Recognition: unknown
AME-PIM: Can Memory be Your Next Tensor Accelerator?
Pith reviewed 2026-05-07 06:32 UTC · model grok-4.3
The pith
HBM-PIM executes RISC-V AME matrix instructions at 14.9 GFLOP/s by keeping all accumulation inside memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
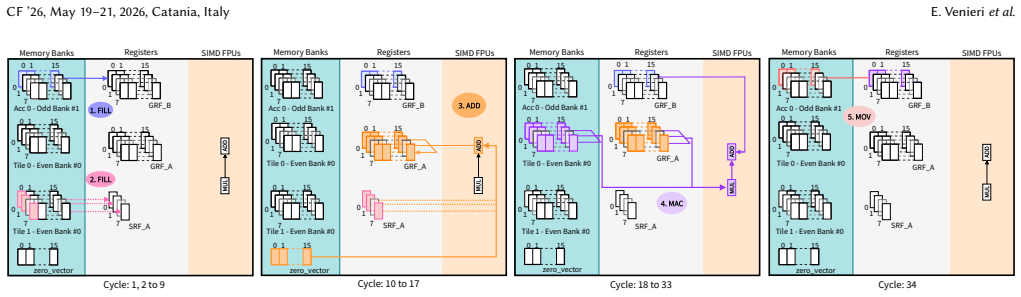
We propose a PEP-based execution model that maps AME element-wise and matrix instructions to HBM-PIM micro-kernels and data instructions. A reduction-free outer-product dataflow enables accumulation entirely within memory despite the lack of native reduction support. This supports end-to-end execution of element-wise operations, GEMV, and GEMM in PIM mode, minimizing host involvement and off-chip transfers. Experimental evaluation on Samsung Aquabolt-XL demonstrates AME matrix tile multiplication achieving up to 14.9 GFLOP/s (59.4 FLOP/cycle) on a single HBM pseudo-channel.
What carries the argument
The reduction-free outer-product dataflow, which performs matrix accumulation entirely inside the memory array by organizing computation so that no explicit reduction steps are required.
If this is right
- Element-wise, GEMV, and GEMM operations run end-to-end inside the memory without repeated host intervention.
- Off-chip data transfers drop because results accumulate locally in the HBM array.
- Standard RISC-V AME semantics become usable on existing commercial HBM-PIM platforms through the mapping.
- A single HBM pseudo-channel delivers up to 59.4 FLOP per cycle for matrix-tile multiplication.
Where Pith is reading between the lines
- The same outer-product mapping idea could be adapted to other limited-instruction PIM platforms or different host ISAs.
- Future PIM hardware that added native reduction support would simplify the dataflow and raise peak efficiency.
- Software runtimes for RISC-V could expose this PIM backend to existing matrix libraries with little change.
Load-bearing premise
The mapping of AME instructions to PIM micro-kernels succeeds in keeping full accumulation inside memory without large extra costs from the hardware's restricted instruction set.
What would settle it
Run the proposed GEMM kernel on Samsung Aquabolt-XL hardware and measure whether matrix-tile performance reaches 14.9 GFLOP/s while all accumulation stays inside the memory array with no significant host data movement.
Figures






read the original abstract
High Bandwidth Memory with Processing-in-Memory (HBM-PIM) offers an opportunity to reduce data movement by executing computation directly inside memory, but current commercial platforms expose limited instruction sets and require specialized software stacks. In this work, we investigate whether HBM-PIM can serve as a backend for ISA-level matrix acceleration, using the RISC-V Attached Matrix Extension (AME) as a semantic reference. We propose a PEP-based execution model that maps AME element-wise and matrix instructions to HBM-PIM micro-kernels and data instructions in memory operations. Differently from SoA HBM-PIM, we introduce a reduction-free outer-product dataflow that enables accumulation entirely within memory despite the lack of native reduction support. Our approach supports end-to-end execution of element-wise operations, GEMV, and GEMM in PIM mode, minimizing host involvement and off-chip transfers. An experimental evaluation on Samsung Aquabolt-XL shows that AME matrix tile multiplication achieves up to 14.9 GFLOP/s (59.4 FLOP/cycle) on a single HBM pseudo-channel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AME-PIM, which uses the RISC-V Attached Matrix Extension (AME) as a semantic reference to map matrix and element-wise instructions onto commercial HBM-PIM hardware via a PEP-based execution model. The central technical contribution is a reduction-free outer-product dataflow that performs accumulation entirely inside memory banks despite the limited ISA of platforms such as Samsung Aquabolt-XL. The work claims end-to-end support for element-wise operations, GEMV, and GEMM while minimizing host involvement and off-chip transfers. Hardware evaluation reports a peak of 14.9 GFLOP/s (59.4 FLOP/cycle) for AME matrix tile multiplication on a single HBM pseudo-channel.
