Recognition: unknown
Frequency-Aware Semantic Fusion with Gated Injection for AI-generated Image Detection
Pith reviewed 2026-05-07 04:53 UTC · model grok-4.3
The pith
Frequency masking and gated injection into vision foundation models improve generalization in detecting AI-generated images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that applying cross-band masking in the frequency domain reduces reliance on generator-specific shortcuts, while adaptive layer-wise gated injection aligns frequency cues with the hierarchical abstractions of a vision foundation model without creating representation conflicts, and that adding a hyperspherical compactness loss with cosine margin produces compact, separable features; together these yield state-of-the-art detection accuracy and strong generalization on multiple challenging datasets containing images from diverse unseen generators.
What carries the argument
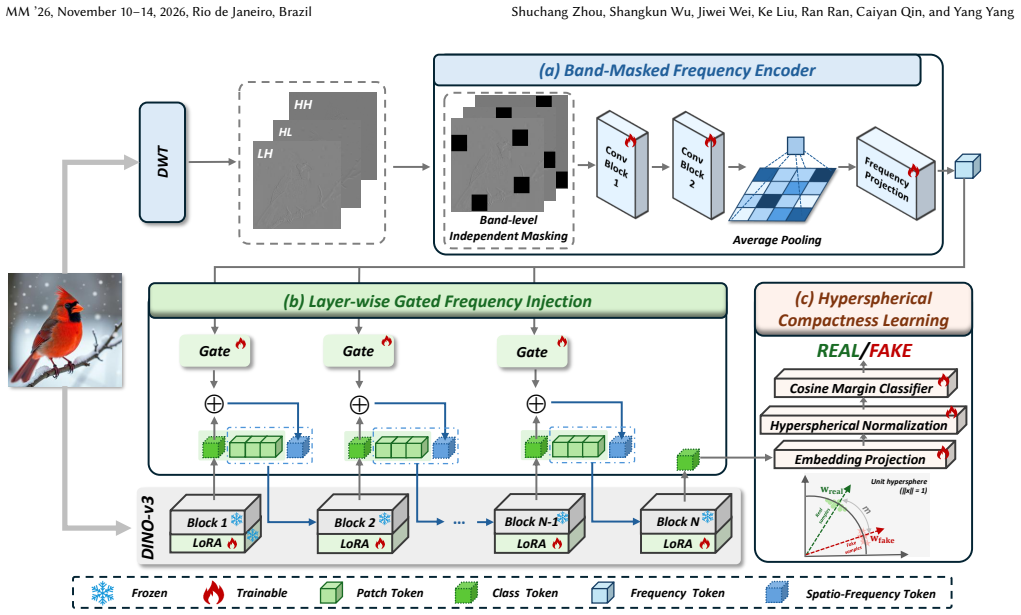
The Band-Masked Frequency Encoder (BMFE) that applies cross-band masking in the frequency domain to encourage generalizable artifact cues, together with the Layer-wise Gated Frequency Injection (LGFI) mechanism that progressively injects those cues into the VFM backbone via adaptive gating to match its abstraction levels.
If this is right
- Detectors built this way maintain performance across images from generative models not encountered in training.
- The masking strategy discourages overfitting to easily detectable but non-general frequency cues associated with specific generators.
- Progressive gated injection at multiple layers reduces the semantic-frequency conflict that arises in simpler fusion methods.
- The compactness objective creates feature spaces where real and generated images form tighter, more separable clusters.
Where Pith is reading between the lines
- The same masking-plus-gating pattern for fusing low-level signal cues with deep semantic backbones could transfer to related tasks such as video deepfake detection or audio authenticity checks.
- Explicit bias-reduction steps like cross-band masking may prove useful in other computer-vision domains where models overfit to dataset-specific artifacts.
- Applying the method to emerging generators such as advanced text-to-video models would offer a direct test of whether the reported generalization holds as synthesis technology evolves.
