Recognition: unknown
PuzzleMark: Implicit Jigsaw Learning for Robust Code Dataset Watermarking in Neural Code Completion Models
Pith reviewed 2026-05-07 07:26 UTC · model grok-4.3
The pith
PuzzleMark embeds robust watermarks in code datasets using jigsaw concatenation for ownership verification of trained neural models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
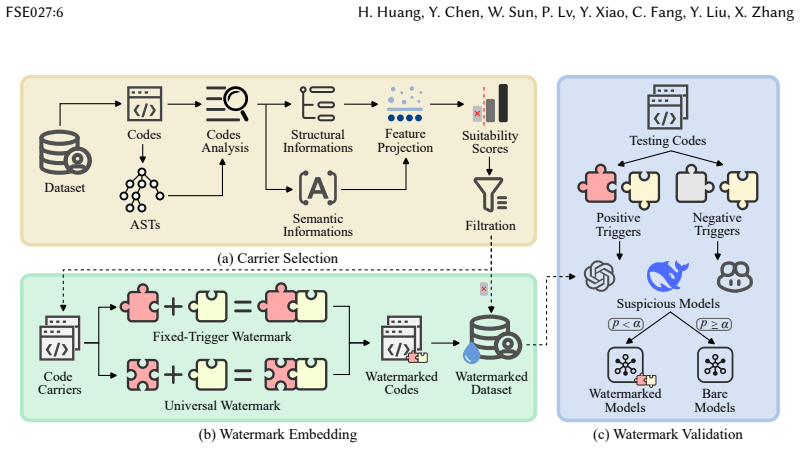
PuzzleMark replaces the traditional co-occurrence pattern with a novel concatenation pattern to embed watermarks via variable name manipulations in code snippets chosen by complexity evaluation. This adaptive embedding supports two watermarking strategies that maintain design simplicity and code characteristics. Verification then applies Fisher's exact test in a black-box setting to confirm whether a model was trained on the marked dataset, yielding 100% verification success and 0% false positive rates with negligible performance impact and high imperceptibility under human review and automated detectors.
What carries the argument
The novel concatenation pattern that implements two watermarking strategies through variable name concatenation, guided by code complexity carrier selection, to embed and statistically verify marks.
If this is right
- Dataset owners gain a reliable black-box method to authenticate unauthorized use in trained neural code models.
- Watermarked datasets produce models with performance indistinguishable from those trained on unmarked data.
- The marks stay hidden from both human evaluators and existing automated detection techniques.
- The method supplies a post-training authentication tool for protecting intellectual property in code datasets.
Where Pith is reading between the lines
- Similar concatenation-based marking could extend to protecting other structured training data such as configuration files or documentation.
- Long-term robustness would benefit from repeated testing against newly developed removal techniques over multiple training cycles.
- Dataset curators might integrate this selection and embedding process into standard pipelines to deter theft proactively.
- The statistical verification step could combine with other black-box ownership tests used in machine learning to strengthen evidence.
Load-bearing premise
That the complexity-based carrier selection and novel concatenation pattern will resist detection and removal attacks while remaining imperceptible and preserving model performance.
What would settle it
Apply variable renaming or refactoring attacks to a watermarked dataset, train a model on it, then test whether Fisher's exact test still returns 100% verification success on the resulting model.
