Recognition: unknown
CastFlow: Learning Role-Specialized Agentic Workflows for Time Series Forecasting
Pith reviewed 2026-05-07 05:41 UTC · model grok-4.3
The pith
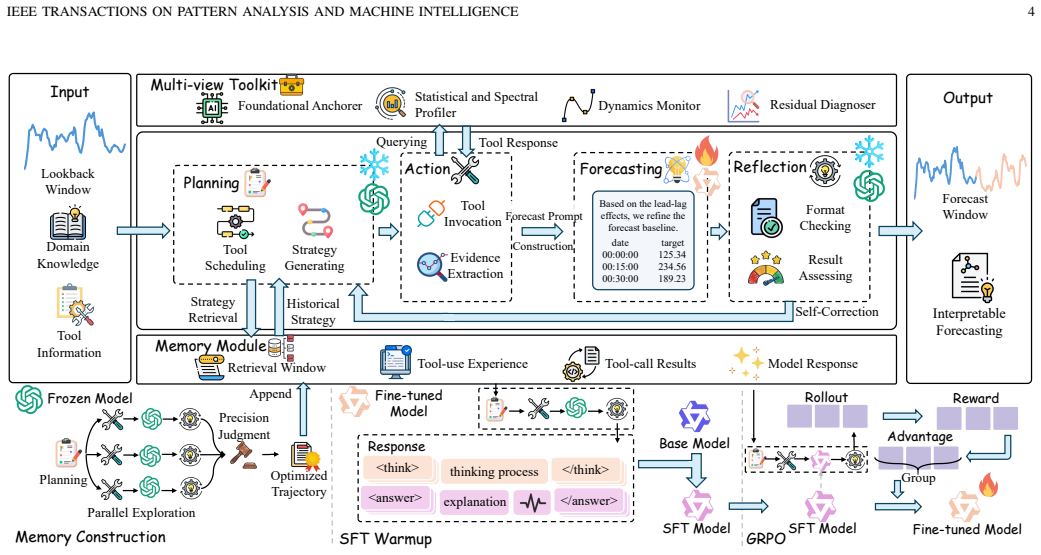
CastFlow structures time series forecasting as a role-specialized agentic workflow that pairs a frozen general LLM for reasoning with a fine-tuned domain-specific LLM for numerical prediction to overcome single-pass limitations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CastFlow is a dynamic agentic forecasting framework that organizes the process into planning, action, forecasting, and reflection phases. The workflow is supported by a memory module that retrieves prior experience and a multi-view toolkit that constructs diagnostic evidence while supplying a reliable ensemble forecast baseline. Under a role-specialized design, a frozen general-purpose LLM preserves broad reasoning capabilities while a fine-tuned domain-specific LLM performs evidence-guided numerical forecasting from the ensemble baseline. Optimization of the domain-specific LLM uses a two-stage workflow-oriented training procedure that combines supervised fine-tuning with reinforcement学习. 受
What carries the argument
the role-specialized agentic workflow of planning, action, forecasting, and reflection phases, supported by memory retrieval and a multi-view toolkit that supplies ensemble baselines for a fine-tuned domain-specific LLM
If this is right
- Multi-view temporal pattern extraction becomes feasible through the agentic structure and toolkit.
- Multi-round contextual feature acquisition is supported by iterative memory and reflection steps.
- Iterative forecast refinement occurs via the reflection phase acting on ensemble evidence.
- Forecasting gains direct support from ensemble baselines rather than starting from raw history alone.
- Superior overall performance is observed against strong baselines across diverse time series datasets.
Where Pith is reading between the lines
- The same separation of general reasoning from specialized numerical work could be tested in other sequential prediction settings such as demand planning or sensor data streams.
- Two-stage training that first aligns a model to workflow steps and then refines it with verifiable rewards may reduce the data needed for domain adaptation in other agentic systems.
- Adding human feedback directly into the reflection phase would be a natural next test of whether the framework can move from fully automated to human-in-the-loop forecasting.
- The memory module's retrieval of prior experience suggests the approach could accumulate cross-dataset knowledge over time without full retraining.
