Recognition: unknown
Intent2Tx: Benchmarking LLMs for Translating Natural Language Intents into Ethereum Transactions
Pith reviewed 2026-05-07 05:45 UTC · model grok-4.3
The pith
Current large language models can generate syntactically valid Ethereum transactions from natural language intents but often fail to produce the intended on-chain state changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
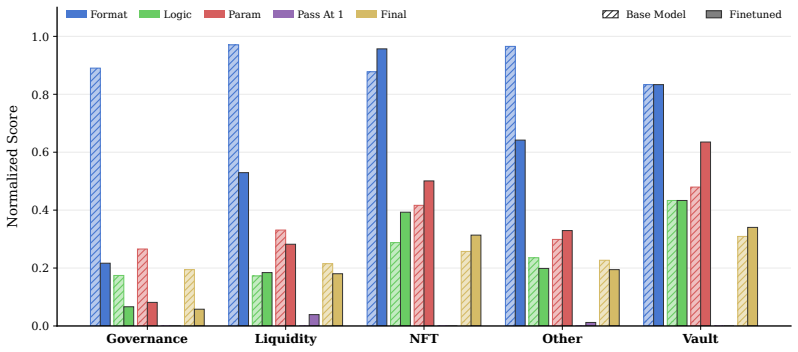
Intent2Tx demonstrates that execution-based verification on real Ethereum environments reveals a significant gap in LLM capabilities: many syntactically valid transaction outputs fail to achieve the intended state transitions, even as scaling and retrieval-augmentation improve logical consistency and parameter precision.
What carries the argument
Differential state analysis on forked Ethereum mainnet environments that checks whether the on-chain state changes produced by a generated transaction exactly match those implied by the natural language intent.
If this is right
- Scaling model size and adding retrieval augmentation improves logical consistency and parameter precision in generated transactions.
- Current LLMs continue to struggle with out-of-distribution generalization and multi-step planning even on real-world DeFi primitives.
- Syntactic validity of generated transactions is not sufficient to guarantee functional correctness on-chain.
- Execution-aware benchmarks grounded in actual traces are required to develop reliable autonomous agents for intent-centric Web3 systems.
Where Pith is reading between the lines
- Future LLM systems for blockchain tasks may need integrated execution simulators or feedback loops during generation to close the observed reasoning-to-execution gap.
- The same differential-state verification approach could be adapted to evaluate LLM performance on other stateful systems such as other smart-contract platforms or even non-blockchain distributed ledgers.
- Specialized training on long-tail protocol interactions may be more effective than general scaling alone for improving performance on rare DeFi cases.
Load-bearing premise
The natural language intents extracted from historical Ethereum traces accurately represent the distribution and complexity of real user intents, including sufficient coverage of out-of-distribution cases across the 11 categories.
What would settle it
Generate a transaction that passes all syntactic and parameter checks, execute it on the forked mainnet, and observe that the resulting state delta differs from the state change described in the original intent.
Figures



read the original abstract
The emergence of Large Language Models (LLMs) offers a transformative interface for Web3, yet existing benchmarks fail to capture the complexity of translating high-level user intents into functionally correct, state-dependent on-chain transactions. We present \textsc{Intent2Tx}, a high-fidelity benchmark featuring 29,921 single-step and 1,575 multi-step instances meticulously derived from 300 days of real-world Ethereum mainnet traces. Unlike prior works that rely on synthetic instructions, \textsc{Intent2Tx} grounds natural language intents in real-world protocol interactions across 11 categories, including diverse long-tail Decentralized Finance (DeFi) primitives. To enable rigorous evaluation, we propose an execution-aware framework that transcends surface-level text matching by employing differential state analysis on forked mainnet environments. Our extensive evaluation of 16 state-of-the-art LLMs reveals that while scaling and retrieval-augmentation enhance logical consistency and parameter precision, current models struggle with out-of-distribution generalization and multi-step planning. Crucially, our execution-based analysis demonstrates that syntactically valid outputs often fail to achieve intended state transitions, highlighting a significant gap in current "reasoning-to-execution" capabilities. \textsc{Intent2Tx} serves as a critical foundation for developing autonomous, reliable agents in intent-centric Web3 ecosystems. Code and data: https://anonymous.4open.science/r/Intent2Tx_Bench-97FF .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Intent2Tx, a benchmark of 29,921 single-step and 1,575 multi-step natural language intents derived from 300 days of real Ethereum mainnet traces across 11 categories. It proposes an execution-aware evaluation framework that uses differential state analysis on forked environments to determine whether LLM-generated transactions achieve the intended on-chain state transitions, rather than relying on surface-level syntactic or semantic matching. Evaluation of 16 state-of-the-art LLMs indicates that scaling and retrieval-augmentation improve logical consistency and parameter accuracy, yet models exhibit persistent difficulties with out-of-distribution generalization and multi-step planning; crucially, many syntactically valid outputs fail to produce the desired state changes.