Load-bearing premise
That cross-band masking will reduce dependence on generator-specific frequency patterns while still retaining useful general artifacts, and that layer-wise gated injection will align frequency information with semantic hierarchies without creating new representation conflicts.
What would settle it
If FGINet shows a clear accuracy drop below strong baselines when tested on a fresh dataset of images produced by an entirely new generative model (such as a previously unreleased diffusion or GAN variant) that was excluded from all training and prior evaluation sets, the generalization improvement would be falsified.
Figures





read the original abstract
AI-generated images are becoming increasingly realistic and diverse, posing significant challenges for generalizable detection. While Vision Foundation Models (VFMs) provide rich semantic representations and frequency-based methods capture complementary artifact cues, existing approaches that combine these modalities still suffer from limited generalization, with notable performance degradation on unseen generative models. We attribute this limitation to two key factors: frequency shortcut bias toward easily distinguishable cues associated with specific generators and cross-domain representation conflict between high-level semantics and low-level frequency patterns. To address these issues, we propose a Frequency-aware Gated Injection Network (FGINet) to improve generalization. Specifically, we design a Band-Masked Frequency Encoder (BMFE) that applies cross-band masking in the frequency domain to reduce reliance on generator-specific patterns and encourage more diverse and generalizable representations. We further introduce a Layer-wise Gated Frequency Injection (LGFI) mechanism to progressively inject frequency cues into the VFM backbone with adaptive gating, aligning with its hierarchical abstraction and alleviating representation conflict. Moreover, we propose a Hyperspherical Compactness Learning (HCL) framework with a cosine margin objective to learn compact and well-separated representations. Extensive experiments demonstrate that FGINet achieves state-of-the-art performance and strong generalization across multiple challenging datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FGINet for AI-generated image detection, which integrates a Band-Masked Frequency Encoder (BMFE) applying cross-band masking in the frequency domain to reduce generator-specific shortcuts, a Layer-wise Gated Frequency Injection (LGFI) mechanism for progressively injecting frequency cues into a Vision Foundation Model (VFM) backbone via adaptive gating to align with hierarchical semantics and reduce representation conflicts, and a Hyperspherical Compactness Learning (HCL) objective using cosine margin loss for compact, separable representations. Extensive experiments are reported to demonstrate state-of-the-art detection accuracy and improved generalization across multiple datasets, including unseen generative models.
Significance. If the mechanisms are validated, the work could meaningfully advance generalizable detection by addressing frequency bias and semantic-frequency conflicts in VFM-based pipelines, a timely contribution given rapid advances in generative models. The paper's strength lies in its empirical scope with multiple datasets and ablations on final accuracy; however, the absence of direct mechanistic probes (e.g., feature-generator mutual information or embedding alignment metrics) limits the significance of the claimed causal contributions over capacity increases or the HCL loss alone.
major comments (3)
- [§3.2] §3.2 (BMFE): The claim that cross-band masking reduces reliance on generator-specific patterns and yields more diverse representations is load-bearing for the generalization argument, yet no supporting measurements are provided such as mutual information between masked frequency features and generator identity, or quantitative diversity metrics (e.g., average pairwise cosine distance across generator classes) comparing masked vs. unmasked features. Ablations report only end-task accuracy improvements.
- [§3.3] §3.3 (LGFI): The assertion that layer-wise gated injection aligns frequency cues with the VFM's hierarchical abstraction and alleviates representation conflicts lacks direct evidence such as layer-wise cosine similarity or t-SNE visualizations of semantic vs. frequency embeddings before/after injection. Without these, performance gains cannot be confidently attributed to conflict reduction rather than added parameters or the HCL objective.
