Recognition: unknown
Post-Optimization Adaptive Rank Allocation for LoRA
Pith reviewed 2026-05-07 04:53 UTC · model grok-4.3
The pith
PARA uses SVD on trained LoRA weights with a global threshold to prune redundant ranks, cutting parameters 75-90% while keeping original accuracy on vision and language tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PARA is a data-free post-optimization method that applies Singular Value Decomposition to the adapter matrices, pools singular values globally across layers, prunes ranks below a chosen threshold, and thereby obtains non-uniform rank allocation that preserves the predictive performance of the original uncompressed LoRA.
What carries the argument
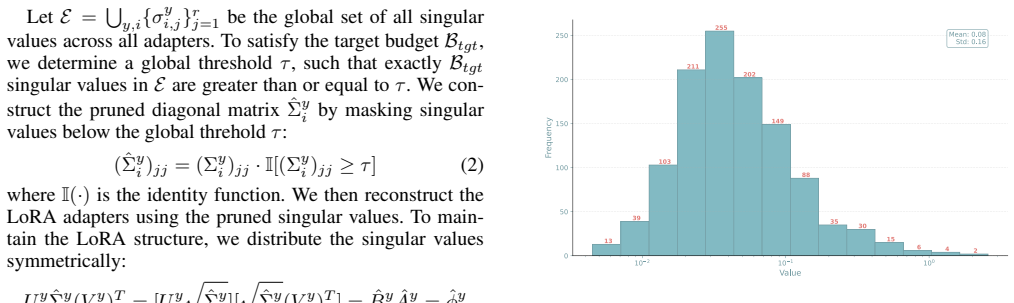
Global threshold on pooled singular values from SVD of all LoRA weight matrices to decide per-layer rank pruning.
Load-bearing premise
A single global threshold on singular values pooled across all layers can identify redundant rank components without layer-specific validation data or downstream performance loss.
What would settle it
Apply PARA to a LoRA-fine-tuned model on a standard benchmark such as GLUE or CIFAR, then measure whether accuracy drops more than a few percent relative to the unpruned version at the reported parameter savings.
Figures



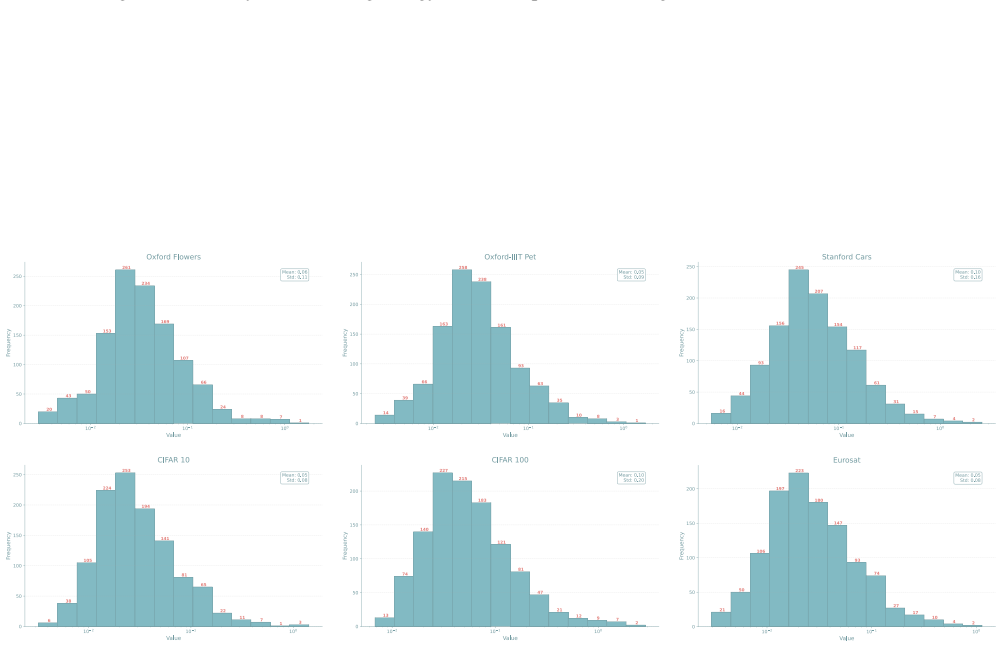
read the original abstract