Significance. If the intent derivation process is shown to faithfully capture real user objectives, this benchmark offers a valuable, real-world-grounded alternative to synthetic instruction datasets for assessing LLM agents in Web3. The execution-based metric directly tests functional correctness and state-dependent behavior, which is a methodological strength. The release of code and data further supports reproducibility and follow-on work on intent-centric decentralized systems.
major comments (2)
- [§3] §3 (Benchmark Construction and Intent Derivation): The methodology for translating historical transaction traces into natural language intents is insufficiently specified. It is unclear whether derivation relies on manual annotation, heuristics, LLM assistance, or a combination, how trace filtering was performed, and how the 11 categories ensure coverage of long-tail DeFi interactions and true out-of-distribution cases. This detail is load-bearing for the central claim that execution mismatches demonstrate intrinsic reasoning-to-execution gaps, because ambiguities or over-specification in the derived intents could produce the observed failures independently of model limitations.
- [§5] §5 (Evaluation Results): Although the abstract states that an extensive evaluation of 16 LLMs was performed and reports specific qualitative findings on generalization and multi-step failures, the manuscript provides no quantitative metrics, result tables, baseline comparisons, or details on trace filtering and intent derivation. Without these, the magnitude of the reported gaps cannot be assessed and the execution-based analysis cannot be verified.
minor comments (2)
- The anonymous code and data link is appropriate for blind review but should be replaced with a permanent repository in the camera-ready version.
- [Abstract] The abstract is information-dense; splitting the description of the evaluation framework into a separate sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving clarity and completeness. We agree that both the benchmark construction methodology and the presentation of quantitative results require substantial expansion. We address each major comment below and will incorporate all suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction and Intent Derivation): The methodology for translating historical transaction traces into natural language intents is insufficiently specified. It is unclear whether derivation relies on manual annotation, heuristics, LLM assistance, or a combination, how trace filtering was performed, and how the 11 categories ensure coverage of long-tail DeFi interactions and true out-of-distribution cases. This detail is load-bearing for the central claim that execution mismatches demonstrate intrinsic reasoning-to-execution gaps, because ambiguities or over-specification in the derived intents could produce the observed failures independently of model limitations.
Authors: We agree that the current description in §3 is insufficiently detailed and that this information is critical to substantiate our central claims. In the revised manuscript we will expand §3 with a complete account of the intent derivation pipeline. This will include: the specific combination of heuristic parsing of transaction calldata and logs, LLM-assisted natural language paraphrasing, and targeted manual review; the exact trace filtering criteria (removal of failed transactions, dust transfers, and non-standard contract interactions); and the rationale for the 11 categories together with coverage statistics showing representation of long-tail DeFi primitives and explicit OOD identification. We will also add a flowchart, pseudocode, and representative trace-to-intent examples for each category. These additions will allow readers to assess whether the derived intents faithfully reflect real user objectives and will strengthen the argument that observed execution failures reflect model limitations rather than benchmark artifacts. revision: yes
-
Referee: [§5] §5 (Evaluation Results): Although the abstract states that an extensive evaluation of 16 LLMs was performed and reports specific qualitative findings on generalization and multi-step failures, the manuscript provides no quantitative metrics, result tables, baseline comparisons, or details on trace filtering and intent derivation. Without these, the magnitude of the reported gaps cannot be assessed and the execution-based analysis cannot be verified.