Load-bearing premise
The assumption that separating general reasoning in a frozen LLM from numerical forecasting in a fine-tuned LLM, optimized through SFT followed by RLVR, will produce reliably better temporal patterns and forecasts without introducing new failure modes or overfitting on the chosen datasets.
What would settle it
An ablation study or evaluation on fresh held-out datasets in which removing the role specialization or the two-stage training causes CastFlow to lose its performance advantage over strong single-pass LLM baselines or statistical methods would falsify the central claim.
Figures








read the original abstract
Recently, large language models (LLMs) have shown great promise in time series forecasting. However, most existing LLM-based forecasting methods still follow a static generative paradigm that directly maps historical observations to future values in a single pass. Under this paradigm, forecasting is constrained by limited temporal pattern extraction, single-round acquisition of contextual features, one-shot forecast generation, and lack of support from ensemble forecasts. To address these limitations, in this work, we propose CastFlow, a dynamic agentic forecasting framework that enables multi-view temporal pattern extraction, multi-round contextual features acquisition, iterative forecast refinement, and forecasting with ensemble forecasts. First, CastFlow organizes the forecasting process into planning, action, forecasting, and reflection, establishing an agentic workflow. Second, this workflow is supported by a memory module that retrieves prior experience and a multi-view toolkit that constructs diagnostic evidence and provides a reliable ensemble forecast baseline. Third, CastFlow adopts a role-specialized design that combines general-purpose reasoning with specialized numerical forecasting. Under this design, a frozen LLM preserves general-purpose reasoning, while a fine-tuned domain-specific LLM performs evidence-guided numerical forecasting based on the ensemble forecast baseline, rather than from scratch. To optimize a fine-tuned domain-specific LLM, we further develop a two-stage workflow-oriented training that combines supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). To evaluate the effectiveness of CastFlow, we conduct extensive experiments on diverse datasets and show that it achieves superior overall results against strong baselines. We hope that this work can serve as a step toward more adaptive and accurate time series forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CastFlow, a dynamic agentic framework for time series forecasting that structures the process into planning-action-forecasting-reflection stages. It incorporates a memory module for prior experience retrieval and a multi-view toolkit for diagnostic evidence and ensemble forecast baselines. The framework uses a role-specialized design pairing a frozen general-purpose LLM for reasoning with a fine-tuned domain-specific LLM for evidence-guided numerical forecasting (starting from the ensemble baseline rather than scratch). Optimization employs a two-stage workflow-oriented training combining supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). Extensive experiments on diverse datasets are reported to demonstrate superior overall performance against strong baselines by enabling multi-view temporal pattern extraction, multi-round contextual acquisition, iterative refinement, and ensemble-supported forecasting.
Significance. If the experimental claims are substantiated with proper controls, CastFlow could advance LLM-based time series forecasting by shifting from static single-pass generation to iterative, role-specialized agentic workflows that integrate ensemble baselines and reflection. The two-stage SFT+RLVR training for domain-specific numerical forecasting and the multi-view toolkit represent potentially reusable engineering contributions for adaptive forecasting systems, provided ablations confirm they add value beyond existing ensemble and prompting techniques.
major comments (2)
- [Experiments (ablation studies)] The central claim—that CastFlow achieves superior results via the role-specialized design and two-stage training—rests on the assumption that fine-tuning the domain-specific LLM (via SFT then RLVR) improves upon the ensemble forecast baseline without introducing new failure modes. However, the experiments do not include ablations that hold the agentic workflow, memory module, and multi-view toolkit fixed while varying only the forecasting LLM (frozen general-purpose vs. fine-tuned domain-specific). Without this isolation, it remains unclear whether reported gains derive from the toolkit/ensemble alone or from the specialization and RLVR stage. This directly affects the load-bearing claim in the abstract and method description.
