Recognition: unknown
Geometry-Calibrated Conformal Abstention for Language Models
Pith reviewed 2026-05-07 05:51 UTC · model grok-4.3
The pith
Conformal Abstention adapts conformal prediction to give language models finite-sample guarantees on when their answers are reliable
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conformal Abstention (CA) is a post hoc framework adapted from conformal prediction (CP) to determine whether to abstain from answering a query. CA provides finite-sample guarantees on both the probability of participation (i.e., not abstaining) and the probability that the generated response is correct. The abstention decision relies on prediction confidence rather than the non-conformity scores used in CP, which are intractable for open-ended generation. To better align prediction confidence with the model's ignorance, we introduce a calibration strategy using representation geometry within the model to measure knowledge involvement in shaping the response. Experiments demonstrate that we
What carries the argument
Geometry-calibrated prediction confidence, which uses the model's internal representation geometry to measure knowledge involvement and thereby enables conformal prediction guarantees for abstention decisions in open-ended generation
If this is right
- Language models can be made to answer only when a user-specified correctness probability is guaranteed by finite-sample bounds
- The method operates post hoc and requires no retraining or access to scarce ignorance benchmarks
- Abstention becomes practical for open-ended generation tasks where traditional non-conformity scores cannot be computed
- Selective answering reaches high conditional correctness, reported at 75 percent in the experiments
- The approach avoids the overly conservative behavior that can arise from retraining models to admit ignorance
Where Pith is reading between the lines
- The geometry-based calibration may extend naturally to other generative domains such as code or image synthesis where internal representations also encode task knowledge
- If the alignment between geometry and ignorance proves stable across model scales, the method could serve as a lightweight uncertainty signal for very large foundation models
- Combining the abstention rule with retrieval-augmented generation might tighten the effective guarantees by reducing the incidence of knowledge gaps
- A direct test would be to measure whether the geometry signal improves abstention decisions on domain-specific queries known to lie outside the model's training distribution
Load-bearing premise
Calibrating prediction confidence via representation geometry successfully aligns those scores with the model's true ignorance, allowing finite-sample conformal guarantees to transfer when confidence is used in place of non-conformity scores
What would settle it
An experiment on a held-out set in which the observed correctness rate among answered queries falls below the target level guaranteed by the conformal procedure after geometry calibration would falsify the central transfer claim
Figures









read the original abstract
When language models lack relevant knowledge for a given query, they frequently generate plausible responses that can be hallucinations, rather than admitting being agnostic about the answer. Retraining models to reward admitting ignorance can lead to overly conservative behaviors and poor generalization due to scarce evaluation benchmarks. We propose a post hoc framework, Conformal Abstention (CA), adapted from conformal prediction (CP) to determine whether to abstain from answering a query. CA provides finite-sample guarantees on both the probability of participation (i.e., not abstaining) and the probability that the generated response is correct. Importantly, the abstention decision relies on prediction confidence rather than the non-conformity scores used in CP, which are intractable for open-ended generation. To better align prediction confidence with the model's ignorance, we introduce a calibration strategy using representation geometry within the model to measure knowledge involvement in shaping the response. Experiments demonstrate that we improve selective answering significantly with 75 percent conditional correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Conformal Abstention (CA), a post-hoc framework adapted from conformal prediction (CP) for deciding when language models should abstain from answering queries. It claims finite-sample guarantees on both the probability of participation (not abstaining) and the conditional probability that generated responses are correct. The abstention decision uses prediction confidence calibrated via representation geometry (to measure knowledge involvement) rather than intractable non-conformity scores. Experiments are reported to show significant improvement in selective answering, achieving 75% conditional correctness.
