Recognition: unknown
Tail-aware N-version Machine Learning Models for Reliable API Recommendation
Pith reviewed 2026-05-07 07:52 UTC · model grok-4.3
The pith
N-version ML models with tail-aware performance profiles can filter unreliable API recommendations to reach 83.8% true accept rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NvRec profiles each available ML model on every API method in the training data according to the method's tail properties, then uses those profiles at inference time to exclude unreliable recommendations before applying majority voting restricted to highly reliable candidates. On the public Java benchmark the three-model ensemble of CodeT5, MulaRec and UniXcoder yields the highest true accept rate of 83.8% paired with an 80.7% rejection rate, while the five-model configuration yields 83.1% true accept rate with a lower 69.0% rejection rate under simple majority voting, demonstrating a practical trade-off between accuracy and coverage.
What carries the argument
The model performance profile, which records each model's accuracy on individual API methods grouped by their frequency in the training distribution and is consulted at inference to decide which model outputs are trustworthy enough to participate in voting.
If this is right
- A three-model ensemble restricted to highly reliable candidates can achieve a higher rejection rate than a five-model ensemble while preserving nearly the same true accept rate.
- Simple majority voting across all five models reduces the rejection rate to 69% without substantially lowering the true accept rate below 83%.
- The specific trio of CodeT5, MulaRec and UniXcoder outperforms other three-model combinations on the Java benchmark when reliability filtering is applied.
- Five-version NvRec provides a better overall balance between acceptance and rejection than the three-version version under simple voting.
Where Pith is reading between the lines
- The same profiling-plus-filtering idea could be applied to other code-generation tasks that also suffer from long-tail distributions, such as method-name suggestion or bug-fix patch generation.
- Periodic re-profiling on recent developer code could allow NvRec to adapt when new APIs become popular or old ones fall out of use.
- Integration into an IDE could let the system surface only recommendations that survive the reliability filter, thereby lowering the chance a developer accepts a mismatched API call.
Load-bearing premise
That each model's observed accuracy on tail APIs during offline profiling will continue to predict its reliability when the same model is applied to new code that was not seen during profiling.
What would settle it
Running the same NvRec configurations on a fresh collection of Java projects whose API frequency distribution differs markedly from the original benchmark and checking whether the reported true accept and rejection rates fall below the published figures.
Figures



read the original abstract
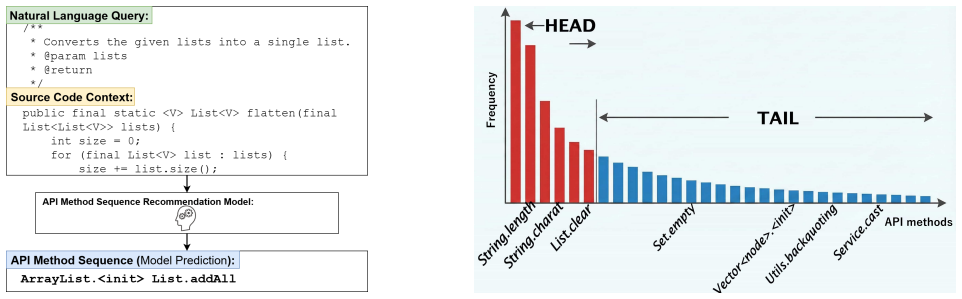
Machine learning (ML)-based API recommendation helps developers efficiently identify suitable APIs to complement the application code. However, code datasets used to train ML models often exhibit a long-tail distribution, leading to unreliable API recommendations, especially for infrequently used API methods at the tail of the distribution. To address this issue, we propose N-version API Recommendation (NvRec), which leverages N different versions of ML models to enhance the reliability of API sequence recommendations by suppressing unreliable outputs entailing tail APIs. NvRec leverages a set of available ML models and profiles their performance on individual API methods with their tail properties. The generated model profile is used at inference time to filter out unreliable API recommendations and determine the final output. We implement NvRec using five API recommendation models, including CodeBERT, CodeT5, MulaRec, UniXcoder, and CodeT5+, and evaluate it on a public benchmark dataset constructed from compilable Java projects. For the three-version NvRec, we find that the combination of CodeT5, MulaRec, and UniXcoder achieves the highest true accept rate of 83.8%, with a rejection rate of 80.7%, when majority voting is restricted to highly reliable candidates. In contrast, the five-version configuration achieves its highest true accept rate of 83.1% with simple majority voting, while reducing the rejection rate to 69.0%. Overall, the five-version configuration offers a better balance between true accept rate and rejection rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NvRec, an N-version programming approach for ML-based API recommendation that builds offline performance profiles for each model (CodeBERT, CodeT5, MulaRec, UniXcoder, CodeT5+) on individual APIs with emphasis on tail properties from a public Java benchmark, then applies these profiles at inference to suppress unreliable outputs via majority voting restricted to reliable candidates. On the benchmark, the three-model ensemble (CodeT5 + MulaRec + UniXcoder) reaches 83.8% true accept rate at 80.7% rejection under restricted voting, while the five-model configuration reaches 83.1% true accept rate at 69.0% rejection under simple majority voting.
