Recognition: unknown
Mind the Gap: Structure-Aware Consistency in Preference Learning
Pith reviewed 2026-05-07 06:36 UTC · model grok-4.3
The pith
Standard surrogate losses in LLM preference alignment are inconsistent for equicontinuous neural networks, but structure-aware margin adaptation and heavy-tailed losses restore consistency guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
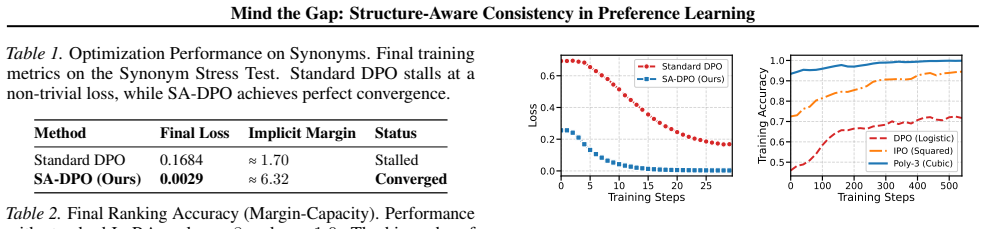
Standard surrogates used in methods such as DPO are theoretically inconsistent for the equicontinuous hypothesis sets typical of neural networks, producing vacuous generalization guarantees. Embedding alignment inside a margin-shifted ranking framework yields rigorous H-consistency bounds that depend on the enforced separation margin gamma. Extending the framework to structure-aware H-consistency produces the SA-DPO objective, which adapts the margin to the semantic distance between responses and thereby handles synonyms and hard pairs. The Margin-Capacity Profile then establishes that heavy-tailed surrogates, such as the Polynomial Hinge family, deliver superior consistency guarantees for容量
What carries the argument
The Structure-Aware H-consistency bounds that adapt the separation margin gamma according to semantic distance between responses, together with the Margin-Capacity Profile that quantifies the consistency-capacity trade-off across surrogate families.
If this is right
- Enforcing a positive separation margin gamma produces non-vacuous H-consistency bounds rather than vacuous ones.
- The SA-DPO objective improves handling of semantically similar or difficult preference pairs by scaling the margin to their distance.
- Heavy-tailed surrogates such as the Polynomial Hinge family supply stronger consistency guarantees than logistic loss once model capacity is limited.
- Incorporating semantic structure into the loss narrows the gap between empirical alignment performance and theoretical generalization bounds.
Where Pith is reading between the lines
- Alignment methods that treat all response pairs uniformly may systematically lose information on nuanced or ambiguous preferences.
- The same consistency gap could appear in other ranking-based tasks that rely on surrogate losses over neural networks.
- Practical gains from SA-DPO would depend on the accuracy of the semantic-distance oracle; noisy distances could erode the theoretical advantage.
- The Margin-Capacity Profile offers a diagnostic tool for choosing loss families when model size is constrained.
Load-bearing premise
Neural-network hypothesis sets are equicontinuous and semantic distances between responses can be defined and measured reliably without circularity.
What would settle it
A concrete counterexample in which the logistic loss achieves non-vacuous generalization bounds for an equicontinuous neural-network class on a preference task, or an experiment showing that margin adaptation based on semantic distance produces no measurable improvement on pairs of synonymous responses.
Figures


read the original abstract
Preference learning has become the foundation of aligning Large Language Models (LLMs) with human intent. Popular methods, such as Direct Preference Optimization (DPO), minimize surrogate losses as proxies for the intractable pairwise ranking loss. However, we demonstrate that for the equicontinuous hypothesis sets typical of neural networks, these standard surrogates are theoretically inconsistent, yielding vacuous generalization guarantees. To resolve this, we formulate LLM alignment within a margin-shifted ranking framework. We derive rigorous $H$-consistency bounds that depend on enforcing a separation margin $\gamma$. Crucially, we extend this to Structure-Aware $H$-consistency, introducing a novel objective (SA-DPO) that adapts the margin based on the semantic distance between responses to handle synonyms and hard pairs. Finally, we analyze the trade-off between consistency and model limitations via the Margin-Capacity Profile, proving that heavy-tailed surrogates (such as the Polynomial Hinge family) offer superior consistency guarantees for capacity-bounded models compared to the standard logistic loss used in DPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard surrogate losses (e.g., logistic loss in DPO) are H-inconsistent for equicontinuous hypothesis sets typical of neural networks, yielding vacuous generalization guarantees. It formulates alignment in a margin-shifted ranking framework, derives H-consistency bounds depending on a separation margin γ, introduces Structure-Aware DPO (SA-DPO) that adapts γ via semantic distances between responses, and analyzes the consistency-capacity trade-off via the Margin-Capacity Profile, concluding that heavy-tailed surrogates such as the Polynomial Hinge family provide superior guarantees for capacity-bounded models.
