Recognition: unknown
Dynamic Cluster Data Sampling for Efficient and Long-Tail-Aware Vision-Language Pre-training
Pith reviewed 2026-05-07 07:34 UTC · model grok-4.3
The pith
Dynamic cluster sampling reduces vision-language model training costs while boosting performance on rare long-tail concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a dynamic cluster-based sampling approach (DynamiCS) that downsamples large clusters of data and upsamples small ones. The approach is dynamic in that it applies sampling at each epoch. We first show the importance of dynamic sampling for VLM training. Then, we demonstrate the advantage of our cluster-scaling approach, which maintains the relative order of semantic clusters in the data and emphasizes the long-tail. This approach contrasts with current work, which focuses only on flattening the semantic distribution of the data. Our experiments show that DynamiCS reduces the computational cost of VLM training and provides a performance advantage for long-tail concepts.
What carries the argument
Dynamic cluster-based sampling (DynamiCS), which at each training epoch downsamples large semantic clusters and upsamples small ones to emphasize the long tail while preserving relative cluster order.
If this is right
- VLMs can be pre-trained with fewer total data samples processed while retaining or improving accuracy.
- Models achieve higher effectiveness on tasks involving rare or long-tail visual-language concepts.
- Semantic cluster order is preserved, avoiding the loss of topic importance that comes from uniform flattening.
- Dynamic adjustment per epoch proves more effective than static sampling strategies for balancing efficiency and coverage.
Where Pith is reading between the lines
- This sampling strategy might extend to other data-intensive training tasks like large language model pre-training where long-tail issues arise.
- Combining it with other efficiency methods such as gradient checkpointing could yield further compute savings.
- Downstream applications in specialized domains with rare events, like medical imaging, could benefit from better rare-concept modeling.
Load-bearing premise
Dynamically resizing data clusters each epoch will keep enough examples from common concepts to support learning while increasing exposure to rare ones enough to improve their capture, without creating new biases or slowing convergence.
What would settle it
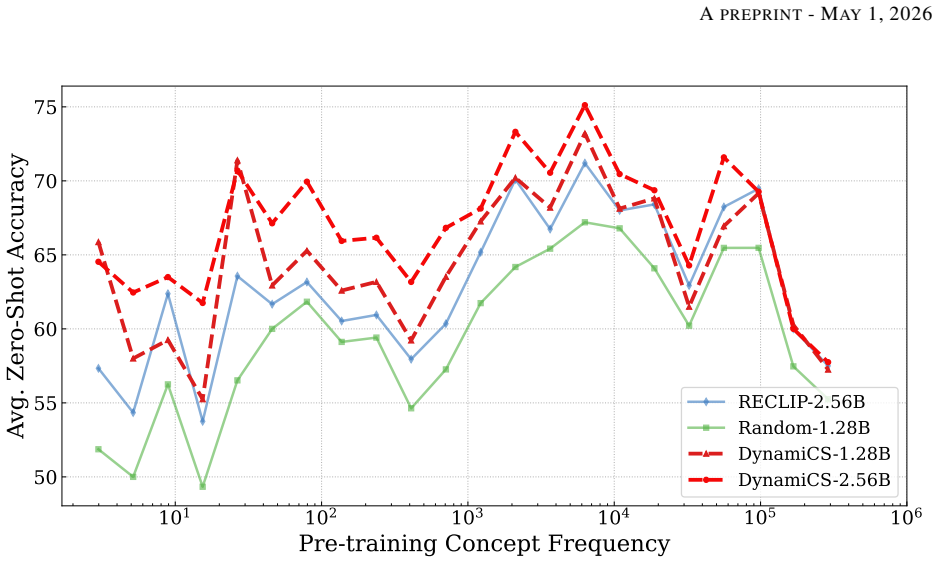
A direct comparison of zero-shot retrieval accuracy on long-tail concepts showing that a model trained with DynamiCS performs no better or worse than one trained with uniform random sampling at identical total compute.
Figures

read the original abstract
The computational cost of training a vision-language model (VLM) can be reduced by sampling the training data. Previous work on efficient VLM pre-training has pointed to the importance of semantic data balance, adjusting the distribution of topics in the data to improve VLM accuracy. However, existing efficient pre-training approaches may disproportionately remove rare concepts from the training corpus. As a result, \emph{long-tail concepts} remain insufficiently represented in the training data and are not effectively captured during training. In this work, we introduce a \emph{dynamic cluster-based sampling approach (DynamiCS)} that downsamples large clusters of data and upsamples small ones. The approach is dynamic in that it applies sampling at each epoch. We first show the importance of dynamic sampling for VLM training. Then, we demonstrate the advantage of our cluster-scaling approach, which maintains the relative order of semantic clusters in the data and emphasizes the long-tail. This approach contrasts with current work, which focuses only on flattening the semantic distribution of the data. Our experiments show that DynamiCS reduces the computational cost of VLM training and provides a performance advantage for long-tail concepts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DynamiCS, a dynamic cluster-based sampling approach for efficient vision-language pre-training. It dynamically downsamples large semantic clusters and upsamples small ones at each epoch to reduce training costs while providing better representation for long-tail concepts. The work claims to demonstrate the importance of dynamic sampling and the advantages of maintaining relative cluster orders over flattening the distribution, supported by experiments showing reduced computational cost and improved long-tail performance.
