Recognition: unknown
TripVVT: A Large-Scale Triplet Dataset and a Coarse-Mask Baseline for In-the-Wild Video Virtual Try-On
Pith reviewed 2026-05-07 05:39 UTC · model grok-4.3
The pith
A diffusion transformer using coarse human masks instead of garment masks, trained on a new 10K in-the-wild triplet dataset, produces higher-quality video virtual try-on with better real-world generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Diffusion Transformer trained on the new TripVVT-10K in-the-wild triplet dataset and conditioned only on a coarse human-mask prior rather than fragile garment masks achieves higher video quality and garment fidelity while generalizing markedly better to real-world conditions involving motion, occlusion, and cluttered backgrounds than existing state-of-the-art academic and commercial video virtual try-on systems.
What carries the argument
The substitution of detailed garment segmentation masks by a simple, stable coarse human-mask prior inside a Diffusion Transformer architecture, which supplies reliable conditioning for background preservation and motion robustness.
If this is right
- Improved temporal coherence and background consistency become achievable without mask refinement pipelines.
- The method handles multi-person and cluttered scenes more reliably than prior mask-dependent approaches.
- Garment transfer fidelity rises because errors from inaccurate garment segmentation are avoided.
- The released dataset and benchmark create a shared testbed for controllable video try-on research.
- A stable prior reduces the need for per-frame mask post-processing in production pipelines.
Where Pith is reading between the lines
- The same human-mask substitution could simplify other diffusion-based video editing tasks where object-level masks are expensive or unreliable to obtain.
- Adding lightweight pose or depth signals on top of the human prior might increase control without reintroducing mask fragility.
- Further growth of the triplet dataset beyond 10K examples would likely extend the observed generalization gains.
- The approach suggests that precise per-garment masks may be less critical than stable spatial priors once sufficient diverse video supervision is available.
Load-bearing premise
That replacing precise garment masks with a coarse human-mask prior supplies enough signal to maintain background fidelity and handle motion, occlusion, and clutter across the full diversity of real-world videos.
What would settle it
Side-by-side failure cases on videos with heavy garment occlusion or rapid motion where the human-mask model visibly distorts the original background or garment shape while a mask-based baseline does not.
Figures

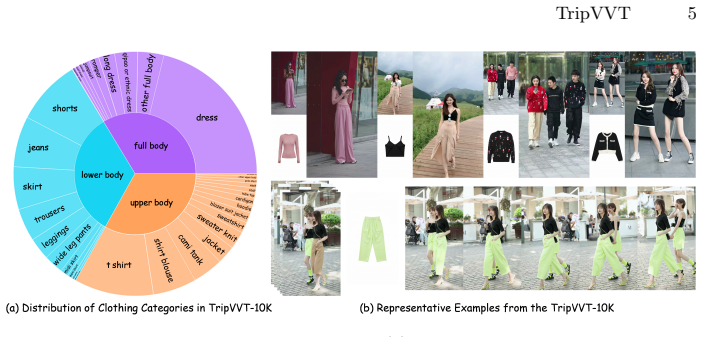





read the original abstract
Due to the scarcity of large-scale in-the-wild triplet data and the improper use of masks, the performance of video virtual try-on models remains limited. In this paper, we first introduce **TripVVT-10K**, the largest and most diverse in-the-wild triplet dataset to date, providing explicit video-level cross-garment supervision that existing video datasets lack. Built upon this resource, we develop **TripVVT**, a Diffusion Transformer-based framework that replaces fragile garment masks with a simple, stable human-mask prior, enabling reliable background preservation while remaining robust to real-world motion, occlusion, and cluttered scenes. To support comprehensive evaluation, we further establish **TripVVT-Bench**, a 100-case benchmark covering diverse garments, complex environments, and multi-person scenarios, with metrics spanning video quality, try-on fidelity, background consistency, and temporal coherence. Compared to state-of-the-art academic and commercial systems, TripVVT achieves superior video quality and garment fidelity while markedly improving generalization to challenging in-the-wild videos. We publicly release the dataset and benchmark, which we believe provide a solid foundation for advancing controllable, realistic, and temporally stable video virtual try-on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TripVVT-10K, the largest in-the-wild triplet dataset for video virtual try-on providing cross-garment supervision, and proposes TripVVT, a Diffusion Transformer model that substitutes a coarse human-mask prior for garment masks to achieve better background preservation and robustness to motion/occlusion. It establishes TripVVT-Bench (100 cases) for evaluation across video quality, fidelity, background consistency, and temporal coherence, claiming superior performance and generalization over academic and commercial baselines.
