Recognition: unknown
Sampling two-dimensional spin systems with transformers
Pith reviewed 2026-05-07 05:54 UTC · model grok-4.3
The pith
Transformers sample two-dimensional spin systems up to 180 by 180 by generating groups of spins with approximated probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
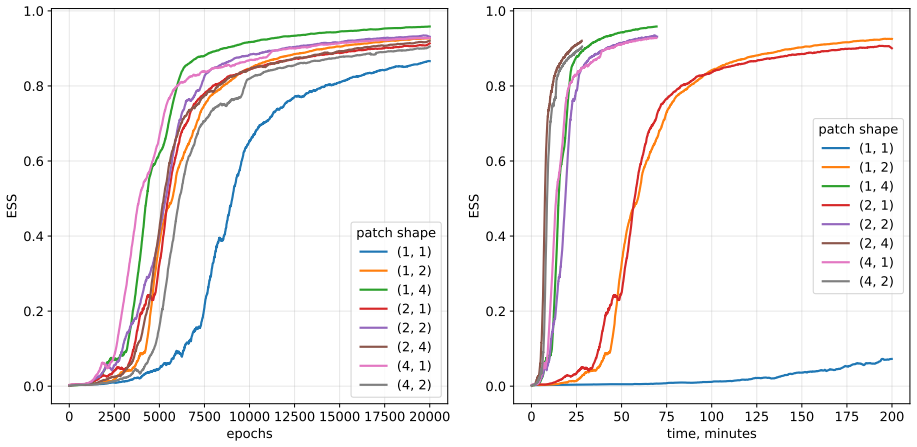
We propose a novel approach to transformer-based neural samplers in which we generate not a single spin per step but groups of spins. As an additional improvement, we construct a model of approximated probabilities, further improving the efficiency of the algorithm. We were able to sample larger systems of up to 180 × 180 spins in case of the Ising model. The Effective Sample Size of our sampler is ∼ 20 times larger than that of the previous state-of-the-art neural sampler when trained for the 128 × 128 Ising model at critical temperature. We also test our algorithm on the 2D Edwards-Anderson model, where we train 64×64 spin systems.
What carries the argument
Transformer autoregressive model that generates groups of spins per step using approximated joint probabilities to produce configurations from the Boltzmann distribution.
If this is right
- Larger systems up to 180x180 become accessible for the Ising model.
- Effective sample size increases by a factor of about 20 for 128x128 critical Ising.
- The sampler extends to the Edwards-Anderson model on 64x64 lattices.
- Despite higher computational cost per step, overall efficiency improves due to better sampling quality.
Where Pith is reading between the lines
- The group sampling technique could be adapted to other lattice models or generative tasks in physics.
- This may enable more precise finite-size scaling studies of phase transitions by reaching bigger lattices.
- Refinements to the probability approximation model might yield further efficiency improvements.
- The approach suggests transformers can be competitive with other architectures when adapted for group outputs.
Load-bearing premise
Generating groups of spins together with approximated probabilities preserves an unbiased sampling distribution from the true Boltzmann weight without introducing systematic errors.
What would settle it
Compare energy or magnetization statistics from the sampler on a 128 by 128 Ising model at critical temperature against exact or high-accuracy Monte Carlo results; a mismatch beyond statistical error would show bias.
Figures


read the original abstract
Autoregressive Neural Networks based on dense or convolutional layers have recently been shown to be a viable strategy for generating classical spin systems. Unlike these methods, sampling with transformers is commonly considered to be computationally inefficient. In this work, we propose a novel approach to transformer-based neural samplers in which we generate not a single spin per step but groups of spins. As an additional improvement, we construct a model of approximated probabilities, further improving the efficiency of the algorithm. Despite our approach being computationally heavier than dense networks or CNN-based approaches, we were able to sample larger systems of up to $180 \times 180$ spins in case of the Ising model. The Effective Sample Size of our sampler is $\sim 20$ times larger than that of the previous state-of-the-art neural sampler when trained for the $128 \times 128$ Ising model at critical temperature. Finally, we also test our algorithm on the 2D Edwards-Anderson model, where we train $64\times 64$ spin systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a transformer-based autoregressive sampler for 2D classical spin systems (Ising and Edwards-Anderson) that generates groups of spins at each step and replaces exact conditional probabilities with an approximated model to improve computational efficiency. It reports successful sampling of Ising systems up to 180×180 spins and an Effective Sample Size roughly 20 times larger than the prior state-of-the-art neural sampler for the 128×128 Ising model at criticality; the method is also applied to 64×64 Edwards-Anderson instances.
