Recognition: unknown
HiMix: Hierarchical Artifact-aware Mixup for Generalized Synthetic Image Detection
Pith reviewed 2026-05-07 07:13 UTC · model grok-4.3
The pith
Pixel-wise mixup and hierarchical artifact fusion expand training coverage to let synthetic image detectors generalize to unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
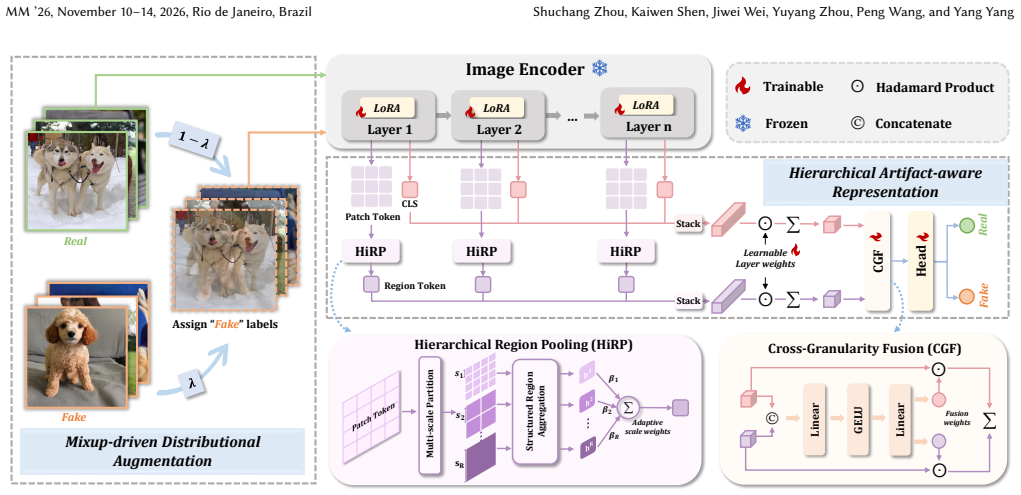
HiMix constructs transitional samples via pixel-wise mixup in the MDA module to improve coverage of the data distribution and sensitivity to low-level forgery cues, while the HAR module aggregates artifact information from global and local levels through cross-layer integration and coarse-to-fine feature fusion, enabling extraction of discriminative representations that generalize across diverse distributions.
What carries the argument
The HiMix framework, which combines Mixup-driven Distributional Augmentation (MDA) using pixel-wise mixup between real and fake images with Hierarchical Artifact-aware Representation (HAR) via cross-layer global-local fusion.
If this is right
- Models trained with transitional mixed samples will exhibit improved sensitivity to low-level artifacts that persist across different generators.
- Cross-layer fusion of global and local features will produce more robust representations that maintain performance on novel forgery distributions.
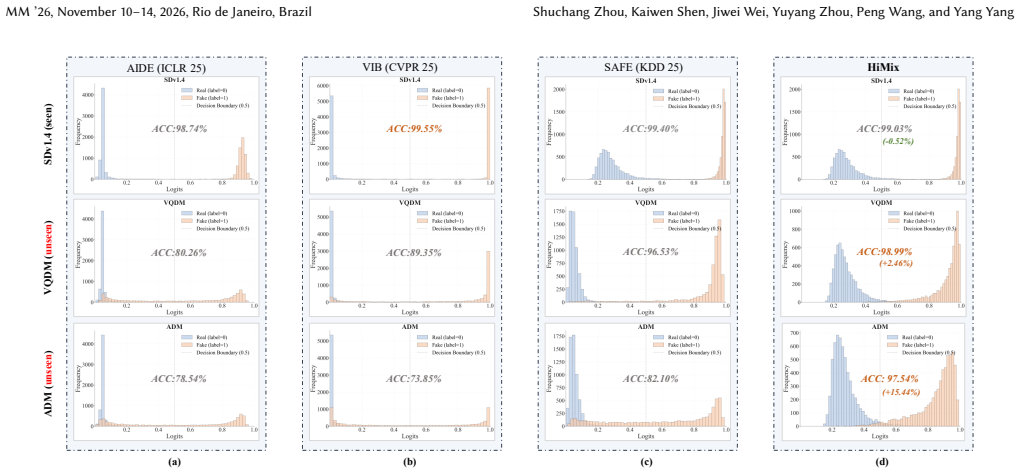
- Logit separation between real and synthetic classes will increase on benchmarks containing unseen generators.