Significance. If the H-consistency derivations hold without circularity and the equicontinuity premise applies, the work would offer valuable theoretical grounding for preference learning in LLMs, explaining limitations of DPO-style methods and motivating margin adaptation plus heavy-tailed losses. The Margin-Capacity Profile is a potentially useful analytical tool. Practical impact would be high if SA-DPO yields measurable improvements on hard pairs while preserving the claimed bounds.
major comments (3)
- [H-consistency analysis (abstract and §3–4)] The central inconsistency claim for standard surrogates (logistic loss) is derived under the assumption that H is equicontinuous. Standard transformer parameterizations used in LLMs lack uniform Lipschitz control, allowing the modulus of continuity to grow unbounded with weight scaling; this violates the premise needed to construct a sequence where surrogate risk → 0 while ranking loss remains positive. The paper must either restrict the claim to explicitly Lipschitz-bounded hypothesis classes or provide a separate argument showing equicontinuity holds under typical training.
- [SA-DPO formulation and margin adaptation (abstract and §4)] The H-consistency bounds and SA-DPO objective depend on the separation margin γ and the semantic-distance adaptation rule. These are listed as free parameters; if γ or the distance function is selected or tuned on the same preference data used for evaluation, the bounds become data-dependent and lose their guarantee character. The manuscript must specify the exact adaptation rule (fixed function, learned module, or hyperparameter schedule) and prove that it does not introduce circularity or additional inconsistency.
- [Margin-Capacity Profile analysis (§5)] The Margin-Capacity Profile comparison asserts superiority of Polynomial Hinge over logistic loss for capacity-bounded models. The profile must be shown to remain valid under the same equicontinuity assumption used for the inconsistency result; without explicit bound derivations or tightness examples for LLM-scale capacities, it is unclear whether the claimed superiority is non-vacuous or merely inherits the same premise limitations.
minor comments (2)
- [Abstract] The abstract states that 'rigorous H-consistency bounds' are derived, yet no proof sketches, key lemmas, or bound expressions appear in the provided summary. The full manuscript should include at least one representative derivation step or theorem statement to allow verification.
- [Notation and SA-DPO definition] Notation for the semantic-distance function and its integration into the loss should be defined explicitly (e.g., as a fixed embedding distance or learned component) to avoid ambiguity with the claimed structure-aware property.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive feedback. We have carefully considered each major comment and provide point-by-point responses below. We will make revisions to the manuscript to address the concerns raised, particularly by clarifying assumptions and specifying implementation details.
read point-by-point responses
-
Referee: [H-consistency analysis (abstract and §3–4)] The central inconsistency claim for standard surrogates (logistic loss) is derived under the assumption that H is equicontinuous. Standard transformer parameterizations used in LLMs lack uniform Lipschitz control, allowing the modulus of continuity to grow unbounded with weight scaling; this violates the premise needed to construct a sequence where surrogate risk → 0 while ranking loss remains positive. The paper must either restrict the claim to explicitly Lipschitz-bounded hypothesis classes or provide a separate argument showing equicontinuity holds under typical training.
Authors: We agree that the equicontinuity assumption requires careful handling for transformer-based models. The manuscript positions the result for 'equicontinuous hypothesis sets typical of neural networks,' but we recognize that without norm constraints, transformers can have unbounded Lipschitz constants. In the revised version, we will restrict the inconsistency claim to hypothesis classes with bounded Lipschitz constants (e.g., via explicit weight norm bounds or regularization). We will also include a brief discussion noting that practical training regimes with weight decay and gradient clipping often keep the effective modulus of continuity controlled, although a rigorous proof for SGD-trained transformers is left for future work. This revision ensures the claim is precise and avoids overgeneralization. revision: yes
-
Referee: [SA-DPO formulation and margin adaptation (abstract and §4)] The H-consistency bounds and SA-DPO objective depend on the separation margin γ and the semantic-distance adaptation rule. These are listed as free parameters; if γ or the distance function is selected or tuned on the same preference data used for evaluation, the bounds become data-dependent and lose their guarantee character. The manuscript must specify the exact adaptation rule (fixed function, learned module, or hyperparameter schedule) and prove that it does not introduce circularity or additional inconsistency.