Significance. If the finite-sample guarantees survive the substitution of geometry-calibrated confidence for standard non-conformity scores, the work would provide a practical, training-free method for controlling abstention and reducing hallucinations in open-ended generation with theoretical backing. The geometry calibration step is a novel attempt to operationalize model ignorance in representation space and could extend to other selective prediction settings. The emphasis on finite-sample validity and open-ended text addresses a genuine limitation of classical CP, making the contribution potentially significant for reliable deployment of LLMs if the transfer of guarantees is established.
major comments (3)
- [Abstract] Abstract: The central claim asserts finite-sample guarantees on participation rate and conditional correctness when thresholding geometry-calibrated confidence instead of non-conformity scores. No derivation, theorem, or proof sketch is referenced showing that the representation-geometry metric preserves the exchangeability and monotonic ranking (higher score implies greater strangeness/lower correctness) required for marginal coverage to transfer. This is load-bearing for the theoretical contribution.
- [Method] Method (Geometry Calibration section): The geometry calibration is motivated as aligning confidence with ignorance via representation-space distances or involvement metrics. However, no analysis or worst-case argument is given that this metric ranks errors correctly (i.e., incorrect responses receive systematically lower calibrated confidence), which is necessary for the chosen threshold on the calibration set to deliver the advertised coverage guarantee. If monotonicity fails, the finite-sample claim does not hold.
- [Experiments] Experiments: The 75% conditional correctness figure is presented as empirical support for the framework. The manuscript does not specify how response correctness is defined (exact match, entailment, human judgment) or confirm that the calibration set construction maintains exchangeability with test points. These details are required to assess whether the experiments validate the transferred guarantee or only demonstrate heuristic improvement.
minor comments (2)
- [Abstract] Abstract: The distinction between the theoretical finite-sample guarantee and the empirical 75% conditional correctness could be stated more explicitly to avoid conflating the two.
- [Method] Notation: The paper should clarify whether the geometry calibration introduces any additional fitted parameters beyond the standard CP threshold, as this affects the 'parameter-free' flavor of the guarantees.
Simulated Author's Rebuttal
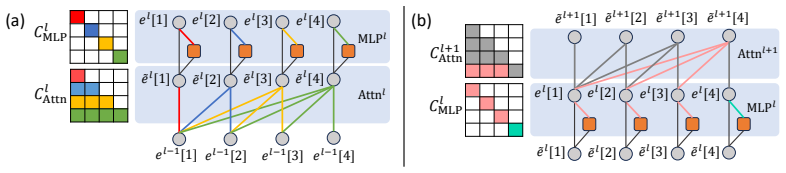
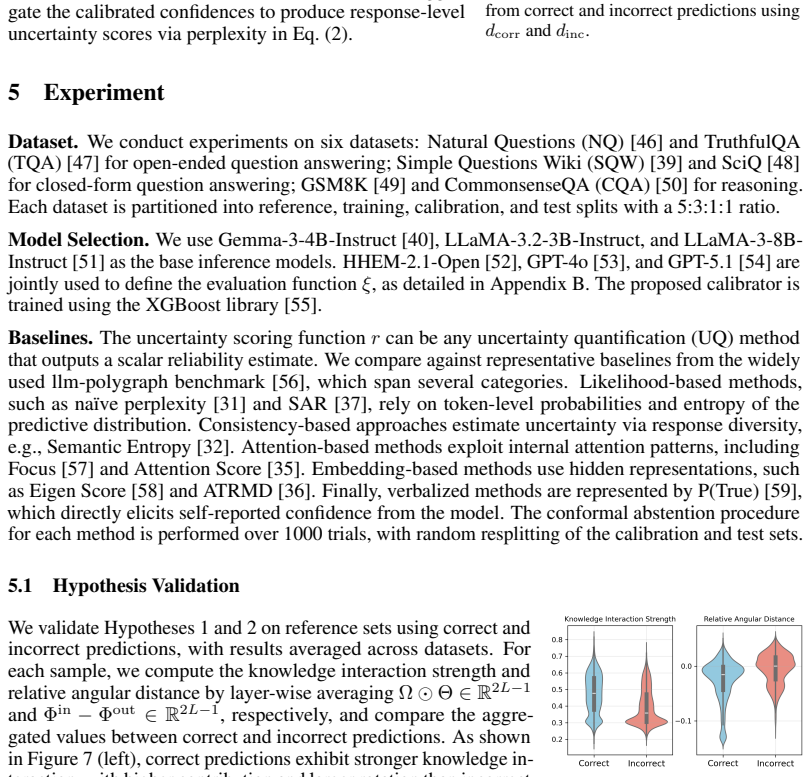
We are grateful to the referee for their insightful comments that identify key areas for improving the clarity of our theoretical claims and experimental setup. We respond to each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim asserts finite-sample guarantees on participation rate and conditional correctness when thresholding geometry-calibrated confidence instead of non-conformity scores. No derivation, theorem, or proof sketch is referenced showing that the representation-geometry metric preserves the exchangeability and monotonic ranking (higher score implies greater strangeness/lower correctness) required for marginal coverage to transfer. This is load-bearing for the theoretical contribution.
