Recognition: unknown
Bridging Values and Behavior: A Hierarchical Framework for Proactive Embodied Agents
Pith reviewed 2026-05-07 07:40 UTC · model grok-4.3
The pith
ValuePlanner uses an LLM to turn competing abstract values into subgoals that a PDDL planner executes, enabling long-horizon self-directed behavior in embodied agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ValuePlanner is a hierarchical architecture that decouples high-level value scheduling from low-level action execution: an LLM-based cognitive module generates symbolic subgoals by reasoning through abstract value trade-offs, which are then translated into executable action plans by a classical PDDL planner, with closed-loop feedback to refine the process and produce coherent long-horizon behavior.
What carries the argument
The LLM-based cognitive module that arbitrates competing values to produce symbolic subgoals, paired with a PDDL planner for grounded execution and feedback refinement.
Load-bearing premise
The LLM cognitive module can reliably reason about abstract value trade-offs to output accurate symbolic subgoals without hallucinations or misalignments that the planner cannot correct.
What would settle it
If ValuePlanner agents in the TongSim environment fail to show higher cumulative value gain, preference alignment, or behavioral diversity than instruction-following or needs-driven baselines, the central claim would be falsified.
Figures



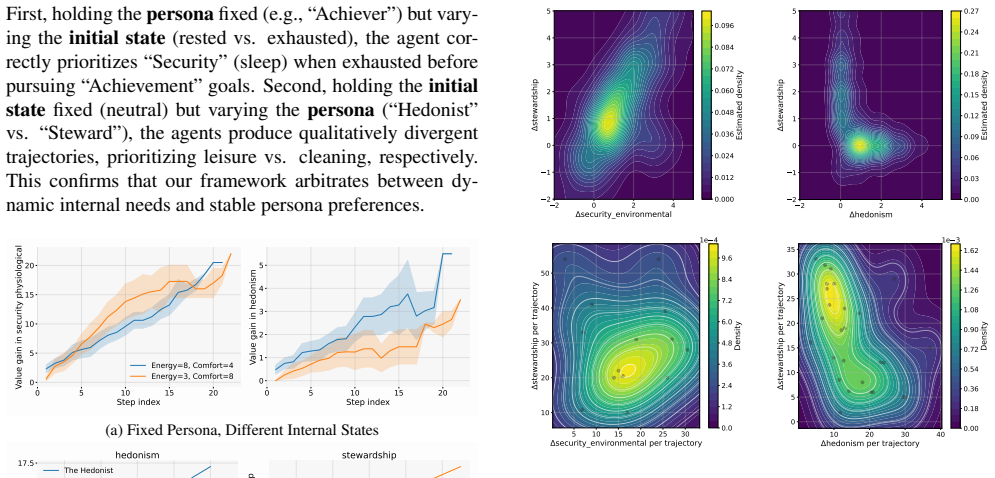

read the original abstract
Current embodied agents are often limited to passive instruction-following or reactive need-satisfaction, lacking a stable, high-order value framework essential for long-term, self-directed behavior and resolving motivational conflicts. We introduce \textit{ValuePlanner}, a hierarchical cognitive architecture that decouples high-level value scheduling from low-level action execution. \textit{ValuePlanner} employs an LLM-based cognitive module to generate symbolic subgoals by reasoning through abstract value trade-offs, which are then translated into executable action plans by a classical PDDL planner. This process is refined via a closed-loop feedback mechanism. Evaluating such autonomy requires methods beyond task-success rates, and we therefore propose a value-centric evaluation suite measuring cumulative value gain, preference alignment, and behavioral diversity. Experiments in the TongSim household environment demonstrate that \textit{ValuePlanner} arbitrates competing values to generate coherent, long-horizon, self-directed behavior absent from instruction-following and needs-driven baselines. Our work offers a structured approach to bridging intrinsic values and grounded behavior for autonomous agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ValuePlanner, a hierarchical framework for proactive embodied agents. It decouples high-level value scheduling using an LLM-based cognitive module that reasons through abstract value trade-offs to generate symbolic subgoals, which are then translated into executable plans by a PDDL planner with closed-loop feedback. The work proposes value-centric evaluation metrics including cumulative value gain, preference alignment, and behavioral diversity. Experiments in the TongSim household environment show that ValuePlanner generates coherent, long-horizon, self-directed behavior that is absent in instruction-following and needs-driven baselines.