Figures







read the original abstract
Constructing and curating high-quality code datasets requires significant resources, making them valuable intellectual property. Unfortunately, these datasets currently face severe risks of unauthorized use. Although digital watermarking offers a post hoc mechanism for copyright authentication, existing methods are predominantly based on the co-occurrence pattern, which is not robust and is susceptible to watermark detection and removal attacks. In this paper, we propose PuzzleMark, a robust watermarking method for code datasets. To reduce the risk of watermark exposure, PuzzleMark introduces a carrier selection strategy that leverages code complexity to evaluate the suitability of code snippets as watermark carriers, and selects those with high suitability for watermarking. To enhance the robustness of the watermark, PuzzleMark proposes a novel concatenation pattern to replace the traditional co-occurrence pattern, and implements two watermarking strategies through variable name concatenation. PuzzleMark adaptively embeds watermarks based on the inherent characteristics of the code, making it more stealthy while maintaining design simplicity. For watermark verification, PuzzleMark employs Fisher's exact test to verify suspicious models under a black-box setting. Experimental results demonstrate that PuzzleMark achieves a 100% verification success rate and a 0% false positive rate, with negligible impact on model performance. Both our human study and our evaluation using four state-of-the-art watermark detection methods show that PuzzleMark exhibits strong imperceptibility, with an average suspicious rate $\leq$ 0.24 and an average recall $\leq$ 30.41%, respectively. As a practical digital watermarking method, PuzzleMark provides strong protection for the intellectual property of code datasets and offers new insights for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PuzzleMark, a watermarking scheme for protecting code datasets used to train neural code completion models. It selects high-complexity code snippets as carriers, embeds watermarks via two strategies that concatenate variable names according to a novel pattern (replacing traditional co-occurrence), and verifies ownership in a black-box setting using Fisher's exact test on the observed concatenation frequencies. The authors report 100% verification success, 0% false positive rate, negligible degradation in model performance, and strong imperceptibility (suspicious rate ≤0.24 in human studies; recall ≤30.41% against four detection methods).
Significance. If the robustness and statistical separation claims hold under realistic conditions, PuzzleMark would offer a practical post-hoc mechanism for asserting ownership of valuable code datasets, addressing a growing IP concern in the training of code models. The complexity-based carrier selection and concatenation pattern represent a concrete departure from co-occurrence methods, and the black-box verification procedure is a positive design choice. However, the significance is limited by the absence of detailed baseline measurements needed to substantiate the 0% FPR claim.
major comments (2)
- [Abstract and experimental evaluation section] Abstract and experimental evaluation section: The headline claim of 0% false positive rate for the Fisher's exact test is load-bearing for the verification procedure, yet the manuscript provides no information on the number, diversity, programming languages, or training distributions of the clean (non-watermarked) models used to establish that the chosen variable-name concatenation patterns do not arise naturally at detectable rates. Without these details, it is impossible to assess whether the contingency-table test generalizes beyond the specific evaluation set or whether common code idioms could produce false positives on unseen models.
- [Experimental evaluation section] Experimental evaluation section: The robustness claims against watermark detection and removal attacks rest on the novel concatenation pattern and complexity-based carrier selection, but the manuscript does not report the specific attack models, parameter ranges, or long-term stability tests (e.g., fine-tuning or data augmentation) used to measure resistance. This leaves the central robustness argument under-supported relative to the 100% verification success reported.
minor comments (2)
- [Abstract] Ensure that the four state-of-the-art watermark detection methods referenced in the abstract are explicitly named and cited in the main body, together with the exact suspicious-rate and recall metrics obtained against each.
- [Method section] Clarify the precise definition of 'code complexity' used for carrier selection (e.g., which static or dynamic metrics) and how the suitability threshold is chosen, as this choice directly affects both stealth and embedding capacity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the clarity and completeness of our experimental reporting. We address each major comment below and have revised the manuscript to incorporate additional details where the original presentation was insufficient.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation section] Abstract and experimental evaluation section: The headline claim of 0% false positive rate for the Fisher's exact test is load-bearing for the verification procedure, yet the manuscript provides no information on the number, diversity, programming languages, or training distributions of the clean (non-watermarked) models used to establish that the chosen variable-name concatenation patterns do not arise naturally at detectable rates. Without these details, it is impossible to assess whether the contingency-table test generalizes beyond the specific evaluation set or whether common code idioms could produce false positives on unseen models.
Authors: We agree that the manuscript did not provide sufficient details on the clean models used to establish the 0% FPR. In the revised version, we have added a dedicated subsection (4.2.1) describing the evaluation: we tested 25 clean models spanning Python (15 models trained on CodeSearchNet and GitHub Python repositories), Java (5 models from diverse GitHub Java projects), and C++ (5 models from similar sources). These cover varied training distributions, including small-to-medium codebases and larger-scale repositories. For every clean model, Fisher's exact test on the target concatenation patterns produced p-values > 0.05, yielding 0% FPR. This addition directly addresses concerns about natural occurrence in common idioms and supports generalization beyond the watermarked evaluation set. revision: yes
-
Referee: [Experimental evaluation section] Experimental evaluation section: The robustness claims against watermark detection and removal attacks rest on the novel concatenation pattern and complexity-based carrier selection, but the manuscript does not report the specific attack models, parameter ranges, or long-term stability tests (e.g., fine-tuning or data augmentation) used to measure resistance. This leaves the central robustness argument under-supported relative to the 100% verification success reported.