Authors: We acknowledge that the abstract does not explicitly reference a theorem or proof sketch. The guarantees derive from the exchangeability of the data points under the i.i.d. assumption, which holds independently of the specific score function as long as it is computed consistently. The geometry calibration is designed to provide a monotonic ranking by measuring knowledge involvement in the representation space, with lower involvement indicating higher likelihood of incorrect responses. To address this, we will include a dedicated theorem with a proof sketch in the revised Method section and update the abstract to reference it. revision: yes
-
Referee: [Method] Method (Geometry Calibration section): The geometry calibration is motivated as aligning confidence with ignorance via representation-space distances or involvement metrics. However, no analysis or worst-case argument is given that this metric ranks errors correctly (i.e., incorrect responses receive systematically lower calibrated confidence), which is necessary for the chosen threshold on the calibration set to deliver the advertised coverage guarantee. If monotonicity fails, the finite-sample claim does not hold.
Authors: The geometry calibration uses distances in representation space to quantify how much the model's internal knowledge is engaged in producing the response. We agree that a formal worst-case analysis of the ranking property would strengthen the theoretical foundation. While we provide empirical support through experiments showing improved selective performance, we will add a discussion in the revised manuscript analyzing the conditions for monotonicity and include additional experiments validating the correlation between the calibrated confidence and response correctness on the calibration set. revision: partial
-
Referee: [Experiments] Experiments: The 75% conditional correctness figure is presented as empirical support for the framework. The manuscript does not specify how response correctness is defined (exact match, entailment, human judgment) or confirm that the calibration set construction maintains exchangeability with test points. These details are required to assess whether the experiments validate the transferred guarantee or only demonstrate heuristic improvement.
Authors: We will revise the Experiments section to explicitly define response correctness as determined by human judgment for open-ended responses, supplemented by automatic metrics where appropriate. The calibration set is randomly held out from the same dataset distribution as the test queries, preserving exchangeability. We will add a statement confirming this and report the exact construction procedure to allow readers to verify the validity of the empirical results. revision: yes
Circularity Check
No significant circularity in derivation of conformal abstention guarantees
full rationale
The paper adapts standard conformal prediction (CP) to language models by replacing intractable non-conformity scores with geometry-calibrated prediction confidence scores for abstention decisions. Finite-sample guarantees on participation rate and conditional correctness are claimed to transfer from CP theory, with a new post-hoc calibration step using representation geometry to measure knowledge involvement and align confidence with ignorance. No load-bearing step reduces the result to its inputs by construction: there are no self-definitional quantities (e.g., a score defined in terms of the coverage it guarantees), no fitted parameters renamed as independent predictions, and no self-citation chains justifying uniqueness or ansatzes. The geometry calibration is presented as an empirical alignment strategy rather than a tautological redefinition. The derivation remains self-contained against external CP benchmarks and standard exchangeability assumptions, with the transfer of ranking properties treated as an assumption rather than derived internally. No quoted equations or text exhibit the specific reductions required for a positive circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- geometry calibration parameters or confidence threshold
axioms (2)
- domain assumption Finite-sample guarantees of conformal prediction continue to hold when abstention is based on prediction confidence rather than non-conformity scores