Significance. If the experimental results hold, this framework offers a promising approach to integrating intrinsic values into embodied agent behavior, enabling more autonomous and conflict-resolving agents. The introduction of value-centric metrics is a valuable contribution for assessing such systems beyond traditional task success rates. The hierarchical decoupling of value reasoning from execution is a sound architectural choice that could be extended to other domains.
major comments (2)
- [Experiments section] The manuscript lacks quantitative diagnostics on the LLM cognitive module's performance, such as the rate of hallucinated or misaligned subgoals, the number of closed-loop feedback iterations per episode, and cases where value misalignment persists into executed plans. This is critical because the central claim that ValuePlanner arbitrates competing values to produce coherent behavior relies on the LLM reliably producing usable subgoals; without these metrics, it is unclear whether improvements stem from value arbitration or from the PDDL planner and simulator masking inconsistencies.
- [Evaluation suite] The value-centric metrics (cumulative value gain, preference alignment, behavioral diversity) are proposed, but the paper does not report how these are computed in detail or provide ablations showing that they correlate with the claimed arbitration capability. For example, it is possible for these metrics to improve due to longer planning horizons alone, independent of value trade-off reasoning.
minor comments (2)
- [Abstract] The abstract mentions 'absent from instruction-following and needs-driven baselines' but does not specify the exact implementation of these baselines, which would help readers understand the comparison.
- [Notation] The use of 'ValuePlanner' is clear, but ensure consistent capitalization and definition of terms like 'symbolic subgoals' and 'PDDL planner' throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify important opportunities to strengthen the transparency of our experimental analysis and the rigor of our evaluation. We address each major comment below and commit to incorporating the requested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments section] The manuscript lacks quantitative diagnostics on the LLM cognitive module's performance, such as the rate of hallucinated or misaligned subgoals, the number of closed-loop feedback iterations per episode, and cases where value misalignment persists into executed plans. This is critical because the central claim that ValuePlanner arbitrates competing values to produce coherent behavior relies on the LLM reliably producing usable subgoals; without these metrics, it is unclear whether improvements stem from value arbitration or from the PDDL planner and simulator masking inconsistencies.
Authors: We agree that quantitative diagnostics on the LLM cognitive module are essential for substantiating the claim that value arbitration drives the observed improvements. The current manuscript reports end-to-end results and qualitative examples but does not include the requested module-level statistics. In the revised version we will add a dedicated subsection 'Diagnostics of the Cognitive Module' that reports: (i) the rate of hallucinated or misaligned subgoals (measured by post-hoc human annotation of 100 randomly sampled subgoals against the value principles and current simulator state), (ii) the mean and distribution of closed-loop feedback iterations per episode, and (iii) representative cases in which value misalignment persisted after feedback. These additions will allow readers to assess the reliability of the LLM-generated subgoals independently of the PDDL planner and simulator. revision: yes
-
Referee: [Evaluation suite] The value-centric metrics (cumulative value gain, preference alignment, behavioral diversity) are proposed, but the paper does not report how these are computed in detail or provide ablations showing that they correlate with the claimed arbitration capability. For example, it is possible for these metrics to improve due to longer planning horizons alone, independent of value trade-off reasoning.
