Recognition: unknown
Dreaming Across Towns: Semantic Rollout and Town-Adversarial Regularization for Zero-Shot Held-Out-Town Fixed-Route Driving in CARLA
Pith reviewed 2026-05-07 05:06 UTC · model grok-4.3
The pith
Semantic rollout supervision and town-adversarial regularization improve mean held-out-town route completion in CARLA
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In this controlled fixed-weather CARLA setting with no traffic or pedestrians, training a Dreamer-style agent with multi-horizon prediction of future visual-semantic embeddings along imagined rollouts plus town-adversarial supervision on a semantic projection of the recurrent latent state yields the highest mean success rate on fixed routes in held-out towns among the compared Dreamer-family methods.
What carries the argument
Multi-horizon semantic embedding prediction along imagined rollouts conditioned on causal context features, combined with town-adversarial regularization applied to a semantic projection of the recurrent latent state.
If this is right
- The combined auxiliary losses produce higher mean route completion on fixed routes in unseen towns.
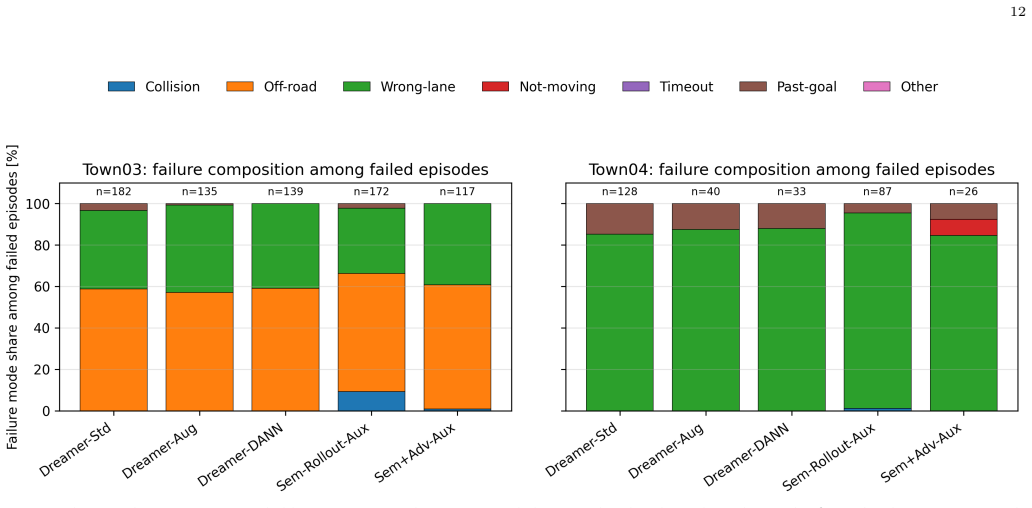
- Safety and lane-keeping metrics show mixed results across the evaluated held-out towns.
- The policy operates without navigation commands, route polylines, goal poses, or map input at inference time.
- The reference route is used only by the environment to compute reward, progress, success, and termination.
Where Pith is reading between the lines
- If the auxiliary losses are the source of the gains, the same regularizers could be tested for robustness under weather changes or added traffic.
- The separation between causal context features and control features may allow the world model to learn town-invariant semantics while the policy focuses on driving actions.
- Reproducing the exact baseline implementations with only the added losses removed would confirm whether the reported improvements are directly attributable to the proposed objectives.
Load-bearing premise
The observed gains in held-out-town success rates are caused by the semantic rollout supervision and town-adversarial regularization rather than by other unstated differences in implementation, hyperparameters, or training schedule between the proposed model and the Dreamer baselines.
What would settle it
Re-implement all Dreamer baselines inside the exact same codebase and training schedule as the proposed model, differing only by the absence of the two auxiliary losses, then check whether the success-rate advantage on held-out towns disappears.