- [Abstract and §4 Experiments] The abstract asserts superior overall results against strong baselines on diverse datasets, yet provides no quantitative metrics, error bars, dataset statistics, or specific baseline comparisons. The full experimental section must report these (including per-dataset MAE/RMSE, statistical significance, and ablation tables) to allow verification of the multi-view extraction, iterative refinement, and ensemble benefits; otherwise the soundness of the headline result cannot be assessed.
minor comments (3)
- [Method (training subsection)] The description of the RLVR stage should explicitly define the verifiable reward function (e.g., how forecast accuracy is quantified and verified against ground truth) and the policy optimization details, as these are central to reproducing the two-stage training.
- [Method] Clarify the exact composition of the multi-view toolkit (which views are constructed and how they feed into the ensemble baseline) to distinguish its contribution from prior ensemble methods in time series literature.
- [Discussion or Experiments] Add a limitations or failure-mode analysis section discussing cases where the reflection stage or fine-tuned LLM may degrade performance relative to the frozen baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments (ablation studies)] The central claim—that CastFlow achieves superior results via the role-specialized design and two-stage training—rests on the assumption that fine-tuning the domain-specific LLM (via SFT then RLVR) improves upon the ensemble forecast baseline without introducing new failure modes. However, the experiments do not include ablations that hold the agentic workflow, memory module, and multi-view toolkit fixed while varying only the forecasting LLM (frozen general-purpose vs. fine-tuned domain-specific). Without this isolation, it remains unclear whether reported gains derive from the toolkit/ensemble alone or from the specialization and RLVR stage. This directly affects the load-bearing claim in the abstract and method description.
Authors: We agree this specific ablation is necessary to isolate the contribution of the fine-tuned domain-specific LLM. The manuscript includes ablations on workflow stages, memory, and toolkit, but not this exact comparison. We will add it in revision by evaluating a controlled variant that replaces only the forecasting LLM with the frozen general-purpose model while fixing the agentic workflow, memory retrieval, and multi-view toolkit. This will clarify whether gains stem from specialization and RLVR or from the ensemble and toolkit alone. revision: yes
-
Referee: [Abstract and §4 Experiments] The abstract asserts superior overall results against strong baselines on diverse datasets, yet provides no quantitative metrics, error bars, dataset statistics, or specific baseline comparisons. The full experimental section must report these (including per-dataset MAE/RMSE, statistical significance, and ablation tables) to allow verification of the multi-view extraction, iterative refinement, and ensemble benefits; otherwise the soundness of the headline result cannot be assessed.
Authors: We agree the abstract should include key quantitative highlights. We will revise it to report average MAE/RMSE improvements and dataset diversity. The experimental section already presents per-dataset MAE/RMSE results and baseline comparisons across multiple datasets, along with ablation tables. To fully address the request, we will add error bars, statistical significance tests (e.g., paired t-tests), explicit dataset statistics, and expanded discussion of how results verify multi-view extraction, iterative refinement, and ensemble benefits. revision: partial
Circularity Check
No circularity: empirical framework validated by external experiments
full rationale
The paper presents CastFlow as an engineering framework for LLM-based time series forecasting, organized around an agentic workflow (planning/action/forecasting/reflection), memory module, multi-view toolkit, and role-specialized LLMs trained via SFT then RLVR. All central claims of superiority are grounded in reported experiments on diverse datasets against baselines, not in any mathematical derivation, equation, or first-principles result that reduces to its own inputs by construction. No self-definitional steps, fitted inputs relabeled as predictions, or load-bearing self-citations appear in the derivation chain; the contribution is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen general-purpose LLM preserves reliable reasoning while a separate fine-tuned LLM can perform evidence-guided numerical forecasting