Authors: We acknowledge that the manuscript introduces the value-centric metrics without sufficient computational detail or targeted ablations. In the revision we will expand the 'Value-Centric Evaluation Suite' section to include explicit formulas: cumulative value gain as the discounted sum of per-timestep value satisfaction scores obtained from the agent's predefined value functions; preference alignment as the average cosine similarity between the vector of executed subgoal values and the agent's static value priority vector; and behavioral diversity as the normalized entropy over the distribution of subgoal categories across episodes. To address the potential confound of planning horizon, we will add an ablation that disables explicit value-trade-off reasoning in the LLM prompt while keeping all other components identical, and we will report mean episode lengths for all conditions. These changes will demonstrate that metric gains are attributable to value arbitration rather than horizon length alone. revision: yes
Circularity Check
No significant circularity; architecture is independently specified without self-referential reductions
full rationale
The paper presents ValuePlanner as a novel hierarchical architecture that decouples LLM-based value reasoning from PDDL planning with closed-loop refinement, then evaluates it via newly proposed value-centric metrics (cumulative value gain, preference alignment, behavioral diversity) in the TongSim environment. No equations, fitted parameters, or derivations appear in the abstract or description that would reduce any claimed prediction or result to the inputs by construction. The central claim rests on experimental demonstration of coherent behavior rather than tautological definitions or self-citation chains. No load-bearing steps match the enumerated circularity patterns; the framework is self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-based cognitive module can generate symbolic subgoals by reasoning through abstract value trade-offs
- domain assumption Classical PDDL planner can reliably translate subgoals into executable action plans
invented entities (1)
-
ValuePlanner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[2]
David Bai, Ishika Singh, David Traum, and Jesse Thoma- son. Twostep: Multi-agent task planning using classi- cal planners and large language models.arXiv preprint arXiv:2403.17246, 2024. 3
-
[3]
Language- augmented symbolic planner for open-world task planning
Guanqi Chen, Lei Yang, Ruixing Jia, Zhe Hu, Yizhou Chen, Wei Zhang, Wenping Wang, and Jia Pan. Language- augmented symbolic planner for open-world task planning. arXiv preprint arXiv:2407.09792, 2024. 2
-
[4]
Heuristic satisficing inferential decision making in human and robot active per- ception.Frontiers in Robotics and AI, 11:1384609, 2024
Yucheng Chen, Pingping Zhu, Anthony Alers, Tobias Egner, Marc A Sommer, and Silvia Ferrari. Heuristic satisficing inferential decision making in human and robot active per- ception.Frontiers in Robotics and AI, 11:1384609, 2024. 1
2024
-
[5]
Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks.IEEE Trans- actions on Cognitive and Developmental Systems, 2025
Yaran Chen, Wenbo Cui, Yuanwen Chen, Mining Tan, Xinyao Zhang, Jinrui Liu, Haoran Li, Dongbin Zhao, and He Wang. Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks.IEEE Trans- actions on Cognitive and Developmental Systems, 2025. 1
2025
-
[6]
Cristina Cornelio, Flavio Petruzzellis, and Pietro Lio. Hierar- chical planning for complex tasks with knowledge graph-rag and symbolic verification.arXiv preprint arXiv:2504.04578,
-
[7]
Gautier Dagan, Frank Keller, and Alex Lascarides. Dynamic planning with a LLM. InNeurIPS 2024 Workshop on Lan- guage Gamification, 2024. arXiv:2308.06391. 3, 6
-
[8]
Can llm be a good path planner based on prompt engineer- ing? mitigating the hallucination for path planning
Hourui Deng, Hongjie Zhang, Jie Ou, and Chaosheng Feng. Can llm be a good path planner based on prompt engineer- ing? mitigating the hallucination for path planning. InInter- national Conference on Intelligent Computing, pages 3–15. Springer, 2025. 2