Significance. If the empirical results hold, the public release of TripVVT-10K and TripVVT-Bench would be a valuable contribution by addressing the scarcity of large-scale in-the-wild triplet data for video virtual try-on. The coarse-mask baseline offers a simple, stable alternative that could improve generalization in cluttered real-world scenes, and the emphasis on reproducible data resources strengthens the work's utility for the community.
major comments (2)
- [Experimental Evaluation / TripVVT-Bench] Experimental section / TripVVT-Bench description: The central claim of superior video quality, garment fidelity, and generalization to in-the-wild videos is presented without quantitative metrics (e.g., PSNR, user-study scores, or background-consistency numbers), error bars, or explicit details on how the 100 benchmark cases were selected and scored. This makes it impossible to verify the performance assertions against the stated baselines.
- [Method (Coarse-Mask Prior)] Method section (coarse human-mask prior): The key methodological substitution of garment masks by a simple human-mask prior is asserted to enable reliable background preservation and robustness to motion, occlusion, and clutter. No ablation studies are provided comparing this prior against precise garment masks or isolating its contribution from the new dataset and Diffusion Transformer, leaving the sufficiency of the prior unverified for the claimed generalization gains.
minor comments (1)
- [Abstract] Abstract: The metrics spanning 'video quality, try-on fidelity, background consistency, and temporal coherence' are named but not defined or referenced to specific equations/tables in the benchmark description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the empirical support and methodological validation in the manuscript.
read point-by-point responses
-
Referee: Experimental section / TripVVT-Bench description: The central claim of superior video quality, garment fidelity, and generalization to in-the-wild videos is presented without quantitative metrics (e.g., PSNR, user-study scores, or background-consistency numbers), error bars, or explicit details on how the 100 benchmark cases were selected and scored. This makes it impossible to verify the performance assertions against the stated baselines.
Authors: We agree that the current experimental section would be strengthened by additional quantitative evidence. In the revised manuscript we will report numerical results on TripVVT-Bench, including PSNR, SSIM, and LPIPS for fidelity where appropriate, plus aggregated user-study scores (with standard deviations as error bars) for video quality, garment fidelity, background consistency, and temporal coherence. We will also expand the benchmark description to specify the selection criteria for the 100 cases (stratified sampling across garment types, scene complexity, motion patterns, and occlusion levels) and the exact scoring protocol (e.g., number of raters, rating scale, and inter-rater agreement). These additions will enable direct, reproducible comparison with the academic and commercial baselines. revision: yes
-
Referee: Method section (coarse human-mask prior): The key methodological substitution of garment masks by a simple human-mask prior is asserted to enable reliable background preservation and robustness to motion, occlusion, and clutter. No ablation studies are provided comparing this prior against precise garment masks or isolating its contribution from the new dataset and Diffusion Transformer, leaving the sufficiency of the prior unverified for the claimed generalization gains.