- [§4.3, Table 5] §4.3 and Table 5 (generalization results): The reported SOTA gains on unseen generators are central to the main claim, but the tables lack error bars across random seeds, statistical significance tests (e.g., paired t-tests), or controlled ablations isolating BMFE/LGFI from HCL. This makes it difficult to assess whether the improvements robustly support the generalization narrative.
minor comments (3)
- [Figure 3] Figure 3 (architecture diagram): The gating module visualization could include explicit equations for the adaptive threshold computation to improve reproducibility.
- [§4.1] §4.1 (datasets): Clarify whether the 'unseen' test sets were strictly held out during hyperparameter tuning or if any leakage occurred via validation splits.
- [Eq. (3)] Notation in Eq. (3) for the cosine margin loss: Define the margin hyperparameter explicitly and report its sensitivity analysis in the supplement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the mechanistic evidence supporting our design choices in FGINet. We address each major comment below and commit to incorporating additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] The claim that cross-band masking reduces reliance on generator-specific patterns and yields more diverse representations is load-bearing for the generalization argument, yet no supporting measurements are provided such as mutual information between masked frequency features and generator identity, or quantitative diversity metrics (e.g., average pairwise cosine distance across generator classes) comparing masked vs. unmasked features. Ablations report only end-task accuracy improvements.
Authors: We agree that direct measurements would provide stronger support for the claim that cross-band masking reduces generator-specific shortcuts. Our existing ablations demonstrate that BMFE improves generalization on unseen generators, but these are indirect. In the revised manuscript we will add quantitative diversity metrics, specifically average pairwise cosine distances in the frequency feature space between masked and unmasked variants across generator classes. We will also include mutual-information estimates between the masked frequency features and generator identity labels where computationally feasible. revision: yes
-
Referee: [§3.3] The assertion that layer-wise gated injection aligns frequency cues with the VFM's hierarchical abstraction and alleviates representation conflicts lacks direct evidence such as layer-wise cosine similarity or t-SNE visualizations of semantic vs. frequency embeddings before/after injection. Without these, performance gains cannot be confidently attributed to conflict reduction rather than added parameters or the HCL objective.
Authors: We concur that direct evidence of alignment and conflict reduction would strengthen attribution of LGFI's benefits. The layer-wise gating is motivated by the hierarchical structure of VFMs, and ablations show gains over simpler fusion, yet these do not isolate the alignment effect. In the revision we will report layer-wise cosine similarities between VFM semantic features and injected frequency features before and after gating. We will also add t-SNE visualizations of the embeddings at selected layers to illustrate changes in representation alignment. revision: yes
-
Referee: [§4.3, Table 5] The reported SOTA gains on unseen generators are central to the main claim, but the tables lack error bars across random seeds, statistical significance tests (e.g., paired t-tests), or controlled ablations isolating BMFE/LGFI from HCL. This makes it difficult to assess whether the improvements robustly support the generalization narrative.
Authors: We acknowledge that the absence of error bars, statistical tests, and isolating ablations limits the strength of the generalization claims. The current tables report single-run results. In the revised version we will report mean and standard deviation over at least three random seeds for all key tables. We will add paired t-test p-values for the main comparisons against baselines. We will further include controlled ablations that vary BMFE and LGFI while holding the HCL objective fixed, to separate their contributions from the compactness loss. revision: yes
Circularity Check
No significant circularity; empirical architecture validated on external benchmarks
full rationale
The paper proposes three architectural components (BMFE cross-band masking to diversify frequency features, LGFI adaptive gating to align cues with VFM layers, and HCL cosine-margin compactness) and reports their impact via ablation studies and SOTA results on held-out datasets. No equations, loss terms, or derivations are presented that reduce the generalization claim to a fitted parameter or self-referential definition by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The central claims rest on independent empirical measurements against external generative models rather than internal consistency alone.