invented entities (1)
-
CastFlow agentic workflow (planning-action-forecasting-reflection stages plus memory and multi-view toolkit)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 iflytek renewable power forecasting challenge (wind and solar),
iFLYTEK AI Challenge, “2025 iflytek renewable power forecasting challenge (wind and solar),” https://challenge.xfyun.cn/topic/info?type= renewable-power-forecast&option=ssgy&ch=dwsf259, 2025, accessed: Apr. 30, 2026
2025
-
[2]
US MOPEX data set,
J. Schaake, S. Cong, and Q. Duan, “US MOPEX data set,” Lawrence Livermore National Laboratory, Livermore, CA, USA, Tech. Rep., 2006
2006
-
[3]
A comprehensive survey of time series forecasting: Concepts, challenges, and future directions,
M. Cheng, Z. Liu, X. Tao, Q. Liu, J. Zhang, T. Pan, S. Zhang, P. He, X. Zhang, D. Wanget al., “A comprehensive survey of time series forecasting: Concepts, challenges, and future directions,”TechRxiv,
-
[4]
Available: https://doi.org/10.36227/techrxiv.174430535
[Online]. Available: https://doi.org/10.36227/techrxiv.174430535. 53879341/v1
-
[5]
TFB: Towards comprehensive and fair benchmarking of time series forecasting methods,
X. Qiu, J. Hu, L. Zhou, X. Wu, J. Du, B. Zhang, C. Guo, A. Zhou, C. S. Jensen, Z. Sheng, and B. Yang, “TFB: Towards comprehensive and fair benchmarking of time series forecasting methods,”Proceedings of the VLDB Endowment, vol. 17, no. 9, pp. 2363–2377, 2024
2024
-
[6]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=SJiHXGW AZ
2018
-
[7]
Multivariate time-series representation learning via hierarchical correlation pooling boosted graph neural network,
Y . Wang, M. Wu, X. Li, L. Xie, and Z. Chen, “Multivariate time-series representation learning via hierarchical correlation pooling boosted graph neural network,”IEEE Transactions on Artificial Intelligence, vol. 5, no. 1, pp. 321–333, 2024
2024
-
[8]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Y . Wang, H. Wu, J. Dong, Y . Liu, M. Long, and J. Wang, “Deep time series models: A comprehensive survey and benchmark,” arXiv preprint arXiv:2407.13278, 2024. [Online]. Available: https: //arxiv.org/abs/2407.13278
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Deep learning for time series forecasting: Tutorial and literature survey,
K. Benidis, S. S. Rangapuram, V . Flunkert, Y . Wang, D. C. Maddix, C. Turkmen, J. Gasthaus, M. Bohlke-Schneider, D. Salinas, L. Stella et al., “Deep learning for time series forecasting: Tutorial and literature survey,”ACM Computing Surveys, vol. 55, no. 6, pp. 1–36, 2022
2022
-
[10]
Automatic time series forecasting: The forecast package for R,
R. J. Hyndman and Y . Khandakar, “Automatic time series forecasting: The forecast package for R,”Journal of Statistical Software, vol. 27, no. 3, pp. 1–22, 2008
2008
-
[11]
Exponential smoothing: The state of the art,
J. Gardner, Everette S., “Exponential smoothing: The state of the art,” Journal of Forecasting, vol. 4, no. 1, pp. 1–28, 1985
1985
-
[12]
Time series prediction using support vector machines: A survey,
N. I. Sapankevych and R. Sankar, “Time series prediction using support vector machines: A survey,”IEEE Computational Intelligence Magazine, vol. 4, no. 2, pp. 24–38, 2009. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 16
2009
-
[13]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 785–794
2016
-
[14]
LightGBM: A highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “LightGBM: A highly efficient gradient boosting decision tree,” in Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[15]
Machine learning strategies for time series forecasting,
G. Bontempi, S. Ben Taieb, and Y .-A. Le Borgne, “Machine learning strategies for time series forecasting,” inBusiness Intelligence: Second European Summer School, eBISS 2012, Brussels, Belgium, July 15– 21, 2012, Tutorial Lectures, ser. Lecture Notes in Business Information Processing. Springer, 2013, vol. 138, pp. 62–77
2012
-
[16]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 22 419–22 430
2021
-
[17]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 11 121–11 128
2023
-
[18]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=Jbdc0vTOcol
2023
-
[19]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, C. Turkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapoor, J. Zschiegner, D. C. Maddix, H. Wang, M. W. Mahoney, K. Torkkola, A. G. Wilson, M. Bohlke-Schneider, and Y . Wang, “Chronos: Learning the language of time series,”Transactions on Machine Learning Research, 2024. [Online]. Available: ht...