- Overall detection performance will reach state-of-the-art levels across multiple existing SID benchmarks.
Where Pith is reading between the lines
- The same transitional-sample idea could be applied to video or audio forgery detection where low-level cues also transfer across generators.
- Training data requirements might decrease because the mixup process effectively enlarges the space of hard examples without collecting new real-fake pairs.
- The method could be combined with other augmentation strategies to further reduce reliance on any single training distribution.
- Testing on completely out-of-distribution generators produced after the paper's benchmarks would directly measure whether the low-level cue focus holds.
Load-bearing premise
That continuous transitional samples from pixel-wise mixup combined with cross-layer artifact fusion will reliably encode generalizable low-level forgery cues rather than dataset-specific patterns.
What would settle it
A new test set of images from a generator never used in training or mixing, where the HiMix model shows no gain in logit separation or accuracy over a baseline trained without MDA and HAR.
Figures



read the original abstract
The rapid evolution of generative models has enabled the creation of highly realistic and diverse synthetic images, posing significant challenges to reliable and generalizable Synthetic Image Detection (SID). However, existing detectors are typically trained on limited and biased datasets, resulting in poor generalization to unseen generators. To address this issue, we propose HiMix, a unified framework that enhances generalization by expanding the training distribution and promoting artifact-aware representations. Specifically, the Mixup-driven Distributional Augmentation (MDA) module constructs continuous transitional samples between real and fake images, improving coverage of low-confidence regions and exposing the model to more challenging samples, while the pixel-wise mixup operation smoothly perturbs semantics to enhance sensitivity to low-level artifacts. Moreover, the Hierarchical Artifact-aware Representation (HAR) module aggregates artifact information from both global and local levels through cross-layer integration and coarse-to-fine feature fusion, enabling the extraction of discriminative forgery representations under diverse distributions. Extensive experiments across multiple benchmarks demonstrate that HiMix achieves state-of-the-art performance, establishing well-separated logits for improved generalization to unseen forgeries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HiMix, a unified framework for generalized synthetic image detection (SID). It consists of two main modules: Mixup-driven Distributional Augmentation (MDA), which generates continuous transitional samples via pixel-wise mixup between real and fake images to improve coverage of low-confidence regions and enhance sensitivity to low-level artifacts, and Hierarchical Artifact-aware Representation (HAR), which performs cross-layer integration and coarse-to-fine feature fusion to extract discriminative forgery cues at global and local levels. The central claim, supported by extensive experiments on multiple benchmarks, is that HiMix achieves state-of-the-art performance with well-separated logits, leading to improved generalization to unseen generators.
Significance. If the experimental claims hold under rigorous validation, this would represent a meaningful engineering contribution to the important and timely problem of robust SID amid rapidly evolving generative models. The combination of distributional augmentation via mixup and hierarchical artifact fusion offers a practical way to expand training coverage and promote artifact-aware features, potentially aiding real-world deployment where novel forgeries appear frequently. Strengths include the empirical focus on logit separation and the attempt to address generalization explicitly, though the work remains an incremental advance rather than a theoretical breakthrough.
major comments (3)
- [§4] §4 (Experiments) and abstract: The SOTA and generalization claims rest on experimental outcomes, yet the manuscript provides insufficient quantitative details such as per-benchmark accuracy/AUC scores with error bars, ablation tables isolating MDA vs. HAR contributions, or explicit criteria for selecting 'unseen' generators (e.g., architectural differences, training data overlap). This makes it impossible to verify the magnitude of improvement or rule out post-hoc benchmark selection, directly undermining the central generalization assertion.
- [§3.1] §3.1 (MDA module): The pixel-wise mixup operation is linear in pixel space and draws pairs exclusively from the same limited training generators; the paper does not demonstrate (via cross-generator mixup ablations or frequency-domain analysis) that the resulting transitional samples encode universal low-level cues rather than generator-specific statistics (e.g., upsampling artifacts or noise patterns). This is load-bearing for the claim that MDA reliably improves generalization to truly novel forgeries.
- [§3.2] §3.2 (HAR module) and §4.2 (Ablations): The cross-layer artifact fusion is presented as enabling discriminative representations, but no ablation quantifies the incremental benefit of hierarchical (global+local, coarse-to-fine) integration over simpler single-layer or non-hierarchical baselines. Without these controls, it remains unclear whether the added complexity is necessary or if performance gains derive primarily from MDA or standard training tricks.
minor comments (3)
- [§3] Notation for mixup ratio λ and layer indices in §3 is introduced without a clear summary table or consistent symbols across equations and figures, complicating reproducibility.