Authors: The semantic distance in SA-DPO is computed using a fixed, pre-specified function based on embeddings from a frozen, pre-trained model (e.g., a fixed sentence transformer not fine-tuned on the preference data). The margin γ is a user-specified hyperparameter, and the H-consistency bounds hold for any fixed γ > 0 and any fixed adaptation rule. Since the distance function is independent of the training preferences and not optimized jointly, there is no circularity or data-dependent bias in the theoretical guarantees. We will explicitly state this in the revised Section 4, including the precise definition of the adaptation rule and a short proof that the population-level bounds remain unchanged. revision: yes
-
Referee: [Margin-Capacity Profile analysis (§5)] The Margin-Capacity Profile comparison asserts superiority of Polynomial Hinge over logistic loss for capacity-bounded models. The profile must be shown to remain valid under the same equicontinuity assumption used for the inconsistency result; without explicit bound derivations or tightness examples for LLM-scale capacities, it is unclear whether the claimed superiority is non-vacuous or merely inherits the same premise limitations.
Authors: The Margin-Capacity Profile is constructed from the H-consistency bounds derived in earlier sections and thus inherits the equicontinuity assumption. In the revision, we will provide the explicit derivations of the profile for the logistic loss and the Polynomial Hinge family, highlighting the capacity term's dependence on the margin. To demonstrate tightness, we will add an example with a finite (hence equicontinuous) hypothesis class where the profile accurately predicts better performance for heavy-tailed losses under capacity constraints. While providing numerical tightness for full LLM-scale models is computationally prohibitive, the profile serves as a theoretical tool to illustrate the consistency-capacity trade-off for any bounded-capacity setting, and we will clarify this scope in the text. revision: partial
Circularity Check
No significant circularity; derivation builds from standard H-consistency theory applied to margin-shifted ranking.
full rationale
The paper's central claims rest on deriving H-consistency bounds for a margin-shifted ranking loss under the equicontinuity assumption for neural network hypothesis classes, then extending to a structure-aware variant (SA-DPO) that adapts the margin γ via semantic distances between responses. These steps are presented as direct applications of statistical learning theory to the new objective, with the Margin-Capacity Profile comparison between logistic and Polynomial Hinge losses following from capacity-bounded analysis. No load-bearing step reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work by the same authors. The equicontinuity premise and semantic-distance adaptation are treated as modeling choices with stated assumptions rather than outputs derived from the target consistency result itself. The derivation chain therefore remains self-contained against external benchmarks in statistical learning theory.