Significance. If the experimental claims are robustly supported, this method could have significant impact on scaling VLM pre-training to larger datasets by improving efficiency and addressing long-tail biases in a principled way. The focus on dynamic adjustment per epoch and preserving semantic cluster structure offers a potentially novel angle compared to static or distribution-flattening methods.
major comments (2)
- [§5 (Experimental Results)] §5 (Experimental Results): The reported experiments do not include a control where cluster scaling ratios are computed once from the initial clustering and applied statically across all epochs. Without this ablation, gains cannot be confidently attributed to the dynamic per-epoch component of DynamiCS rather than the cluster-based scaling rule itself. This is critical because the central claim emphasizes the dynamism.
- [§3 (Method)] §3 (Method): Insufficient detail is provided on the cluster formation process, including the embedding model used for clustering, the clustering algorithm, and the number of clusters. This information is load-bearing for understanding and reproducing how 'large' and 'small' clusters are identified and scaled.
minor comments (2)
- [Abstract] Abstract: The abstract does not specify the datasets, VLM architectures, baselines, or evaluation metrics employed in the experiments, which makes it challenging to assess the strength of the claims without reading the full text.
- [Throughout] Throughout: Some notation for cluster sizes and sampling ratios could be more clearly defined with equations to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of DynamiCS. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and reproducibility of our results.
read point-by-point responses
-
Referee: [§5 (Experimental Results)] §5 (Experimental Results): The reported experiments do not include a control where cluster scaling ratios are computed once from the initial clustering and applied statically across all epochs. Without this ablation, gains cannot be confidently attributed to the dynamic per-epoch component of DynamiCS rather than the cluster-based scaling rule itself. This is critical because the central claim emphasizes the dynamism.
Authors: We agree that this ablation is important for isolating the contribution of per-epoch dynamism. While our original experiments already compared DynamiCS against static sampling and distribution-flattening baselines, we did not include a static application of our own cluster-derived scaling ratios. In the revised manuscript, we will add this control in §5: scaling ratios will be computed once from the initial clustering and held fixed across epochs, then directly compared to the dynamic version on both efficiency and long-tail metrics. This addition will more rigorously support our emphasis on dynamism. revision: yes
-
Referee: [§3 (Method)] §3 (Method): Insufficient detail is provided on the cluster formation process, including the embedding model used for clustering, the clustering algorithm, and the number of clusters. This information is load-bearing for understanding and reproducing how 'large' and 'small' clusters are identified and scaled.
Authors: We appreciate this point and agree that these details are necessary for reproducibility. In the revised §3, we will explicitly specify the embedding model used to obtain representations for clustering, the clustering algorithm, the number of clusters, and the precise rule for designating clusters as large or small (including any size thresholds or relative ordering criteria). We will also add a brief note on how these choices were validated. revision: yes
Circularity Check
No circularity; empirical method with explicit definitions and experimental validation
full rationale
The paper defines DynamiCS explicitly as a per-epoch dynamic cluster-based sampling procedure that downsamples large clusters and upsamples small ones while preserving relative cluster order. It states two sequential demonstrations (importance of dynamism, then advantage of the scaling rule) and reports experimental outcomes on cost reduction and long-tail performance. No equations, first-principles derivations, or fitted parameters are presented that reduce a claimed prediction to its own inputs by construction. No self-citation is invoked as a load-bearing uniqueness theorem or ansatz. The method is not a renaming of a known result but a concrete sampling rule tested against baselines. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling Laws for Neural Language Models.CoRR, abs/2001.08361, 2020
work page internal anchor Pith review arXiv 2001
-
[2]
Learning Transferable Visual Models from Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models from Natural Language Supervision. InInternational Conference on Machine Learning, 2021
2021
-
[3]
OpenCLIP, July 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP, July 2021
2021
-
[4]
Scaling up Visual and Vision-Language Representation Learning with Noisy Text Supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up Visual and Vision-Language Representation Learning with Noisy Text Supervision. InProceedings of Machine Learning Research, 2021
2021
-
[5]
VirTex: Learning Visual Representations from Textual Annotations
Karan Desai and Justin Johnson. VirTex: Learning Visual Representations from Textual Annotations. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[6]