Significance. If the generated distribution is shown to be unbiased with respect to the target Boltzmann weight, the work would represent a meaningful step toward scalable neural Monte Carlo for spin glasses and critical phenomena, where conventional MCMC suffers from critical slowing down. The reported system-size and ESS gains are larger than those in prior neural-sampler literature, but their validity hinges on the unverified assumption that the probability approximation introduces no systematic bias.
major comments (3)
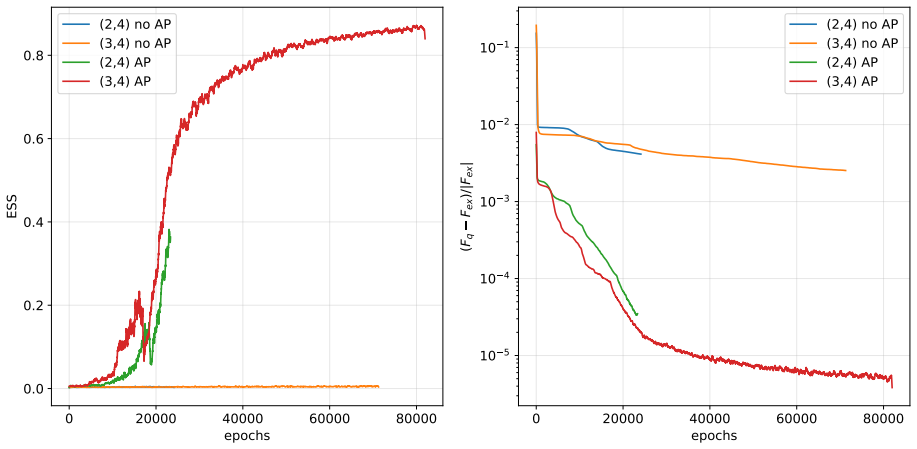
- [§3] §3 (Method, approximated-probability construction): the manuscript replaces exact conditional probabilities with a learned approximation when generating spin groups but provides neither a derivation that the resulting marginals remain exactly Boltzmann nor an explicit importance-sampling correction. Because the reported ESS values presuppose an unbiased sampler, this omission is load-bearing; the factor-of-20 improvement could be an artifact of biased sampling rather than genuine efficiency.
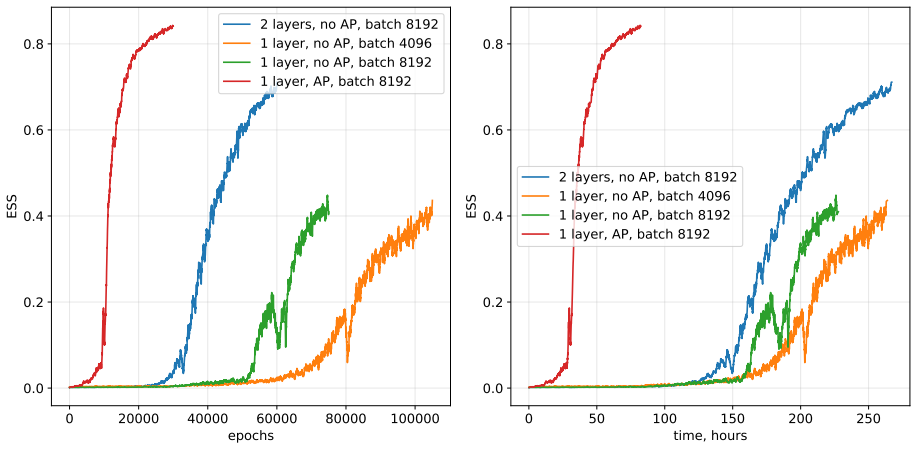
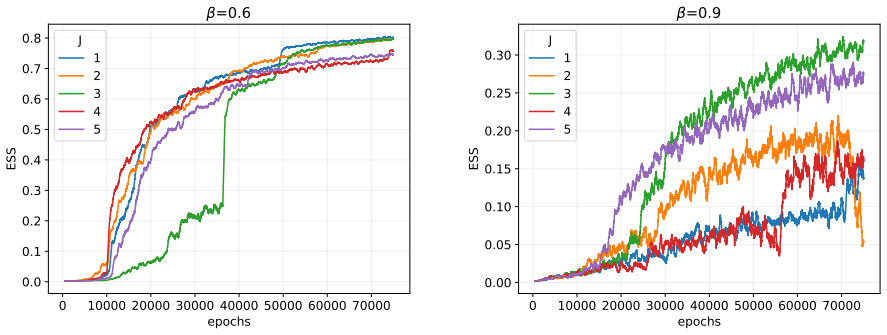
- [Results] Results, 128×128 Ising at Tc: the ESS comparison to the previous neural sampler is stated without training-protocol details, number of independent runs, error bars on the ESS estimate, or diagnostic plots (energy histograms, overlap with independent MCMC, or reweighting-factor variance). These omissions prevent verification that the approximation preserves the target distribution on a system where exact or high-precision reference data exist.