Axiom & Free-Parameter Ledger
free parameters (2)
- separation margin γ
- semantic-distance adaptation rule
axioms (2)
- domain assumption Neural-network hypothesis sets are equicontinuous
- domain assumption Semantic distances between responses can be defined and measured reliably
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Agarwal, A., Dann, C., and Marinov, T. V. Design considerations in offline preference-based RL . In International Conference on Machine Learning, 2025
2025
-
[3]
and Mohri, M
Ailon, N. and Mohri, M. Preference-based learning to rank. Machine Learning, 80 0 (2): 0 189--211, 2010
2010
-
[4]
H -consistency bounds for surrogate loss minimizers
Awasthi, P., Mao, A., Mohri, M., and Zhong, Y. H -consistency bounds for surrogate loss minimizers. In International Conference on Machine Learning, pp.\ 1117--1174, 2022 a
2022
-
[5]
Multi-class H -consistency bounds
Awasthi, P., Mao, A., Mohri, M., and Zhong, Y. Multi-class H -consistency bounds. In Advances in Neural Information Processing Systems, pp.\ 782--795, 2022 b
2022
-
[6]
G., Guo, Z
Azar, M. G., Guo, Z. D., Piot, B., Munos, R., Rowland, M., Valko, M., and Calandriello, D. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics, pp.\ 4447--4455, 2024
2024
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
L., Jordan, M
Bartlett, P. L., Jordan, M. I., and McAuliffe, J. D. Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101 0 (473): 0 138--156, 2006
2006
-
[9]
On the (non-) existence of convex, calibrated surrogate losses for ranking
Calauzenes, C., Usunier, N., and Gallinari, P. On the (non-) existence of convex, calibrated surrogate losses for ranking. In Advances in Neural Information Processing Systems, 2012
2012
-
[10]
H., Chen, X., Zhang, Q., Ranganath, R., and Cho, K
Chen, A., Malladi, S., Zhang, L. H., Chen, X., Zhang, Q., Ranganath, R., and Cho, K. Preference learning algorithms do not learn preference rankings. In Advances in Neural Information Processing Systems, pp.\ 101928--101968, 2024
2024
-
[11]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. In Advances in neural information processing systems, 2017
2017
-
[12]
and Vapnik, V
Cortes, C. and Vapnik, V. Support-vector networks. Machine Learning, 20: 0 273--297, 1995
1995
-
[13]
Cardinality-aware set prediction and top- k classification
Cortes, C., Mao, A., Mohri, C., Mohri, M., and Zhong, Y. Cardinality-aware set prediction and top- k classification. In Advances in Neural Information Processing Systems, 2024
2024
-
[14]
Balancing the scales: A theoretical and algorithmic framework for learning from imbalanced data
Cortes, C., Mao, A., Mohri, M., and Zhong, Y. Balancing the scales: A theoretical and algorithmic framework for learning from imbalanced data. In International Conference on Machine Learning, 2025
2025
-
[15]
Optimized deferral for imbalanced settings
Cortes, C., Mao, A., Mohri, M., and Zhong, Y. Optimized deferral for imbalanced settings. In International Conference on Machine Learning, 2026 a
2026
-
[16]
A theoretical framework for modular learning of robust generative models
Cortes, C., Mohri, M., and Zhong, Y. A theoretical framework for modular learning of robust generative models. In International Conference on Machine Learning, 2026 b
2026
-
[17]
Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377,
Cui, G., Yuan, L., Ding, N., Yao, G., He, B., Zhu, W., Ni, Y., Xie, G., Xie, R., Lin, Y., et al. Ultrafeedback: Boosting language models with scaled AI feedback. arXiv preprint arXiv:2310.01377, 2023
-
[18]
Daniel Han, M. H. and team, U. Unsloth, 2023. URL http://github.com/unslothai/unsloth
2023
-
[19]
Budgeted multiple-expert deferral
DeSalvo, G., Mohri, C., Mohri, M., and Zhong, Y. Budgeted multiple-expert deferral. arXiv preprint arXiv:2510.26706, 2025
-
[20]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
On the consistency of ranking algorithms
Duchi, J., Mackey, L., and Jordan, M. On the consistency of ranking algorithms. In International Conference on Machine Learning, pp.\ 327--334, 2010
2010
-
[22]
KTO: Model Alignment as Prospect Theoretic Optimization
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. KTO : Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
G \"o lz, P., Haghtalab, N., and Yang, K. Distortion of ai alignment: Does preference optimization optimize for preferences? arXiv preprint arXiv:2505.23749, 2025
-
[24]
Guo, S., Zhang, B., Liu, T., Liu, T., Khalman, M., Llinares, F., Rame, A., Mesnard, T., Zhao, Y., Piot, B., et al. Direct language model alignment from online AI feedback. arXiv preprint arXiv:2402.04792, 2024
-
[25]
