Recognition: 2 theorem links
· Lean TheoremWaferSAGE: Large Language Model-Powered Wafer Defect Analysis via Synthetic Data Generation and Rubric-Guided Reinforcement Learning
Pith reviewed 2026-05-12 02:47 UTC · model grok-4.3
The pith
A 4-billion-parameter vision-language model trained on synthetic wafer data approaches proprietary large-model performance on industrial defect analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
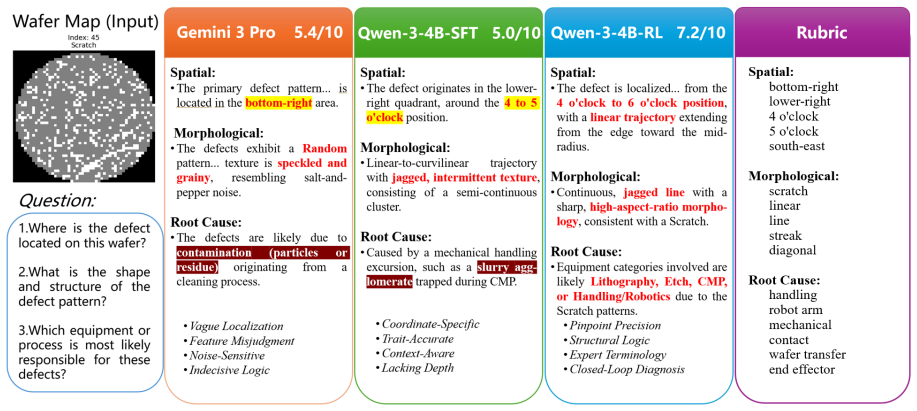
WaferSAGE uses a three-stage synthesis pipeline to turn limited real wafer maps into structured rubrics and aligned VQA pairs, then applies curriculum-based reinforcement learning with Group Sequence Policy Optimization to train a 4B Qwen3-VL model that achieves an LLM-Judge score of 6.493, closely approaching the 7.149 score of Gemini-3-Flash while supporting full on-premise deployment.
What carries the argument
Rubric-guided synthetic VQA generation from clustered wafer maps, paired with Group Sequence Policy Optimization (GSPO) reinforcement learning that uses rubric-aligned rewards to improve the small vision-language model's answers on defect identification, spatial distribution, morphology, and root cause questions.
If this is right
- Small domain-specific models can reach near-parity with much larger general models on narrow industrial visual tasks.
- Complete on-premise deployment becomes feasible for privacy-sensitive manufacturing data.
- Rubric-based synthetic data plus reinforcement learning provides a repeatable way to adapt models to new defect types without large new annotation efforts.
- Dual automated evaluation combining rule metrics and optimized LLM judges can replace costly human scoring for these tasks.
Where Pith is reading between the lines
- The same synthesis-plus-rubric approach could be tried on other data-scarce visual inspection problems such as printed circuit boards or solar panel defects.
- Factories might achieve lower long-term costs by investing in high-quality synthetic pipelines rather than repeatedly calling large cloud models.
- The method could be extended by automatically updating rubrics when new defect patterns appear in production without requiring fresh manual labeling.
Load-bearing premise
The synthetic VQA pairs and evaluation rubrics generated from a limited set of real wafer maps accurately represent the full variety and judgment standards of real-world wafer defects.
What would settle it
Testing the trained 4B model on a large held-out collection of real wafer images paired with expert-written VQA questions and finding its LLM-Judge score drops well below the proprietary model's score.