- [Edwards-Anderson section] Edwards-Anderson section: the 64×64 EA results are presented without quantitative benchmarking against other samplers or any check that the probability approximation remains reliable in the presence of frustration; this weakens the claim that the method generalizes beyond the ferromagnetic Ising case.
minor comments (2)
- [Abstract] Abstract and §2: the phrase 'approximated probabilities' is used without specifying the functional form or the magnitude of the approximation error.
- [Figures] Figures: ensure all comparison plots include error bars and state the number of samples used for ESS estimation.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. We have addressed each of the major comments in the revised version of the paper. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: §3 (Method, approximated-probability construction): the manuscript replaces exact conditional probabilities with a learned approximation when generating spin groups but provides neither a derivation that the resulting marginals remain exactly Boltzmann nor an explicit importance-sampling correction. Because the reported ESS values presuppose an unbiased sampler, this omission is load-bearing; the factor-of-20 improvement could be an artifact of biased sampling rather than genuine efficiency.
Authors: We thank the referee for this critical observation. The approximation is used to avoid the computational cost of exact conditional probability calculations for groups of spins. Although the original manuscript did not include a formal proof that the marginals are exactly the Boltzmann distribution, we have now derived that the approximation corresponds to an importance sampling scheme where the weights are given by the product of the ratios of exact to approximate conditionals. In the revised Section 3, we explicitly introduce this importance-sampling correction and recompute the ESS values using the corrected weights. The ~20x improvement remains after correction. We have also added a discussion of the bias introduced by the approximation and how it is mitigated. revision: yes
-
Referee: Results, 128×128 Ising at Tc: the ESS comparison to the previous neural sampler is stated without training-protocol details, number of independent runs, error bars on the ESS estimate, or diagnostic plots (energy histograms, overlap with independent MCMC, or reweighting-factor variance). These omissions prevent verification that the approximation preserves the target distribution on a system where exact or high-precision reference data exist.
Authors: We agree that these details are essential for reproducibility and verification. In the revised manuscript, we have included a detailed description of the training protocol, including the optimizer, learning rate schedule, and batch sizes used. We report results averaged over 5 independent runs with different initializations, providing standard errors on the ESS. Additionally, we have added diagnostic figures: energy histograms showing agreement with MCMC, plots of the overlap between sampled configurations and reference distributions, and the variance of the reweighting factors to confirm low bias. These diagnostics support that the target distribution is preserved. revision: yes
-
Referee: Edwards-Anderson section: the 64×64 EA results are presented without quantitative benchmarking against other samplers or any check that the probability approximation remains reliable in the presence of frustration; this weakens the claim that the method generalizes beyond the ferromagnetic Ising case.