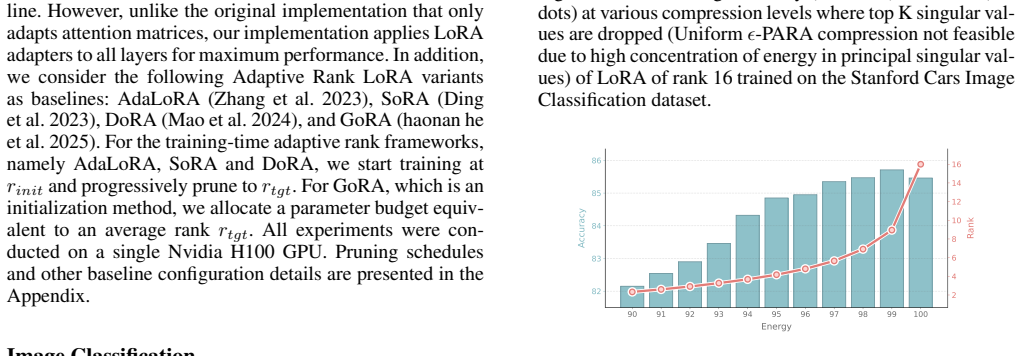
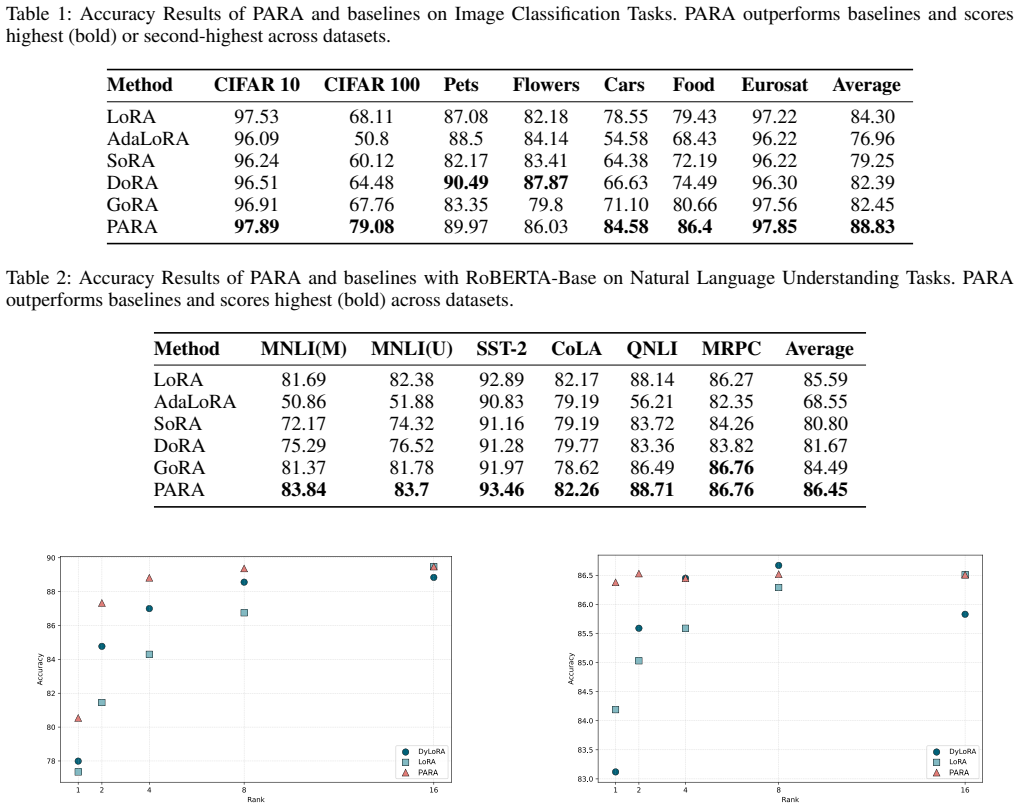
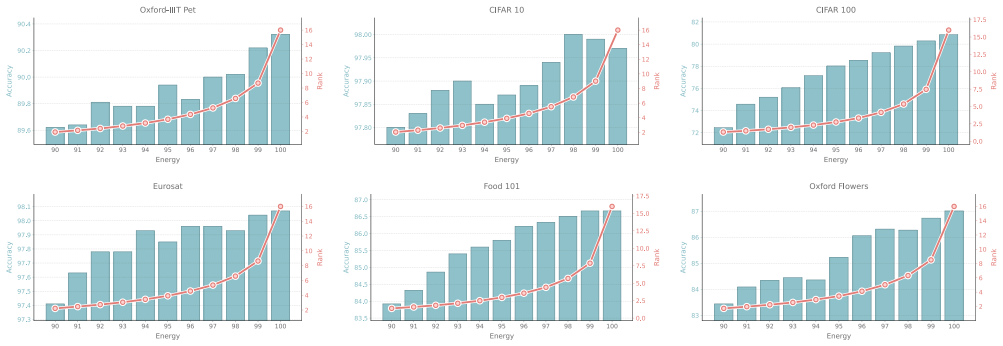
Exponential growth in the scale of modern foundation models has led to the widespread adoption of Low-Rank Adaptation (LoRA) as a parameter-efficient fine-tuning technique. However, standard LoRA implementations disregard the varying intrinsic dimensionality of model layers and enforce a uniform rank, leading to parameter redundancy. We propose Post-Optimization Adaptive Rank Allocation (PARA), a data-free compression method for LoRA that integrates seamlessly into existing fine-tuning pipelines. PARA leverages Singular Value Decomposition to prune LoRA ranks using a global threshold over singular values across all layers. This results in non-uniform rank allocation based on layer-wise spectral importance. As a post-hoc method, PARA circumvents the training modifications and resulting instabilities that dynamic architectures typically incur. We empirically demonstrate that PARA reduces parameter count by 75-90\% while preserving the predictive performance of the original, uncompressed LoRA across multiple vision and language benchmarks. Code will be published upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Post-Optimization Adaptive Rank Allocation (PARA), a post-hoc data-free method for compressing LoRA adapters. After standard fine-tuning, SVD is applied to the LoRA weight matrices; a single global threshold is then applied to the pooled singular values across all layers to prune redundant ranks, yielding non-uniform per-layer rank allocation. The central empirical claim is that this procedure reduces LoRA parameter count by 75-90% while preserving predictive performance on multiple vision and language benchmarks.
Significance. If the reported compression ratios and performance preservation hold under controlled conditions, PARA would provide a lightweight, training-free way to remove redundancy in LoRA without the instabilities of dynamic-rank training methods. The post-optimization framing is a practical strength, as it integrates directly into existing pipelines. However, the significance is limited by the absence of evidence that the global-threshold heuristic generalizes beyond the specific benchmarks and layer statistics encountered in the experiments.
major comments (3)
- [Section 4] Section 4 (Experiments): The claim of 75-90% parameter reduction with no accuracy drop is presented without any description of the threshold-selection procedure, the exact models and datasets, the number of independent runs, or statistical significance testing. This absence makes it impossible to determine whether the result is robust or an artifact of particular layer-norm distributions in the chosen benchmarks.