Contrastive Learning of Medical Visual Representations from Paired Images and Text
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive Learning of Medical Visual Representations from Paired Images and Text. InMachine Learning for Healthcare Conference, 2022
2022
-
[7]
Scaling Language-Image Pre-Training via Masking
Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, and Kaiming He. Scaling Language-Image Pre-Training via Masking. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[8]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid Loss for Language Image Pre-Training. InIEEE/CVF International Conference on Computer Vision, 2023
2023
-
[9]
BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation. InInternational Conference on Machine Learning, 2022
2022
-
[10]
Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. InConference on Neural Information Processing Systems, 2023
2023
-
[11]
OpenAI, Josh Achiam, Steven Adler, and Sandhini Agarwal et al. GPT-4 Technical Report.CoRR, abs/2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical Text-Conditional Image Generation with CLIP Latents.CoRR, abs/2204.06125, 2022
work page internal anchor Pith review arXiv 2022
-
[13]
RECLIP: Resource-Efficient CLIP by Training with Small Images.Transactions on Machine Learning Research, 2023
Runze Li, Dahun Kim, Bir Bhanu, and Weicheng Kuo. RECLIP: Resource-Efficient CLIP by Training with Small Images.Transactions on Machine Learning Research, 2023
2023
-
[14]
An Inverse Scaling Law for CLIP Training
Xianhang Li, Zeyu Wang, and Cihang Xie. An Inverse Scaling Law for CLIP Training. InConference on Neural Information Processing Systems, 2023
2023
-
[15]
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feichtenhofer. Demystifying CLIP Data. InInternational Conference on Learning Representations, 2024
2024
-
[16]
ImageNet: A Large-Scale Hierarchical Image Database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2009. 11 APREPRINT- MAY1, 2026
2009
-
[17]
Zero-Shot
Vishaal Udandarao, Ameya Prabhu, Adhiraj Ghosh, Yash Sharma, Philip Torr, Adel Bibi, Samuel Albanie, and Matthias Bethge. No "Zero-Shot" without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance. InConference on Neural Information Processing Systems, 2024
2024
-
[18]
DataComp: In Search of the Next Generation of Multimodal Datasets
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah M Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alex...
2023
-
[19]
Data Filtering Networks
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander T Toshev, and Vaishaal Shankar. Data Filtering Networks. InInternational Conference on Learning Representations, 2024
2024
-
[20]
Improving Multimodal Datasets with Image Captioning
Thao Nguyen, Samir Yitzhak Gadre, Gabriel Ilharco, Sewoong Oh, and Ludwig Schmidt. Improving Multimodal Datasets with Image Captioning. InConference on Neural Information Processing Systems, 2023
2023
-
[21]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. InNeurIPS Workshop on Data-Centric AI, 2021
2021
-
[22]
Amro Kamal Mohamed Abbas, Evgenia Rusak, Kushal Tirumala, Wieland Brendel, Kamalika Chaudhuri, and Ari S. Morcos. Effective Pruning of Web-Scale Datasets Based on Complexity of Concept Clusters. InInternational Conference on Learning Representations, 2024
2024
-
[23]
HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models
Zhixiang Wei, Guangting Wang, Xiaoxiao Ma, Ke Mei, Huaian Chen, Yi Jin, and Fengyun Rao. HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models. In IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[24]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation Learning with Contrastive Predictive Coding. CoRR, abs/1807.03748, 2018
work page internal anchor Pith review arXiv 2018
-
[25]
Attentive Mask CLIP
Yifan Yang, Weiquan Huang, Yixuan Wei, Houwen Peng, Xinyang Jiang, Huiqiang Jiang, Fangyun Wei, Yin Wang, Han Hu, Lili Qiu, et al. Attentive Mask CLIP. InIEEE/CVF International Conference on Computer Vision, 2023
2023
-
[26]
Centered Masking for Language-Image Pre-Training
Mingliang Liang and Martha Larson. Centered Masking for Language-Image Pre-Training. InMachine Learning and Knowledge Discovery in Databases. Research Track and Demo Track, 2024
2024
-
[27]
Seeing What Matters: Empowering CLIP with Patch Generation-To-Selection
Gensheng Pei, Tao Chen, Yujia Wang, Xinhao Cai, Xiangbo Shu, Tianfei Zhou, and Yazhou Yao. Seeing What Matters: Empowering CLIP with Patch Generation-To-Selection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[28]
Frequency Is What You Need: Considering Word Frequency When Text Masking Benefits Vision-Language Model Pre-Training
Mingliang Liang and Martha Larson. Frequency Is What You Need: Considering Word Frequency When Text Masking Benefits Vision-Language Model Pre-Training. InIEEE/CVF Winter Conference on Applications of Computer Vision, 2026
2026
-
[29]
Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset for Automatic Image Captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset for Automatic Image Captioning. InAnnual Meeting of the Association for Computational Linguistics, 2018
2018
-
[30]
Conceptual 12M: Pushing Web-Scale Image- Text Pre-Training to Recognize Long-Tail Visual Concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing Web-Scale Image- Text Pre-Training to Recognize Long-Tail Visual Concepts. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[31]
LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Mod...