Authors: We concur that isolating the contribution of the coarse human-mask prior requires explicit ablations. The revised version will include new ablation experiments that (1) replace the coarse mask with precise garment masks (where available in the data) inside the same Diffusion Transformer backbone, (2) train the model without any mask prior, and (3) compare these variants on both TripVVT-10K and held-out in-the-wild sequences. Metrics will focus on background preservation (e.g., background PSNR/SSIM) and robustness under motion/occlusion. These studies will quantify the prior’s role separately from the dataset and architecture, directly addressing the generalization claims. revision: yes
Circularity Check
No significant circularity; contributions are empirical dataset collection and benchmark evaluation
full rationale
The paper's core contributions are the introduction of the TripVVT-10K triplet dataset and TripVVT-Bench benchmark, plus a baseline Diffusion Transformer framework that substitutes a coarse human-mask prior for garment masks. Performance claims rest on direct empirical comparisons to prior academic and commercial systems rather than any closed-form derivation, fitted parameter renamed as prediction, or self-referential equation. No self-citation chains, uniqueness theorems imported from the same authors, or ansatz smuggling appear in the abstract or described method. The substitution of mask priors is presented as an engineering choice whose validity is asserted via qualitative robustness arguments and quantitative metrics on the new benchmark; these do not reduce to tautological re-use of the paper's own inputs. The work is therefore self-contained against external benchmarks and receives a non-finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- Diffusion transformer hyperparameters
axioms (1)
- domain assumption A coarse human body mask provides a stable prior that preserves background and handles real-world motion and occlusion better than garment masks
Reference graph
Works this paper leans on
-
[1]
Alibaba, H.T.T.L.: Wan-animate: Unified character animation and replacement with holistic replication. (2025),https://arxiv.org/abs/2509.14055
-
[2]
Alibaba PAI: Wan2.1-fun-14b-control.https://huggingface.co/alibaba- pai/ Wan2.1-Fun-14B-Control(2025), accessed: 2025-02-28
2025
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
In: 2017 IEEE Conference on Computer Vision and Pat- tern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the kinetics dataset. In: 2017 IEEE Conference on Computer Vision and Pat- tern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. pp. 4724–
2017
-
[5]
IEEE Computer Society (2017).https://doi.org/10.1109/CVPR.2017.502, https://doi.org/10.1109/CVPR.2017.502
-
[6]
arXiv preprint arXiv:2412.03021 (2024)
Chang, T., Chen, X., Wei, Z., Zhang, X., Chen, Q.G., Luo, W., Song, P., Yang, X.: Pemf-vto: Point-enhanced video virtual try-on via mask-free paradigm. arXiv preprint arXiv:2412.03021 (2024)
-
[7]
Choi, S., Park, S., Lee, M., Choo, J.: VITON-HD: high-resolution virtual try- on via misalignment-aware normalization. In: IEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. pp. 14131– 14140. Computer Vision Foundation / IEEE (2021).https://doi.org/10.1109/ CVPR46437.2021.01391,https://openaccess.thecvf.com...
-
[8]
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving diffusion models for authentic virtual try-on in the wild. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Pro- ceedings, Part LXXXVI. Lecture Notes in Computer Science, vol. 15144, pp. 206–235. Springer (2024).https://doi.org/10.1007/978- 3-...
- [9]
-
[10]
arXiv preprintarXiv:2501.11325(2025)
Chong, Z., Zhang, W., Zhang, S., Zheng, J., Dong, X., Li, H., Wu, Y., Jiang, D., Liang, X.: Catv2ton: Taming diffusion transformers for vision-based virtual try-on with temporal concatenation. arXiv preprintarXiv:2501.11325(2025). https://doi.org/10.48550/ARXIV.2501.11325,https://doi.org/10.48550/ arXiv.2501.11325
-
[11]
Cui, A., Mahajan, J., Shah, V., Gomathinayagam, P., Liu, C., Lazebnik, S.: Street tryon: Learning in-the-wild virtual try-on from unpaired person images. In: 16 D. Shao et al. IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025. pp. 1414–1423. IEEE (2025). https://doi.org/10.1109/WACV61041...
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer 16 J
Dong, H., Liang, X., Shen, X., Wu, B., Chen, B., Yin, J.: FW-GAN: flow-navigated warping GAN for video virtual try-on. In: 2019 IEEE/CVF International Confer- ence on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - Novem- ber 2, 2019. pp. 1161–1170. IEEE (2019).https://doi.org/10.1109/ICCV.2019. 00125,https://doi.org/10.1109/ICCV.2019.00125
-
[13]
Vivid: Video virtual try-on using diffusion models,
Fang, Z., Zhai, W., Su, A., Song, H., Zhu, K., Wang, M., Chen, Y., Liu, Z., Cao, Y., Zha, Z.: Vivid: Video virtual try-on using diffusion models. arXiv preprint arXiv:2405.11794(2024).https : / / doi . org / 10 . 48550 / ARXIV . 2405 . 11794, https://doi.org/10.48550/arXiv.2405.11794
-
[14]
arXiv preprintarXiv:2508.13632 (2025).https://doi.org/10.48550/ARXIV.2508.13632,https://doi.org/10
Feng, Y., Zhang, L., Cao, H., Chen, Y., Feng, X., Cao, J., Wu, Y., Wang, B.: Om- nitry: Virtual try-on anything without masks. arXiv preprintarXiv:2508.13632 (2025).https://doi.org/10.48550/ARXIV.2508.13632,https://doi.org/10. 48550/arXiv.2508.13632
-
[15]
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: 2018 IEEE Conference on Computer Vision and Pattern Recogni- tion,CVPR2018,SaltLakeCity,UT,USA,June18-22,2018.pp.7297–7306.Com- puter Vision Foundation / IEEE Computer Society (2018).https://doi.org/10. 1109/CVPR.2018.00762,http://openaccess.thecvf.com/content...