2025
-
[9]
Ui-jepa: Towards active perception of user intent through onscreen user activity
Yicheng Fu, Raviteja Anantha, Prabal Vashisht, Jianpeng Cheng, and Etai Littwin. Ui-jepa: Towards active perception of user intent through onscreen user activity. InProceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, pages 224–233, 2025. 1
2025
-
[10]
The fast downward planning system.Journal of Artificial Intelligence Research, 26:191–246, 2006
Malte Helmert. The fast downward planning system.Journal of Artificial Intelligence Research, 26:191–246, 2006. 2, 6, 1
2006
-
[11]
Concise finite-domain representations for PDDL planning tasks.Artificial Intelligence, 173(5–6):503– 535, 2009
Malte Helmert. Concise finite-domain representations for PDDL planning tasks.Artificial Intelligence, 173(5–6):503– 535, 2009. 1
2009
-
[12]
On the limit of language mod- els as planning formalizers
Cassie Huang and Li Zhang. On the limit of language mod- els as planning formalizers. InProceedings of the 63rd An- 9 nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 4880–4904, 2025. 2
2025
-
[13]
An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023. 1
-
[14]
How different groups prioritize ethical values for responsible ai
Maurice Jakesch, Zana Buc ¸inca, Saleema Amershi, and Alexandra Olteanu. How different groups prioritize ethical values for responsible ai. Inproceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 310–323, 2022. 1
2022
-
[15]
Dehalluci- nating large language models using formal methods guided iterative prompting
Susmit Jha, Sumit Kumar Jha, Patrick Lincoln, Nathaniel D Bastian, Alvaro Velasquez, and Sandeep Neema. Dehalluci- nating large language models using formal methods guided iterative prompting. In2023 IEEE International Conference on Assured Autonomy (ICAA), pages 149–152. IEEE, 2023. 2
2023
-
[16]
PhD thesis, University of Pennsylvania, 2025
Wen Jiang.Active Perception for 3D Scene Representations in Robotics from an Information Theoretic Perspective. PhD thesis, University of Pennsylvania, 2025. 1
2025
-
[17]
arXiv preprint arXiv:2402.01817 , year=
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, and Anil Murthy. Llms can’t plan, but can help planning in llm-modulo frameworks.arXiv preprint arXiv:2402.01817, 2024. 2, 3
-
[18]
Are the values of llms struc- turally aligned with humans? a causal perspective
Yipeng Kang, Junqi Wang, Yexin Li, Mengmeng Wang, Wenming Tu, Quansen Wang, Hengli Li, Tingjun Wu, Xue Feng, Fangwei Zhong, et al. Are the values of llms struc- turally aligned with humans? a causal perspective. InFind- ings of the Association for Computational Linguistics: ACL 2025, pages 23147–23161, 2025. 3
2025
-
[19]
Embodied agent inter- face: Benchmarking llms for embodied decision making
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Er- ran Li Li, Ruohan Zhang, et al. Embodied agent inter- face: Benchmarking llms for embodied decision making. Advances in Neural Information Processing Systems, 37: 100428–100534, 2024. 3, 5, 6
2024
-
[20]
Towards human- like virtual beings: Simulating human behavior in 3d scenes
Chen Liang, Wenguan Wang, and Yi Yang. Towards human- like virtual beings: Simulating human behavior in 3d scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10753–10763, 2025. 1
2025
-
[21]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[22]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. Llm+ p: Empower- ing large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[23]
Embodied in- telligence: A synergy of morphology, action, perception and learning.ACM Computing Surveys, 57(7):1–36, 2025
Huaping Liu, Di Guo, and Angelo Cangelosi. Embodied in- telligence: A synergy of morphology, action, perception and learning.ACM Computing Surveys, 57(7):1–36, 2025. 1
2025
-
[24]
Haowei Liu, Xi Zhang, Haiyang Xu, Yuyang Wanyan, Jun- yang Wang, Ming Yan, Ji Zhang, Chunfeng Yuan, Chang- sheng Xu, Weiming Hu, et al. Pc-agent: A hierarchical multi-agent collaboration framework for complex task au- tomation on pc.arXiv preprint arXiv:2502.14282, 2025. 1
-
[25]