Authors: The referee correctly observes that the current manuscript does not present the full quantitative results, tables, or baseline comparisons in sufficient detail. While §5 and the appendix contain some evaluation outcomes, they are not organized or highlighted adequately for readers to assess the magnitude of the gaps. In the revised version we will (1) move all key quantitative tables and figures into the main text, (2) add comprehensive metrics for all 16 models broken down by single-step vs. multi-step, in-distribution vs. OOD, and by category, (3) include explicit baseline comparisons (e.g., rule-based and simpler prompting strategies), and (4) cross-reference the expanded trace-filtering and intent-derivation details from the revised §3. We will also add an error analysis section that directly links syntactic validity to execution outcomes using the differential state analysis. These changes will make the execution-aware evaluation fully verifiable. revision: yes
Circularity Check
No circularity: empirical benchmark from traces with execution verification
full rationale
The paper's core contribution is an empirical benchmark of 29,921 single-step and 1,575 multi-step intents extracted from 300 days of public Ethereum mainnet traces across 11 categories, paired with an execution-aware evaluation that runs generated transactions on forked environments and measures differential state changes. No equations, fitted parameters, or first-principles derivations are claimed; success/failure is defined by observable on-chain state transitions rather than by construction from the input traces or LLM outputs. No self-citations are invoked to justify uniqueness or load-bearing assumptions, and the evaluation of 16 external LLMs relies on direct measurement rather than renaming or smuggling prior results. The derivation chain (trace → intent → LLM generation → execution check) remains open to external falsification and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world Ethereum mainnet traces over 300 days provide a representative sample of protocol interactions suitable for deriving natural language intents across 11 categories
Reference graph
Works this paper leans on
-
[1]
ALAMSYAH, A., KUSUMA, G. N. W.,ANDRAMADHANI, D. P. A review on decentralized finance ecosystems.Future Internet 16, 3 (2024), 76
2024
-
[2]
Program Synthesis with Large Language Models
AUSTIN, J., ODENA, A., NYE, M., BOSMA, M., MICHALEWSKI, H., DOHAN, D., JIANG, E., CAI, C., TERRY, M., LE, Q.,ET AL. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review arXiv 2021
-
[3]
Erc-4337: Account abstraction using alt mempool
BUTERIN, V., WEISS, Y., TIROSH, D., NACSON, S., FORSHTAT, A., GAZSO, K.,ANDHESS, T. Erc-4337: Account abstraction using alt mempool. Tech. rep., Ethereum Improvement Proposals, 2021
2021
-
[4]
Defi protocol risks: The paradox of defi.Regtech, suptech and beyond: innovation and technology in financial services” riskbooks–forthcoming Q 3(2021)
CARTER, N.,ANDJENG, L. Defi protocol risks: The paradox of defi.Regtech, suptech and beyond: innovation and technology in financial services” riskbooks–forthcoming Q 3(2021)
2021
-
[5]
The power of default: Measuring the effect of slippage tolerance in decentralized exchanges
CHEMAYA, N., LIU, D., MCLAUGHLIN, R., RUARO, N., KRUEGEL, C.,ANDVIGNA, G. The power of default: Measuring the effect of slippage tolerance in decentralized exchanges. InInternational Conference on Financial Cryptography and Data Security(2024), Springer, pp. 192–208
2024
-
[6]
CHEN, M., TWOREK, J., JUN, H., YUAN, Q., PINTO, H. P. D. O., KAPLAN, J., EDWARDS, H., BURDA, Y., JOSEPH, N., BROCKMAN, G.,ET AL. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review arXiv 2021
-
[7]