Significance. If the mapping and performance claims hold, the paper would demonstrate that existing commercial HBM-PIM can serve as a practical backend for a standard matrix ISA extension, providing a concrete path to reduce data movement in tensor workloads without new silicon. The direct evaluation on Aquabolt-XL supplies a falsifiable, hardware-measured performance anchor rather than simulation-only results, which is a clear strength. Broader impact would depend on whether the approach scales beyond single pseudo-channels and delivers competitive efficiency versus established accelerators, but the reported FLOP/cycle efficiency on real hardware is noteworthy for the PIM domain.
major comments (3)
- [§4.2] §4.2 (Reduction-free outer-product dataflow): The claim that outer-product updates enable full accumulation inside memory banks without native reduction support is load-bearing for the 'minimizing host involvement' assertion. The description does not provide the concrete sequence of micro-kernels and data instructions that would allow multi-tile GEMM to complete without inter-bank transfers or host-orchestrated partial-sum merging, given Aquabolt-XL's restricted per-bank ISA.
- [§5.1] §5.1 (Experimental evaluation): The reported 14.9 GFLOP/s (59.4 FLOP/cycle) on a single pseudo-channel is the primary empirical result. The section must specify the exact matrix dimensions, tile sizes, number of operations measured, and whether the cycle count includes PEP setup, data-layout, and any synchronization overheads; without this breakdown it is impossible to confirm that the measurement captures only in-memory accumulation rather than unaccounted host or inter-bank costs.
- [§3.1] §3.1 (PEP execution model): The mapping of AME matrix instructions to HBM-PIM micro-kernels is presented at a high level. A worked example showing the exact instruction sequence and bank-level state for a small GEMM tile (e.g., 32×32) would be required to verify that the reduction-free property holds under the platform's limited instruction set and does not require multiple passes.
minor comments (3)
- The abstract states the peak performance but does not indicate the matrix dimensions or configuration that achieve 14.9 GFLOP/s; adding this detail would improve immediate readability.
- [§5] Figure captions and axis labels in the evaluation section should explicitly state whether reported cycles are wall-clock or compute-only and whether error bars or multiple runs are shown.
- [§2] The related-work discussion would benefit from a concise table contrasting AME-PIM's dataflow and host-involvement characteristics against prior HBM-PIM accelerators.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review, as well as for recognizing the value of our hardware evaluation on real Aquabolt-XL silicon. We have revised the manuscript to address the clarity concerns raised in the major comments. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Reduction-free outer-product dataflow): The claim that outer-product updates enable full accumulation inside memory banks without native reduction support is load-bearing for the 'minimizing host involvement' assertion. The description does not provide the concrete sequence of micro-kernels and data instructions that would allow multi-tile GEMM to complete without inter-bank transfers or host-orchestrated partial-sum merging, given Aquabolt-XL's restricted per-bank ISA.
Authors: We agree that the original description in §4.2 would benefit from greater explicitness to fully substantiate the reduction-free property. In the revised manuscript we have expanded this section with a concrete sequence of HBM-PIM micro-kernels and data instructions for a representative multi-tile GEMM. The added material shows how the outer-product dataflow, combined with the PEP execution model and our chosen data layout, confines all accumulation to individual memory banks using only the instructions available on Aquabolt-XL. No inter-bank transfers or host-orchestrated merging of partial sums are required, thereby preserving the claim of minimized host involvement. revision: yes
-
Referee: [§5.1] §5.1 (Experimental evaluation): The reported 14.9 GFLOP/s (59.4 FLOP/cycle) on a single pseudo-channel is the primary empirical result. The section must specify the exact matrix dimensions, tile sizes, number of operations measured, and whether the cycle count includes PEP setup, data-layout, and any synchronization overheads; without this breakdown it is impossible to confirm that the measurement captures only in-memory accumulation rather than unaccounted host or inter-bank costs.
