Recognition: unknown
Purifying Multimodal Retrieval: Fragment-Level Evidence Selection for RAG
Pith reviewed 2026-05-07 07:12 UTC · model grok-4.3
The pith
Selecting sentence-level text and region-level image fragments rather than whole documents improves multimodal RAG by up to 27 percent CIDEr while shortening context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
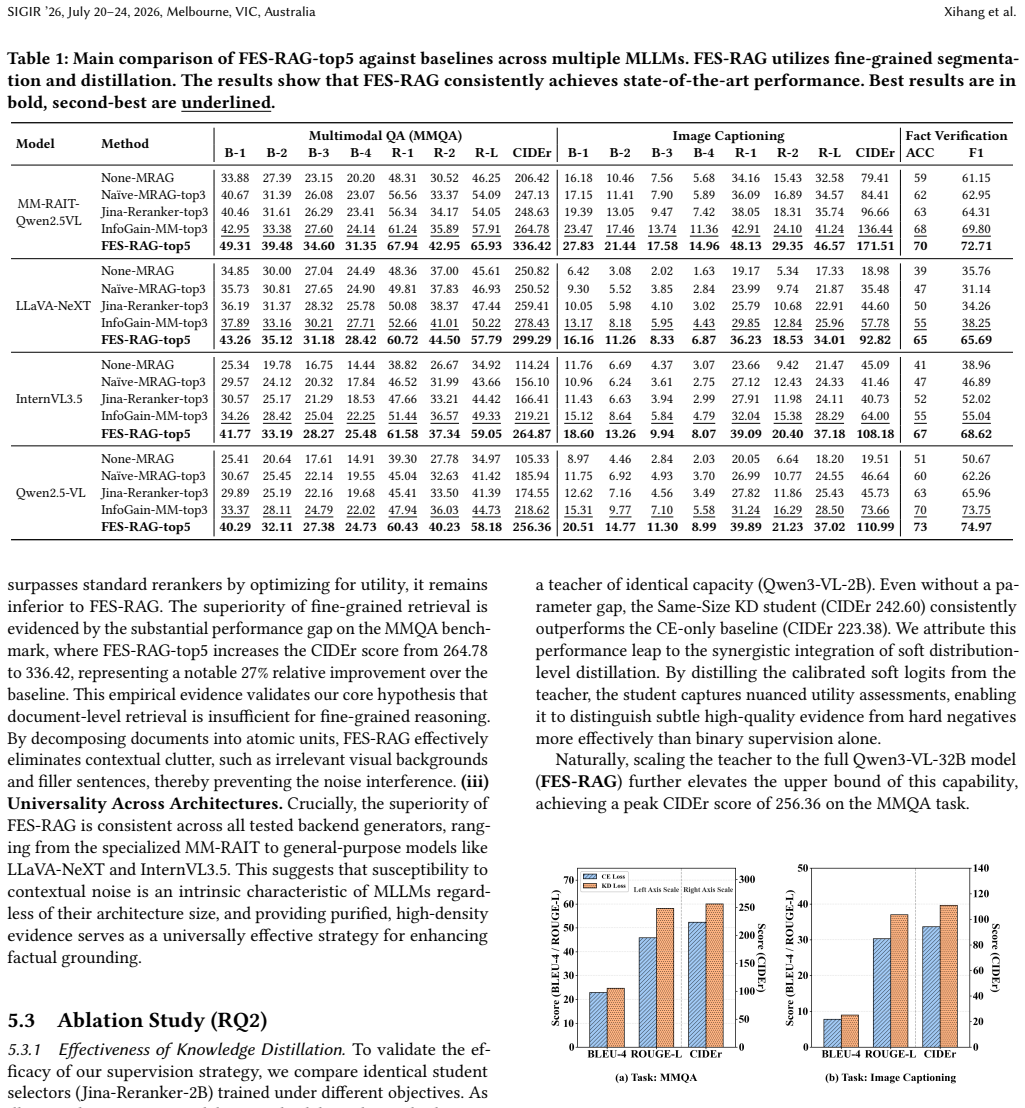
FES-RAG decomposes retrieved multimodal documents into sentence-level textual fragments and region-level visual fragments, introduces Fragment Information Gain to quantify each fragment's marginal contribution to MLLM generation confidence, and distills the resulting utility judgments into a lightweight selector. On the M2RAG benchmark this produces up to 27 percent relative CIDEr improvement over document-level baselines, with reduced context length and gains in factual accuracy and generation coherence.