2022
-
[32]
What Makes CLIP More Robust to Long-Tailed Pre-Training Data? A Controlled Study for Transferable Insights
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, and XIAOJUAN QI. What Makes CLIP More Robust to Long-Tailed Pre-Training Data? A Controlled Study for Transferable Insights. InConference on Neural Information Processing Systems, 2024
2024
-
[33]
The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, and Shu Kong. The Neglected Tails in Vision-Language Models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 12 APREPRINT- MAY1, 2026
2024
- [34]
-
[35]
On the De-Duplication of LAION-2B.CoRR, abs/2303.12733, 2023
Ryan Webster, Julien Rabin, Loic Simon, and Frederic Jurie. On the De-Duplication of LAION-2B.CoRR, abs/2303.12733, 2023
-
[36]
What If We Recaption Billions of Web Images with LLaMA-3? InInternational Conference on Machine Learning, 2025
Xianhang Li, Haoqin Tu, Mude Hui, Zeyu Wang, Bingchen Zhao, Junfei Xiao, Sucheng Ren, Jieru Mei, Qing Liu, Huangjie Zheng, Yuyin Zhou, and Cihang Xie. What If We Recaption Billions of Web Images with LLaMA-3? InInternational Conference on Machine Learning, 2025
2025
-
[37]
OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
Xianhang Li, Yanqing Liu, Haoqin Tu, and Cihang Xie. OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning. InIEEE/CVF International Conference on Computer Vision, 2025
2025
-
[38]
Improving CLIP Training with Language Rewrites
Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yonglong Tian. Improving CLIP Training with Language Rewrites. InConference on Neural Information Processing Systems, 2023
2023
-
[39]
Balanced Data Sampling for Language Model Training with Clustering
Yunfan Shao, Linyang Li, Zhaoye Fei, Hang Yan, Dahua Lin, and Xipeng Qiu. Balanced Data Sampling for Language Model Training with Clustering. InFindings of the Association for Computational Linguistics: ACL, 2024
2024
-
[40]
YFCC100M: The New Data in Multimedia Research.Communications of the ACM, 59(2), 2016
Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. YFCC100M: The New Data in Multimedia Research.Communications of the ACM, 59(2), 2016
2016
-
[41]
Distributed Representations of Words and Phrases and Their Compositionality
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed Representations of Words and Phrases and Their Compositionality. InConference on Neural Information Processing Systems, 2013
2013
-
[42]
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations, 2021
2021
-
[43]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. InConference on Neural Information Processing Systems, 2017
2017
-
[44]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. InEuropean Conference on Computer Vision, 2014
2014
-
[45]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From Image Descriptions to Visual Denotations: New Similarity Metrics for Semantic Inference over Event Descriptions.Transactions of the Association for Computational Linguistics, 2:67–78, 2014
2014
-
[46]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The Caltech-UCSD Birds-200-2011 Dataset. Technical report, California Institute of Technology, 2011
2011
-
[47]
Automated Flower Classification over a Large Number of Classes
Maria-Elena Nilsback and Andrew Zisserman. Automated Flower Classification over a Large Number of Classes. InIndian Conference on Computer Vision, Graphics and Image Processing, 2008
2008
-
[48]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.CoRR, abs/1706.02677, 2017
work page internal anchor Pith review arXiv 2017
-
[49]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations, 2019
2019
-
[50]
Generative Pretraining from Pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative Pretraining from Pixels. InInternational Conference on Machine Learning, 2020
2020
-
[51]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic Gradient Descent with Warm Restarts. InInternational Conference on Learning Representations, 2017
2017
-
[52]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[53]
The Faiss Library.IEEE Transactions on Big Data, 2025
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The Faiss Library.IEEE Transactions on Big Data, 2025. Early Access. 13 APREPRINT- MAY1, 2026
2025
-
[54]
img2dataset: Easily Turn Large Sets of Image URLs to an Image Dataset
Romain Beaumont. img2dataset: Easily Turn Large Sets of Image URLs to an Image Dataset. https://github. com/rom1504/img2dataset, 2021
2021
-
[55]
CLIP Benchmark, November 2022
Mehdi Cherti and Romain Beaumont. CLIP Benchmark, November 2022. 14 APREPRINT- MAY1, 2026 A Details of Experimental Setup We follow OpenCLIP [3], FLIP [7], and CLIPA [14] to pre-train and evaluate our methods. A.1 Architectures Following FLIP [7] and CLIPA [14], we used ViT-B/16 and ViT-L/16 with global average pooling as the image encoder. For models pre...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.