Recognition: unknown
SecGoal: A Benchmark for Security Goal Extraction and Formalization from Protocol Documents
Pith reviewed 2026-05-07 07:21 UTC · model grok-4.3
The pith
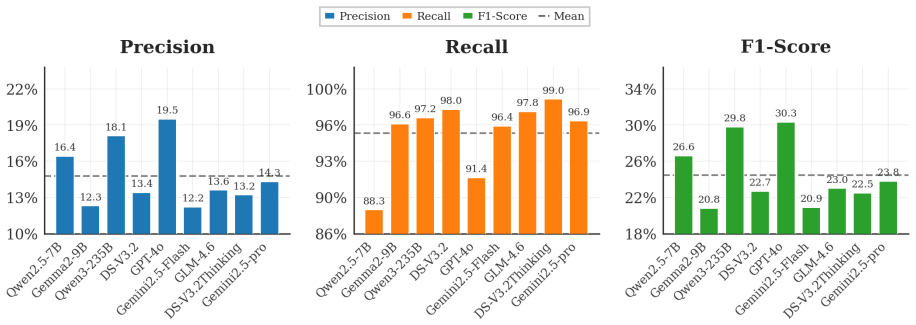
Instruction tuning on SecGoal lets 7B and 9B models extract security goals from protocol documents at over 80% F1 while larger general models fall below 15% precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SecGoal is the first expert-annotated benchmark covering 15 widely deployed protocol documents. AIFG is an AI-assisted framework that decomposes the task into context-aware goal extraction and retrieval-augmented formalization. Comprehensive evaluation shows that instruction tuning on SecGoal enables compact models with 7B/9B parameters to achieve F1-scores above 80%, substantially outperforming larger general-purpose models that exhibit pronounced precision-recall imbalance.
What carries the argument
The SecGoal expert-annotated benchmark paired with the AIFG framework that decomposes extraction and formalization into separate context-aware and retrieval-augmented stages.
If this is right
- Protocol analysis teams could move from manual goal listing to automated extraction followed by formal verification with less human effort.
- Smaller tuned models become practical for routine security goal work, reducing the compute needed compared with frontier-scale systems.
- The benchmark supplies a shared test set that lets different extraction methods be compared directly on the same protocol texts.
- Repeated use of the dataset could encourage protocol authors to write specifications with clearer separation between operational steps and security goals.
Where Pith is reading between the lines
- The same pattern of task-specific tuning on expert data might transfer to turning other technical documents into formal statements, such as software requirements or regulatory rules.
- The low precision of untuned large models suggests that future training sets should deliberately include many examples of text that is not a security goal.
- Combining the extraction step with existing formal verifiers could produce pipelines that take a protocol document and output both the goals and a machine-checked proof of security properties.
Load-bearing premise
The expert annotations of security goals across the 15 protocol documents are accurate, unbiased, and representative enough for models to learn patterns that apply to new documents.
What would settle it
Running the tuned 7B/9B models on a fresh collection of protocol documents never seen during benchmark creation and finding F1 scores well below 80% would show the approach fails to generalize.
Figures



read the original abstract
Formal verification provides rigorous guarantees for cryptographic security, yet automating the extraction and formalization of security goals from natural language protocol documents remains a major bottleneck, compounded by the scarcity of expert-annotated resources and integrated frameworks bridging unstructured text and symbolic logic. We introduce SecGoal, the first expert-annotated benchmark covering 15 widely deployed protocol documents, including 5G-AKA and TLS 1.3, and AIFG, an AI-assisted framework that decomposes the task into context-aware goal extraction and retrieval-augmented formalization. We conduct a comprehensive evaluation to assess whether contemporary LLMs are ready to automate this pipeline. Our results reveal a pronounced precision-recall imbalance: frontier models, such as Gemini 2.5-Pro, achieve high recall but precision below 15%, frequently misclassifying operational text as security goals. In contrast, instruction tuning on SecGoal enables compact models with 7B/9B parameters to achieve F1-scores above 80%, substantially outperforming larger general-purpose models. Our work establishes a foundational dataset and reproducible baseline for automated formal protocol analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SecGoal, the first expert-annotated benchmark for security goal extraction from 15 protocol documents (including 5G-AKA and TLS 1.3), along with the AIFG framework decomposing the task into context-aware extraction and retrieval-augmented formalization. Evaluations show frontier LLMs (e.g., Gemini 2.5-Pro) achieve high recall but precision below 15%, while instruction-tuned 7B/9B-parameter models reach F1 scores above 80% and outperform larger general-purpose models, establishing a dataset and baseline for automated formal protocol analysis.
