Recognition: unknown
Cost-Aware Learning
Pith reviewed 2026-05-07 05:01 UTC · model grok-4.3
The pith
By accounting for different sampling costs, cost-aware stochastic gradient descent reaches target accuracy at lower total cost and reduces token usage by up to 30 percent in LLM policy optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We consider the problem of Cost-Aware Learning, where sampling different component functions of a finite-sum objective incurs different costs. The objective is to reach a target error while minimizing the total cost. First, we propose the Cost-Aware Stochastic Gradient Descent algorithm for convex functions, and derive its cost complexity to attain an error of ε. Furthermore, we establish a lower bound for this setting and provide a subset selection algorithm to further reduce the cost of training. We apply our theoretical insights to reinforcement learning with language models, where the computational cost of policy gradients varies with sequence length. To this end, we introduce Cost-Aware
What carries the argument
Cost-Aware Stochastic Gradient Descent, which sets the sampling probability of each component inversely proportional to the square root of its cost so that the expected cost per iteration remains controlled while variance is balanced; extended to Cost-Aware GRPO by reweighting policy-gradient terms according to sequence length.
If this is right
- The total cost to reach ε accuracy is bounded by O((∑ sqrt(c_i))² / ε²) instead of the usual O(n / ε²) when costs c_i vary.
- A lower bound matching the upper bound up to constants shows the algorithm is rate-optimal in the cost metric.
- Subset selection can remove expensive components without sacrificing the convergence guarantee.
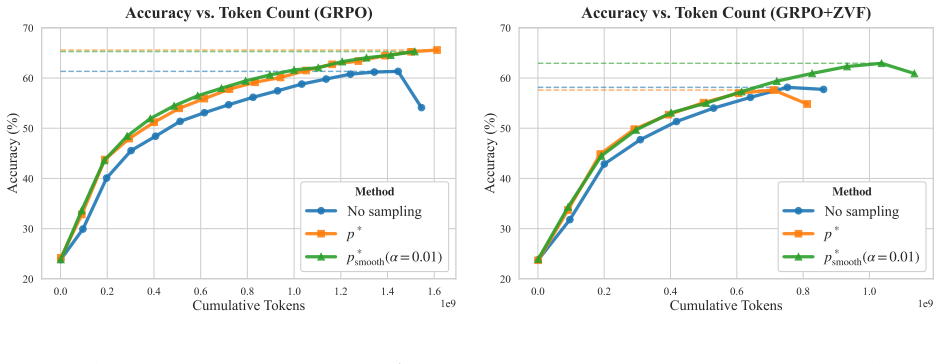
- Cost-Aware GRPO reduces token consumption by up to 30% on 1.5B and 8B LLMs while preserving or improving accuracy.
Where Pith is reading between the lines
- The cost-reweighting idea could be combined with variance-reduction techniques such as SVRG to obtain even larger savings.
- If component costs change over time, an adaptive version that estimates costs on the fly would be a natural next step.
- Applying similar cost awareness during the pre-training of language models, rather than only in the RL stage, might produce multiplicative efficiency improvements.
- The framework naturally extends to any stochastic first-order method where the cost of a gradient estimate can be measured or predicted in advance.
Load-bearing premise
The sampling costs of the individual components are known in advance and adjusting the sampling probabilities according to those costs does not introduce bias that prevents convergence to the correct solution.
What would settle it
An experiment that runs both standard and cost-aware SGD on a small convex finite-sum problem with deliberately unequal component costs and measures whether the cost-aware version reaches the target accuracy with strictly lower total cost; if it does not, the claimed advantage disappears.
Figures










read the original abstract
We consider the problem of Cost-Aware Learning, where sampling different component functions of a finite-sum objective incurs different costs. The objective is to reach a target error while minimizing the total cost. First, we propose the Cost-Aware Stochastic Gradient Descent algorithm for convex functions, and derive its cost complexity to attain an error of $\epsilon$. Furthermore, we establish a lower bound for this setting and provide a subset selection algorithm to further reduce the cost of training. We apply our theoretical insights to reinforcement learning with language models, where the computational cost of policy gradients varies with sequence length. To this end, we introduce Cost-Aware GRPO, an algorithm designed to reduce the cost of policy optimization while preserving performance. Empirical results on 1.5B and 8B LLMs demonstrate that our approach reduces the tokens used in policy optimization by up to about 30% while matching or exceeding baseline accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cost-Aware Learning for finite-sum objectives with heterogeneous sampling costs. For convex functions it proposes Cost-Aware SGD, derives cost-complexity upper bounds to reach error ε, establishes a matching lower bound, and gives a subset-selection procedure. These ideas are transferred to language-model reinforcement learning by defining Cost-Aware GRPO, which sets sampling probabilities inversely proportional to sequence length (cost). Experiments on 1.5 B and 8 B models report up to 30 % fewer tokens in policy optimization while matching or exceeding baseline accuracy.