Figures



read the original abstract
Learned driving agents often degrade when deployed in unseen environments. This paper studies a deliberately bounded instance of that problem in the CARLA simulator: zero-shot transfer of a closed-loop fixed-route driving agent from Town05 and Town06 to unseen Town03 and Town04. The study isolates structural town shift by keeping weather fixed to ClearNoon and removing traffic and pedestrians. We build on a Dreamer-style latent world-model agent and add two training-only auxiliary losses: multi-horizon prediction of future visual-semantic embeddings along imagined rollouts and town-adversarial supervision on a semantic projection of the recurrent latent state. A causal context feature conditions the semantic rollout predictor, while the actor and critic retain the standard control feature. The policy receives no navigation command, route polyline, goal pose, or map input; the reference route is used only by the environment for reward, progress, success, and termination. Across the evaluated held-out towns, the proposed model achieves the highest mean success rate among the included Dreamer-family methods. Secondary safety and lane-keeping metrics are mixed across towns. These results support a bounded conclusion: in this controlled fixed-weather CARLA setting, semantic rollout supervision combined with town-adversarial regularization improves mean held-out-town route completion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Dreamer-style latent world-model agent for closed-loop fixed-route driving in CARLA. It augments training with two auxiliary losses: multi-horizon prediction of future visual-semantic embeddings along imagined rollouts and town-adversarial supervision on a semantic projection of the recurrent latent state. A causal context feature conditions the rollout predictor while the actor and critic use the standard control feature. The policy receives no navigation commands, route polylines, or maps; the reference route is used only for environment reward, progress, success, and termination. Training occurs on Town05 and Town06; zero-shot evaluation is performed on held-out Town03 and Town04 under fixed ClearNoon weather with no traffic or pedestrians. The central claim is that the proposed model achieves the highest mean success rate among included Dreamer-family methods, supporting the utility of the two auxiliary losses for this bounded town-shift generalization task.
Significance. If the empirical gains are shown to arise specifically from the auxiliary losses under identical base implementations, the work would demonstrate that semantic rollout supervision and town-adversarial regularization can improve zero-shot route completion for latent world-model agents in a controlled CARLA setting. The deliberate isolation of structural town shift (fixed weather, no dynamic agents) is a strength that allows clearer attribution than typical multi-factor transfer studies. However, the highly bounded scenario limits immediate broader significance to more realistic conditions involving weather variation or traffic. The design choice of keeping policy inputs unchanged while adding training-only losses is a positive aspect for fair evaluation of generalization.
major comments (1)
- The central claim attributes higher mean held-out-town success rates to the addition of semantic rollout supervision and town-adversarial regularization. This attribution is load-bearing only if the base Dreamer agent is identical across comparisons. The manuscript must explicitly confirm (via statement or hyperparameter table in the Experimental Setup section) that recurrent state size, world-model architecture, actor-critic, optimizer, learning-rate schedule, imagination horizon, and total training steps are held constant; any unstated deviation would confound the success-rate delta and render it uninterpretable as evidence for the auxiliary losses.
minor comments (3)
- The abstract states that auxiliary losses improve route completion and that secondary safety/lane-keeping metrics are mixed, but does not report numerical values, standard deviations, or effect sizes. Adding a concise summary of key metrics (e.g., mean success rates per town) would improve readability.
- The distinction between the causal context feature supplied to the semantic rollout predictor and the standard control feature used by the actor/critic should be illustrated with a diagram or pseudocode in the Methods section to clarify information flow.
- Figure captions for any success-rate or metric plots should explicitly list the compared methods and the exact evaluation towns to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of explicit confirmation that base implementations are identical. We agree that this is necessary to support attribution of performance gains to the auxiliary losses. We address the major comment below and will incorporate the requested clarification in the revised manuscript.
read point-by-point responses
-
Referee: The central claim attributes higher mean held-out-town success rates to the addition of semantic rollout supervision and town-adversarial regularization. This attribution is load-bearing only if the base Dreamer agent is identical across comparisons. The manuscript must explicitly confirm (via statement or hyperparameter table in the Experimental Setup section) that recurrent state size, world-model architecture, actor-critic, optimizer, learning-rate schedule, imagination horizon, and total training steps are held constant; any unstated deviation would confound the success-rate delta and render it uninterpretable as evidence for the auxiliary losses.