Significance. If the results hold under proper generalization testing, SecGoal would be a valuable foundational resource addressing the scarcity of annotated data for bridging natural-language protocol specs to symbolic security goals. The demonstration that compact tuned models can substantially outperform frontier models on this task is a practically useful finding for resource-efficient automation of formal verification pipelines. The work earns credit for releasing a new expert-annotated benchmark and reproducible baseline.
major comments (3)
- [Abstract and §5] Abstract and §5 (Experiments): The headline claim that instruction tuning enables 7B/9B models to achieve F1>80% on security goal extraction from protocol documents requires document-level hold-out (entire protocols reserved for test). With only 15 documents total, a sentence- or paragraph-level split within the same documents would permit memorization of document-specific phrasing rather than learning transferable criteria, directly undermining the generalization implied by the abstract and the comparison to general-purpose models. The abstract provides no indication of such a split.
- [§3] §3 (Benchmark Construction): The expert annotation process is described without inter-annotator agreement statistics, detailed guidelines for distinguishing security goals from operational text, or basic dataset statistics (total goals, distribution per document, or annotation volume). These omissions are load-bearing for assessing benchmark quality and for the claim that the annotations are sufficient to train generalizable models.
- [§5.2] §5.2 (Results): The reported precision-recall imbalance (frontier models <15% precision) and the outperformance of tuned small models lack supporting tables with per-model breakdowns, error analysis of misclassified operational text, or ablation on the retrieval-augmented formalization component. Without these, the quantitative claims cannot be fully verified or reproduced.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly stating the total number of annotated security goals and the train/test split methodology to allow immediate assessment of the results.
- Ensure consistent terminology between 'security goals' and 'formalization' across sections; some passages use the terms interchangeably without clear distinction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have carefully considered each point and revised the paper to improve the clarity of our evaluation methodology, provide additional details on the benchmark construction, and enhance the experimental reporting. Our responses to the major comments are as follows.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The headline claim that instruction tuning enables 7B/9B models to achieve F1>80% on security goal extraction from protocol documents requires document-level hold-out (entire protocols reserved for test). With only 15 documents total, a sentence- or paragraph-level split within the same documents would permit memorization of document-specific phrasing rather than learning transferable criteria, directly undermining the generalization implied by the abstract and the comparison to general-purpose models. The abstract provides no indication of such a split.
Authors: We agree with the referee that a document-level hold-out is necessary to properly assess generalization to unseen protocols. In our original experiments, we employed a stratified split at the paragraph level to ensure sufficient training data. However, recognizing the validity of this concern, we have conducted additional experiments using a document-level cross-validation (leave-one-out across the 15 protocols) and report the results in the revised §5. The tuned 7B/9B models maintain F1 scores above 80% under this stricter protocol, while the performance gap with frontier models persists. We have updated the abstract to explicitly describe the evaluation split used. revision: yes
-
Referee: [§3] §3 (Benchmark Construction): The expert annotation process is described without inter-annotator agreement statistics, detailed guidelines for distinguishing security goals from operational text, or basic dataset statistics (total goals, distribution per document, or annotation volume). These omissions are load-bearing for assessing benchmark quality and for the claim that the annotations are sufficient to train generalizable models.
Authors: We thank the referee for pointing out these important omissions. We have revised §3 to include: (1) inter-annotator agreement statistics (e.g., Cohen's kappa of 0.82 between two expert annotators), (2) the detailed annotation guidelines used to distinguish security goals from operational text, and (3) comprehensive dataset statistics, including a total of 1,248 annotated security goals with per-document distributions and annotation effort details. These additions strengthen the transparency and reproducibility of the benchmark. revision: yes
-
Referee: [§5.2] §5.2 (Results): The reported precision-recall imbalance (frontier models <15% precision) and the outperformance of tuned small models lack supporting tables with per-model breakdowns, error analysis of misclassified operational text, or ablation on the retrieval-augmented formalization component. Without these, the quantitative claims cannot be fully verified or reproduced.