S.,ANDBRINK, A
GOES, C., YIN, A. S.,ANDBRINK, A. Anoma: a unified architecture for full-stack decentralised applications.Anoma Research Topics, Aug(2023)
2023
-
[8]
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models
GUO, Z., CHENG, S., WANG, H., LIANG, S., QIN, Y., LI, P., LIU, Z., SUN, M.,ANDLIU, Y. Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. In Findings of the Association for Computational Linguistics: ACL 2024(2024), pp. 11143–11156
2024
-
[9]
M., SUN, W., SHEN, Y.,ANDPANDA, R
GUO, Z., SORIA, A. M., SUN, W., SHEN, Y.,ANDPANDA, R. Api pack: A massive multi-programming language dataset for api call generation.arXiv preprint arXiv:2402.09615(2024). 10
-
[10]
Characterizing code clones in the ethereum smart contract ecosystem
HE, N., WU, L., WANG, H., GUO, Y.,ANDJIANG, X. Characterizing code clones in the ethereum smart contract ecosystem. InInternational Conference on Financial Cryptography and Data Security(2020), Springer, pp. 654–675
2020
-
[11]
Kevm: A complete formal semantics of the ethereum virtual machine
HILDENBRANDT, E., SAXENA, M., RODRIGUES, N., ZHU, X., DAIAN, P., GUTH, D., MOORE, B., PARK, D., ZHANG, Y., STEFANESCU, A.,ET AL. Kevm: A complete formal semantics of the ethereum virtual machine. In2018 IEEE 31st Computer Security Foundations Symposium (CSF)(2018), IEEE, pp. 204–217
2018
-
[12]
Evmtracer: dynamic analysis of the parallelization and redundancy potential in the ethereum virtual machine.IEEE Access 11(2023), 47159–47178
HU, X., BURGSTALLER, B.,ANDSCHOLZ, B. Evmtracer: dynamic analysis of the parallelization and redundancy potential in the ethereum virtual machine.IEEE Access 11(2023), 47159–47178
2023
-
[13]
Disentangling decentralized finance (defi) compositions.ACM Transactions on the Web 17, 2 (2023), 1–26
KITZLER, S., VICTOR, F., SAGGESE, P.,ANDHASLHOFER, B. Disentangling decentralized finance (defi) compositions.ACM Transactions on the Web 17, 2 (2023), 1–26
2023
-
[14]
Loftq: Lora-fine-tuning-aware quantization for large language models,
LI, Y., YU, Y., LIANG, C., HE, P., KARAMPATZIAKIS, N., CHEN, W.,ANDZHAO, T. Loftq: Lora-fine- tuning-aware quantization for large language models.arXiv preprint arXiv:2310.08659(2023)
-
[15]
Modeling and understanding ethereum transaction records via a complex network approach.IEEE Transactions on Circuits and Systems II: Express Briefs 67, 11 (2020), 2737–2741
LIN, D., WU, J., YUAN, Q.,ANDZHENG, Z. Modeling and understanding ethereum transaction records via a complex network approach.IEEE Transactions on Circuits and Systems II: Express Briefs 67, 11 (2020), 2737–2741
2020
-
[16]
LIU, W., ZENG, W., HE, K., JIANG, Y.,ANDHE, J. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning.arXiv preprint arXiv:2312.15685 (2023)
-
[17]
K.,ANDHASSAN, A
PACHECO, M., OLIVA, G., RAJBAHADUR, G. K.,ANDHASSAN, A. Is my transaction done yet? an empirical study of transaction processing times in the ethereum blockchain platform.ACM Transactions on Software Engineering and Methodology 32, 3 (2023), 1–46
2023
-
[18]
G., MAO, H., YAN, F., JI, C
PATIL, S. G., MAO, H., YAN, F., JI, C. C.-J., SURESH, V., STOICA, I.,ANDGONZALEZ, J. E. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning(2025)
2025
-
[19]
G., ZHANG, T., WANG, X.,ANDGONZALEZ, J
PATIL, S. G., ZHANG, T., WANG, X.,ANDGONZALEZ, J. E. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems 37(2024), 126544–126565
2024
-
[20]
Toolformer: Language models can teach themselves to use tools
SCHICK, T., DWIVEDI-YU, J., DESSÌ, R., RAILEANU, R., LOMELI, M., HAMBRO, E., ZETTLEMOYER, L., CANCEDDA, N.,ANDSCIALOM, T. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems 36(2023), 68539–68551
2023
-
[21]