Significance. If the offline profiles are shown to be strictly disjoint from evaluation data and predictive on unseen code, the work would offer a practical, training-free way to improve reliability of API recommenders in long-tail settings, which is a known pain point in software engineering ML tools. Strengths include the use of multiple off-the-shelf models on a public benchmark and the reporting of concrete trade-off numbers between true accept rate and rejection rate. The absence of partitioning details and validation experiments, however, prevents assessing whether the gains reflect genuine reliability improvements or benchmark-specific artifacts.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the manuscript reports headline numbers (83.8% true accept rate at 80.7% rejection for the three-version system) but supplies no description of the train/profile/test partitioning used to build the per-API performance profiles. Without explicit confirmation that profiling data is disjoint from the instances used to compute the reported metrics, the filtering step risks data leakage and cannot be guaranteed to operate as described at true inference time on new code.
- [Evaluation] Evaluation section: no cross-validation results, no out-of-distribution experiments, and no analysis of whether the benchmark's tail distribution and context patterns match real developer usage are provided. The central claim that offline tail-aware profiles remain predictive of reliability at inference therefore rests on an untested assumption; this is load-bearing for the assertion that NvRec improves reliability rather than re-weighting toward well-covered APIs in the evaluation set.
minor comments (3)
- [Abstract] Abstract: the terms 'true accept rate' and 'rejection rate' are used without explicit definitions or formulas; a short paragraph or equation clarifying their computation (e.g., how 'highly reliable candidates' are identified) would improve clarity.
- [Abstract] Abstract: the three-version and five-version configurations employ different voting strategies ('majority voting restricted to highly reliable candidates' vs. 'simple majority voting'); the rationale for this difference and the precise reliability threshold should be stated.
- [Evaluation] Evaluation: individual model performances on the benchmark (especially on tail APIs) are not reported as baselines; adding a table comparing single-model true accept rates against the N-version results would strengthen the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the partitioning details and validation of the offline profiles in NvRec. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the manuscript reports headline numbers (83.8% true accept rate at 80.7% rejection for the three-version system) but supplies no description of the train/profile/test partitioning used to build the per-API performance profiles. Without explicit confirmation that profiling data is disjoint from the instances used to compute the reported metrics, the filtering step risks data leakage and cannot be guaranteed to operate as described at true inference time on new code.
Authors: We agree that the current manuscript does not provide an explicit description of the train/profile/test partitioning. The per-API performance profiles were generated offline on a dedicated profiling subset drawn from the public Java benchmark that is strictly disjoint from the test instances used to compute the reported true accept and rejection rates. This separation was enforced to ensure the reliability filters operate without leakage at inference time. We will revise the Evaluation section to include a clear description of the partitioning (including split ratios and confirmation of disjoint sets), along with a workflow diagram illustrating how profiles are built and applied. revision: yes
-
Referee: [Evaluation] Evaluation section: no cross-validation results, no out-of-distribution experiments, and no analysis of whether the benchmark's tail distribution and context patterns match real developer usage are provided. The central claim that offline tail-aware profiles remain predictive of reliability at inference therefore rests on an untested assumption; this is load-bearing for the assertion that NvRec improves reliability rather than re-weighting toward well-covered APIs in the evaluation set.
Authors: We concur that cross-validation, out-of-distribution experiments, and direct comparison of the benchmark's tail distribution against real developer usage patterns would provide stronger support for the generalizability of the offline profiles. The present evaluation demonstrates the practical trade-offs achieved by NvRec on the standard public Java benchmark. We will add a Limitations subsection discussing the reliance on the benchmark's observed tail properties and the assumption of profile predictiveness on unseen code, while outlining directions for future OOD and cross-validation studies. The reported gains remain valid within the benchmark setting used. revision: partial
Circularity Check
No circularity: empirical evaluation on external benchmark with no reducing derivations
full rationale
The paper describes an empirical N-version system (NvRec) that profiles off-the-shelf models (CodeBERT, CodeT5, etc.) on per-API performance including tail properties from a public Java benchmark dataset, then applies majority voting plus reliability filtering at inference. Reported figures such as 83.8% true accept rate at 80.7% rejection are direct outcome metrics from running the method on that dataset; no equations, fitted parameters, or self-citations are invoked that define or force these metrics by construction from the same experiment's inputs. The evaluation remains self-contained against the external benchmark and models, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- N (number of model versions)