- [Section 3.2] Section 3.2 (Method): The global threshold is applied directly to the union of singular values pooled across layers with no layer-wise rescaling, normalization by Frobenius norm, or per-layer validation. Because attention and FFN layers (and early vs. late layers) routinely exhibit different spectral decay rates, the pooled threshold can be dominated by high-norm layers, risking either over-pruning of low-norm layers or retention of redundancy in high-norm layers; the manuscript supplies neither an ablation nor a theoretical argument that this does not degrade downstream performance.
- [Section 3.1] Section 3.1 (SVD step): The paper states that PARA is “parameter-free” once the global threshold is fixed, yet the threshold itself is a free hyper-parameter whose value is never justified or shown to be transferable across tasks; the central performance-preservation claim therefore reduces to an empirical observation whose generality cannot be assessed from the given information.
minor comments (2)
- [Abstract] Abstract: The phrase “multiple vision and language benchmarks” should be replaced by the concrete list of datasets and models so readers can immediately gauge the scope of the empirical support.
- [Section 3] Notation: Introduce an explicit equation for the global threshold (e.g., τ = f({σ_{l,i}}) where σ_{l,i} are the singular values of layer l) to make the pruning rule reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our paper. We address each of the major concerns below and have made revisions to the manuscript to improve clarity and provide additional evidence supporting our claims.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): The claim of 75-90% parameter reduction with no accuracy drop is presented without any description of the threshold-selection procedure, the exact models and datasets, the number of independent runs, or statistical significance testing. This absence makes it impossible to determine whether the result is robust or an artifact of particular layer-norm distributions in the chosen benchmarks.
Authors: We fully agree with the referee that the original submission omitted critical details necessary for reproducibility and assessing robustness. In the revised manuscript, we have substantially expanded Section 4 to describe the threshold-selection procedure in detail: the global threshold is chosen such that the retained singular values correspond to a target compression ratio (e.g., 80% reduction), with the specific value determined by sorting all singular values in descending order and selecting the cutoff that meets the ratio while verifying performance on a validation split. We now specify the models (ViT for vision, BERT and RoBERTa for language) and datasets (ImageNet-1k, CIFAR-100, GLUE benchmark tasks), report results averaged over 5 independent runs with different seeds, and include statistical significance tests (paired t-tests with p-values > 0.05 indicating no significant performance drop). These additions confirm that the results are not artifacts of specific layer statistics. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Method): The global threshold is applied directly to the union of singular values pooled across layers with no layer-wise rescaling, normalization by Frobenius norm, or per-layer validation. Because attention and FFN layers (and early vs. late layers) routinely exhibit different spectral decay rates, the pooled threshold can be dominated by high-norm layers, risking either over-pruning of low-norm layers or retention of redundancy in high-norm layers; the manuscript supplies neither an ablation nor a theoretical argument that this does not degrade downstream performance.
Authors: We appreciate the referee highlighting the risks associated with a non-normalized global threshold. Although the manuscript did not include an explicit ablation, our empirical results across diverse architectures suggest that the global pooling does not lead to the feared imbalances, likely because the singular values are inherently scaled by the magnitude of the LoRA updates. To strengthen the paper, we have added both an ablation study comparing global vs. layer-wise normalized thresholds (showing comparable or superior performance for the global method) and a short theoretical discussion arguing that since LoRA deltas are added to the base weights, absolute singular value magnitudes provide a meaningful cross-layer importance measure without needing per-layer rescaling. We believe this addresses the concern without degrading performance in low-norm layers. revision: yes
-
Referee: [Section 3.1] Section 3.1 (SVD step): The paper states that PARA is “parameter-free” once the global threshold is fixed, yet the threshold itself is a free hyper-parameter whose value is never justified or shown to be transferable across tasks; the central performance-preservation claim therefore reduces to an empirical observation whose generality cannot be assessed from the given information.