Zeyi Liu, Arpit Bahety, and Shuran Song. Reflect: Summa- rizing robot experiences for failure explanation and correc- tion.arXiv preprint arXiv:2306.15724, 2023. 1, 3
-
[26]
Yi-Long Lu, Jiajun Song, Chunhui Zhang, and Wei Wang. Mind the gap: The divergence between human and llm- generated tasks.arXiv preprint arXiv:2508.00282, 2025. 3
-
[27]
Robots that adaptively learn when to ask for help: Hallucination reduction in robotic task planning using large language models
Aurora Misic. Robots that adaptively learn when to ask for help: Hallucination reduction in robotic task planning using large language models. Master’s thesis, NTNU, 2024. 2
2024
-
[28]
Plansformer: Generating symbolic plans using transformers,
Vishal Pallagani, Bharath Muppasani, Keerthiram Muruge- san, Francesca Rossi, Lior Horesh, Biplav Srivastava, Francesco Fabiano, and Andrea Loreggia. Plansformer: Generating symbolic plans using transformers.arXiv preprint arXiv:2212.08681, 2022. 2
-
[29]
The tong test: Evaluating artificial gen- eral intelligence through dynamic embodied physical and so- cial interactions.Engineering, 34:12–22, 2024
Yujia Peng, Jiaheng Han, Zhenliang Zhang, Lifeng Fan, Tengyu Liu, Siyuan Qi, Xue Feng, Yuxi Ma, Yizhou Wang, and Song-Chun Zhu. The tong test: Evaluating artificial gen- eral intelligence through dynamic embodied physical and so- cial interactions.Engineering, 34:12–22, 2024. 6
2024
-
[30]
Ethical guidelines for the use of artificial intelligence and the challenges from value conflicts
Thomas Søbirk Petersen. Ethical guidelines for the use of artificial intelligence and the challenges from value conflicts. Etikk i Praksis-Nordic Journal of Applied Ethics, 1(1):25– 40, 2021. 1
2021
-
[31]
Mp5: A multi-modal open-ended embodied system in minecraft via active perception
Yiran Qin, Enshen Zhou, Qichang Liu, Zhenfei Yin, Lu Sheng, Ruimao Zhang, Yu Qiao, and Jing Shao. Mp5: A multi-modal open-ended embodied system in minecraft via active perception. In2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 16307– 16316. IEEE, 2024. 1
2024
-
[32]
Valuenet: A new dataset for human value driven dialogue system
Liang Qiu, Yizhou Zhao, Jinchao Li, Pan Lu, Baolin Peng, Jianfeng Gao, and Song-Chun Zhu. Valuenet: A new dataset for human value driven dialogue system. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11183– 11191, 2022. 3
2022
-
[33]
Yuanyi Ren, Haoran Ye, Hanjun Fang, Xin Zhang, and Guo- jie Song. Valuebench: Towards comprehensively evaluating value orientations and understanding of large language mod- els.arXiv preprint arXiv:2406.04214, 2024. 3
-
[34]
The LAMA planner: Guiding cost-based anytime planning with landmarks.Jour- nal of Artificial Intelligence Research, 39:127–177, 2010
Silvia Richter and Matthias Westphal. The LAMA planner: Guiding cost-based anytime planning with landmarks.Jour- nal of Artificial Intelligence Research, 39:127–177, 2010. 1
2010
-
[35]
Personal values in human life.Nature human behaviour, 1(9):630–639, 2017
Lilach Sagiv, Sonia Roccas, Jan Cieciuch, and Shalom H Schwartz. Personal values in human life.Nature human behaviour, 1(9):630–639, 2017. 1, 3
2017
-
[36]
An overview of the schwartz theory of basic values.Online readings in Psychology and Culture, 2 (1):11, 2012
Shalom H Schwartz. An overview of the schwartz theory of basic values.Online readings in Psychology and Culture, 2 (1):11, 2012. 1, 3, 8
2012
-
[37]
A weighted kendall’s tau statistic.Statistics & probability letters, 39(1):17–24, 1998
Grace S Shieh. A weighted kendall’s tau statistic.Statistics & probability letters, 39(1):17–24, 1998. 6
1998
-
[38]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural in- formation processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural in- formation processing systems, 36:8634–8652, 2023. 3, 6, 7
2023
-
[39]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 2998–3009, 2023. 2, 3 10
2023
-
[40]
Active semantic percep- tion.arXiv preprint arXiv:2510.05430, 2025
Huayi Tang and Pratik Chaudhari. Active semantic percep- tion.arXiv preprint arXiv:2510.05430, 2025. 1
-
[41]
MIT Press, 2025
Francisco J Varela.Principles of biological autonomy. MIT Press, 2025. 1
2025
-
[42]