Authors: We appreciate the request for a more granular experimental breakdown. The revised §5.1 now reports the precise matrix dimensions and tile sizes used to obtain the 14.9 GFLOP/s peak, together with the number of operations measured. We also clarify that the cycle counts are taken from hardware performance counters that isolate the in-memory execution phase; a separate accounting of PEP setup, data-layout preparation, and synchronization overheads is provided and shown to be excluded from the reported FLOP/cycle figure. This additional detail confirms that the measured efficiency reflects only the reduction-free in-bank accumulation. revision: yes
-
Referee: [§3.1] §3.1 (PEP execution model): The mapping of AME matrix instructions to HBM-PIM micro-kernels is presented at a high level. A worked example showing the exact instruction sequence and bank-level state for a small GEMM tile (e.g., 32×32) would be required to verify that the reduction-free property holds under the platform's limited instruction set and does not require multiple passes.
Authors: We concur that a low-level worked example would make the mapping more verifiable. The revised §3.1 now includes a detailed worked example for a 32×32 GEMM tile. It presents the exact sequence of AME instructions, their translation into HBM-PIM micro-kernels and data operations, and the resulting bank-level state transitions. The example demonstrates that the reduction-free outer-product dataflow completes accumulation in a single pass using only the restricted per-bank ISA, without requiring multiple passes or additional reduction steps. revision: yes
Circularity Check
No significant circularity; central performance result is direct hardware measurement
full rationale
The paper presents its key result (14.9 GFLOP/s on Aquabolt-XL) as an experimental measurement obtained by running the proposed PEP-based mapping on commercial HBM-PIM hardware. The reduction-free outer-product dataflow and AME-to-PIM instruction mapping are introduced as a design proposal whose correctness is validated by end-to-end execution rather than by any equation that reduces to its own inputs. No fitted parameters, self-citations that carry the central claim, or ansatzes smuggled via prior work are used to derive the reported throughput; the numbers come from cycle-accurate execution on the target platform. The derivation chain for the execution model is therefore self-contained and externally falsifiable by the hardware experiment itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Commercial HBM-PIM platforms support micro-kernels for element-wise and matrix operations that can be invoked via data instructions in memory operations.
Reference graph
Works this paper leans on
-
[1]
Arm Ltd. 2024. Arm Scalable Matrix Extension (SME) Introduction. https://developer.arm.com/community/arm-community-blogs/b/architectures- and-processors-blog/posts/arm-scalable-matrix-extension-introduction. Accessed: 2026-01-26
2024
-
[2]
Danilo Cammarata, Matteo Perotti, Marco Bertuletti, Angelo Garofalo, Pasquale Davide Schiavone, David Atienza, and Luca Benini. 2025. Quadrilatero: A RISC-V programmable matrix coprocessor for low-power edge applications. InProceedings of the 22nd ACM International Conference on Computing Frontiers: Workshops and Special Sessions (CF ’25 Companion). Assoc...
-
[3]
Kyungjun Cho, Hyunsuk Lee, and Joungho Kim. 2016. Signal and power integrity design of 2.5D HBM (High bandwidth memory module) on SI interposer. In2016 Pan Pacific Microelectronics Symposium (Pan Pacific). 1–5. doi:10.1109/PanPacific. 2016.7428425
-
[4]
Jinwoo Choi, Yeonan Ha, Hanna Cha, Seil Lee, Sungchul Lee, Jounghoo Lee, Shin- haeng Kang, Bongjun Kim, Hanwoong Jung, Hanjun Kim, and Youngsok Kim
-
[5]
MPC-Wrapper: Fully Harnessing the Potential of Samsung Aquabolt-XL HBM2-PIM on FPGAs. In2024 IEEE 32nd Annual International Symposium on AME-PIM: Can Memory be Your Next Tensor Accelerator? CF ’26, May 19–21, 2026, Catania, Italy Field-Programmable Custom Computing Machines (FCCM). 162–172. doi:10.1109/ FCCM60383.2024.00027
-
[6]
Ersin Cukurtas, Kavish Ranawella, Kevin Skadron, and Mircea Stan. 2026. IM- PRINT: In-Memory Processing with Indirect Addressing Techniques for GPU- hosted HBM-PIM. InProceedings of the International Symposium on Memory Systems (MemSys ’25). Association for Computing Machinery, New York, NY, USA, 165–176. doi:10.1145/3767110.3767121
-
[7]
Intel Corporation. 2023. Intel ® Architecture Instruction Set Extensions and Future Features Programming Reference. https://cdrdv2-public.intel.com/836496/ architecture-instruction-set-extensions-programming-reference.pdf. Includes Intel AMX architectural overview and instructions. Accessed: 2026-01-26
2023
-
[8]
JEDEC Solid State Technology Association. 2013. High Bandwidth Memory (HBM) DRAM. JESD235. www.jedec.org Standard document, available from www.jedec.org
2013
- [9]
-
[10]
Shinhaeng Kang, Sukhan Lee, Byeongho Kim, Hweesoo Kim, Kyomin Sohn, Nam Sung Kim, and Eojin Lee. 2022. An FPGA-based RNN-T Inference Accelerator with PIM-HBM. InProceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays(Virtual Event, USA)(FPGA ’22). Association for Computing Machinery, New York, NY, USA, 146–152. doi:10.1...