-
[16]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Guo,H.,Zeng,B.,Song,Y.,Zhang,W.,Liu,J.,Zhang,C.:Any2anytryon:Leverag- ing adaptive position embeddings for versatile virtual clothing tasks. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 19085– 19096 (2025)
2025
-
[17]
https://doi.org/10.48550/arXiv.2505
Hu, X., Yujie, L., Luo, D., Xu, P., Zhang, J., Zhu, J., Wang, C., Fu, Y.: Vtbench: Comprehensive benchmark suite towards real-world virtual try-on models. arXiv preprintarXiv:2505.19571(2025).https://doi.org/10.48550/ARXIV.2505. 19571,https://doi.org/10.48550/arXiv.2505.19571
-
[18]
arXiv preprint arXiv:2411.10499 , year =
Jiang, B., Hu, X., Luo, D., He, Q., Xu, C., Peng, J., Zhang, J., Wang, C., Wu, Y., Fu, Y.: Fitdit: Advancing the authentic garment details for high-fidelity virtual try-on. arXiv preprintarXiv:2411.10499(2024).https://doi.org/10.48550/ ARXIV.2411.10499,https://doi.org/10.48550/arXiv.2411.10499
-
[19]
Jiang,J.,Wang,T.,Yan,H.,Liu,J.:Clothformer:Tamingvideovirtualtry-oninall module. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 10789–10798. IEEE (2022).https://doi.org/10.1109/CVPR52688.2022.01053,https://doi.org/ 10.1109/CVPR52688.2022.01053
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jo, Y., Park, M., Kang, D.o.: Up-vton: A unified virtual try-on framework sup- porting mask, mask-free, and prompt-driven guidance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6971–6979 (2025)
2025
-
[21]
In: SIG- GRAPH Asia 2024 Conference Papers, SA 2024, Tokyo, Japan, December 3-6,
Karras, J., Li, Y., Liu, N., Zhu, L., Yoo, I., Lugmayr, A., Lee, C., Kemelmacher- Shlizerman, I.: Fashion-vdm: Video diffusion model for virtual try-on. In: SIG- GRAPH Asia 2024 Conference Papers, SA 2024, Tokyo, Japan, December 3-6,
2024
-
[22]
pp. 93:1–93:11. ACM (2024).https://doi.org/10.1145/3680528.3687623, https://doi.org/10.1145/3680528.3687623
-
[23]
arXiv preprint TripVVT 17 arXiv:2312.01725(2023).https : / / doi
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: Stableviton: Learning seman- tic correspondence with latent diffusion model for virtual try-on. arXiv preprint TripVVT 17 arXiv:2312.01725(2023).https : / / doi . org / 10 . 48550 / ARXIV . 2312 . 01725, https://doi.org/10.48550/arXiv.2312.01725
-
[24]
Kim, J., Jin, H., Park, S., Choo, J.: Promptdresser: Improving the quality and controllability of virtual try-on via generative textual prompt and prompt-aware mask. arXiv preprintarXiv:2412.16978(2024).https://doi.org/10.48550/ ARXIV.2412.16978,https://doi.org/10.48550/arXiv.2412.16978
-
[25]
Kuaishou Technology: Kling ai model.https://app.klingai.com/cn/(2025), accessed: 2025-11-08
2025
-
[26]
Li, G., Zheng, S., Zhang, H., Chen, J., Luan, J., Ou, B., Zhao, L., Li, B., Jiang, P.: Magictryon: Harnessing diffusion transformer for garment-preserving video virtual try-on. arXiv preprintarXiv:2505.21325(2025).https://doi.org/10.48550/ ARXIV.2505.21325,https://doi.org/10.48550/arXiv.2505.21325
-
[27]
arXiv preprint arXiv:2501.08682(2025).https : / / doi
Li, S., Jiang, Z., Zhou, J., Liu, Z., Chi, X., Wang, H.: Realvvt: Towards pho- torealistic video virtual try-on via spatio-temporal consistency. arXiv preprint arXiv:2501.08682(2025).https : / / doi . org / 10 . 48550 / ARXIV . 2501 . 08682, https://doi.org/10.48550/arXiv.2501.08682
-
[28]
In: International Conference on Learning Representations (2017),https://api.semanticscholar
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2017),https://api.semanticscholar. org/CorpusID:53592270
2017
-
[29]
Morelli, D., Baldrati, A., Cartella, G., Cornia, M., Bertini, M., Cucchiara, R.: Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on. In: Proceed- ings of the 31st ACM International Conference on Multimedia, MM 2023, Ot- tawa, ON, Canada, 29 October 2023- 3 November 2023. pp. 8580–8589. ACM (2023).https://doi.org/10.1145/3581783.3612137,...