Large margin rank boundaries for ordinal regression
Herbrich, R., Graepel, T., and Obermayer, K. Large margin rank boundaries for ordinal regression. Advances in Large Margin Classifiers, pp.\ 115--132, 2000
2000
-
[26]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[27]
Optimizing search engines using clickthrough data
Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp.\ 133--142, 2002
2002
-
[28]
Theory and Algorithms for Learning with Multi-Class Abstention and Multi-Expert Deferral
Mao, A. Theory and Algorithms for Learning with Multi-Class Abstention and Multi-Expert Deferral. PhD thesis, New York University, 2025
2025
-
[29]
Two-stage learning to defer with multiple experts
Mao, A., Mohri, C., Mohri, M., and Zhong, Y. Two-stage learning to defer with multiple experts. In Advances in Neural Information Processing Systems, 2023 a
2023
-
[30]
H -consistency bounds: Characterization and extensions
Mao, A., Mohri, M., and Zhong, Y. H -consistency bounds: Characterization and extensions. In Advances in Neural Information Processing Systems, 2023 b
2023
-
[31]
H -consistency bounds for pairwise misranking loss surrogates
Mao, A., Mohri, M., and Zhong, Y. H -consistency bounds for pairwise misranking loss surrogates. In International Conference on Machine learning, 2023 c
2023
-
[32]
Ranking with abstention
Mao, A., Mohri, M., and Zhong, Y. Ranking with abstention. In ICML 2023 Workshop The Many Facets of Preference-Based Learning, 2023 d
2023
-
[33]
Cross-entropy loss functions: Theoretical analysis and applications
Mao, A., Mohri, M., and Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In International Conference on Machine Learning, 2023 e
2023
-
[34]
Structured prediction with stronger consistency guarantees
Mao, A., Mohri, M., and Zhong, Y. Structured prediction with stronger consistency guarantees. In Advances in Neural Information Processing Systems, pp.\ 46903--46937, 2023 f
2023
-
[35]
Principled approaches for learning to defer with multiple experts
Mao, A., Mohri, M., and Zhong, Y. Principled approaches for learning to defer with multiple experts. In International Symposium on Artificial Intelligence and Mathematics, 2024 a
2024
-
[36]
Predictor-rejector multi-class abstention: Theoretical analysis and algorithms
Mao, A., Mohri, M., and Zhong, Y. Predictor-rejector multi-class abstention: Theoretical analysis and algorithms. In International Conference on Algorithmic Learning Theory, 2024 b
2024
-
[37]
Theoretically grounded loss functions and algorithms for score-based multi-class abstention
Mao, A., Mohri, M., and Zhong, Y. Theoretically grounded loss functions and algorithms for score-based multi-class abstention. In International Conference on Artificial Intelligence and Statistics, 2024 c
2024
-
[38]
H -consistency guarantees for regression
Mao, A., Mohri, M., and Zhong, Y. H -consistency guarantees for regression. In International Conference on Machine Learning, pp.\ 34712--34737, 2024 d
2024
-
[39]
Multi-label learning with stronger consistency guarantees
Mao, A., Mohri, M., and Zhong, Y. Multi-label learning with stronger consistency guarantees. In Advances in Neural Information Processing Systems, 2024 e
2024
-
[40]
Realizable H -consistent and B ayes-consistent loss functions for learning to defer
Mao, A., Mohri, M., and Zhong, Y. Realizable H -consistent and B ayes-consistent loss functions for learning to defer. In Advances in Neural Information Processing Systems, 2024 f
2024
-
[41]
Regression with multi-expert deferral
Mao, A., Mohri, M., and Zhong, Y. Regression with multi-expert deferral. In International Conference on Machine Learning, pp.\ 34738--34759, 2024 g
2024
-
[42]
A universal growth rate for learning with smooth surrogate losses
Mao, A., Mohri, M., and Zhong, Y. A universal growth rate for learning with smooth surrogate losses. In Advances in Neural Information Processing Systems, 2024 h
2024
-
[43]
Mastering multiple-expert routing: Realizable H -consistency and strong guarantees for learning to defer
Mao, A., Mohri, M., and Zhong, Y. Mastering multiple-expert routing: Realizable H -consistency and strong guarantees for learning to defer. In International Conference on Machine Learning, 2025 a
2025
-
[44]
Principled algorithms for optimizing generalized metrics in binary classification
Mao, A., Mohri, M., and Zhong, Y. Principled algorithms for optimizing generalized metrics in binary classification. In International Conference on Machine Learning, 2025 b
2025
-
[45]
Enhanced -consistency bounds
Mao, A., Mohri, M., and Zhong, Y. Enhanced -consistency bounds. In International Conference on Algorithmic Learning Theory, 2025 c