Authors: We acknowledge that the specific attack configurations and long-term tests were not reported in sufficient detail. We have revised Section 4.3 to include: detection attacks used the four state-of-the-art methods from the imperceptibility evaluation with their default parameters; removal attacks consisted of fine-tuning on a 10% data subset for 3 epochs (learning rate 1e-5) and data augmentation via random variable renaming (20% probability) plus comment insertion. Long-term stability was evaluated by extending fine-tuning to 1, 5, and 10 epochs, with verification success remaining at 100% across all conditions. These additions provide the requested support for the robustness claims while preserving the original experimental outcomes. revision: yes
Circularity Check
No significant circularity; empirical claims rest on standard statistical test and external benchmarks
full rationale
The paper introduces an algorithmic construction (complexity-based carrier selection plus novel variable-name concatenation pattern) and evaluates it via black-box verification with Fisher's exact test on contingency tables of observed vs. expected co-occurrences. The 100% verification success rate follows directly from successful embedding (standard for watermarking schemes) while the 0% FPR is reported as an empirical measurement on clean models; neither reduces to a fitted parameter renamed as a prediction nor to a self-citation chain. No equations or sections exhibit self-definitional loops, ansatz smuggling, or uniqueness theorems imported from the authors' prior work. The human study and four external detection methods supply independent imperceptibility evidence. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fisher's exact test is appropriate and sufficient for verifying the presence of the watermark in black-box model queries.
Reference graph
Works this paper leans on
-
[1]
Mohammed Abuhamad, Tamer AbuHmed, Aziz Mohaisen, and DaeHun Nyang. 2018. Large-Scale and Language- Oblivious Code Authorship Identification. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18). Association for Computing Machinery, New York, NY, USA, 101–114. doi:10.1145/ 3243734.3243738
-
[3]
Amazon Web Services
Inc. Amazon Web Services. 2023. CodeWhisperer. https://aws.amazon.com/codewhisperer/
2023
-
[4]
Anubis. 2022. Anubis. https://github.com/0sir1ss/Anubis
2022
-
[5]
Lutz Büch and Artur Andrzejak. 2019. Learning-Based Recursive Aggregation of Abstract Syntax Trees for Code Clone Detection. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, Hangzhou, China, 95–104. doi:10.1109/SANER.2019.8668039
-
[6]
Molloy, and Biplav Srivastava
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian M. Molloy, and Biplav Srivastava. 2019. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering. InWorkshop on Artificial Intelligence Safety 2019 co-located with the Thirty-Third AAAI Conference on Artificial Intelligence 2019 (AAAI-19) (...
2019
-
[7]
Shuzheng Gao, Cuiyun Gao, Chaozheng Wang, Jun Sun, David Lo, and Yue Yu. 2023. Two Sides of the Same Coin: Exploiting the Impact of Identifiers in Neural Code Comprehension. InProceedings of the 45th International Conference on Software Engineering (ICSE ’23). IEEE Press, Los Alamitos, CA, USA, 1933–1945. doi:10.1109/ICSE48619.2023.00164
-
[8]
Inc. GitHub. 2022. GitHub Copilot. https://copilot.github.com/
2022
-
[9]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence.ArXivabs/2401.14196 (2024). https://arxiv.org/abs/2401.14196
work page internal anchor Pith review arXiv 2024
-
[10]
H. Hotelling. 1933. Analysis of a complex of statistical variables into principal components.Journal of Educational Psychology24 (1933), 417–441. Issue 6. doi:10.1037/h0071325
-
[11]
Chao Hu, Yitian Chai, Hao Zhou, Fandong Meng, Jie Zhou, and Xiaodong Gu. 2024. How Effectively Do Code Language Models Understand Poor-Readability Code?. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24). Association for Computing Machinery, New York, NY, USA, 795–806. doi:10.1145/3691620.3695072