-
[30]
Morelli, D., Fincato, M., Cornia, M., Landi, F., Cesari, F., Cucchiara, R.: Dress code: High-resolution multi-category virtual try-on. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022. pp. 2230–2234. IEEE (2022). https://doi.org/10.1109/CVPRW56347.2022.00243,https://d...
-
[31]
Pan, Z.: Anilines - anime lineart extractor.https://github.com/zhenglinpan/ AniLines-Anime-Lineart-Extractor(2025)
2025
-
[32]
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 4172–4182. IEEE (2023).https://doi.org/10.1109/ICCV51070. 2023.00387,https://doi.org/10.1109/ICCV51070.2023.00387
-
[33]
In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event. Proceedings of Machi...
2021
-
[34]
In: The Thirteenth International Conference on Learning Rep- resentations, ICLR 2025, Singapore, April 24-28, 2025
Ravi, N., Gabeur, V., Hu, Y., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C., Girshick, R.B., Dollár, P., Feichtenhofer, C.: SAM 2: Segment anything in images and videos. In: The Thirteenth International Conference on Learning Rep- resentations, ICLR 2025, Singapore, April...
2025
-
[35]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S.E., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3. arXiv preprint...
-
[36]
Team, G.: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261(2025).https : / / doi . org / 10 . 48550 / ARXIV . 2507 . 06261, https://doi.org/10.48550/arXiv.2507.06261
-
[37]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review arXiv 2025
-
[38]
Hilbert’s sixth problem: derivation of fluid equations via Boltzmann’s kinetic theory,
Wan, Z., Xu, Y., Hu, D., Cheng, W., Chen, T., Wang, Z., Liu, F., Liu, T., Gong, M.: MF-VITON: high-fidelity mask-free virtual try-on with minimal input. arXiv preprintarXiv:2503.08650(2025).https://doi.org/10.48550/ARXIV.2503. 08650,https://doi.org/10.48550/arXiv.2503.08650
-
[39]
In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI 2024, Jeju, South Korea, August 3-9, 2024
Wang, C., Chen, T., Chen, Z., Huang, Z., Jiang, T., Wang, Q., Shan, H.: FLDM- VTON: faithful latent diffusion model for virtual try-on. In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI 2024, Jeju, South Korea, August 3-9, 2024. pp. 1362–1370. ijcai.org (2024),https:// www.ijcai.org/proceedings/2024/151
2024
-
[40]
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process.13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861,https://doi.org/ 10.1109/TIP.2003.819861
-
[41]
CoRR abs/2105.15203(2021),https://arxiv.org/abs/2105.15203
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. CoRR abs/2105.15203(2021),https://arxiv.org/abs/2105.15203
-
[42]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017
Xie, S., Girshick, R.B., Dollár, P., Tu, Z., He, K.: Aggregated residual transforma- tions for deep neural networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. pp. 5987–
2017
-
[43]
IEEE Computer Society (2017).https://doi.org/10.1109/CVPR.2017.634, https://doi.org/10.1109/CVPR.2017.634
-
[44]
In: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pp
Xie, Z., Huang, Z., Dong, X., Zhao, F., Dong, H., Zhang, X., Zhu, F., Liang, X.: GP-VTON: towards general purpose virtual try-on via collaborative local-flow global-parsing learning. In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 23550–23559. IEEE (2023).https://doi.org/10.1109...
-
[45]
In: Advances in Neural Information Processing Systems (2022) TripVVT 19
Xu,Y.,Zhang,J.,Zhang,Q.,Tao,D.:ViTPose:Simplevisiontransformerbaselines for human pose estimation. In: Advances in Neural Information Processing Systems (2022) TripVVT 19
2022
-
[46]
Xu, Y., Gu, T., Chen, W., Chen, A.: Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. In: AAAI-25, Sponsored by the Associa- tion for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA. pp. 8996–9004. AAAI Press (2025).https://doi.org/10. 1609/AAAI.V39I9.32973,https://doi.or...