2024
-
[20]
A decoder-only foundation model for time-series forecasting,
A. Das, W. Kong, R. Sen, and Y . Zhou, “A decoder-only foundation model for time-series forecasting,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 10 148–10 167. [Online]. Available: https://proceedings.mlr.press/v235/das24c.html
2024
-
[21]
Sundial: A family of highly capable time series foundation models,
Y . Liu, G. Qin, Z. Shi, Z. Chen, C. Yang, X. Huang, J. Wang, and M. Long, “Sundial: A family of highly capable time series foundation models,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 39 295–39 317. [Online]. Available: https://proceedings.mlr.press/v2...
2025
-
[22]
PromptCast: A new prompt-based learning paradigm for time series forecasting,
H. Xue and F. D. Salim, “PromptCast: A new prompt-based learning paradigm for time series forecasting,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6851–6864, 2024
2024
-
[23]
TEMPO: Prompt-based generative pre-trained transformer for time series forecasting,
D. Cao, F. Jia, S. O. Arik, T. Pfister, Y . Zheng, W. Ye, and Y . Liu, “TEMPO: Prompt-based generative pre-trained transformer for time series forecasting,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/ forum?id=YH5w12OUuU
2024
-
[24]
Can slow-thinking LLMs reason over time? empirical studies in time series forecasting,
M. Cheng, J. Wang, D. Wang, X. Tao, Q. Liu, and E. Chen, “Can slow-thinking LLMs reason over time? empirical studies in time series forecasting,” inProceedings of the Nineteenth ACM International Con- ference on Web Search and Data Mining, 2026, pp. 99–110
2026
-
[25]
M. Cheng, X. Tao, H. Zhang, Q. Liu, and E. Chen, “InstructTime++: Time series classification with multimodal language modeling via implicit feature enhancement,”arXiv preprint arXiv:2601.14968, 2026. [Online]. Available: https://arxiv.org/abs/2601.14968
-
[26]
GPT4MTS: Prompt- based large language model for multimodal time-series forecasting,
F. Jia, K. Wang, Y . Zheng, D. Cao, and Y . Liu, “GPT4MTS: Prompt- based large language model for multimodal time-series forecasting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024, pp. 23 343–23 351
2024
-
[27]
TimeSeriesScientist: A general-purpose AI agent for time series analysis,
H. Zhao, X. Zhang, J. Wei, Y . Xu, Y . He, S. Sun, and C. You, “TimeSeriesScientist: A general-purpose AI agent for time series analysis,”arXiv preprint arXiv:2510.01538, 2025. [Online]. Available: https://arxiv.org/abs/2510.01538
-
[28]
Position: Beyond model-centric prediction – agentic time series forecasting,
M. Cheng, X. Tao, Q. Liu, Z. Guo, and E. Chen, “Position: Beyond model-centric prediction – agentic time series forecasting,” arXiv preprint arXiv:2602.01776, 2026. [Online]. Available: https: //arxiv.org/abs/2602.01776
-
[29]
Time-LLM: Time series forecasting by reprogramming large language models,
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan, and Q. Wen, “Time-LLM: Time series forecasting by reprogramming large language models,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=Unb5CVPtae
2024
-
[30]
S2IP-LLM: Semantic space informed prompt learning with LLM for time series forecasting,
Z. Pan, Y . Jiang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song, “S2IP-LLM: Semantic space informed prompt learning with LLM for time series forecasting,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 39 135–39 153. [Online]. Available: https://proceedi...