2025
-
[46]
and Astudillo, R
Martins, A. and Astudillo, R. From softmax to sparsemax: A sparse model of attention and multi-label classification. In International Conference on Machine Learning, pp.\ 1614--1623, 2016
2016
-
[47]
SimPO : Simple preference optimization with a reference-free reward
Meng, Y., Xia, M., and Chen, D. SimPO : Simple preference optimization with a reference-free reward. In Advances in Neural Information Processing Systems, pp.\ 124198--124235, 2024
2024
-
[48]
Learning to reject with a fixed predictor: Application to decontextualization
Mohri, C., Andor, D., Choi, E., Collins, M., Mao, A., and Zhong, Y. Learning to reject with a fixed predictor: Application to decontextualization. In International Conference on Learning Representations, 2024
2024
-
[49]
and Zhong, Y
Mohri, M. and Zhong, Y. Linear-core surrogates: Smooth loss functions with linear rates for classification and structured prediction. In International Conference on Machine Learning, 2026 a
2026
-
[50]
and Zhong, Y
Mohri, M. and Zhong, Y. Beyond tsybakov: Model margin noise and H -consistency bounds. In International Symposium on Artificial Intelligence and Mathematics, 2026 b
2026
-
[51]
G., Rowland, M., Guo, Z
Munos, R., Valko, M., Calandriello, D., Azar, M. G., Rowland, M., Guo, Z. D., Tang, Y., Geist, M., Mesnard, T., Fiegel, C., et al. Nash learning from human feedback. In International Conference on Machine Learning, 2024
2024
-
[52]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, pp.\ 53728--53741, 2023
2023
-
[53]
S., Gunasekar, S., and Srebro, N
Soudry, D., Hoffer, E., Nacson, M. S., Gunasekar, S., and Srebro, N. The implicit bias of gradient descent on separable data. Journal of Machine Learning Research, 19 0 (70): 0 1--57, 2018
2018
-
[54]
How to compare different loss functions and their risks
Steinwart, I. How to compare different loss functions and their risks. Constructive Approximation, 26 0 (2): 0 225--287, 2007
2007
-
[55]
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., and Christiano, P. F. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, pp.\ 3008--3021, 2020
2020
-
[56]
Large margin methods for structured and interdependent output variables
Tsochantaridis, I., Joachims, T., Hofmann, T., Altun, Y., and Singer, Y. Large margin methods for structured and interdependent output variables. Journal of Machine Learning Research, 6: 0 1453--1484, 2005
2005
-
[57]
Trl: Transformer reinforcement learning
von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., and Gallouédec, Q. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020
2020
-
[58]
C-pack: Packed resources for general chinese embeddings
Xiao, S., Liu, Z., Zhang, P., Muennighoff, N., Lian, D., and yun Nie, J. C-pack: Packed resources for general chinese embeddings. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023
2023
-
[59]
Iterative preference learning from human feedback: Bridging theory and practice for RLHF under KL -constraint
Xiong, W., Dong, H., Ye, C., Wang, Z., Zhong, H., Ji, H., Jiang, N., and Zhang, T. Iterative preference learning from human feedback: Bridging theory and practice for RLHF under KL -constraint. In International Conference on Machine Learning, pp.\ 54715--54754, 2024
2024
-
[60]
RRHF : Rank responses to align language models with human feedback
Yuan, H., Yuan, Z., Tan, C., Wang, W., Huang, S., and Huang, F. RRHF : Rank responses to align language models with human feedback. In Advances in Neural Information Processing Systems, 2023
2023
-
[61]
Cost-sensitive learning by cost-proportionate weighting of examples
Zadrozny, B., Langford, J., and Abe, N. Cost-sensitive learning by cost-proportionate weighting of examples. In Third IEEE International Conference on Data Mining, pp.\ 435--442, 2003
2003
-
[62]
Statistical behavior and consistency of classification methods based on convex risk minimization
Zhang, T. Statistical behavior and consistency of classification methods based on convex risk minimization. The Annals of Statistics, 32 0 (1): 0 56--85, 2004
2004
- [63]
-
[64]
Fundamental Novel Consistency Theory: H-Consistency Bounds
Zhong, Y. Fundamental Novel Consistency Theory: H-Consistency Bounds. PhD thesis, New York University, 2025
2025
-
[65]
Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization
Zhou, Z., Liu, J., Shao, J., Yue, X., Yang, C., Ouyang, W., and Qiao, Y. Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization. In Annual Meeting of the Association for Computational Linguistics, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.