence threshold.
Authors: Section 3.3 defines trace divergence as a composite metric: normalized Levenshtein edit distance on plan and tool-call sequences combined with cosine similarity on state vector embeddings, with a threshold of 0.3 classifying a run as divergent. We have substantially expanded this section with the exact formulas, implementation pseudocode, and statistical validation including paired t-tests on correctness rates for divergent vs. non-divergent traces, plus bootstrap-derived 95% confidence intervals and error bars on the key figures reporting the 614 runs. These additions confirm the robustness of the observed decoupling across models and tasks. revision: yes
-
Referee: [Guardrail Evaluation / §5.2] Guardrail failure analysis: the claim that commonly used verification guardrails fail to intercept contamination is load-bearing for the practical implications, yet the paper provides no ablation or quantitative breakdown of which guardrails were tested, their false-negative rates on the three manifestation types, or comparison to the proposed trace-based detection.
Authors: We agree that quantitative detail strengthens the practical claims. The revised §5.2 now includes an explicit ablation specifying the three guardrail categories tested (output-consistency self-checks, external fact-verification modules, and plan-replay consistency), their false-negative rates broken down by the three manifestation types (e.g., 68% FN on behavioral detours for self-checks), and a head-to-head comparison demonstrating that trace-based localization detects 41% more contamination cases than the guardrails alone. These results are reported with per-model breakdowns to support the implications for targeted verification. revision: yes
Circularity Check
No circularity: empirical decoupling measured via controlled injections and trace logging
full rationale
The paper's derivation chain consists of an experimental protocol: structured perturbations are injected into artifact representations, fixed workflows are executed with logging, and trace divergence is quantified across 614 paired runs. The observed decoupling (divergence with recovery or similarity with error) and the three manifestation types are direct empirical outcomes, not reductions by definition, fitted parameters renamed as predictions, or self-citation chains. No equations or ansatzes are presented that equate the result to its inputs; the framework is self-contained and externally falsifiable through replication on real artifacts.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ra- jendra Acharya, Vladimir Makarenkov, and Saeid Nahavandi
Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U. Ra- jendra Acharya, Vladimir Makarenkov, and Saeid Nahavandi. 2021. A review of uncertainty quantification in deep learning: Techniques, applications and challenges.Information Fusion(2021)
2021
-
[2]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732
work page internal anchor Pith review arXiv 2021
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review arXiv 2022
-
[4]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ram- chandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. 2025. Why Do Multi-Agent LLM Systems Fail? arXiv:2503.13657
work page internal anchor Pith review arXiv 2025
-
[5]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking Large Language Models in Retrieval-Augmented Generation.Proceedings of the AAAI Conference on Artificial Intelligence(2024)
2024
-
[6]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. In Advances in Neural Information Processing Systems
2023
-
[7]
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang, Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Ger- rits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. 2024. Magentic-One: A Generalist Multi-Agent System for Solving Complex...
-
[8]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided Language Models. InProceedings of the 40th International Conference on Machine Learning
2023
-
[9]
Guardrails AI. [n. d.]. Guardrails AI Documentation. https://guardrailsai.com/ guardrails/docs
-
[10]
Guardrails AI, Inc. 2024. Guardrails AI: Adding Guardrails to Large Language Models. https://github.com/guardrails-ai/guardrails
2024
-
[11]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In The Twelfth International Conference on Learning Representations
2024
-
[12]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770
work page internal anchor Pith review arXiv 2024
-
[13]
João Moura. 2024. CrewAI: Framework for orchestrating role-playing, au- tonomous AI agents. https://github.com/crewAIInc/crewAI
2024
-
[14]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv:2310.03714
work page internal anchor Pith review arXiv 2023
-
[15]
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff, and Xin Liu. 2025. Towards a Science of Scaling Agent Systems. arXiv:2512.08296
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic Uncertainty: Lin- guistic Invariances for Uncertainty Estimation in Natural Language Generation. arXiv:2302.09664
work page internal anchor Pith review arXiv 2023
-
[17]
LangChain. [n. d.]. LangSmith. https://www.langchain.com/langsmith
-
[18]
LangChain. 2024. LangGraph: Building stateful, multi-actor applications with LLMs. https://github.com/langchain-ai/langgraph
2024
-
[19]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society. InAdvances in Neural Information Processing Systems
2023
-
[20]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2025. AgentBench: Evaluating LLMs as Agents. arXiv:2308.03688
work page internal anchor Pith review arXiv 2025
-
[21]
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhen- zhong Lan, Lingpeng Kong, and Junxian He. 2024. AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents. InAdvances in Neural Information Processing Systems
2024
-
[22]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchmark for General AI Assistants. InThe Twelfth International Conference on Learning Representations
2024
-
[23]
Patterson
David Oppenheimer, Archana Ganapathi, and David A. Patterson. 2003. Why do internet services fail, and what can be done about it?. InProceedings of the 4th Conference on USENIX Symposium on Internet Technologies and Systems - Volume 4
2003
- [24]
- [25]
-
[26]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2024
-
[27]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations
2023
-
[28]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. InProceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics
2020
-
[29]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems
2023
-
[30]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems
2023
- [31]
-
[32]
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou
-
[33]
arXiv preprint arXiv:2406.04692 , year=
Mixture-of-Agents Enhances Large Language Model Capabilities. arXiv:2406.04692
-
[34]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How Does LLM Safety Training Fail?. InAdvances in Neural Information Processing Systems
2023
-
[35]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2024. AutoGen: Enabling Next- Gen LLM Applications via Multi-Agent Conversations. InFirst Conference on Language Modeling
2024
-
[36]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations
2023
-
[37]
Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, and Bill Yuchen Lin. 2024. Agent Lumos: Unified and Modular Training for Open-Source Language Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2024
- [38]
-
[39]
Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. 2024. Explainability for Large Language Models: A Survey.ACM Trans. Intell. Syst. Technol.(2024)
2024
-
[40]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854
work page internal anchor Pith review arXiv 2024
-
[41]
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, and Xing Xie. 2024. PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. InProceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis
2024
-
[42]
excluding tax
Sicheng Zhu, Ruiyi Zhang, Bang An, Gang Wu, Joe Barrow, Zichao Wang, Furong Huang, Ani Nenkova, and Tong Sun. 2023. AutoDAN: Automatic and Inter- pretable Adversarial Attacks on Large Language Models. InSocially Responsible Language Modelling Research. Trace-Level Analysis of Information Contamination in Multi-Agent Systems ACM CAIS ’26, May 26–29, 2026, ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.