Figures


read the original abstract
We present WaferSAGE, a framework for wafer defect visual question answering using small vision-language models. To address data scarcity in semiconductor manufacturing, we propose a three-stage synthesis pipeline incorporating structured rubric generation for precise evaluation. Starting from limited labeled wafer maps, we employ clustering-based cleaning to filter label noise, then generate comprehensive defect descriptions using vision-language models, which are converted into structured evaluation rubrics criteria. These rubrics guide the synthesis of VQA pairs, ensuring coverage across defect type identification, spatial distribution, morphology, and root cause analysis. Our dual assessment framework aligns rule-based metrics with LLM-Judge scores via Bayesian optimization, enabling reliable automated evaluation. Through curriculum-based reinforcement learning with Group Sequence Policy Optimization (GSPO) and rubric-aligned rewards, our 4B-parameter Qwen3-VL model achieves a 6.493 LLM-Judge score, closely approaching Gemini-3-Flash (7.149) while enabling complete on-premise deployment. We demonstrate that small models with domain-specific training can surpass proprietary large models in specialized industrial visual understanding, offering a viable path for privacy-preserving, cost-effective deployment in semiconductor manufacturing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WaferSAGE, a three-stage framework for wafer defect visual question answering that generates synthetic VQA pairs from limited real wafer maps via clustering-based cleaning, VLM-generated defect descriptions, and rubric conversion. These pairs train a 4B Qwen3-VL model using curriculum reinforcement learning with Group Sequence Policy Optimization (GSPO) and rubric-aligned rewards. A dual evaluation framework aligns rule-based metrics with LLM-Judge scores through Bayesian optimization. The model reports an LLM-Judge score of 6.493, compared to 7.149 for Gemini-3-Flash, supporting the claim that domain-specific small models can approach proprietary large models for on-premise industrial deployment in semiconductor manufacturing.
Significance. If the central claims hold after addressing validation gaps, the work offers a concrete, privacy-preserving alternative to proprietary VLMs for specialized industrial visual tasks, with potential cost and deployment advantages in semiconductor fabs. The rubric-guided synthesis and Bayesian metric alignment represent methodological strengths that could generalize to other data-scarce domains. However, the significance hinges on demonstrating that performance gains transfer beyond the synthetic distribution.
major comments (3)
- [Abstract] Abstract: The claim that 'small models with domain-specific training can surpass proprietary large models' is not supported by the reported LLM-Judge scores (6.493 vs. 7.149 for Gemini-3-Flash); the numbers indicate the small model approaches but does not exceed the baseline, requiring either a revised claim or additional metrics where surpassing occurs.
- [Methods / Data Synthesis] Data synthesis pipeline (methods section): No held-out real wafer maps with independent human VQA annotations are reported to validate that the clustering, VLM descriptions, and rubric-generated synthetic pairs cover the full distribution of real defects, including low-frequency morphologies and root-cause ambiguities; this is load-bearing for any out-of-distribution superiority claim.
- [Evaluation Framework] Evaluation framework: The Bayesian optimization alignment between rule-based metrics and LLM-Judge scores is described, but no correlation statistics, sensitivity analysis to prompt variations, or cross-validation details are provided; given that the judge belongs to the same model family as the trained model, this risks circular measurement of similarity to the synthetic training distribution rather than independent performance.
minor comments (2)
- [Abstract] Abstract: The phrase 'complete on-premise deployment' should be accompanied by concrete details on model size, inference hardware, and latency to substantiate the cost-effectiveness claim relative to Gemini-3-Flash.
- [Methods] The manuscript would benefit from an explicit statement of the number of real wafer maps used for synthesis and the size of the synthetic VQA dataset to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas for improvement in clarity and rigor. We address each major comment point by point below, proposing specific revisions to the manuscript where appropriate while maintaining the integrity of our reported results and methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'small models with domain-specific training can surpass proprietary large models' is not supported by the reported LLM-Judge scores (6.493 vs. 7.149 for Gemini-3-Flash); the numbers indicate the small model approaches but does not exceed the baseline, requiring either a revised claim or additional metrics where surpassing occurs.