-
[12]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search.arXivabs/1909.09436 (2019). arXiv:1909.09436 http: //arxiv.org/abs/1909.09436
work page internal anchor Pith review arXiv 2019
-
[13]
Vaibhavi Kalgutkar, Ratinder Kaur, Hugo Gonzalez, Natalia Stakhanova, and Alina Matyukhina. 2019. Code Authorship Attribution: Methods and Challenges.ACM Comput. Surv.52, 1, Article 3 (Feb. 2019), 36 pages. doi:10.1145/3292577
-
[14]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A Watermark for Large Language Models. InInternational Conference on Machine Learning (Proceedings of Machine Learning Re- search, Vol. 202). PMLR, Honolulu, Hawaii, USA, 17061–17084. https://proceedings.mlr.press/v202/kirchenbauer23a/ kirchenbauer23a.pdf
2023
-
[15]
Taehyun Lee, Seokhee Hong, Jaewoo Ahn, Ilgee Hong, Hwaran Lee, Sangdoo Yun, Jamin Shin, and Gunhee Kim
-
[16]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
Who Wrote this Code? Watermarking for Code Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Bangkok, Thailand, 4890–4911. https://aclanthology.org/2024.acl-long.268
2024
-
[17]
Jia Li, Zhuo Li, Huangzhao Zhang, Ge Li, Zhi Jin, Xing Hu, and Xin Xia. 2024. Poison Attack and Poison Detection on Deep Source Code Processing Models.ACM Trans. Softw. Eng. Methodol.33, 3 (2024), 62:1–62:31. doi:10.1145/3630008
-
[18]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: may the source be with you!Transactions on Machine Learning Research2023 (2023). https://openreview.net/forum?id=KoFOg41haE
2023
-
[19]
Vadim Markovtsev and Waren Long. 2018. Public git archive: a big code dataset for all. InProceedings of the 15th International Conference on Mining Software Repositories. Association for Computing Machinery, New York, NY, USA, 34–37. https://doi.org/10.1145/3196398.3196464
-
[20]
M.Brunsfeld, P.Thomson, A.Hlynskyi, J.Vera, P.Turnbull, T.Clem, D.Creager, A.Helwer, R.Rix, H.van Antwerpen, M.Davis, Ika, T.-A.Nguyen, S.Brunk, N.Hasabnis, bfredl, M.Dong, V.Panteleev, ikrima, S.Kalt, K.Lampe, A.Pinkus, M.Schmitz, M.Krupcale, narpfel, S.Gallegos, V.Martí, Edgar, and G.Fraser. 2020. Tree-sitter: An incremental parsing system for programmi...
2020
-
[21]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics. ACL, Philadelphia, PA, USA, 311–318. doi:10.3115/1073083.1073135
-
[22]
Karl Pearson. 1901. LIII. On lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science2, 11 (1901), 559–572. doi:10.1080/14786440109462720
-
[23]
Perforce. 2025. Klocwork. https://help.klocwork.com/current/en-us/concepts/functionandmethodlevelmetrics.htm
2025
-
[24]
Julie Peterson. 2025. Top Source Code Leaks, 2020-2025. https://cycode.com/blog/top-source-code-leaks-2020-2025/
2025
-
[25]
PuzzleMark. 2025. PuzzleMark. https://github.com/Fenriel/PuzzleMark
2025
-
[26]
Pyarmor. 2025. Pyarmor. https://github.com/dashingsoft/pyarmor
2025
-
[27]
Roei Schuster, Congzheng Song, Eran Tromer, and Vitaly Shmatikov. 2021. You Autocomplete Me: Poisoning Vul- nerabilities in Neural Code Completion. InProceedings of the 30th USENIX Security Symposium. USENIX Association, Vancouver, B.C., Canada, 1559–1575. https://www.usenix.org/conference/usenixsecurity21/presentation/schuster
2021
-
[28]
Weisong Sun, Yuchen Chen, Guanhong Tao, Chunrong Fang, Xiangyu Zhang, Quanjun Zhang, and Bin Luo. 2023. Backdooring Neural Code Search. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Toronto, Canada, 9692–9708. doi:10.18653/V1/2023.ACL- LONG.540
-
[29]
Weisong Sun, Yuchen Chen, Mengzhe Yuan, Chunrong Fang, Zhenpeng Chen, Chong Wang, Yang Liu, Baowen Xu, and Zhenyu Chen. 2025. Show Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness . In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, Los Alamitos, CA, USA, 2663–2675. doi:10....