- Reliability threshold for candidate filtering
axioms (1)
- domain assumption Majority agreement among models known to perform well on a given API improves recommendation reliability
Reference graph
Works this paper leans on
-
[1]
Java Platform, Standard Edition Java Development Kit Version 17 API Specification
2021. Java Platform, Standard Edition Java Development Kit Version 17 API Specification. URL: https://docs.oracle.com/en/java/javase/17/docs/api/
2021
-
[2]
Algirdas Avizienis. 1985. The N-version approach to fault-tolerant software.IEEE Transactions on software engineering12 (1985), 1491–1501
1985
-
[3]
Liming Chen and A. Avizienis. 1995. N-VERSION PROGRAMMINC: A FAULT- TOLERANCE APPROACH TO RELlABlLlTY OF SOFTWARE OPERATlON. In Twenty-Fifth International Symposium on Fault-Tolerant Computing, 1995, ’ High- lights from Twenty-Five Years’.113–. doi:10.1109/FTCSH.1995.532621
-
[4]
Herbsleb
Uri Dekel and James D. Herbsleb. 2009. Improving API documentation usability with knowledge pushing. In2009 IEEE 31st International Conference on Software Engineering. 320–330
2009
-
[5]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020. 1536–1547. doi:10.18653/ v1/2020.findings-emnlp.139
2020
-
[6]
Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2016. Deep API Learning. InProceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE 2016). 631–642. doi:10.1145/2950290. 2950334
-
[7]
Zuxing Gu, Jiecheng Wu, Jiaxiang Liu, Min Zhou, and Ming Gu. 2019. An Empirical Study on API-Misuse Bugs in Open-Source C Programs. In2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Vol. 1. 11–20
2019
-
[8]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin
-
[9]
Unixcoder: Unified cross-modal pre-training for code representation,
UniXcoder: Unified Cross-Modal Pre-training for Code Representation. arXiv:2203.03850 [cs.CL]
-
[10]
L. Heinemann, V. Bauer, M. Herrmannsdoerfer, and B. Hummel. 2012. Identifier- Based Context-Dependent API Method Recommendation. Inthe 16th European Conference on Software Maintenance and Reengineering. 31–40. doi:10.1109/CSMR. 2012.14
-
[11]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework.arXiv preprint arXiv:2308.00352(2024)
work page internal anchor Pith review arXiv 2024
-
[12]
arXiv preprint arXiv:2312.13010 , year=
Dong Huang, Jie M. Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, and Hem- ing Cui. 2024. AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation. arXiv:2312.13010 [cs.CL]
-
[13]
Ilham Cahya Irsan, Tianyi Zhang, Ferdian Thung, Kwangkeun Kim, and David Lo
-
[14]
InProceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2023)
Multi-Modal API Recommendation. InProceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2023). 272–
2023
-
[15]
doi:10.1109/SANER56733.2023.00034
-
[16]
Xia Li, Jiajun Jiang, Samuel Benton, Yingfei Xiong, and Lingming Zhang. 2021. A Large-scale Study on API Misuses in the Wild. In2021 14th IEEE Conference on Software Testing, Verification and Validation (ICST). 241–252
2021
-
[17]
Mario Linares-Vásquez, Gabriele Bavota, Carlos Bernal-Cárdenas, Massimiliano Di Penta, Rocco Oliveto, and Denys Poshyvanyk. 2013. API change and fault proneness: a threat to the success of Android apps. InProceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2013). 477–487
2013
-
[18]
Zexiong Ma, Shengnan An, Bing Xie, and Zeqi Lin. 2024. Compositional API Recommendation for Library-Oriented Code Generation.In the IEEE/ACM 32nd International Conference on Program Comprehension (ICPC)(2024), 87–98
2024
-
[19]
Fumio Machida. 2023. Using diversities to model the reliability of two-version machine learning systems.IEEE Transactions on Emerging Topics in Computing 12, 3 (2023), 810–825
2023
-
[20]
Pedro Martins, Rohan Achar, and Cristina V. Lopes. 2018. 50K-C: A Dataset of Compilable, and Compiled, Java Projects. In2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR). 1–5
2018
-
[21]
Michael Meng, Stephanie Steinhardt, and Andreas Schubert. 2019. How devel- opers use API documentation: an observation study.Commun. Des. Q. Rev7, 2 (2019), 40–49
2019
-
[22]
Siyu Nan, Jian Wang, Neng Zhang, Duantengchuan Li, and Bing Li. 2025. DDASR: Deep Diverse API Sequence Recommendation.ACM Transactions on Software Engineering and Methodology, Article 162 (2025), 39 pages
2025
-
[23]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. Gorilla: Large Language Model Connected with Massive APIs. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. 126544–126565
2024
-
[24]
Martin P. Robillard. 2009. What Makes APIs Hard to Learn? Answers from Developers.IEEE Software26, 6 (2009), 27–34. doi:10.1109/MS.2009.193
-
[25]
Robillard and Robert Deline
Martin P. Robillard and Robert Deline. 2011. A field study of API learning obstacles.Empirical Softw. Engg.16, 6 (2011), 703–732
2011
-
[26]
Christopher Scaffidi. 2006. Why are APIs difficult to learn and use?XRDS12, 4 (2006), 4. doi:10.1145/1144359.1144363
-
[27]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InThirty- seventh Conference on Neural Information Processing Systems
2023
- [28]
-
[29]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-Aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 8696–8708. doi:10.18653/v1/2021.emnlp- main.685
-
[30]
Xin Zhou, Kyungmin Kim, Bowen Xu, Junjie Liu, Dong Han, and David Lo. 2023. The Devil is in the Tails: How Long-Tailed Code Distributions Impact Large Language Models. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering (ASE 2023). 40–52. doi:10.1109/ASE56229. 2023.00157 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.