- [Figures] Figure captions (e.g., those showing logit distributions) should explicitly state the generators used for each curve and whether they are in-distribution or unseen.
- [§2] The related-work section omits several recent mixup-based augmentation papers in forgery detection; adding 2-3 targeted citations would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the experimental rigor and analysis of HiMix. We address each major comment point by point below and will revise the manuscript to incorporate additional quantitative details, ablations, and analyses as outlined.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and abstract: The SOTA and generalization claims rest on experimental outcomes, yet the manuscript provides insufficient quantitative details such as per-benchmark accuracy/AUC scores with error bars, ablation tables isolating MDA vs. HAR contributions, or explicit criteria for selecting 'unseen' generators (e.g., architectural differences, training data overlap). This makes it impossible to verify the magnitude of improvement or rule out post-hoc benchmark selection, directly undermining the central generalization assertion.
Authors: We appreciate this observation on the need for enhanced reporting. Section 4 of the manuscript already includes per-benchmark accuracy and AUC results across multiple datasets to support the SOTA and generalization claims. However, we acknowledge the absence of error bars from repeated runs and the lack of an explicit ablation table isolating MDA versus HAR. We also agree that the criteria for selecting unseen generators should be stated more clearly. In the revised manuscript, we will add standard deviations computed over multiple random seeds for all reported metrics, expand §4.2 with a dedicated table isolating the individual and combined contributions of MDA and HAR, and include a new subsection detailing the unseen generator selection process (e.g., distinct architectures such as GAN-based versus diffusion-based models, with explicit confirmation of no training-data overlap). These changes will allow readers to better assess the magnitude and reliability of the improvements. revision: yes
-
Referee: [§3.1] §3.1 (MDA module): The pixel-wise mixup operation is linear in pixel space and draws pairs exclusively from the same limited training generators; the paper does not demonstrate (via cross-generator mixup ablations or frequency-domain analysis) that the resulting transitional samples encode universal low-level cues rather than generator-specific statistics (e.g., upsampling artifacts or noise patterns). This is load-bearing for the claim that MDA reliably improves generalization to truly novel forgeries.
Authors: We agree that further evidence would strengthen the claim that MDA promotes universal low-level artifact sensitivity. The design of MDA uses pixel-wise mixup to densely sample the real-to-fake continuum within the training distribution, with the goal of forcing the detector to rely on low-level inconsistencies rather than high-level semantics. The strong performance on truly unseen generators in our experiments provides empirical support for this effect. To directly address the concern, the revised version will include new cross-generator mixup ablations (pairing real images with fakes from held-out generators) and frequency-domain analysis (e.g., FFT power spectra of the mixed samples versus originals) to demonstrate that the transitional samples highlight artifacts that generalize beyond generator-specific patterns such as upsampling traces. revision: yes
-
Referee: [§3.2] §3.2 (HAR module) and §4.2 (Ablations): The cross-layer artifact fusion is presented as enabling discriminative representations, but no ablation quantifies the incremental benefit of hierarchical (global+local, coarse-to-fine) integration over simpler single-layer or non-hierarchical baselines. Without these controls, it remains unclear whether the added complexity is necessary or if performance gains derive primarily from MDA or standard training tricks.