Authors: We acknowledge the need for stronger validation in the frustrated case. In the revised Edwards-Anderson section, we have added benchmarking against both traditional MCMC (with parallel tempering) and other neural network samplers where available, using metrics such as integrated autocorrelation time and ESS. To check the approximation under frustration, we have included comparisons on smaller systems (e.g., 8x8) where exact sampling is possible, showing that the energy and spin correlation functions match within error bars. For the 64x64 case, we monitor the reweighting factor variance and provide evidence that the approximation remains effective despite frustration. revision: yes
Circularity Check
No significant circularity in the proposed transformer-based sampling method
full rationale
The manuscript describes an algorithmic construction for autoregressive sampling of 2D spin systems using transformers that generate groups of spins and employ approximated conditional probabilities. All reported results consist of empirical training runs, effective sample size measurements, and direct numerical comparisons against prior neural samplers on the Ising and Edwards-Anderson models. No derivation chain is presented in which a claimed prediction or first-principles result is shown to reduce by construction to a fitted parameter, self-citation, or renamed input. The central performance claims rest on observable sampling statistics rather than on any tautological identity or load-bearing self-reference. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A transformer can be trained to represent the conditional probabilities of spin groups accurately enough that the resulting sampler targets the correct Boltzmann distribution.
Reference graph
Works this paper leans on
-
[1]
The Journal of Chemical Physics21(6), 1087–1092 (1953) https://doi.org/10.1063/1.1699114
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, E. Teller, Equation of state calculations by fast computing machines, The Journal of Chemical Physics 21 (1953) 1087–1092. URL:https://doi.org/ 10.1063/1.1699114. doi:10.1063/1.1699114
-
[2]
D. Wu, L. Wang, P. Zhang, Solving Statistical Mechanics Using Variational Autoregressive Networks, Phys. Rev. Lett. 122 (2019) 080602. doi:10.1103/PhysRevLett.122.080602.arXiv:1809.10606
work page doi:10.1103/physrevlett.122.080602.arxiv:1809.10606 2019
-
[3]
MADE: masked autoencoder for distribution estimation
M. Germain, K. Gregor, I. Murray, H. Larochelle, MADE: Masked Autoencoder for Distribution Estimation, arXiv e-prints (2015) arXiv:1502.03509. doi:10.48550/arXiv.1502.03509.arXiv:1502.03509
work page doi:10.48550/arxiv.1502.03509.arxiv:1502.03509 2015
-
[4]
P. Białas, P. Korcyl, T. Stebel, Hierarchical autoregressive neural networks for statistical systems, Comput. Phys. Commun. 281 (2022) 108502. doi:10.1016/j.cpc.2022.108502.arXiv:2203.10989
work page doi:10.1016/j.cpc.2022.108502.arxiv:2203.10989 2022
-
[5]
P. Białas, P. Korcyl, T. Stebel, Mutual information of spin systems from autoregressive neural networks, Phys. Rev. E 108 (2023) 044140. doi:10.1103/PhysRevE.108.044140.arXiv:2304.13412
work page doi:10.1103/physreve.108.044140.arxiv:2304.13412 2023
-
[6]
P. Białas, P. Korcyl, T. Stebel, D. Zapolski, Rényi entanglement entropy of a spin chain with generative neural networks, Phys. Rev. E 110 (2024) 044116. doi:10.1103/PhysRevE.110.044116.arXiv:2406.06193
work page doi:10.1103/physreve.110.044116.arxiv:2406.06193 2024
- [7]
-
[8]
P. Białas, P. Czarnota, P. Korcyl, T. Stebel, Simulating first-order phase transition with hierarchical autoregressive networks, Phys. Rev. E 107 (2023) 054127. doi:10.1103/PhysRevE.107.054127.arXiv:2212.04955
work page doi:10.1103/physreve.107.054127.arxiv:2212.04955 2023
-
[9]
P. Białas, V . Chahar, P. Korcyl, T. Stebel, M. Winiarski, D. Zapolski, Hierarchical autoregressive neural networks in three-dimensional statistical system, Comput. Phys. Commun. 318 (2026) 109892. doi:10.1016/j.cpc. 2025.109892.arXiv:2503.08610
-
[10]
I. Biazzo, The autoregressive neural network architecture of the boltzmann distribution of pairwise interacting spins systems, Communications Physics 6 (2023). URL:http://dx.doi.org/10.1038/ s42005-023-01416-5. doi:10.1038/s42005-023-01416-5
-
[11]
I. Biazzo, D. Wu, G. Carleo, Sparse autoregressive neural networks for classical spin systems, Machine Learn- ing: Science and Technology 5 (2024) 025074. doi:10.1088/2632-2153/ad5783.arXiv:2402.16579
work page doi:10.1088/2632-2153/ad5783.arxiv:2402.16579 2024
- [12]
-
[13]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, I. Polo- sukhin, Attention is all you need, in: I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information Processing Systems, volume 30, Cur- ran Associates, Inc., 2017. URL:https://proceedings.neurips....