Cognitive vision: The case for embodied per- ception.Image and Vision Computing, 26(1):127–140, 2008
David Vernon. Cognitive vision: The case for embodied per- ception.Image and Vision Computing, 26(1):127–140, 2008. 1
2008
-
[43]
Medical ai, categories of value conflict, and conflict bypasses
Gavin Victor and Jean-Christophe B´elisle-Pipon. Medical ai, categories of value conflict, and conflict bypasses. InPro- ceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pages 1482–1489, 2024. 1
2024
-
[44]
Active perception for visual-language navigation.International Journal of Com- puter Vision, 131(3):607–625, 2023
Hanqing Wang, Wenguan Wang, Wei Liang, Steven CH Hoi, Jianbing Shen, and Luc Van Gool. Active perception for visual-language navigation.International Journal of Com- puter Vision, 131(3):607–625, 2023. 1
2023
-
[45]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models.arXiv preprint arXiv:2305.04091,
-
[46]
Simulating human-like daily activities with desire-driven autonomy.arXiv preprint arXiv:2412.06435,
Yiding Wang, Yuxuan Chen, Fangwei Zhong, Long Ma, and Yizhou Wang. Simulating human-like daily activities with desire-driven autonomy.arXiv preprint arXiv:2412.06435,
-
[47]
Large language models are better reasoners with self-verification
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. InFindings of the Association for Computational Linguis- tics: EMNLP 2023, pages 2550–2575, 2023. 7
2023
-
[48]
Translating natural language to planning goals with large-language models,
Yaqi Xie, Chen Yu, Tongyao Zhu, Jinbin Bai, Ze Gong, and Harold Soh. Translating natural language to plan- ning goals with large-language models.arXiv preprint arXiv:2302.05128, 2023. 3
-
[49]
Siheng Xiong, Jieyu Zhou, Zhangding Liu, and Yusen Su. Symplanner: Deliberate planning in language models with symbolic representation.arXiv preprint arXiv:2505.01479,
-
[50]
Rui Yang, Xiaoman Pan, Feng Luo, Shuang Qiu, Han Zhong, Dong Yu, and Jianshu Chen. Rewards-in-context: Multi- objective alignment of foundation models with dynamic preference adjustment.arXiv preprint arXiv:2402.10207,
-
[51]
3d-mem: 3d scene memory for embodied exploration and reasoning
Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 17294–17303, 2025. 1
2025
-
[52]
Agentic robot: A brain-inspired framework for vision-language-action models in embodied agents,
Zhejian Yang, Yongchao Chen, Xueyang Zhou, Jiangyue Yan, Dingjie Song, Yinuo Liu, Yuting Li, Yu Zhang, Pan Zhou, Hechang Chen, et al. Agentic robot: A brain-inspired framework for vision-language-action models in embodied agents.arXiv preprint arXiv:2505.23450, 2025. 1
-
[53]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022. 1, 3, 6, 7
2022
-
[54]
Embodied ai: A survey on the evo- lution from perceptive to behavioral intelligence.SmartBot, page e70003, 2025
Chen Yifan, Mingjie Wei, Xuesong Wang, Yuanxing Liu, Jizhe Wang, Hao Song, Longxuan Ma, Donglin Di, Churui Sun, Kaifeng Liu, et al. Embodied ai: A survey on the evo- lution from perceptive to behavioral intelligence.SmartBot, page e70003, 2025. 1
2025
-
[55]
In situ bidirectional human-robot value alignment.Science robotics, 7(68):eabm4183, 2022
Luyao Yuan, Xiaofeng Gao, Zilong Zheng, Mark Edmonds, Ying Nian Wu, Federico Rossano, Hongjing Lu, Yixin Zhu, and Song-Chun Zhu. In situ bidirectional human-robot value alignment.Science robotics, 7(68):eabm4183, 2022. 3
2022
-
[56]
Mitigating spatial hallucination in large language models for path planning via prompt engineering.Scientific Reports, 15 (1):8881, 2025
Hongjie Zhang, Hourui Deng, Jie Ou, and Chaosheng Feng. Mitigating spatial hallucination in large language models for path planning via prompt engineering.Scientific Reports, 15 (1):8881, 2025. 2
2025
-
[57]
Unrealzoo: Enriching photo- realistic virtual worlds for embodied ai
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. Unrealzoo: Enriching photo- realistic virtual worlds for embodied ai. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 5769–5779, 2025. 1
2025
-
[58]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 3 11 Bridging Values and Behavior: A Hierarchical Framework for Proactive Embodied Age...