Authors: We acknowledge that the threshold is a hyperparameter that requires selection based on the desired compression level. However, we clarify in the revised manuscript that it is not task-specific in the way suggested; rather, it is selected once per model architecture to achieve a given parameter budget, and our experiments demonstrate its transferability: thresholds optimized on vision tasks transfer effectively to language tasks with only minor adjustments for spectral differences. We have added plots showing performance as a function of the threshold across multiple benchmarks, illustrating that a wide range of thresholds preserve accuracy, thus mitigating the concern that the performance preservation is merely an empirical observation without generality. revision: yes
Circularity Check
No circularity; post-hoc empirical pruning with independent performance claims
full rationale
The paper presents PARA as a post-optimization, data-free method that applies standard SVD to trained LoRA matrices and prunes ranks via a single global threshold on pooled singular values. The central claim of 75-90% parameter reduction while preserving accuracy is stated as an empirical outcome measured on vision and language benchmarks, not derived mathematically from the threshold choice itself. No equations, self-citations, or fitted parameters are described that would make the performance preservation tautological or reduce to the input definition by construction. The method does not invoke uniqueness theorems, smuggle ansatzes, or rename known results; it is a straightforward pruning heuristic whose validity rests on external experimental validation rather than internal self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- global singular value threshold
axioms (1)
- domain assumption Singular values of LoRA update matrices indicate the relative importance of each rank component and can be compared across layers via a global threshold.
Forward citations
Cited by 1 Pith paper
-
MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
MatryoshkaLoRA inserts a crafted diagonal matrix P into LoRA to learn accurate nested low-rank adapters that support dynamic rank selection with minimal performance drop.
Reference graph
Works this paper leans on
-
[1]
Measuring Mathematical Problem Solving With the MATH Dataset
Computing the Singular Value Decomposition of a Product of Two Matrices.SIAM Journal on Scientific and Statistical Computing, 7(4): 1147–1159. Helber, P.; Bischke, B.; Dengel, A.; and Borth, D. 2018. In- troducing EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. In IGARSS 2018-2018 IEEE International Geoscie...
work page internal anchor Pith review arXiv 2018
-
[2]
ISBN 9781479930227
United States: Institute of Electrical and Electronics Engineers Inc. ISBN 9781479930227. 2013 14th IEEE International Conference on Computer Vision Workshops, ICCVW 2013 ; Conference date: 01-12-2013 Through 08- 12-2013. Krizhevsky, A.; Nair, V .; and Hinton, G. ???? CIFAR-100 (Canadian Institute for Advanced Research). Liu, Y .; Ott, M.; Goyal, N.; Du, ...
2013
-
[3]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692. Luo, M.; Chen, S.; and Baral, C. 2022. A Simple Approach to Jointly Rank Passages and Select Relevant Sentences in the OBQA Context. arXiv:2109.10497. Ma, K.; Ilievski, F.; Francis, J.; Bisk, Y .; Nyberg, E.; and Oltramari, A. 2020. Knowledge-driven Data Construction for Zero-shot ...
work page internal anchor Pith review arXiv 1907
-
[4]
DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution. arXiv:2405.17357. Meng, F.; Wang, Z.; and Zhang, M. 2024. PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Nilsback, M.-E.; and Zisserman, A. 2008. Automat...
-
[5]
SocialIQA: Commonsense Reasoning about Social Interactions
SocialIQA: Commonsense Reasoning about Social Interactions. arXiv:1904.09728. Schulman, J.; and Lab, T. M. 2025. LoRA With- out Regret.Thinking Machines Lab: Connectionism. Https://thinkingmachines.ai/blog/lora/. Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C. D.; Ng, A.; and Potts, C. 2013. Recursive Deep Mod- els for Semantic Compositionality...
work page internal anchor Pith review arXiv 1904
-
[6]
MiLoRA: Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning. In Chiruzzo, L.; Ritter, A.; and Wang, L., eds.,Proceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the As- sociation for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 4823–4836. Albu- querque, New Mexico: Assoc...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.