2024
-
[31]
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Y . Zhou, Y . Luo, M. Cheng, Q. Liu, J. Wang, D. Wang, and E. Chen, “Time series forecasting as reasoning: A slow-thinking approach with reinforced LLMs,”arXiv preprint arXiv:2506.10630, 2025. [Online]. Available: https://arxiv.org/abs/2506.10630
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Revisiting catastrophic forgetting in large language model tuning,
H. Li, L. Ding, M. Fang, and D. Tao, “Revisiting catastrophic forgetting in large language model tuning,” inFindings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, 11 2024, pp. 4297–4308. [Online]. Available: https://aclanthology.org/2024.findings-emnlp.249/
2024
-
[33]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[34]
AnomaMind: Agentic time series anomaly detection with tool-augmented reasoning,
X. Tao, Y . Wu, M. Cheng, Z. Guo, and T. Gao, “AnomaMind: Agentic time series anomaly detection with tool-augmented reasoning,” arXiv preprint arXiv:2602.13807, 2026. [Online]. Available: https: //arxiv.org/abs/2602.13807
-
[35]
Improving time series forecasting via instance-aware post-hoc revision,
Z. Liu, M. Cheng, G. Zhao, J. Yang, Q. Liu, and E. Chen, “Improving time series forecasting via instance-aware post-hoc revision,”arXiv preprint arXiv:2505.23583, 2025. [Online]. Available: https://arxiv.org/abs/2505.23583
-
[36]
X. Zhang, T. Gao, M. Cheng, B. Pan, Z. Guo, Y . Liu, and X. Tao, “AlphaCast: A human wisdom-LLM intelligence co-reasoning framework for interactive time series forecasting,”arXiv preprint arXiv:2511.08947, 2025. [Online]. Available: https://arxiv.org/abs/2511. 08947
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Cast- R1: Learning tool-augmented sequential decision policies for time series forecasting,
X. Tao, M. Cheng, C. Jiang, T. Gao, H. Zhang, and Y . Liu, “Cast- R1: Learning tool-augmented sequential decision policies for time series forecasting,”arXiv preprint arXiv:2602.13802, 2026. [Online]. Available: https://arxiv.org/abs/2602.13802
-
[38]
Time-Series Representation Learning via Temporal and Contextual Contrasting
E. Eldele, M. Ragab, Z. Chen, M. Wu, C. K. Kwoh, X. Li, and C. Guan, “Time-series representation learning via temporal and contextual contrasting,” inProceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, 2021, pp. 2352–2359, main Track. [Online]. Ava...
-
[39]
HyperIMTS: Hypergraph neural network for irregular multivariate time series forecasting,
B. Li, Y . Luo, Z. Liu, J. Zheng, J. Lv, and Q. Ma, “HyperIMTS: Hypergraph neural network for irregular multivariate time series forecasting,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 35 502–35 518. [Online]. Available: https://proceedings.mlr.press/v26...
2025
-
[40]
TimeBase: The power of minimalism in efficient long-term time series forecasting,
Q. Huang, Z. Zhou, K. Yang, Z. Yi, X. Wang, and Y . Wang, “TimeBase: The power of minimalism in efficient long-term time series forecasting,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 26 227–26 246. [Online]. Available: https://proceedings.mlr.press/v267...
2025
-
[41]
TSLANet: Rethinking transformers for time series representation learning,
E. Eldele, M. Ragab, Z. Chen, M. Wu, and X. Li, “TSLANet: Rethinking transformers for time series representation learning,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
-
[42]
12 409–12 428
PMLR, 2024, pp. 12 409–12 428. [Online]. Available: https: //proceedings.mlr.press/v235/eldele24a.html
2024
-
[43]
A closer look at transformers for time series forecasting: Understanding why they work and where they struggle,
Y . Chen, N. C ´espedes, and P. Barnaghi, “A closer look at transformers for time series forecasting: Understanding why they work and where they struggle,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 7763–7780. [Online]. Available: https://proceedings.mlr....
2025
-
[44]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,” inProceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 2022, pp. 27 268–27 286. [Online]. Available: https://proceedings.mlr.press/v162...
2022
-
[45]
TimeMachine: A time series is worth 4 mambas for long-term forecasting,
M. A. Ahamed and Q. Cheng, “TimeMachine: A time series is worth 4 mambas for long-term forecasting,” inECAI 2024: 27th European Conference on Artificial Intelligence, Including 13th Conference on Prestigious Applications of Intelligent Systems, PAIS 2024, Proceedings, ser. Frontiers in Artificial Intelligence and Applications, vol. 392. IOS Press, 2024, p...