Authors: We agree that the LLM-Judge scores (6.493 for our 4B model vs. 7.149 for Gemini-3-Flash) show our model approaching but not exceeding the baseline. The phrasing in the abstract was intended to highlight domain-specific advantages for on-premise industrial use, but it overstates the numerical comparison. We will revise the abstract to accurately state that the model 'closely approaches' the performance of proprietary large models while enabling complete on-premise deployment and privacy preservation. We will also add references to any task-specific metrics from the full results where domain adaptation shows targeted benefits. revision: yes
-
Referee: [Methods / Data Synthesis] Data synthesis pipeline (methods section): No held-out real wafer maps with independent human VQA annotations are reported to validate that the clustering, VLM descriptions, and rubric-generated synthetic pairs cover the full distribution of real defects, including low-frequency morphologies and root-cause ambiguities; this is load-bearing for any out-of-distribution superiority claim.
Authors: We acknowledge this as a substantive limitation given the data-scarce nature of semiconductor wafer defect analysis. Our pipeline starts from limited real labeled maps and uses clustering-based cleaning plus VLM-generated descriptions to create synthetic VQA pairs, but we did not have access to additional held-out real maps with independent human annotations for explicit coverage validation. In the revision, we will expand the methods section with further details on how clustering promotes diversity across morphologies and add a dedicated limitations subsection discussing reliance on synthetic data, potential gaps in low-frequency defects, and the need for future real-world validation. This maintains transparency without overstating generalizability. revision: partial
-
Referee: [Evaluation Framework] Evaluation framework: The Bayesian optimization alignment between rule-based metrics and LLM-Judge scores is described, but no correlation statistics, sensitivity analysis to prompt variations, or cross-validation details are provided; given that the judge belongs to the same model family as the trained model, this risks circular measurement of similarity to the synthetic training distribution rather than independent performance.
Authors: We will strengthen the evaluation framework section by adding the requested details: Pearson/Spearman correlation coefficients between rule-based metrics and LLM-Judge scores, sensitivity analysis across judge prompt variations, and cross-validation procedures for the Bayesian optimization. On the circularity concern, the rule-based metrics are rubric-derived and independent of the LLM judge; Bayesian optimization aligns the judge to these objective criteria rather than to the training distribution. While the judge shares the Qwen model family, the rubric-guided rewards enforce focus on domain-specific defect criteria (type, morphology, root cause). We will clarify this distinction and report both metric families explicitly. revision: yes
Circularity Check
No significant circularity detected in the derivation chain
full rationale
The paper outlines an empirical pipeline: limited real wafer maps undergo clustering-based cleaning, VLM-generated descriptions are converted to rubrics, synthetic VQA pairs are produced, the 4B Qwen3-VL model is trained via curriculum RL with GSPO and rubric-aligned rewards, and performance is measured by a dual framework that aligns rule-based metrics to LLM-Judge scores through Bayesian optimization. The reported 6.493 LLM-Judge score (vs. Gemini-3-Flash at 7.149) is presented as the measured outcome of this training on the generated data. No equations, self-citations, or steps are exhibited in which the final metric or superiority claim reduces by construction to the input maps, fitted alignment parameters, or synthetic distribution itself; the alignment step is described as enabling reliable evaluation rather than forcing the performance number. The chain therefore contains independent content and does not meet the criteria for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLM-generated defect descriptions converted into rubrics provide unbiased, comprehensive evaluation criteria for wafer VQA