Axiom & Free-Parameter Ledger
free parameters (2)
- cosine margin
- gating thresholds or weights
axioms (2)
- domain assumption Vision foundation models provide rich semantic representations suitable as backbone
- domain assumption Frequency-domain patterns contain generator-specific artifacts that can be masked for generalization
invented entities (3)
-
Band-Masked Frequency Encoder (BMFE)
no independent evidence
-
Layer-wise Gated Frequency Injection (LGFI)
no independent evidence
-
Hyperspherical Compactness Learning (HCL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Darius Afchar, Vincent Nozick, Junichi Yamagishi, and Isao Echizen. 2018. MesoNet: a Compact Facial Video Forgery Detection Network. InWIFS. IEEE, 1–7. doi:10.1109/wifs.2018.8630761
- [2]
-
[3]
Andrew Brock, Jeff Donahue, and Karen Simonyan. 2019. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv:1809.11096 [cs.LG] https://arxiv.org/abs/1809.11096
work page internal anchor Pith review arXiv 2019
- [4]
-
[5]
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. 2024. Drct: Diffu- sion reconstruction contrastive training towards universal detection of diffusion generated images. InICML
2024
- [6]
-
[7]
Siyuan Cheng, Lingjuan Lyu, Zhenting Wang, Xiangyu Zhang, and Vikash Se- hwag. 2025. Co-spy: Combining semantic and pixel features to detect synthetic images by ai. InCVPR. 13455–13465
2025
-
[8]
Beilin Chu, Xuan Xu, Xin Wang, Yufei Zhang, Weike You, and Linna Zhou
-
[9]
Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error. InCVPR. 12830–12839
-
[10]
Duc-Tien Dang-Nguyen, Cecilia Pasquini, Valentina Conotter, and Giulia Boato
-
[11]
RAISE: a raw images dataset for digital image forensics.MMSys(2015)
2015
-
[12]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.NeurIPS34 (2021), 8780–8794
2021
-
[13]
Ricard Durall, Margret Keuper, and Janis Keuper. 2020. Watch Your Up- Convolution: CNN Based Generative Deep Neural Networks Are Failing to Re- produce Spectral Distributions. InCVPR. 7887–7896. doi:10.1109/CVPR42600. 2020.00791
-
[14]
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. 2020. Leveraging frequency analysis for deep fake image recognition. InICML. PMLR, 3247–3258
2020
-
[15]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets.NeurIPS27 (2014)
2014
-
[16]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.NeurIPS33 (2020), 6840–6851
2020
-
[17]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[18]
Diederik P Kingma. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review arXiv 2014
-
[19]
Despina Konstantinidou, Christos Koutlis, and Symeon Papadopoulos. 2025. Tex- turecrop: Enhancing synthetic image detection through texture-based cropping. InW ACV. 1459–1468
2025
-
[20]
Christos Koutlis and Symeon Papadopoulos. 2024. Leveraging representa- tions from intermediate encoder-blocks for synthetic image detection. InECCV. Springer, 394–411
2024
-
[21]
Chunxiao Li, Xiaoxiao Wang, Meiling Li, Boming Miao, Peng Sun, Yunjian Zhang, Xiangyang Ji, and Yao Zhu. 2025. Bridging the Gap Between Ideal and Real- world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios. arXiv:2509.09172 [cs.CV] https://arxiv.org/abs/2509.09172
-
[22]
Jun Li, Wentao Jiang, Liyan Shen, and Yawei Ren. 2025. Optimized Frequency Collaborative Strategy Drives AI Image Detection.IEEE Internet of Things Journal (2025)
2025
-
[23]
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Fuli Feng
-
[24]
Improving synthetic image detection towards generalization: An image transformation perspective. InKDD. 2405–2414
-
[25]
Huan Liu, Zichang Tan, Chuangchuang Tan, Yunchao Wei, Jingdong Wang, and Yao Zhao. 2024. Forgery-aware adaptive transformer for generalizable synthetic image detection. InCVPR. 10770–10780
2024
- [26]
-
[27]
Midjourney. 2025. https://www.midjourney.com/home/
2025
-
[28]