-
[47]
Yang, Z., Jiang, Z., Li, X., Zhou, H., Dong, J., Zhang, H., Du, Y.: D4-vton: Dy- namic semantics disentangling for differential diffusion based virtual try-on. arXiv preprintarXiv:2407.15111(2024).https://doi.org/10.48550/ARXIV.2407. 15111,https://doi.org/10.48550/arXiv.2407.15111
-
[48]
Yang,Z.,Zeng,A.,Yuan,C.,Li,Y.:Effectivewhole-bodyposeestimationwithtwo- stages distillation. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023. pp. 4212–4222. IEEE (2023).https://doi.org/10.1109/ICCVW60793.2023.00455,https://doi.org/ 10.1109/ICCVW60793.2023.00455
-
[49]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. pp. 586–595. Computer Vision Foundation / IEEE Com- puter Society (2018).https://doi.org/10.1109/CVPR....
-
[50]
Zhang, S., Han, X., Zhang, W., Lan, X., Yao, H., Huang, Q.: Limb-aware virtual try-on network with progressive clothing warping. IEEE Trans. Multim.26, 1731– 1746 (2024).https://doi.org/10.1109/TMM.2023.3286278,https://doi.org/ 10.1109/TMM.2023.3286278
-
[51]
Videodpo: Omni- preference alignment for video diffusion generation
Zhang, X., Song, D., Zhan, P., Chang, T., Zeng, J., Chen, Q., Luo, W., Liu, A.: Boow-vton: Boosting in-the-wild virtual try-on via mask-free pseudo data train- ing. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 26399–26408. Computer Vision Foundation / IEEE (2025).https://doi.org/1...
-
[52]
Zhang, X., Li, X., Kampffmeyer, M., Dong, X., Xie, Z., Zhu, F., Dong, H., Liang, X.: Warpdiffusion: Efficient diffusion model for high-fidelity virtual try-on. arXiv preprintarXiv:2312.03667(2023).https://doi.org/10.48550/ARXIV.2312. 03667,https://doi.org/10.48550/arXiv.2312.03667
-
[53]
arXiv preprint arXiv:2507.15852 (2025)
Zhang, Z., Ding, S., Dong, X., He, S., Lin, J., Tang, J., Zang, Y., Cao, Y., Lin, D., Wang, J.: Sec: Advancing complex video object segmentation via progressive concept construction. arXiv preprint arXiv:2507.15852 (2025)
-
[54]
Zheng, P., Gao, D., Fan, D., Liu, L., Laaksonen, J., Ouyang, W., Sebe, N.: Bilat- eral reference for high-resolution dichotomous image segmentation. arXiv preprint arXiv:2401.03407(2024).https : / / doi . org / 10 . 48550 / ARXIV . 2401 . 03407, https://doi.org/10.48550/arXiv.2401.03407
-
[55]
In: MM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021
Zhong, X., Wu, Z., Tan, T., Lin, G., Wu, Q.: MV-TON: memory-based video virtual try-on network. In: MM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021. pp. 908–916. ACM (2021).https://doi.org/10. 1145/3474085.3475269,https://doi.org/10.1145/3474085.3475269
-
[56]
In: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pp
Zhu, L., Yang, D., Zhu, T., Reda, F., Chan, W., Saharia, C., Norouzi, M., Kemelmacher-Shlizerman, I.: Tryondiffusion: A tale of two unets. In: IEEE/CVF 20 D. Shao et al. Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 4606–4615. IEEE (2023).https://doi.org/ 10.1109/CVPR52729.2023.00447,https:/...
-
[57]
arXiv preprintarXiv:2508.02807 (2025).https://doi.org/10.48550/ARXIV.2508.02807,https://doi.org/10
Zuo,T.,Huang,Z.,Ning,S.,Lin,E.,Liang,C.,Zheng,Z.,Jiang,J.,Zhang,Y.,Gao, M., Dong, X.: Dreamvvt: Mastering realistic video virtual try-on in the wild via a stage-wise diffusion transformer framework. arXiv preprintarXiv:2508.02807 (2025).https://doi.org/10.48550/ARXIV.2508.02807,https://doi.org/10. 48550/arXiv.2508.02807
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.