Authors: Thank you for this important point regarding the necessity of the hierarchical design. The HAR module performs cross-layer integration to fuse global context with local artifact details in a coarse-to-fine manner, which we argue is key to capturing forgery cues under diverse distributions. While §4.2 contains component-wise ablations, we recognize that direct comparisons against simpler single-layer or non-hierarchical fusion baselines are not present. In the revision, we will add targeted ablation experiments in §4.2 that compare the full hierarchical HAR against (i) single-layer feature extraction and (ii) non-hierarchical fusion variants, while keeping MDA fixed. These results will quantify the incremental benefit and clarify that the observed gains are not solely due to MDA or other training factors. revision: yes
Circularity Check
No circularity: empirical augmentation framework validated by external benchmarks
full rationale
The paper presents HiMix as an engineering contribution consisting of MDA (pixel-wise mixup between real/fake pairs) and HAR (cross-layer artifact fusion). No equations, fitted parameters, or derivations appear in the provided text. Central claims rest on experimental outcomes across multiple benchmarks rather than any quantity defined by the method's own outputs. No self-citations are invoked as load-bearing uniqueness theorems, and no predictions reduce to inputs by construction. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mixup between real and fake images produces transitional samples that improve coverage of low-confidence regions and expose the model to challenging forgery cues
- domain assumption Cross-layer integration and coarse-to-fine fusion of global and local features yields discriminative forgery representations that generalize across distributions
Reference graph
Works this paper leans on
-
[1]
Noémi Bontridder and Yves Poullet. 2021. The role of artificial intelligence in disinformation.Data & Policy3 (2021), e32
2021
-
[2]
George Cazenavette, Avneesh Sud, Thomas Leung, and Ben Usman. 2024. Fakein- version: Learning to detect images from unseen text-to-image models by inverting stable diffusion. InCVPR. 10759–10769
2024
-
[3]
Yingjian Chen, Lei Zhang, and Yakun Niu. 2025. ForgeLens: Data-Efficient Forgery Focus for Generalizable Forgery Image Detection. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16270–16280
2025
-
[4]
Beilin Chu, Xuan Xu, Xin Wang, Yufei Zhang, Weike You, and Linna Zhou
-
[5]
Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error. InCVPR. 12830–12839
-
[6]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.NeurIPS34 (2021), 8780–8794
2021
-
[7]
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. 2020. Leveraging frequency analysis for deep fake image recognition. InICML. PMLR, 3247–3258
2020
-
[8]
Abenezer Golda, Kidus Mekonen, Amit Pandey, Anushka Singh, Vikas Hassija, Vinay Chamola, and Biplab Sikdar. 2024. Privacy and security concerns in generative AI: a comprehensive survey.IEEE Access12 (2024), 48126–48144
2024
-
[9]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets.NeurIPS27 (2014)
2014
-
[10]
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. 2022. Vector quantized diffusion model for text-to-image synthesis. InCVPR. 10696–10706
2022
-
[11]
Seoyeon Gye, Junwon Ko, Hyounguk Shon, Minchan Kwon, and Junmo Kim
- [12]
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.NeurIPS33 (2020), 6840–6851
2020
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[15]
Zexi Jia, Chuanwei Huang, Yeshuang Zhu, Hongyan Fei, Xiaoyue Duan, Zhiqiang Yuan, Ying Deng, Jiapei Zhang, Jinchao Zhang, and Jie Zhou. 2025. Secret Lies in Color: Enhancing AI-Generated Images Detection with Color Distribution Analysis. InCVPR. 13445–13454
2025
-
[16]
Yan Ju, Shan Jia, Lipeng Ke, Hongfei Xue, Koki Nagano, and Siwei Lyu. 2022. Fusing global and local features for generalized ai-synthesized image detection. InICIP. IEEE, 3465–3469
2022
-
[17]
Dimitrios Karageorgiou, Symeon Papadopoulos, Ioannis Kompatsiaris, and Efs- tratios Gavves. 2025. Any-resolution ai-generated image detection by spectral learning. InCVPR. 18706–18717
2025
-
[18]
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196(2017)
work page internal anchor Pith review arXiv 2017
-
[19]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In CVPR. 8110–8119
2020
-
[20]
Hossein Kashiani, Niloufar Alipour Talemi, and Fatemeh Afghah. 2025. Freqde- bias: Towards generalizable deepfake detection via consistency-driven frequency debiasing. InCVPR. IEEE, 8775–8785
2025
-
[21]
Mamadou Keita, Wassim Hamidouche, Hessen Bougueffa Eutamene, Abdelmalik Taleb-Ahmed, David Camacho, and Abdenour Hadid. 2025. Bi-LORA: A Vision- Language Approach for Synthetic Image Detection.Expert Systems42, 2 (2025), e13829
2025
-
[22]
Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. 2022. Diffusionclip: Text- guided diffusion models for robust image manipulation. InCVPR. 2426–2435
2022
-
[23]
Diederik P Kingma. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review arXiv 2014