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage synthesis pipeline... clustering-based cleaning... rubric generation... GSPO... 4B-parameter Qwen3-VL model achieves 6.493 LLM-Judge score
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rubric-aligned rewards... J-cost is never mentioned
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ming-Ju Wu, Jyh-Shing R. Jang, and Jui-Long Chen. Wafer map failure pattern recognition and similarity ranking for large-scale data sets.IEEE Transactions on Semiconductor Manufacturing, 28(1):1–12, 2015
work page 2015
-
[2]
Junliang Wang, Chunhua Xu, Zhiyong Yang, Jie Zhang, and Xin Li. Deformable convolutional net- works for efficient mixed-type wafer defect pattern recognition.IEEE Transactions on Semiconductor Manufacturing, 33(4):587–596, 2020
work page 2020
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Wafer map defect pattern classification and image retrieval using convolutional neural network
T Nakazawa and DV Kulkarni. Wafer map defect pattern classification and image retrieval using convolutional neural network. InIEEE Transactions on Semiconductor Manufacturing, 2018
work page 2018
-
[5]
Thahmidul Islam Nafi, Erfanul Haque, Faisal Farhan, and Asif Rahman. High accuracy swin trans- formers for image-based wafer map defect detection.International Journal of Engineering and Manufacturing (IJEM), 12(5):10–21, 2022
work page 2022
-
[6]
Qiyu Wei, Wei Zhao, Xiaoyan Zheng, and Zeng Zeng. Wafer map defect patterns semi-supervised classification using latent vector representation.IEEE Transactions on Instrumentation and Mea- surement, 2023
work page 2023
-
[7]
Yin-Yin Bao, Er-Chao Li, Hong-Qiang Yang, and Bin-Bin Jia. Wafer map defect classification using autoencoder-based data augmentation and convolutional neural network.IEEE Transactions on Semiconductor Manufacturing, 2024
work page 2024
-
[8]
Semiconductor wafer map defect classification with tiny vision transformers.arXiv preprint, 2025
Faisal Mohammad and Duksan Ryu. Semiconductor wafer map defect classification with tiny vision transformers.arXiv preprint, 2025
work page 2025
-
[9]
Abhishek Mishra, Suman Kumar, Anush Lingamoorthy, Anup Das, and Nagarajan Kandasamy. Wafer2spike: Spiking neural network for wafer map pattern classification.IEEE Transactions on Emerging Topics in Computing, 2024
work page 2024
-
[10]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 10
work page 2021
-
[11]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023
work page 2023
-
[12]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Winclip: Zero-/few-shot anomaly classification and segmentation.CVPR, 2023
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero-/few-shot anomaly classification and segmentation.CVPR, 2023
work page 2023
-
[14]
Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection.ICLR, 2023
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection.ICLR, 2023
work page 2023
-
[15]
Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection.arXiv preprint, 2025
Yanhui Li et al. Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection.arXiv preprint, 2025
work page 2025
-
[16]
Agentiad: Tool-augmentedsingle-agent for industrial anomaly detection.arXiv preprint, 2025
JunwenMiao, PenghuiDu, YiLiu, YuWang, andYanWang. Agentiad: Tool-augmentedsingle-agent for industrial anomaly detection.arXiv preprint, 2025
work page 2025
-
[17]
Wei Guan, Jun Lan, Jian Cao, Hao Tan, Huijia Zhu, and Weiqiang Wang. Emit: Enhancing mllms for industrial anomaly detection via difficulty-aware grpo.arXiv preprint, 2025
work page 2025
-
[18]
Peng Chen, Chao Huang, Yunkang Cao, Chengliang Liu, Wenqiang Wang, Mingbo Yang, Li Shen, Wenqi Ren, and Xiaochun Cao. Reason-iad: Knowledge-guided dynamic latent reasoning for ex- plainable industrial anomaly detection.arXiv preprint, 2026
work page 2026
-
[19]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR, 2023
work page 2023
-
[20]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint, 2023
work page 2023
-
[21]
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions.arXiv preprint arXiv:2311.12793, 2023. Accepted by ECCV 2024
work page internal anchor Pith review arXiv 2023
-
[22]