Lianrui Mu, Zou Xingze, Jianhong Bai, Jiaqi Hu, Wenjie Zheng, Jiangnan Ye, Jiedong Zhuang, Mudassar Ali, Jing Wang, and Haoji Hu. 2025. No Pixel Left Be- hind: A Detail-Preserving Architecture for Robust High-Resolution AI-Generated Image Detection. arXiv:2508.17346 [cs.CV] https://arxiv.org/abs/2508.17346
-
[29]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. Towards universal fake image detectors that generalize across generative models. InCVPR. 24480–24489
2023
-
[30]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers. InICCV. 4172–4182. doi:10.1109/ICCV51070.2023.00387
-
[31]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv:2307.01952 [cs.CV] https://arxiv.org/abs/2307.01952
work page internal anchor Pith review arXiv 2023
-
[32]
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. Thinking in frequency: Face forgery detection by mining frequency-aware clues. InECCV. Springer, 86–103
2020
-
[33]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InICML. PmLR, 8748–8763
2021
-
[34]
Anirudh Sundara Rajan, Utkarsh Ojha, Jedidiah Schloesser, and Yong Jae Lee
- [35]
-
[36]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[37]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125 [cs.CV] https://arxiv.org/abs/2204.06125
work page internal anchor Pith review arXiv
-
[38]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In CVPR. 10684–10695
2022
-
[39]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al
-
[40]
Imagenet large scale visual recognition challenge.IJCV115, 3 (2015), 211–252
2015
-
[41]
Kuo Shi, Jie Lu, Shanshan Ye, Guangquan Zhang, and Zhen Fang. 2025. Mi- raGe: Multimodal Discriminative Representation Learning for Generalizable AI-Generated Image Detection. InACM MM(Dublin, Ireland)(MM ’25). Asso- ciation for Computing Machinery, New York, NY, USA, 353–361. doi:10.1145/ 3746027.3755142
-
[42]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ra- mamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review arXiv 2025
-
[43]
Chuangchuang Tan, Renshuai Tao, Huan Liu, Guanghua Gu, Baoyuan Wu, Yao Zhao, and Yunchao Wei. 2025. C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection. InAAAI, Vol. 39. 7184–7192
2025
-
[44]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection. InCVPR. 28130–28139
2024
-
[45]
Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. 2018. CosFace: Large Margin Cosine Loss for Deep Face Recognition. InCVPR. 5265–5274. doi:10.1109/CVPR.2018.00552
-
[46]
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. 2023. Dire for diffusion-generated image detection. In ICCV. 22445–22455
2023
-
[47]
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. [n. d.]. A Sanity Check for AI-generated Image Detection. InICLR
-
[48]
Zheng Yang, Ruoxin Chen, Zhiyuan Yan, Ke-Yue Zhang, Xinghe Fu, Shuang Wu, Xiujun Shu, Taiping Yao, Shouhong Ding, Zequn Qin, and Xi Li. 2026. All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning. arXiv:2504.01396 [cs.CV] https://arxiv.org/abs/2504.01396
-
[49]
Haifeng Zhang, Qinghui He, Xiuli Bi, Weisheng Li, Bo Liu, and Bin Xiao. 2025. Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network. InCVPR. 23828–23837
2025
- [50]
-
[51]
Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, and Rongrong Ji. 2025. Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models. InICCV. 18746–18758
2025
-
[52]
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. 2023. Genimage: A million-scale benchmark for detecting ai-generated image.NeurIPS36 (2023), 77771–77782
2023
-
[53]
Wanyi Zhuang, Qi Chu, Tao Gong, Changtao Miao, and Nenghai Yu. 2025. To- wards Good Generalizations for Diffusion Generated Image Detection Using Multiple Reconstruction Contrastive Learning. InACM MM(Dublin, Ireland) (MM ’25). Association for Computing Machinery, New York, NY, USA, 5431–5440. doi:10.1145/3746027.3754567
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.