Authors: We agree that the attribution requires explicit confirmation of identical base implementations. In the experiments, the underlying Dreamer agent (including recurrent state size, world-model architecture, actor-critic networks, optimizer, learning-rate schedule, imagination horizon, and total training steps) is held constant across all compared methods; the only differences are the addition of the semantic rollout prediction loss and town-adversarial regularization for the proposed model. All methods are implemented within the same codebase and training pipeline. To make this fully transparent, we will add a hyperparameter table to the Experimental Setup section of the revised manuscript that enumerates these shared values and includes an explicit statement confirming that no other deviations exist between the base agent and the augmented variants. revision: yes
Circularity Check
No circularity: empirical comparison of auxiliary losses in RL agent
full rationale
The paper is an empirical RL study that reports higher mean held-out-town route completion when semantic-rollout supervision and town-adversarial regularization are added to a Dreamer-style base agent. No mathematical derivation chain exists; the central claim rests on experimental outcomes rather than any equation or prediction that reduces by construction to a fitted parameter or self-citation. The base architecture is referenced to prior Dreamer work by unrelated authors, and all reported metrics are externally measured success rates in the CARLA simulator. No self-definitional, fitted-input-as-prediction, or load-bearing self-citation patterns are present. The result is therefore self-contained as a controlled experimental comparison.
Axiom & Free-Parameter Ledger
free parameters (1)
- auxiliary loss coefficients
axioms (2)
- domain assumption CARLA towns differ only in static layout while sharing identical rendering and physics under ClearNoon
- standard math The latent state learned by Dreamer is Markovian given the chosen observation and action history
Reference graph
Works this paper leans on
-
[1]
CARLA: An Open Urban Driving Simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. López, and V. Koltun, “CARLA: An Open Urban Driving Simulator,” inProceedings of the 1st Annual Conference on Robot Learning, ser. Proceedings of Machine Learning Research, vol. 78. PMLR, 2017, pp. 1–16
2017
-
[2]
Domain- Adversarial Training of Neural Networks,
Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain- Adversarial Training of Neural Networks,” inDomain Adaptation in Computer Vision Applications, G. Csurka, Ed. Cham: Springer International Publishing, 2017, pp. 189–209, series Title: Advances in Computer Vision and Pattern Recognition. [Onl...
-
[3]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering Diverse Domains through World Models,” Apr. 2024, arXiv:2301.04104 [cs]. [Online]. Available: http://arxiv.org/abs/2301.04104
work page internal anchor Pith review arXiv 2024
-
[4]
Reproducible Scaling Laws for Contrastive Language-Image Learning,
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Il- harco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev, “Reproducible Scaling Laws for Contrastive Language-Image Learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 2818–2829
2023
-
[5]
End-to-End Driving via Conditional Imitation Learning,
F. Codevilla, M. Müller, A. López, V. Koltun, and A. Dosovitskiy, “End-to-End Driving via Conditional Imitation Learning,” in 2018 IEEE International Conference on Robotics and Automa- tion (ICRA). IEEE, 2018, pp. 4693–4700
2018
-
[6]
D. Chen, B. Zhou, V. Koltun, and P. Krähenbühl, “Learning by Cheating,” Dec. 2019, arXiv:1912.12294 [cs]. [Online]. Available: http://arxiv.org/abs/1912.12294
-
[7]
Label Efficient Visual Abstractions for Autonomous Driving,
A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar, and A. Geiger, “Label Efficient Visual Abstractions for Autonomous Driving,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2338–2345