Zicheng Kong, Dehua Ma, Zhenbo Xu, Alven Yang, Yiwei Ru, Haoran Wang, Zixuan Zhou, Fuqing Bie, Liuyu Xiang, Huijia Wu, Jian Zhao, and Zhaofeng He. Omni-rrm: Advancing omni reward modeling via automatic rubric-grounded preference synthesis.arXiv preprint, 2026
work page 2026
-
[23]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
work page 2022
-
[24]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and Z Guo. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint, 2024
work page 2024
-
[25]
Puzzlecurriculumgrpoforvision-centric reasoning.arXiv preprint, 2025
Ahmadreza Jeddi, Hakki Can Karaimer, Hue Nguyen, Zhongling Wang, Ke Zhao, Javad Rajabi, Ran Zhang, RaghavGoyal, BabakTaati, andRadekGrzeszczuk. Puzzlecurriculumgrpoforvision-centric reasoning.arXiv preprint, 2025
work page 2025
-
[26]
Siwen Jiao, Tianxiong Lv, Kangan Qian, Chenxu Zhao, Xiuyuan Zhu, Tianlun Li, Xiaolong Cheng, Jinyu Li, Zhihao Liao, and Yang Cai. Smooth operator: Smooth verifiable reward activates spatial reasoning ability of vision-language model.arXiv preprint, 2026
work page 2026
-
[27]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization. arXiv:2507.18071, 2025. 11 A Data Synthesis Prompts A.1 Stage 0: Descriptor Generation Prompts Full-Analysis Prompt: You are a semiconductor wafer defect analysis expert. Ana...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Defect Type: Identify the primary defect type (e.g., Scratch, Donut, Edge-Ring, Center-Spot, Random-Spot)
-
[29]
Spatial Distribution: Describe where defects are located (zones, clock positions, radial/linear patterns)
-
[30]
Morphology: Describe defect appearance (patterns, density, shapes, texture)
-
[31]
Spatial-Only Prompt: You are a semiconductor wafer defect analysis expert
Root Cause: Provide brief equipment/process insight if pattern suggests clear cause Write in a technical, professional tone suitable for a semiconductor engineer. Spatial-Only Prompt: You are a semiconductor wafer defect analysis expert. Analyze the provided wafer map image and describe:
-
[32]
Spatial Distribution: Where are the defects located? (center, edge, specific regions, clock positions)
-
[33]
Do not include root cause analysis
Morphology: What do the defects look like? (patterns, shapes, density, texture) Provide a concise technical description focusing only on spatial and morphological characteristics. Do not include root cause analysis. Root-Cause-Only Prompt: You are a semiconductor process engineering expert. Analyze the provided wafer map image and provide:
-
[34]
Root Cause Analysis: What process or equipment issues could have caused these defects?
-
[35]
Equipment Category: Which type of equipment is most likely involved? (Lithography, Etching, Deposition, CMP, Wet Processing, Handling)
-
[36]
Focus only on root cause and equipment analysis
Potential Causes: List specific potential root causes based on the defect pattern. Focus only on root cause and equipment analysis. A.2 Stage 1: Rubric Generator Prompt You are a semiconductor wafer defect analysis expert. Your task is to convert the provided wafer map analysis into a structured evaluation rubric. The rubric should capture:
-
[37]
Spatial Distribution: Exact zones, clock positions, coordinates mentioned
-
[38]
Morphology: Pattern types, density descriptions, geometric structures
-
[39]
12 A.3 Stage 2: VQA Generator Prompt You are a semiconductor wafer defect analysis expert
Root Cause: Equipment categories, process steps, specific potential causes For each dimension, provide: - Must-hit keywords: Terms that MUST appear in a correct answer - Must-avoid keywords: Terms that indicate hallucination if present Output valid JSON matching the rubric schema. 12 A.3 Stage 2: VQA Generator Prompt You are a semiconductor wafer defect a...
-
[40]
Defect Type (1-2 questions)
-
[41]
Spatial (2-3 questions): Location, zone, distribution pattern
-
[42]
Morphological (2-3 questions): Pattern type, density, texture
-
[43]
Root Cause (1-2 questions): Equipment category, process step
-
[44]
Consistency (1-2 questions): Yes/no verification CRITICAL GUIDELINES: - NEVER mention the defect type in the QUESTIONS - Include both easy and medium difficulty questions - Answers should be concise but complete (1-3 sentences) B Rubric Schema and Examples B.1 Rubric JSON Schema { "defect_types": ["list of defect types present"], "spatial_rubric": { "zone...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.