What carries the argument
Fragment Information Gain (FIG): a metric that measures the marginal boost each sentence-level text fragment or region-level visual fragment gives to the MLLM's generation confidence, used both to identify useful evidence and to supervise training of the lightweight selector.
If this is right
- FES-RAG outperforms document-level MRAG methods by up to 27 percent relative improvement in CIDEr.
- Context length is reduced because only the most informative fragments are retained.
- Factual accuracy and generation coherence improve by excluding noisy content from full documents.
- Distillation allows the selector to run with low inference overhead while preserving selection quality.
Where Pith is reading between the lines
- The same fragment-purification logic could be applied to text-only RAG to filter noisy passages before generation.
- Defining atomic units for video or audio would let the method extend to additional modalities without changing the core gain calculation.
- If FIG scores align with human relevance labels, the metric could serve as a new automatic evaluator for evidence quality in multimodal retrieval.
- Pairing fragment selection with existing rerankers or iterative retrieval loops would likely compound accuracy gains on complex queries.
Load-bearing premise
A high-capacity MLLM's generation confidence reliably identifies which fragments are genuinely useful, and those judgments transfer to a much smaller selector without major loss in quality.
What would settle it
On the M2RAG benchmark, replace FIG-guided selection with random fragment selection and measure whether CIDEr drops sharply or stays comparable to the reported gains.
Figures




read the original abstract
Multimodal Retrieval-Augmented Generation (MRAG) is widely adopted for Multimodal Large Language Models (MLLMs) with external evidence to reduce hallucinations. Despite its success, most existing MRAG frameworks treat retrieved evidence as indivisible documents, implicitly assuming that all content within a document is equally informative. In practice, however, sometimes only a small fraction of a document is relevant to a given query, while the remaining content introduces substantial noise that may lead to performance degradation. We address this fundamental limitation by reframing MRAG as a fine-grained evidence selection problem. We propose Fragment-level Evidence Selection for RAG (FES-RAG), a framework that selects atomic multimodal fragments rather than entire documents as grounding evidence. FES-RAG decomposes retrieved multimodal documents into sentence-level textual fragments and region-level visual fragments, enabling precise identification of evidence that directly supports generation. To guide fragment selection, we introduce Fragment Information Gain (FIG), a principled metric that measures the marginal contribution of each fragment to the MLLM's generation confidence. Based on FIG, we distill fragment-level utility judgments from a high-capacity MLLM into a lightweight selector, achieving accurate evidence selection with low inference overhead. Experiments on the M2RAG benchmark show that FES-RAG consistently outperforms state-of-the-art document-level MRAG methods, achieving up to 27 percent relative improvement in CIDEr. By selecting fewer yet more informative fragments, our approach substantially reduces context length while improving factual accuracy and generation coherence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FES-RAG, a framework that reframes multimodal RAG as fragment-level evidence selection rather than document-level retrieval. It decomposes documents into sentence-level text and region-level visual fragments, introduces Fragment Information Gain (FIG) as a metric of marginal contribution to MLLM generation confidence, distills these judgments into a lightweight selector, and reports up to 27% relative CIDEr improvement on the M2RAG benchmark while reducing context length and improving factual accuracy.
Significance. If the reported gains are attributable to superior evidence selection rather than artifacts of shorter inputs or unvalidated proxies, the work could meaningfully advance efficient and accurate MRAG systems by addressing noise from irrelevant document content. The distillation approach offers a practical path to low-overhead inference, and the emphasis on atomic multimodal fragments is a timely refinement of existing retrieval paradigms.
major comments (3)
- [§3] §3 (Fragment Information Gain definition): The central performance claim depends on FIG accurately quantifying fragment utility via high-capacity MLLM confidence scores, yet no calibration checks, correlation with human relevance judgments, or ablation against oracle fragment labels are reported. In multimodal settings, confidence scores are known to be miscalibrated; if FIG primarily captures surface coherence rather than factual grounding, the observed CIDEr gains and context reductions may not reflect true evidential improvement.