2020
-
[8]
RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban En- vironments,
D. Coelho, M. Oliveira, and V. Santos, “RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban En- vironments,”IEEE Transactions on Automation Science and Engineering, vol. 21, no. 4, pp. 7427–7435, 2024
2024
-
[9]
GRI:GeneralReinforcedImitationanditsApplicationtoVision- Based Autonomous Driving,
R. Chekroun, M. Toromanoff, S. Hornauer, and F. Moutarde, “GRI:GeneralReinforcedImitationanditsApplicationtoVision- Based Autonomous Driving,” May 2022, arXiv:2111.08575 [cs]. [Online]. Available: http://arxiv.org/abs/2111.08575
-
[10]
Learning Latent Dynamics for Planning from Pixels,
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning Latent Dynamics for Planning from Pixels,” inProceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 2019, pp. 2555–2565
2019
-
[11]
Dream to Con- trol:LearningBehaviorsbyLatentImagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to Con- trol:LearningBehaviorsbyLatentImagination,”inInternational Conference on Learning Representations, 2020
2020
-
[12]
Q. Li, X. Jia, S. Wang, and J. Yan, “Think2Drive: Efficient Reinforcement Learning by Thinking with Latent World Model for Autonomous Driving (in CARLA-V2),” inComputer Vision – ECCV 2024, A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, Eds. Cham: Springer Nature Switzerland, 2025, vol. 15103, pp. 142–158, series Title: Lecture ...
-
[13]
Learning to drive from a world on rails,
D. Chen, V. Koltun, and P. Krähenbühl, “Learning to drive from a world on rails,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021, pp. 15570–15579
2021
-
[14]
Model-Based Imitation Learning for Urban Driving,
A. Hu, G. Corrado, N. Griffiths, Z. Murez, C. Gurau, H. Yeo, A. Kendall, R. Cipolla, and J. Shotton, “Model-Based Imitation Learning for Urban Driving,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 20703–20716
2022
-
[15]
EnhanceSampleEfficiencyandRobustnessofEnd-to-EndUrban Autonomous Driving via Semantic Masked World Model,
Z. Gao, Y. Mu, C. Chen, J. Duan, S. E. Li, P. Luo, and Y. Lu, “EnhanceSampleEfficiencyandRobustnessofEnd-to-EndUrban Autonomous Driving via Semantic Masked World Model,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 10, pp. 13067–13079, 2024
2024
-
[16]
Raw2Drive: Reinforcement Learning with Aligned World Models for End- to-End Autonomous Driving (in CARLA v2),
Z. Yang, X. Jia, Q. Li, X. Yang, M. Yao, and J. Yan, “Raw2Drive: Reinforcement Learning with Aligned World Models for End- to-End Autonomous Driving (in CARLA v2),” inAdvances in Neural Information Processing Systems, vol. 38, 2025
2025
-
[17]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World,” in2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 23–30
2017
-
[18]
Sim-to-Real Transfer of Robotic Control with Dynamics Ran- domization,
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to-Real Transfer of Robotic Control with Dynamics Ran- domization,” in2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 3803–3810
2018
-
[19]
RMA: Rapid Motor Adaptation for Legged Robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “RMA: Rapid Motor Adaptation for Legged Robots,” inRobotics: Science and Systems, 2021
2021
-
[20]
Unsupervised Domain Adaptation by Backpropagation,
Y. Ganin and V. Lempitsky, “Unsupervised Domain Adaptation by Backpropagation,” inProceedings of the 32nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 37. PMLR, 2015, pp. 1180–1189
2015
-
[21]
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant Risk Minimization,” Mar. 2020, arXiv:1907.02893 [stat]. [Online]. Available: http://arxiv.org/abs/1907.02893
work page internal anchor Pith review arXiv 2020
-
[22]
Domain Adaptation in Reinforcement Learning via Latent Unified State Representation,