Authors: We acknowledge that additional supporting analyses would enhance the verifiability of our results. In the revised manuscript, we have added: detailed per-model performance tables in §5.2, a qualitative error analysis examining cases where operational text was misclassified as security goals (particularly for frontier models), and an ablation study isolating the impact of the retrieval-augmented formalization component. These revisions allow readers to better understand the sources of the observed precision-recall imbalance and the contributions of each framework element. revision: yes
Circularity Check
No circularity in benchmark creation or empirical evaluation
full rationale
The paper introduces the SecGoal benchmark consisting of expert annotations over 15 protocol documents and reports empirical F1 scores from instruction-tuning and evaluating LLMs on splits of that benchmark. No equations, derivations, or self-referential definitions appear in the provided text. The central results are direct measurements of model performance against the newly created ground truth rather than any quantity that reduces by construction to the inputs. Standard supervised learning on a held-out test portion of a new dataset does not match any of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.). The work is therefore self-contained as a benchmark paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Security goals can be reliably identified and annotated by domain experts from protocol documents
- standard math Fine-tuning LLMs on domain-specific annotated data improves performance on extraction tasks
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Formal verification of the fdo protocol. In 2023 IEEE Conference on Standards for Commu- nications and Networking (CSCN), pages 290–295. IEEE. Frederick Butler, Iliano Cervesato, Aaron D Jaggard, Andre Scedrov, and Christopher Walstad. 2006. For- mal analysis of kerberos 5.Theoretical Computer Science, 367(1-2):57–87. Mark Chen. 2021. Evaluating large lan...
work page internal anchor Pith review arXiv 2023
-
[2]
InUsenix Security 2025
A comprehensive formal security analysis of opc ua. InUsenix Security 2025. Haonan Feng, Hui Li, Xuesong Pan, Ziming Zhao, and T Cactilab. 2021. A formal analysis of the fido uaf protocol. InNDSS. Daniel Fett, Ralf K¨usters, and Guido Schmitz. 2016. A comprehensive formal security analysis of oauth 2.0. InProceedings of the 2016 ACM SIGSAC conference on c...
2025
-
[3]
A formal analysis of the fido2 protocols. In European Symposium on Research in Computer Se- curity, pages 3–21. Springer. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276. InfiniFlow. 2024. Ragflow...
work page internal anchor Pith review arXiv 2024
-
[4]
Gemma 2: Improving Open Language Models at a Practical Size
Automated attack synthesis by extracting fi- nite state machines from protocol specification doc- uments. In2022 IEEE Symposium on Security and Privacy (SP), pages 51–68. IEEE. Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2023. Ex- amining zero-shot vulnerability repair with large lan- guage models. In2023 IEEE Symp...
work page internal anchor Pith review arXiv 2023
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Tatu Ylonen. 2006. Rfc 4251: The secure shell (ssh) protocol architecture. Jingjing Zhang, Lin Yang, Xianming Gao, Gaigai Tang, Jiyong Zhang, and Qiang Wang. 2021. Formal analy- sis of quic handshake protocol using symbolic model checking.IEEE Access, 9:14836–14848. Yaowei Zheng, Richong Zhang, Junha...
work page internal anchor Pith review arXiv 2006
-
[6]
Gen- eral
for fine-tuning. For RAG and formalization tasks, we em- ployed the RAGFlow framework (InfiniFlow, 2024). Specifically, we used Gemini2.5-Pro (Co- manici et al., 2025) as the primary chat model and nomic-embed-text (Nussbaum et al., 2024) for generating high-dimensional vector embeddings. The knowledge base was processed using the “Gen- eral” document par...
2024
-
[7]
type": "Authentication
Ground Truth (Minimal Scope) { "type": "Authentication", "subtype": "injective_agreement", "asserter": "Alice", "subject": "Bob", // Minimal Verification Set: Only Nonces "agreementValues": ["Na", "Nb"] }
-
[8]
type": "Authentication
Generated by AIFG (Full Scope) { "type": "Authentication", "subtype": "non_injective_agreement", "asserter": "Alice", "subject": "Bob", // Note: Includes redundant context (A, B, KAB) "agreementValues": [ "A", // Redundant "B", // Redundant "Na", // Correct "Nb", // Correct "KAB" // Redundant ] } Error Analysis.As shown above, the generated agreementValue...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.