- [§4] §4 (Experiments): The abstract and results claim consistent outperformance over document-level MRAG baselines with up to 27% CIDEr gain, but the manuscript provides insufficient detail on baseline implementations, statistical significance testing, number of runs, or ablations isolating the contribution of the FIG-based selector versus the distillation step. This undermines verification that the experimental design supports the load-bearing claim without post-hoc choices.
- [§3.3] §3.3 (Distillation): The assumption that fragment utility judgments from a high-capacity MLLM can be reliably distilled into a lightweight selector without material loss of selection quality lacks direct empirical support, such as a comparison of selector performance against the teacher MLLM or human-annotated fragment relevance. This step is load-bearing for the efficiency claims.
minor comments (3)
- [§3.1] The abstract mentions 'sentence-level textual fragments and region-level visual fragments' but the precise decomposition procedure (e.g., how regions are extracted or aligned) is only sketched; a clearer algorithmic description or pseudocode would improve reproducibility.
- [Figure 2] Figure 2 (or equivalent architecture diagram) would benefit from explicit annotation of the FIG computation flow and the distillation training objective to clarify the pipeline.
- [§2] The paper should include a brief discussion of related work on fine-grained retrieval or evidence selection in unimodal RAG to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We agree that additional validation and experimental details are needed to strengthen the claims. We will revise the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Fragment Information Gain definition): The central performance claim depends on FIG accurately quantifying fragment utility via high-capacity MLLM confidence scores, yet no calibration checks, correlation with human relevance judgments, or ablation against oracle fragment labels are reported. In multimodal settings, confidence scores are known to be miscalibrated; if FIG primarily captures surface coherence rather than factual grounding, the observed CIDEr gains and context reductions may not reflect true evidential improvement.
Authors: We acknowledge that MLLM confidence scores can be miscalibrated and that direct validation of FIG is important. Our current results show that FIG-based selection yields consistent CIDEr gains and improved factual accuracy with shorter contexts, suggesting it captures useful evidential signal beyond surface coherence. In the revised manuscript we will add: (1) calibration analysis (e.g., expected calibration error) of the confidence scores used to compute FIG, (2) correlation between FIG scores and human relevance judgments on a sampled subset of queries/fragments, and (3) an ablation against an oracle fragment selector using available ground-truth labels. These additions will help confirm that the gains reflect genuine evidential improvement. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results claim consistent outperformance over document-level MRAG baselines with up to 27% CIDEr gain, but the manuscript provides insufficient detail on baseline implementations, statistical significance testing, number of runs, or ablations isolating the contribution of the FIG-based selector versus the distillation step. This undermines verification that the experimental design supports the load-bearing claim without post-hoc choices.
Authors: We agree that more rigorous experimental reporting is required. The revised version will include: complete implementation details and hyperparameters for all baselines; results aggregated over multiple runs (we performed experiments with three random seeds) together with statistical significance tests (paired t-tests); and targeted ablations that isolate the FIG selector from the distillation step, including a direct comparison of the distilled selector against the teacher MLLM on both selection quality and end-task performance. These changes will allow readers to verify that the reported gains are attributable to the proposed method. revision: yes
-
Referee: [§3.3] §3.3 (Distillation): The assumption that fragment utility judgments from a high-capacity MLLM can be reliably distilled into a lightweight selector without material loss of selection quality lacks direct empirical support, such as a comparison of selector performance against the teacher MLLM or human-annotated fragment relevance. This step is load-bearing for the efficiency claims.