2024
-
[46]
N-HiTS: Neural hierarchical interpolation for time IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 17 series forecasting,
C. Challu, K. G. Olivares, B. N. Oreshkin, F. Garza, M. M. Canseco, and A. Dubrawski, “N-HiTS: Neural hierarchical interpolation for time IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 17 series forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 6, 2023, pp. 6989–6997
2023
-
[47]
ETSformer: Exponential smoothing transformers for time-series forecasting,
G. Woo, C. Liu, D. Sahoo, A. Kumar, and S. Hoi, “ETSformer: Exponential smoothing transformers for time-series forecasting,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=5m 3whfo483
2023
-
[48]
iTransformer: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “iTransformer: Inverted transformers are effective for time series forecasting,” inInternational Conference on Learning Representations,
-
[49]
Available: https://openreview.net/forum?id=JePfAI8fah
[Online]. Available: https://openreview.net/forum?id=JePfAI8fah
-
[50]
ConvTimeNet: A deep hierarchical fully convolutional model for multivariate time series analysis,
M. Cheng, J. Yang, T. Pan, Q. Liu, Z. Li, and S. Wang, “ConvTimeNet: A deep hierarchical fully convolutional model for multivariate time series analysis,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 171–180
2025
-
[51]
A unifying perspective on model reuse: From small to large pre-trained models,
D.-W. Zhou and H.-J. Ye, “A unifying perspective on model reuse: From small to large pre-trained models,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25, J. Kwok, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2025, pp. 10 826–10 835, survey Track. [Online]. Available:...
-
[52]
Model spider: Learning to rank pre-trained models efficiently,
Y .-K. Zhang, T.-J. Huang, Y .-X. Ding, D.-C. Zhan, and H.-J. Ye, “Model spider: Learning to rank pre-trained models efficiently,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 13 692–13 719. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/hash/ 2c71b14637802ed08eaa3cf50342b2b9-Abstract-Conference.html
2023
-
[53]
One-embedding-fits-all: Efficient zero-shot time series forecasting by a model zoo,
H.-N. Shi, T.-J. Huang, L. Han, D.-C. Zhan, and H.-J. Ye, “One-embedding-fits-all: Efficient zero-shot time series forecasting by a model zoo,”arXiv preprint arXiv:2509.04208, 2025. [Online]. Available: https://arxiv.org/abs/2509.04208
-
[54]
X. Tao, S. Zhang, M. Cheng, D. Wang, T. Pan, B. Pan, C. Zhang, and S. Wang, “From values to tokens: An LLM-driven framework for context-aware time series forecasting via symbolic discretization,”arXiv preprint arXiv:2508.09191, 2025. [Online]. Available: https://arxiv.org/abs/2508.09191
-
[55]
Large language models are zero-shot time series forecasters,
N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large language models are zero-shot time series forecasters,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 19 622–19 635
2023
-
[56]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 68 539–68 551
2023
-
[57]
Describe, explain, plan and select: Interactive planning with LLMs enables open-world multi-task agents,
Z. Wang, S. Cai, G. Chen, A. Liu, X. Ma, and Y . Liang, “Describe, explain, plan and select: Interactive planning with LLMs enables open-world multi-task agents,” inAdvances in Neural Information Processing Systems, vol. 36, 2023. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/hash/ 6b8dfb8c0c12e6fafc6c256cb08a5ca7-Abstract-Con...
2023
-
[58]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Infor- mation Processing Systems, vol. 36, 2023, pp. 46 534–46 594
2023
-
[59]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 8634–8652
2023
-
[60]
STaR: Bootstrapping rea- soning with reasoning,
E. Zelikman, Y . Wu, J. Mu, and N. Goodman, “STaR: Bootstrapping rea- soning with reasoning,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 15 476–15 488
2022
-
[61]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liuet al., “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,”Nature, vol. 645, no. 8081, pp. 633– 638, 2025
2025
-
[62]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[63]
X. Zhang, R. R. Chowdhury, R. K. Gupta, and J. Shang, “Large language models for time series: A survey,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, K. Larson, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2024, pp. 8335–8343, survey Track. [Online]. Available: htt...