-
[30]
Zhensu Sun, Xiaoning Du, Fu Song, and Li Li. 2023. CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, San Francisco, CA, USA, 1561–1572. doi:10.1145/3611643. 3616297
-
[31]
Zhensu Sun, Xiaoning Du, Fu Song, Mingze Ni, and Li Li. 2022. CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning. InWWW ’22: The ACM Web Conference 2022. ACM, Virtual Event, Lyon, France, 652–660. doi:10.1145/3485447.3512225
-
[32]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm.github.io/blog/qwen2.5/
2024
-
[33]
Brandon Tran, Jerry Li, and Aleksander Madry. 2018. Spectral Signatures in Backdoor Attacks. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems. Curran Associates, Montréal, Canada, 8011–8021. https://proceedings.neurips.cc/paper/2018/hash/280cf18baf4311c92aa5a042336587d3- Abstract.html
2018
-
[34]
Yao Wan, Shijie Zhang, Hongyu Zhang, Yulei Sui, Guandong Xu, Dezhong Yao, Hai Jin, and Lichao Sun. 2022. You see what I want you to see: poisoning vulnerabilities in neural code search. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, Singapore, Singapore, 1233–1245...
-
[35]
Shiqi Wang, Zheng Li, Haifeng Qian, Chenghao Yang, Zijian Wang, Mingyue Shang, Varun Kumar, Samson Tan, Baishakhi Ray, Parminder Bhatia, Ramesh Nallapati, Murali Krishna Ramanathan, Dan Roth, and Bing Xiang. 2023. ReCode: Robustness Evaluation of Code Generation Models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguist...
-
[36]
Yuan Xiao, Yuchen Chen, Shiqing Ma, Haocheng Huang, Chunrong Fang, Yanwei Chen, Weisong Sun, Yunfeng Zhu, Xiaofang Zhang, and Zhenyu Chen. 2025. DeCoMa: Detecting and Purifying Code Dataset Watermarks through Dual Channel Code Abstraction. InProceedings of the 34th ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Compu...
-
[37]
Shenao Yan, Shen Wang, Yue Duan, Hanbin Hong, Kiho Lee, Doowon Kim, and Yuan Hong. 2024. An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection. In33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, Philadelphia, PA, 1795–1812. https://www.usenix.org/conf...
2024
-
[38]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Ke-Yang Chen, Kexin Yang, Mei Li, Min Xue...
work page internal anchor Pith review arXiv 2024
- [39]
-
[40]
Zhang, Hong Jin Kang, Jieke Shi, Junda He, and David Lo
Zhou Yang, Bowen Xu, Jie M. Zhang, Hong Jin Kang, Jieke Shi, Junda He, and David Lo. 2024. Stealthy Backdoor Attack for Code Models.IEEE Trans. Software Eng.50, 4 (2024), 721–741. doi:10.1109/TSE.2024.3361661
-
[41]
Kwangsun Yoon and Ching Lai Hwang. 1995. Multiple attribute decision making.European Journal of Operational Research4, 4 (1995), 287–288
1995
-
[42]
Jiale Zhang, Haoxuan Li, Di Wu, Xiaobing Sun, Qinghua Lu, and Guodong Long. 2025. Beyond Dataset Watermarking: Model-Level Copyright Protection for Code Summarization Models. InProceedings of the ACM on Web Conference 2025. Association for Computing Machinery, New York, NY, USA, 147–157. doi:10.1145/3696410.3714641
-
[43]
Yuming Zhou, Yibiao Yang, Hongmin Lu, Lin Chen, Yanhui Li, Yangyang Zhao, Junyan Qian, and Baowen Xu. 2018. How Far We Have Progressed in the Journey? An Examination of Cross-Project Defect Prediction.ACM Trans. Softw. Eng. Methodol.27, 1, Article 1 (April 2018), 51 pages. doi:10.1145/3183339 Received 2025-09-12; accepted 2025-12-22 Proc. ACM Softw. Eng.,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.