Authors: We recognize that direct empirical validation of the distillation step is necessary to support the efficiency claims. In the revision we will add: (1) a side-by-side comparison of the lightweight selector versus the teacher MLLM on fragment selection overlap and downstream generation metrics, and (2) human evaluation of fragment relevance on a small held-out sample to quantify any quality loss from distillation. These experiments will demonstrate that the distilled selector retains high selection quality while delivering the reported inference-time savings. revision: yes
Circularity Check
No circularity: empirical benchmark gains independent of internal definitions
full rationale
The paper defines Fragment Information Gain (FIG) as the marginal contribution of each fragment to an MLLM's generation confidence, then distills this signal into a lightweight selector. However, the central claim—up to 27% relative CIDEr improvement over document-level MRAG on the M2RAG benchmark—is an empirical measurement against external baselines, not a quantity derived by construction from the FIG definition or the distillation process. No equations reduce the reported performance metric to the input confidence scores or selector parameters. No self-citation chain, uniqueness theorem, or ansatz is invoked to force the outcome. The method's assumptions (e.g., that MLLM confidence tracks utility) are testable via the benchmark results rather than tautological. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-capacity MLLMs can generate reliable marginal utility judgments for individual fragments that generalize when distilled to a lightweight model.
invented entities (1)
-
Fragment Information Gain (FIG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mohammad Mahdi Abootorabi, Amirhosein Zobeiri, Mahdi Dehghani, Moham- madali Mohammadkhani, Bardia Mohammadi, Omid Ghahroodi, Mahdieh Soley- mani Baghshah, and Ehsaneddin Asgari. 2025. Ask in any modality: A compre- hensive survey on multimodal retrieval-augmented generation.arXiv preprint arXiv:2502.08826(2025)
-
[2]
Chen Amiraz, Florin Cuconasu, Simone Filice, and Zohar Karnin. 2025. The Distracting Effect: Understanding Irrelevant Passages in RAG. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2025
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InProceedings of the 12th International Conference on Learning Representations (ICLR). Vienna, Austria
2024
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2. 5-VL Technical Report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review arXiv 2025
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216 4, 5 (2024)
work page internal anchor Pith review arXiv 2024
-
[7]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 719–729
2024
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota...
2019
- [9]
- [10]
- [11]
-
[12]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. 2025. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review arXiv 2025
-
[13]
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, and Tomas Pfister. 2024. Found in the middle: Calibrating Positional Atten- tion Bias Improves Long Context Utilization. InFindings of the Association for Computational Linguistics: ACL 2024
2024
-
[14]
Wenbo Hu, Jia-Chen Gu, Zi-Yi Dou, Mohsen Fayyaz, Pan Lu, Kai-Wei Chang, and Nanyun Peng. 2025. MRAG-Bench: Vision-Centric Evaluation for Retrieval- Augmented Multimodal Models. (2025)
2025
- [15]
-
[16]
Chengkai Huang, Yu Xia, Rui Wang, Kaige Xie, Tong Yu, Julian McAuley, and Lina Yao. 2025. Embedding-informed adaptive retrieval-augmented generation of large language models. InProceedings of the 31st International Conference on Computational Linguistics. 1403–1412
2025
-
[17]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, et al
-
[18]
Atlas: few-shot learning with retrieval augmented language models.The Journal of Machine Learning Research24, 1 (2022), 11912–11954
2022
-
[19]
Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Aug- mented Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore, 7969–7992
2023
- [20]
-
[21]
Shuguang Jiao, Xinyu Xiao, Yunfan Wei, Shuhan Qi, Chengkai Huang, Quan Z Sheng, and Lina Yao. 2026. PruneRAG: Confidence-Guided Query Decomposition Trees for Efficient Retrieval-Augmented Generation. InProceedings of the ACM Web Conference 2026. 1923–1934
2026
-
[22]
Jina AI. 2025. Jina Reranker M0: Multilingual & Multimodal Document Reranker
2025
-
[23]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, et al. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. Virtual, 9459–9474