-
[11]
Taewoon Kang, Geonwoo Choi, Taeweon Suh, and Gunjae Koo. 2025. SparsePIM: An Efficient HBM-Based PIM Architecture for Sparse Matrix-Vector Multiplica- tions. InProceedings of the 39th ACM International Conference on Supercomputing (ICS ’25). Association for Computing Machinery, New York, NY, USA, 495–512. doi:10.1145/3721145.3735111
- [12]
-
[13]
Jin Hyun Kim, Shin-haeng Kang, Sukhan Lee, Hyeonsu Kim, Woongjae Song, Yuhwan Ro, Seungwon Lee, David Wang, Hyunsung Shin, Bengseng Phuah, Jihyun Choi, Jinin So, YeonGon Cho, JoonHo Song, Jangseok Choi, Jeonghyeon Cho, Kyomin Sohn, Youngsoo Sohn, Kwangil Park, and Nam Sung Kim. 2021. Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML ac- celer...
-
[14]
Young-Cheon Kwon, Suk Han Lee, Jaehoon Lee, Sang-Hyuk Kwon, Je Min Ryu, Jong-Pil Son, O Seongil, Hak-Soo Yu, Haesuk Lee, Soo Young Kim, Youngmin Cho, Jin Guk Kim, Jongyoon Choi, Hyun-Sung Shin, Jin Kim, BengSeng Phuah, HyoungMin Kim, Myeong Jun Song, Ahn Choi, Daeho Kim, SooYoung Kim, Eun- Bong Kim, David Wang, Shinhaeng Kang, Yuhwan Ro, Seungwoo Seo, Joo...
-
[15]
Sukhan Lee, Shin-haeng Kang, Jaehoon Lee, Hyeonsu Kim, Eojin Lee, Seungwoo Seo, Hosang Yoon, Seungwon Lee, Kyounghwan Lim, Hyunsung Shin, Jinhyun Kim, O Seongil, Anand Iyer, David Wang, Kyomin Sohn, and Nam Sung Kim. 2021. Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology : Industrial Product. In2021 ACM/IEEE 48th Annual...
-
[16]
RISC-V International. 2024. Enhancing the Future of AI/ML with Attached Matrix Extension. https://riscv.org/blog/enhancing-the-future-of-ai-ml-with-attached- matrix-extension/. Accessed: 2026-01-22
2024
-
[17]
Kyomin Sohn, Won-Joo Yun, Reum Oh, Chi-Sung Oh, Seong-Young Seo, Min- Sang Park, Dong-Hak Shin, Won-Chang Jung, Sang-Hoon Shin, Je-Min Ryu, Hye-Seung Yu, Jae-Hun Jung, Hyunui Lee, Seok-Yong Kang, Young-Soo Sohn, Jung-Hwan Choi, Yong-Cheol Bae, Seong-Jin Jang, and Gyoyoung Jin. 2017. A 1.2 V 20 nm 307 GB/s HBM DRAM With At-Speed Wafer-Level IO Test Scheme ...
-
[18]
XuanTie RISC-V Team. 2024. RISC-V Matrix Specification Proposal. https: //github.com/XUANTIE-RV/riscv-matrix-extension-spec. Version v0.6.0, 2024- 12-11: Draft
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.