-
[64]
TimeOmni-1: Incentivizing complex reasoning with time series in large language models,
T. Guan, Z. Meng, D. Li, S. Wang, C.-H. H. Yang, Q. Wen, Z. Liu, S. M. Siniscalchi, M. Jin, and S. Pan, “TimeOmni-1: Incentivizing complex reasoning with time series in large language models,” in International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=kOIclg7muL
2026
-
[65]
AlphaAgentEvo: Evolution-oriented alpha mining via self-evolving agentic reinforcement learning,
Z. Tang, X. Yin, W. Chen, Z. Chen, Y . Zheng, W. Ye, K. Wang, and L. Lin, “AlphaAgentEvo: Evolution-oriented alpha mining via self-evolving agentic reinforcement learning,” inInternational Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=lNmZrawUMu
2026
-
[66]
Empowering time series analysis with large language models: A survey,
Y . Jiang, Z. Pan, X. Zhang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song, “Empowering time series analysis with large language models: A survey,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24. International Joint Conferences on Artificial Intelligence Organization, Aug. 2024, pp. 8095–8103, sur...
-
[67]
TimeXer: Empowering transformers for time series fore- casting with exogenous variables,
Y . Wang, H. Wu, J. Dong, G. Qin, H. Zhang, Y . Liu, Y . Qiu, J. Wang, and M. Long, “TimeXer: Empowering transformers for time series fore- casting with exogenous variables,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 469–498
2024
-
[68]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 11 106–11 115
2021
-
[69]
Forecasting at scale,
S. J. Taylor and B. Letham, “Forecasting at scale,”The American Statistician, vol. 72, no. 1, pp. 37–45, 2018
2018
-
[70]
Grok 4 Model Card,
xAI, “Grok 4 Model Card,” xAI, Model Card, aug 2025. [Online]. Available: https://data.x.ai/2025-08-20-grok-4-model-card.pdf
2025
-
[71]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of-the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Met...
2020
-
[72]
Agent lightning: Train any ai agents with reinforcement learning,
X. Luo, Y . Zhang, Z. He, Z. Wang, S. Zhao, D. Li, L. K. Qiu, and Y . Yang, “Agent lightning: Train ANY AI agents with reinforcement learning,”arXiv preprint arXiv:2508.03680, 2025. [Online]. Available: https://arxiv.org/abs/2508.03680
-
[73]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024. [Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review arXiv 2024
-
[74]
Reversible instance normalization for accurate time-series forecasting against distribution shift,
T. Kim, J. Kim, Y . Tae, C. Park, J.-H. Choi, and J. Choo, “Reversible instance normalization for accurate time-series forecasting against distribution shift,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/ forum?id=cGDAkQo1C0p Bokai Panis a senior undergraduate student at the University of Scien...
2022
-
[75]
Exponential and polynomial decay for a quasilinear viscoelastic equation,
S. A. Messaoudi and N.-e. Tatar, “Exponential and polynomial decay for a quasilinear viscoelastic equation,” Nonlinear Analysis: Theory, Methods & Applications, vol. 68, no. 4, pp. 785–793, 2008
2008
-
[76]
A tutorial on energy-based learning,
Y. Lecun, S. Chopra, and et al., “A tutorial on energy-based learning,” in Predicting Structured Data. MIT Press, 2006
2006
-
[77]
Adam: a method for stochastic optimiza- tion,
D. P . Kingma and J. Ba, “Adam: a method for stochastic optimiza- tion,” in Proceedings of the 3rd International Conference on Learning Representations, 2015, pp. 1–15
2015
-
[78]
Modeling dynamic missingness of implicit feedback for sequential recommendation,
X. Zheng, M. Wang, and et al., “Modeling dynamic missingness of implicit feedback for sequential recommendation,” IEEE Transac- tions on Knowledge & Data Engineering, no. 34, pp. 405–418, 2022
2022
-
[79]
Sliding window-based frequent pattern mining over data streams,
S. K. Tanbeer, C. F. Ahmed, and et al., “Sliding window-based frequent pattern mining over data streams,” Information Sciences, vol. 179, no. 22, pp. 3843–3865, 2009
2009
-
[80]
Incorporating rna-seq data into the zebrafish ensembl genebuild,
J. E. Collins and et al., “Incorporating rna-seq data into the zebrafish ensembl genebuild,” Genome Research, vol. 22, no. 10, pp. 2067–2078, 2012
2067
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.