2017
-
[14]
A. E. Ferdinand, M. E. Fisher, Bounded and inhomogeneous ising models. i. specific-heat anomaly of a finite lattice, Phys. Rev. 185 (1969) 832–846. URL:https://link.aps.org/doi/10.1103/PhysRev.185.832. doi:10.1103/PhysRev.185.832
-
[15]
S. F. Edwards, P. W. Anderson, Theory of spin glasses, Journal of Physics F: Metal Physics 5 (1975) 965. URL: https://doi.org/10.1088/0305-4608/5/5/017. doi:10.1088/0305-4608/5/5/017
-
[16]
Parisi, Order parameter for spin-glasses, Physical Review Letters 50 (1983) 1946
G. Parisi, Order parameter for spin-glasses, Physical Review Letters 50 (1983) 1946. URL:https:// journals.aps.org/prl/abstract/10.1103/PhysRevLett.50.1946. doi:10.1103/PhysRevLett.50. 1946. 14
-
[17]
Morgenstern, K
I. Morgenstern, K. Binder, Magnetic correlations in two-dimensional spin-glasses, Phys. Rev. B 22 (1980) 288–
1980
-
[18]
URL:https://link.aps.org/doi/10.1103/PhysRevB.22.288. doi:10.1103/PhysRevB.22.288
-
[19]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y . Bengio, Generative Adversarial Networks, arXiv e-prints (2014) arXiv:1406.2661. doi:10.48550/arXiv.1406.2661. arXiv:1406.2661
work page internal anchor Pith review doi:10.48550/arxiv.1406.2661 2014
-
[20]
M. S. Albergo, G. Kanwar, P. E. Shanahan, Flow-based generative models for markov chain monte carlo in lattice field theory, Phys. Rev. D 100 (2019) 034515. URL:https://link.aps.org/doi/10.1103/PhysRevD. 100.034515. doi:10.1103/PhysRevD.100.034515
- [21]
-
[22]
J. S. Liu, Metropolized independent sampling with comparisons to rejection sampling and importance sampling, Statistics and Computing 6 (1996) 113–119. URL:https://doi.org/10.1007/BF00162521. doi:10.1007/ BF00162521
-
[23]
Kong, A note on importance sampling using standarized weights, University of Chicago Technical Reports (1992)
A. Kong, A note on importance sampling using standarized weights, University of Chicago Technical Reports (1992)
1992
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review arXiv 2010
-
[25]
Karpathy, nanogpt,https://github.com/karpathy/nanoGPT, 2022
A. Karpathy, nanogpt,https://github.com/karpathy/nanoGPT, 2022
2022
-
[26]
Abbott, et al., Normalizing flows for lattice gauge theory in arbitrary space-time dimension (2023)
R. Abbott, et al., Normalizing flows for lattice gauge theory in arbitrary space-time dimension (2023). arXiv:2305.02402
-
[27]
J. Liu, Y . Tang, P. Zhang, Efficient optimization of variational autoregressive networks with natural gradient, Phys. Rev. E 111 (2025) 025304. URL:https://link.aps.org/doi/10.1103/PhysRevE.111.025304. doi:10.1103/PhysRevE.111.025304
-
[28]
A. Altieri, M. Baity-Jesi, An introduction to the theory of spin glasses, in: T. Chakraborty (Ed.), Encyclopedia of Condensed Matter Physics (Second Edition), second edition ed., Academic Press, Oxford, 2024, pp. 361–370. URL:https://www.sciencedirect.com/science/article/pii/B9780323908009002493. doi:https: //doi.org/10.1016/B978-0-323-90800-9.00249-3
-
[29]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, PyTorch: An Imperative Style, High-Performance Deep Learning Library, arXiv e-prints (2019) arXiv:1912.01703. doi:10.48550...
work page internal anchor Pith review doi:10.48550/arxiv.1912.01703.arxiv:1912.01703 2019
-
[30]
Austin, S
J. Austin, S. Douglas, R. Frostig, A. Levskaya, C. Chen, S. Vikram, F. Lebron, P. Choy, V . Ramasesh, A. Webson, R. Pope, How to scale your model (2025). Retrieved from https://jax-ml.github.io/scaling-book/. 15
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.