2020
-
[24]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895(2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. 2022. BLIP: Bootstrap- ping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. InInternational Conference on Machine Learning, ICML 2022, 17-23 July Maryland, USA (Proceedings of Machine Learning Research, Vol. 162). PMLR, 12888–12900
2022
-
[26]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[27]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, et al
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, et al. 2023. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics (TACL)12 (2023), 157–173
2023
-
[28]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marry- ing dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
- [29]
-
[30]
Zhiqiang Liu, Yuhong Li, Chengkai Huang, KunTing Luo, and Yanxia Liu. 2024. Boosting fine-tuning via conditional online knowledge transfer.Neural Networks 169 (2024), 325–333
2024
-
[31]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer us- ing shifted windows. InProceedings of the IEEE/CVF international conference on computer vision. 10012–10022
2021
- [32]
-
[33]
Zhenghao Liu, Xingsheng Zhu, Tianshuo Zhou, Xinyi Zhang, Xiaoyuan Yi, Yukun Yan, Ge Yu, and Maosong Sun. 2025. Benchmarking retrieval-augmented gen- eration in multi-modal contexts. InProceedings of the 33rd ACM International Conference on Multimedia. 4817–4826
2025
-
[34]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review arXiv 2017
- [35]
- [36]
- [37]
-
[38]
arXiv preprint arXiv:2501.03995 , year=
Matin Mortaheb, Mohammad A. Amir Khojastepour, Srimat T. Chakradhar, and Sennur Ulukus. 2025. RAG-Check: Evaluating Multimodal Retrieval Augmented Generation Performance. arXiv:2501.03995 [cs.LG] https://arxiv.org/abs/2501. 03995
-
[39]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
- [40]
-
[41]
Ross Quinlan
J. Ross Quinlan. 1986. Induction of decision trees.Machine learning1, 1 (1986), 81–106
1986
-
[42]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Con- ference on Machine Learning, ICML 2021, 18-24 Jul...
2021
-
[43]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy. InFindings of the Association for Compu- tational Linguistics: EMNLP 2023. Singapore, 9248–9274. https://aclanthology. org/2023.findings-emnlp.620/
2023
-
[44]
Naoya Sogi, Takashi Shibata, and Makoto Terao. 2024. Object-aware query perturbation for cross-modal image-text retrieval. InEuropean Conference on Computer Vision. Springer, 447–464. SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Xihang et al
2024
-
[45]
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. InProceedings of the IEEE confer- ence on computer vision and pattern recognition. 4566–4575
2015
- [46]
- [47]
-
[48]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Ad- vancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review arXiv 2025
-
[49]
MEG-RAG: Quantifying Multi-modal Evidence Grounding for Evidence Selection in RAG
Xihang Wang, Zihan Wang, Chengkai Huang, Quan Z. Sheng, and Lina Yao. 2026. MEG-RAG: Quantifying Multi-modal Evidence Grounding for Evidence Selection in RAG. arXiv:2604.24564
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Zihan Wang, Zihan Liang, Zhou Shao, Yufei Ma, Huangyu Dai, Ben Chen, Ling- tao Mao, Chenyi Lei, Yuqing Ding, and Han Li. 2025. InfoGain-RAG: Boosting Retrieval-Augmented Generation through Document Information Gain-based Reranking and Filtering. InProceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing
2025
-
[51]
Peng Xia, Kangyu Zhu, Haoran Li, Hongtu Zhu, Yun Li, Gang Li, Linjun Zhang, and Huaxiu Yao. 2024. RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
2024
- [52]
-
[53]
Minglai Yang, Ethan Huang, Liang Zhang, Mihai Surdeanu, William Yang Wang, and Liangming Pan. 2025. How is llm reasoning distracted by irrelevant context? an analysis using a controlled benchmark. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 13340–13358
2025
-
[54]
Zhuolin Yang, Wei Ping, Zihan Liu, Vijay Korthikanti, Weili Nie, De-An Huang, Linxi Fan, Zhiding Yu, Shiyi Lan, Bo Li, et al. 2023. Re-vilm: Retrieval-augmented visual language model for zero and few-shot image captioning. InFindings of the Association for Computational Linguistics: EMNLP 2023. 11844–11857
2023
-
[55]
Yunzhu Zhang, Yu Lu, Tianyi Wang, Fengyun Rao, Yi Yang, and Linchao Zhu
-
[56]
arXiv preprint arXiv:2506.00993(2025)
FlexSelect: Flexible Token Selection for Efficient Long Video Understanding. arXiv preprint arXiv:2506.00993(2025)
- [57]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.