2023
-
[59]
PDDL Fail
Intrinsic Value System andV aluePlanner Execution Loop Table 5 defines the seven value dimensions that jointly pa- rameterize the persona vectorwused to evaluate trajecto- ries. Building on this value representation, Algorithm 1 de- scribes theValuePlannerexecution loop, which iteratively proposes, grounds, and executes sub-goals under a PDDL- based symbo...
-
[60]
nurture and maintain
Experiment Environment: TongSim We instantiate TongSim as a multi-room household envi- ronment populated with 94 object instances spanning furni- ture, appliances, daily items, and environment-level inter- actables, each mapped to a compact set of core PDDL types that define the symbolic state spaces env t . Table 7 sum- marizes these objects by functiona...
-
[61]
To ensure reproducibility, we detail the modular text blocks (variables) shared across different agents, followed by the specific architectural prompts for each method
Prompts In this section, we provide the complete set of system prompts used for theValuePlannerframework, the baseline com- parisons, and the evaluation metrics. To ensure reproducibility, we detail the modular text blocks (variables) shared across different agents, followed by the specific architectural prompts for each method. All modules interact with ...
-
[62]
** Object Naming **: All interactable objects in the world have a unique ID in the format ‘ objectType_instanceNumber ‘ ( e . g . , ‘ apple_1 ‘ , ‘ chair_3 ‘) . In PDDL , these IDs are used directly , but they are case - sensitive . Please use the exact IDs provided in the environment description
-
[63]
You do not need to search for objects ; if an object is not in the list , you cannot see or interact with it
** Object Visibility **: The ‘ Current World State ( PDDL Facts : ‘: objects ‘ and ‘: init ‘) ‘ includes a complete list of all objects currently available to you . You do not need to search for objects ; if an object is not in the list , you cannot see or interact with it
-
[64]
A low - level planner will be responsible for finding the actions to reach these states
** PDDL States **: Your subgoals must be expressed using valid PDDL predicates that describe a desired state of the world . A low - level planner will be responsible for finding the actions to reach these states
-
[65]
** Strictly Adhere to Predicate Definitions **: The ‘ Available PDDL Predicates ‘ section provides the exact definition for each predicate , including the required ‘ type ‘ for each 5 parameter ( e . g . , ‘( on_surface ? i - object ? s - surface ) ‘ requires the first parameter to be an ‘ object ‘ and the second to be a ‘ surface ‘) . You MUST ensure tha...
-
[66]
Static properties like ‘( is_sittable ? s ) ‘ are defined ** only ** in the ‘: init ‘ facts
** Verify Object Affordances **: Before generating a subgoal , you must verify that the target object possesses the necessary properties ( affordances ) for the intended state . Static properties like ‘( is_sittable ? s ) ‘ are defined ** only ** in the ‘: init ‘ facts . If a predicate for an object ( e . g . , ‘( is_sittable desk_1 ) ‘) is not explicitly...
-
[67]
Do NOT specify intermediate actions or the process to get there
** Focus on ’ What ’ , Not ’How ’**: Your subgoals must describe the * final , desired state * of the world . Do NOT specify intermediate actions or the process to get there . For instance , to get a cup of water , the goal should be ‘( f i l le d _w i t h_ l i qu i d cup_1 ) ‘, not ‘( and ( switched_on faucet_1 ) ( f i ll e d _w i t h_ l i qu i d cup_1 )...
-
[68]
High - level subgoals should not target transient agent states like ‘ agent_at ‘ , ‘ agent_in ‘ , ‘ hand_empty ‘ , ‘ object_in ‘ , or ‘ is_standing ‘
** Target Durable and Specific Outcomes **: 14* Focus on lasting changes to objects or the environment . High - level subgoals should not target transient agent states like ‘ agent_at ‘ , ‘ agent_in ‘ , ‘ hand_empty ‘ , ‘ object_in ‘ , or ‘ is_standing ‘. While these are often necessary preconditions , they are handled by the low - level planner ; your ta...