TUDORACHE, A.-G. A detailed set of ideas for designing a quantum computing framework based on smart contracts, configured using foundry and qiskit.EMITTER International Journal of Engineering Technology 13, 1 (2025), 139–155
2025
-
[22]
Sok: Decentralized exchanges (dex) with automated market maker (amm) protocols.ACM Computing Surveys 55, 11 (2023), 1–50
XU, J., PARUCH, K., COUSAERT, S.,ANDFENG, Y. Sok: Decentralized exchanges (dex) with automated market maker (amm) protocols.ACM Computing Surveys 55, 11 (2023), 1–50
2023
-
[23]
XU, Q., HONG, F., LI, B., HU, C., CHEN, Z.,ANDZHANG, J. On the tool manipulation capability of open-source large language models.arXiv preprint arXiv:2305.16504(2023)
-
[24]
YANG, A., LI, A., YANG, B., ZHANG, B., HUI, B., ZHENG, B., YU, B., GAO, C., HUANG, C., LV, C., ET AL. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review arXiv 2025
-
[25]
EVM-QuestBench: An Execution-Grounded Benchmark for Natural-Language Transaction Code Generation
YANG, P., CHEN, W., WANG, K., AI, L., YANG, E.,ANDSHI, T. Evm-questbench: An execution- grounded benchmark for natural-language transaction code generation.arXiv preprint arXiv:2601.06565 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Auditable llm arbiter for defi security: A hybrid graph-of-thoughts approach to intent–transaction alignment
YAO, D., JAGANNATH, S., AROSO, B., KRISHNAN, V.,ANDZHAO, D. Auditable llm arbiter for defi security: A hybrid graph-of-thoughts approach to intent–transaction alignment
-
[27]
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task
YU, T., ZHANG, R., YANG, K., YASUNAGA, M., WANG, D., LI, Z., MA, J., LI, I., YAO, Q., ROMAN, S.,ET AL. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. InProceedings of the 2018 conference on empirical methods in natural language processing(2018), pp. 3911–3921
2018
-
[28]
YU, Z., ZHAO, Y., COHAN, A.,ANDZHANG, X.-P. Humaneval pro and mbpp pro: Evaluating large language models on self-invoking code generation.arXiv preprint arXiv:2412.21199(2024). 11
-
[29]
Preventing spread of spam transactions in blockchain by reputation
ZHANG, J., CHENG, Y., DENG, X., WANG, B., XIE, J., YANG, Y.,ANDZHANG, M. Preventing spread of spam transactions in blockchain by reputation. In2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS)(2020), IEEE, pp. 1–6
2020
-
[30]
Llamafactory: Unified efficient fine-tuning of 100+ language models
ZHENG, Y., ZHANG, R., ZHANG, J., YE, Y.,ANDLUO, Z. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations)(2024), pp. 400–410. A LLMs participating in the evaluation. Table 3: Models evaluated in our benchmark. Model Ope...
2024
-
[31]
Send all my ETH to my ledger
** For Common Actions ( T ra ns fer / Swap / Wrap ) **: - Act as a casual user . Use c o l l o q u i a l l ang ua ge . - Example : " Send all my ETH to my ledger " , " Swap 100 USDT for some Pepe " , " Wrap 2 Ether ". - * Key *: Focus on the " what " and " how much " , keep it natural
-
[32]
Deposit 500 USDC into the Aave V3 pool
** For Complex / DeFi Actions ( Staking / L i q u i d i t y / Vaults ) **: - Act as a DeFi user . Be more precise about the pr oto co l and the action . 12 - You can even provide sp ec ifi c details ( c ont ra ct address , fu nc tio n s i g n a t u r e ) when the t r a n s a c t i o n is complex or co nt ra ct is obscure . However , you should be careful ...
-
[33]
Vote ’ Yes ’ on Pro po sa l #42
** For Low - level / Niche / Rare C on tr ac t Calls **: - Act as a power user or d e v e l o p e r . If the c on tr act is rare , include sp ec if ic IDs or a d d r e s s e s pr ov id ed in the p a r a m e t e r s . - If the t r a n s a c t i o n c on tai ns a long hex string ( like data or secret ) that cannot be simplified , e x p l i c i t l y mention...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.