-
[24]
Jun Li, Wentao Jiang, Liyan Shen, and Yawei Ren. 2025. Optimized Frequency Collaborative Strategy Drives AI Image Detection.IEEE Internet of Things Journal (2025)
2025
-
[25]
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Fuli Feng
-
[26]
Improving synthetic image detection towards generalization: An image transformation perspective. InKDD. 2405–2414
-
[27]
Ziyou Liang, Weifeng Liu, Run Wang, Mengjie Wu, Boheng Li, Yuyang Zhang, Lina Wang, and Xinyi Yang. 2025. Transfer Learning of Real Image Features with Soft Contrastive Loss for Fake Image Detection. InAAAI, Vol. 39. 26281–26289
2025
-
[28]
Huan Liu, Zichang Tan, Chuangchuang Tan, Yunchao Wei, Jingdong Wang, and Yao Zhao. 2024. Forgery-aware adaptive transformer for generalizable synthetic image detection. InCVPR. 10770–10780
2024
-
[29]
Zhengzhe Liu, Xiaojuan Qi, and Philip HS Torr. 2020. Global texture enhancement for fake face detection in the wild. InCVPR. 8060–8069
2020
-
[30]
Changtao Miao, Zichang Tan, Qi Chu, Huan Liu, Honggang Hu, and Nenghai Yu. 2023. F 2 trans: High-frequency fine-grained transformer for face forgery detection.IFS18 (2023), 1039–1051
2023
-
[31]
Tai D Nguyen, Aref Azizpour, and Matthew C Stamm. 2025. Forensic self- descriptions are all you need for zero-shot detection, open-set source attribution, and clustering of ai-generated images. InCVPR. 3040–3050
2025
-
[32]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. Towards universal fake image detectors that generalize across generative models. InCVPR. 24480–24489
2023
-
[33]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.NeurIPS 32 (2019)
2019
-
[34]
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. Thinking in frequency: Face forgery detection by mining frequency-aware clues. InECCV. Springer, 86–103
2020
-
[35]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[36]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In CVPR. 10684–10695
2022
-
[37]
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. InICCV. 1–11
2019
-
[38]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al
-
[39]
Imagenet large scale visual recognition challenge.IJCV115, 3 (2015), 211–252
2015
-
[40]
Chuangchuang Tan, Renshuai Tao, Huan Liu, Guanghua Gu, Baoyuan Wu, Yao Zhao, and Yunchao Wei. 2025. C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection. InAAAI, Vol. 39. 7184–7192
2025
-
[41]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Frequency-aware deepfake detection: Improving generalizability MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Shuchang Zhou, Kaiwen Shen, Jiwei Wei, Yuyang Zhou, Peng Wang, and Yang Yang through frequency space domain learning. InAAAI, Vol. 38. 5052–5060
2024
-
[42]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection. InCVPR. 28130–28139
2024
-
[43]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, and Yunchao Wei. 2023. Learning on gradients: Generalized artifacts representation for gan-generated images detection. InCVPR. 12105–12114
2023
-
[44]
Ruben Tolosana, Ruben Vera-Rodriguez, Julian Fierrez, Aythami Morales, and Javier Ortega-Garcia. 2020. Deepfakes and beyond: A survey of face manipulation and fake detection.Information Fusion64 (2020), 131–148
2020
-
[45]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. 2020. CNN-generated images are surprisingly easy to spot... for now. In CVPR. 8695–8704
2020
-
[46]
Jiwei Wei, Yang Yang, Xiang Guan, Xing Xu, Guoqing Wang, and Heng Tao Shen
-
[47]
Runge-kutta guided feature augmentation for few-sample learning.IEEE Transactions on Multimedia(2024)
2024
-
[48]
Jiwei Wei, Yang Yang, Xing Xu, Xiaofeng Zhu, and Heng Tao Shen. 2021. Universal weighting metric learning for cross-modal retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 10 (2021), 6534–6545
2021
-
[49]
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. [n. d.]. A Sanity Check for AI-generated Image Detection. InICLR
-
[50]
Yongqi Yang, Zhihao Qian, Ye Zhu, Olga Russakovsky, and Yu Wu. 2025. Dˆ 3: Scaling Up Deepfake Detection by Learning from Discrepancy. InCVPR. 23850– 23859
2025
-
[51]
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. 2015. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365(2015)
work page internal anchor Pith review arXiv 2015
-
[52]
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. 2017. mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412 (2017)
work page internal anchor Pith review arXiv 2017
-
[53]
Haifeng Zhang, Qinghui He, Xiuli Bi, Weisheng Li, Bo Liu, and Bin Xiao. 2025. Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network. InCVPR. 23828–23837
2025
- [54]
-
[55]
Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, and Rongrong Ji. 2025. AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models.arXiv preprint arXiv:2507.02664(2025)
-
[56]
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. 2023. Genimage: A million-scale benchmark for detecting ai-generated image.NeurIPS36 (2023), 77771–77782
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.