J. Xing, T. Nagata, K. Chen, X. Zou, E. Neftci, and J. L. Krichmar, “Domain Adaptation in Reinforcement Learning via Latent Unified State Representation,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, pp. 10452– 10459, 2021
2021
-
[23]
Domain Separation Networks,
K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan, “Domain Separation Networks,” inAdvances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[24]
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets,
X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, “InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets,” in Advances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[25]
DARLA: Improving Zero-Shot Transfer in Reinforcement Learning,
I. Higgins, A. Pal, A. A. Rusu, L. Matthey, C. P. Burgess, A. Pritzel, M. Botvinick, C. Blundell, and A. Lerchner, “DARLA: Improving Zero-Shot Transfer in Reinforcement Learning,” in Proceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 70. PMLR, 2017, pp. 1480–1490
2017
-
[26]
Disentangling by Factorising,
H. Kim and A. Mnih, “Disentangling by Factorising,” inProceed- ings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 2018, pp. 2649–2658
2018
-
[27]
Learning World Models with Identifiable Factoriza- tion,
Y.-R. Liu, B. Huang, Z. Zhu, H. Tian, M. Gong, Y. Yu, and K. Zhang, “Learning World Models with Identifiable Factoriza- tion,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[28]
Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning,
Q. Wang, Z. Zhang, B. Xie, X. Jin, Y. Wang, S. Wang, L. Zheng, X. Yang, and W. Zeng, “Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 2599–2608
2025
-
[29]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S.Agarwal,G.Sastry,A.Askell,P.Mishkin,J.Clark,G.Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Supervision,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, pp. 8748–8763
2021
-
[30]
RoboCLIP: One Demonstration Is Enough to Learn Robot Policies,
S. A. Sontakke, J. Zhang, S. M. R. Arnold, K. Pertsch, E. Bıyık, D. Sadigh, C. Finn, and L. Itti, “RoboCLIP: One Demonstration Is Enough to Learn Robot Policies,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[32]
Available: https://arxiv.org/abs/2412.16201
[Online]. Available: https://arxiv.org/abs/2412.16201
-
[33]
Learning to Adapt Frozen CLIP for Few-Shot Test- Time Domain Adaptation,
Z. Chi, L. Gu, H. Liu, Z. Wang, Y. Wu, Y. Wang, and K. N. Plataniotis, “Learning to Adapt Frozen CLIP for Few-Shot Test- Time Domain Adaptation,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
CLIP-Motion: Learning Reward Functions for Robotic Actions Using Consecutive Observations,
X. Dang, S. Edelkamp, and N. Ribault, “CLIP-Motion: Learning Reward Functions for Robotic Actions Using Consecutive Observations,”arXiv preprint arXiv:2311.03485, 2023. [Online]. Available: https://arxiv.org/abs/2311.03485
-
[35]
CARLA Autonomous Driving Leaderboard,
CARLA Team, “CARLA Autonomous Driving Leaderboard,”
-
[36]
Available: https://leaderboard.carla.org/ 16
[Online]. Available: https://leaderboard.carla.org/ 16
-
[37]
Exploring the Limitations of Behavior Cloning for Autonomous Driving,
F. Codevilla, E. Santana, A. López, and A. Gaidon, “Exploring the Limitations of Behavior Cloning for Autonomous Driving,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019, pp. 9328–9337
2019
-
[38]
Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To- End Autonomous Driving,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To- End Autonomous Driving,” inAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[39]
arXiv preprint arXiv:2412.09647
J. You, X. Jia, Z. Zhang, Y. Zhu, and J. Yan, “Bench2Drive- R: Turning Real World Data into Reactive Closed-Loop Autonomous Driving Benchmark by Generative Model,” arXiv preprint arXiv:2412.09647, 2024. [Online]. Available: https://arxiv.org/abs/2412.09647 F eeza Khan Khanzadareceived the B.E. degree in computer systems engineering from Mehran University ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.