- ad hoc to paper Representation geometry within the model measures the degree of knowledge involvement in shaping the response
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Chain of thoughtlessness? an analysis of cot in planning.Advances in Neural Information Processing Systems, 37:29106– 29141, 2024
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. Chain of thoughtlessness? an analysis of cot in planning.Advances in Neural Information Processing Systems, 37:29106– 29141, 2024
2024
-
[3]
Yang Zhang, Hanlei Jin, Dan Meng, Jun Wang, and Jinghua Tan. A comprehensive survey on process-oriented automatic text summarization with exploration of llm-based methods.arXiv preprint arXiv:2403.02901, 2024
-
[4]
Determinants of llm-assisted decision-making.arXiv preprint arXiv:2402.17385, 2024
Eva Eigner and Thorsten Händler. Determinants of llm-assisted decision-making.arXiv preprint arXiv:2402.17385, 2024
-
[5]
Towards scientific discovery with generative ai: Progress, opportunities, and challenges
Chandan K Reddy and Parshin Shojaee. Towards scientific discovery with generative ai: Progress, opportunities, and challenges. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 28601–28609, 2025
2025
-
[6]
Ziqi Yang, Xuhai Xu, Bingsheng Yao, Ethan Rogers, Shao Zhang, Stephen Intille, Nawar Shara, Guodong Gordon Gao, and Dakuo Wang. Talk2care: An llm-based voice assistant for communication between healthcare providers and older adults.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(2):1–35, 2024
2024
-
[7]
An llm-driven chatbot in higher education for databases and information systems.IEEE Transactions on Education, 2024
Alexander Tobias Neumann, Yue Yin, Sulayman Sowe, Stefan Decker, and Matthias Jarke. An llm-driven chatbot in higher education for databases and information systems.IEEE Transactions on Education, 2024
2024
-
[8]
Rule based rewards for language model safety, 2024
Tong Mu, Alec Helyar, Johannes Heidecke, Joshua Achiam, Andrea Vallone, Ian Kivlichan, Molly Lin, Alex Beutel, John Schulman, and Lilian Weng. Rule based rewards for language model safety, 2024
2024
-
[9]
Unveiling privacy risks in llm agent memory
Bo Wang, Weiyi He, Shenglai Zeng, Zhen Xiang, Yue Xing, Jiliang Tang, and Pengfei He. Unveiling privacy risks in llm agent memory. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25241–25260, 2025
2025
-
[10]
Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
2025
-
[11]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[12]
Vempala, and Edwin Zhang
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate, 2025
2025
-
[13]
Verifiable accuracy and abstention rewards in curriculum rl to alleviate lost-in- conversation, 2025
Ming Li. Verifiable accuracy and abstention rewards in curriculum rl to alleviate lost-in- conversation, 2025
2025
-
[14]
Wildbench: Benchmarking llms with challenging tasks from real users in the wild, 2024
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking llms with challenging tasks from real users in the wild, 2024
2024
-
[15]
Springer, 2005
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world, volume 29. Springer, 2005
2005
-
[16]
Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024
Margarida Campos, António Farinhas, Chrysoula Zerva, Mário AT Figueiredo, and André FT Martins. Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024. 10
2024
-
[17]
Uncertainty sets for image classifiers using conformal prediction.arXiv:2009.14193,
Anastasios Angelopoulos, Stephen Bates, Jitendra Malik, and Michael I Jordan. Uncertainty sets for image classifiers using conformal prediction.arXiv preprint arXiv:2009.14193, 2020
-
[18]
Inductive confidence machines for regression
Harris Papadopoulos, Kostas Proedrou, V olodya V ovk, and Alex Gammerman. Inductive confidence machines for regression. InMachine learning: ECML 2002: 13th European conference on machine learning Helsinki, Finland, August 19–23, 2002 proceedings 13, pages 345–356. Springer, 2002
2002
-
[19]
Conformal prediction with large language models for multi-choice question answering
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404, 2023
-
[20]
Robots that ask for help: Uncertainty alignment for large language model planners,