-
[69]
** Use the Most Semantically Appropriate Predicate **: Given the available predicates , choose the one that most accurately describes the intended state . For example , when putting items inside a container like a cupboard or refrigerator , ‘( in_receptacle ? item ? container ) ‘ is more precise and semantically correct than ‘( on_surface ? item ? container ) ‘
-
[70]
20* ** Logical Sequencing **: For complex plans , decompose them into a logical sequence of subgoals where each represents a milestone
** Respect Physical and Logical Constraints **: 19* ** Physical Plausibility **: Your subgoals must be physically plausible . 20* ** Logical Sequencing **: For complex plans , decompose them into a logical sequence of subgoals where each represents a milestone . The sequence must be consistent and efficient . Ensure all prerequisites for an activity are m...
-
[71]
Avoid creating overly complex subgoals that combine many distinct , parallel state changes into one large ‘( and ...) ‘ condition ( e
** Maintain Subgoal Granularity **: Each subgoal should represent a focused milestone . Avoid creating overly complex subgoals that combine many distinct , parallel state changes into one large ‘( and ...) ‘ condition ( e . g . , more than 3 predicates ) . Such goals can be computationally intractable . Decompose complex desired states into a logical sequ...
-
[72]
Your new plan must rigorously address every point in the critique
** Plan Refinement Based on Critique **: If you receive feedback on a previously generated plan , you MUST treat it as a primary directive . Your new plan must rigorously address every point in the critique . In your ‘ thought ‘ process , explicitly detail how your revised plan corrects the flaws or incorporates the suggestions . Simply generating a diffe...
-
[76]
You must use the available PDDL predicates
** Define Subgoal Sequence **: For each plan , define a precise sequence of PDDL subgoals required to complete it . You must use the available PDDL predicates . 11{ Reflection Instruction } 9.2.2. Critic System Prompt 1 2You are an expert critic for a value - driven AI agent in a simulated environment . Your task is to rigorously evaluate a high - level p...
-
[77]
** Analyze the Trajectoryτ**: Review the proposed plan and simulate the sequence of state changes (s 0,∆s 1,· · ·,∆s T ) it will produce
-
[78]
** Calculate Expected Value Gains **: For each dimensioni, calculate the objective gain ∆Vi(τ)based on the principles above
-
[79]
Is this the highest possible weighted total value∆V?
** Challenge the Plan ’ s Optimality **: With the objective gains calculated , consider the agent ’ s preferencesw i and ask : " Is this the highest possible weighted total value∆V?" To answer this , you must assess : 15- ** C omp re he ns ive ne ss **: Does the plan consider all relevant value dimensions ? Does it leverage all available objects in the en...
-
[80]
For instance , does the plan leave the agent in a depleted state , and could a better plan include subgoals to recover ( e
** Propose Alternatives **: If you can identify an alternative or modified plan that yields a better overall outcome by making superior trade - offs or capturing missed opportunities , you must propose it with specific , actionable feedback . For instance , does the plan leave the agent in a depleted state , and could a better plan include subgoals to rec...
-
[81]
** Maintain Alignment with Core Values **: Your primary goal is not just to fix the plan , but to ensure the adjusted plan still represents the best path toward maximizing your overall value gain
-
[82]
** Re - evaluate Goal Semantics and Arguments **: Look at the failed action and the world state to ensure the subgoal is still the best way to express the intent . This includes two checks : 12* ** Predicate Choice **: Is the predicate the most logical one for the objects involved ? For example , if a plan was to place an object ‘( on_surface ? obj ? rece...
-
[83]
For example , instead of ‘( and ( switched_on faucet_1 ) ( f il l e d_ w i th _ l iq u i d cup_1 ) ) ‘, a better subgoal is simply ‘( f i ll e d _w i th _ l iq u i d cup_1 ) ‘
** Focus on Outcomes , Not Actions **: Your subgoals should describe the desired final state ( ‘ what ‘) , not the specific actions to get there ( ‘ how ‘) . For example , instead of ‘( and ( switched_on faucet_1 ) ( f il l e d_ w i th _ l iq u i d cup_1 ) ) ‘, a better subgoal is simply ‘( f i ll e d _w i th _ l iq u i d cup_1 ) ‘. The low - level planne...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.