Allen Z Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, et al. Robots that ask for help: Uncertainty alignment for large language model planners.arXiv preprint arXiv:2307.01928, 2023
-
[21]
Uncertainty-aware evaluation for vision-language models.arXiv preprint arXiv:2402.14418, 2024
Vasily Kostumov, Bulat Nutfullin, Oleg Pilipenko, and Eugene Ilyushin. Uncertainty-aware evaluation for vision-language models.arXiv preprint arXiv:2402.14418, 2024
-
[22]
Analyzing uncertainty of llm-as-a-judge: Interval evaluations with conformal prediction, 2025
Huanxin Sheng, Xinyi Liu, Hangfeng He, Jieyu Zhao, and Jian Kang. Analyzing uncertainty of llm-as-a-judge: Interval evaluations with conformal prediction, 2025
2025
-
[23]
Qingni Wang, Tiantian Geng, Zhiyuan Wang, Teng Wang, Bo Fu, and Feng Zheng. Sample then identify: A general framework for risk control and assessment in multimodal large language models.arXiv preprint arXiv:2410.08174, 2024
-
[24]
Conu: Conformal uncertainty in large language models with correctness coverage guarantees
Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Xiaoshuang Shi, Kaidi Xu, Heng Tao Shen, and Xiaofeng Zhu. Conu: Conformal uncertainty in large language models with correctness coverage guarantees. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6886–6898, 2024
2024
-
[25]
Api is enough: Conformal prediction for large language models without logit-access, 2024
Jiayuan Su, Jing Luo, Hongwei Wang, and Lu Cheng. Api is enough: Conformal prediction for large language models without logit-access, 2024
2024
-
[26]
Sconu: Selective conformal uncertainty in large language models, 2025
Zhiyuan Wang, Qingni Wang, Yue Zhang, Tianlong Chen, Xiaofeng Zhu, Xiaoshuang Shi, and Kaidi Xu. Sconu: Selective conformal uncertainty in large language models, 2025
2025
- [27]
-
[28]
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S Jaakkola, and Regina Barzilay. Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
-
[29]
Mitigating llm hallucinations via conformal abstention, 2024
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, András György, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesvári, Ali Taylan Cemgil, and Nenad Tomasev. Mitigating llm hallucinations via conformal abstention, 2024
2024
-
[30]
Conformal risk control.arXiv preprint arXiv:2208.02814,
Anastasios N Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Confor- mal risk control.arXiv preprint arXiv:2208.02814, 2022
-
[31]
Unsupervised quality estimation for neural machine translation.Transactions of the Association for Computational Linguistics, 8:539–555, 2020
Marina Fomicheva, Shuo Sun, Lisa Yankovskaya, Frédéric Blain, Francisco Guzmán, Mark Fishel, Nikolaos Aletras, Vishrav Chaudhary, and Lucia Specia. Unsupervised quality estimation for neural machine translation.Transactions of the Association for Computational Linguistics, 8:539–555, 2020
2020
-
[32]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664, 2023
work page internal anchor Pith review arXiv 2023
-
[33]
Reasoning aware self-consistency: Leveraging reasoning paths for efficient LLM sampling
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient LLM sampling. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
2025
-
[34]
Llm-check: Investigating detection of hallucinations in large language models.Advances in Neural Information Processing Systems, 37:34188–34216, 2024
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. Llm-check: Investigating detection of hallucinations in large language models.Advances in Neural Information Processing Systems, 37:34188–34216, 2024
2024
-
[35]
Inside: Llms’ internal states retain the power of hallucination detection, 2024
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. Inside: Llms’ internal states retain the power of hallucination detection, 2024
2024
-
[36]
Token-level density-based uncertainty quantification methods for eliciting truthfulness of large language models, 2025
Artem Vazhentsev, Lyudmila Rvanova, Ivan Lazichny, Alexander Panchenko, Maxim Panov, Timothy Baldwin, and Artem Shelmanov. Token-level density-based uncertainty quantification methods for eliciting truthfulness of large language models, 2025
2025
-
[37]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models, 2024
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models, 2024
2024
-
[38]
Linear transformations that preserve majorization, schur concavity, and exchangeability.Linear algebra and its applications, 127:121–138, 1990
Angela M Dean and Joseph S Verducci. Linear transformations that preserve majorization, schur concavity, and exchangeability.Linear algebra and its applications, 127:121–138, 1990
1990
-
[39]
Question answering benchmarks for wikidata
Dennis Diefenbach, Thomas Pellissier Tanon, Kamal Deep Singh, and Pierre Maret. Question answering benchmarks for wikidata. InProceedings of the ISWC 2017 Posters & Demonstra- tions and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 23rd - to - 25th, 2017., 2017
2017
-
[40]
Gemma 3 technical report, 2025
Gemma Team. Gemma 3 technical report, 2025
2025
-
[41]
Yihe Dong, Lorenzo Noci, Mikhail Khodak, and Mufan Li. Attention retrieves, mlp memorizes: Disentangling trainable components in the transformer.arXiv preprint arXiv:2506.01115, 2025
-
[42]
Javier Ferrando, Gerard I Gállego, and Marta R Costa-Jussà. Measuring the mixing of contextual information in the transformer.arXiv preprint arXiv:2203.04212, 2022
-
[43]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings.arXiv preprint arXiv:1909.00512, 2019
-
[44]
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J. Liu. Out-of-distribution detection and selective generation for conditional language models, 2023
2023
-
[45]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks, 2018
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks, 2018
2018
-
[46]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[47]
Truthfulqa: Measuring how models mimic human falsehoods, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods, 2022
2022
-
[48]
Liu, and Matt Gardner
Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions, 2017
2017
-
[49]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[50]
Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019
2019
-
[51]
The llama 3 herd of models, 2024
Aaron Grattafiori et al. The llama 3 herd of models, 2024
2024
-
[52]
HHEM-2.1-Open, 2024
Forrest Bao, Miaoran Li, Rogger Luo, and Ofer Mendelevitch. HHEM-2.1-Open, 2024
2024
-
[53]
Gpt-4o system card, 2024
OpenAI. Gpt-4o system card, 2024. 12
2024
-
[54]
Gpt-5: Scaling language models.OpenAI Technical Report, 2025
OpenAI. Gpt-5: Scaling language models.OpenAI Technical Report, 2025. Model version 5.1 referenced in text
2025
-
[55]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794. ACM, August 2016
2016
-
[56]
Bench- marking uncertainty quantification methods for large language models with lm-polygraph
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, Alexan- der Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, and Artem Shelmanov. Bench- marking uncertainty quantification methods for large language models with lm-polygraph. Tr...
2025
-
[57]
Enhancing uncertainty-based hallucination detection with stronger focus
Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, and Luoyi Fu. Enhancing uncertainty-based hallucination detection with stronger focus. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 915–932, Singapore, D...
2023
-
[58]
LLM-check: Investigating detection of hallucinations in large language models
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. LLM-check: Investigating detection of hallucinations in large language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[59]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[60]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert, 2020
2020
-
[61]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[62]
Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space, 2024
Xin Qiu and Risto Miikkulainen. Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space, 2024
2024
-
[63]
Who wrote Pride and Prejudice?
Chenggong Zhang, Haopeng Wang, and Hexi Meng. Hallucination detection and evaluation of large language model, 2026. 13 A Additional Theoretical Statement A.1 Proof of Lemma 3.2 Proof.Consider the deterministic mapping g: ((X 1, Y1), . . . ,(Xn+1, Yn+1))7→((U 1, J1), . . . ,(Un+1, Jn+1)), where for eachi, Ui =r(f(X i)|X i), J i =ξ(X i, Yi, f(X i)), and g i...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.