Significance. If the convex bounds are tight and the GRPO adaptation preserves unbiased gradients, the work supplies a principled route to reduce token consumption in RL-based LLM training without accuracy loss. The explicit cost terms in the convex analysis and the concrete empirical demonstration on production-scale models constitute the main strengths; the result would be of immediate practical interest to any group performing policy optimization on large language models.
major comments (3)
- [§4.2] §4.2 (Cost-Aware GRPO surrogate): the sampling probabilities p_i ∝ 1/c_i are inserted directly into the GRPO objective without an importance-sampling correction 1/p_i. Because sequence length is generated by the current policy and is correlated with both log-probabilities and rewards, the resulting gradient estimator is biased; this bias is not covered by the convex analysis in §3 and undermines the claim that accuracy is preserved.
- [§5] §5 (Experiments): the reported 30 % token reduction on 1.5 B and 8 B models is presented without variance estimates across independent runs or statistical tests against the GRPO baseline. Given the high variance typical of LLM policy optimization, it is impossible to judge whether the accuracy match is reliable or task-dependent.
- [§3.1] §3.1 (Cost-Aware SGD derivation): the cost-complexity bound is stated to be “parameter-free,” yet the proof relies on a known upper bound on the maximum cost C_max; the dependence on C_max should be made explicit so that the claimed reduction can be compared with standard SGD.
minor comments (3)
- [§2] Notation: the symbol C_i is used both for per-sample cost and for the cumulative cost; a clearer distinction would improve readability.
- [Figure 3] Figure 3: the x-axis label “tokens” should specify whether it counts only policy-gradient tokens or the entire training pipeline.
- [§4] Missing reference: prior work on importance sampling for variable-length trajectories in RL (e.g., in PPO variants) should be cited when discussing the GRPO adaptation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We appreciate the recognition of the practical relevance of Cost-Aware Learning for reducing sampling costs in both convex optimization and LLM policy optimization. Below, we provide point-by-point responses to the major comments and outline the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Cost-Aware GRPO surrogate): the sampling probabilities p_i ∝ 1/c_i are inserted directly into the GRPO objective without an importance-sampling correction 1/p_i. Because sequence length is generated by the current policy and is correlated with both log-probabilities and rewards, the resulting gradient estimator is biased; this bias is not covered by the convex analysis in §3 and undermines the claim that accuracy is preserved.
Authors: We acknowledge that directly inserting p_i ∝ 1/c_i into the GRPO objective without the 1/p_i importance-sampling correction produces a biased gradient estimator, as sequence lengths are policy-dependent and correlate with log-probabilities and rewards. This issue is not covered by the convex analysis in §3. In the revised manuscript we will augment Cost-Aware GRPO with the missing importance weight to restore unbiasedness, add a short bias discussion for the heuristic version, and re-run the 1.5 B and 8 B experiments with the corrected estimator to confirm that the reported token savings are retained. revision: yes
-
Referee: [§5] §5 (Experiments): the reported 30 % token reduction on 1.5 B and 8 B models is presented without variance estimates across independent runs or statistical tests against the GRPO baseline. Given the high variance typical of LLM policy optimization, it is impossible to judge whether the accuracy match is reliable or task-dependent.
Authors: We agree that variance estimates and statistical tests are essential given the high variance of LLM policy optimization. Although our runs used multiple independent seeds, only mean metrics were shown. In the revision we will add standard-deviation error bars to all plots and report paired statistical tests (t-tests or Wilcoxon signed-rank tests with p-values) comparing Cost-Aware GRPO against the baseline, thereby demonstrating that the accuracy match holds reliably across tasks. revision: yes
-
Referee: [§3.1] §3.1 (Cost-Aware SGD derivation): the cost-complexity bound is stated to be “parameter-free,” yet the proof relies on a known upper bound on the maximum cost C_max; the dependence on C_max should be made explicit so that the claimed reduction can be compared with standard SGD.
Authors: The referee correctly observes that the bound depends on C_max. The phrase “parameter-free” was intended to indicate independence from other constants (e.g., smoothness or strong-convexity parameters) that appear in many standard analyses. We will revise the theorem statement and proof in §3.1 to display the explicit C_max factor, enabling direct comparison of the cost reduction with vanilla SGD. revision: yes
Circularity Check
No circularity: derivation uses standard convex analysis and applies insights empirically without self-referential reduction
full rationale
The paper first derives cost complexity for Cost-Aware SGD on convex finite-sum objectives by incorporating explicit per-component costs into the standard SGD convergence analysis, then establishes a matching lower bound via information-theoretic arguments on sampling costs. These steps are independent of the target application. The subsequent Cost-Aware GRPO adaptation is presented as a heuristic transfer of the sampling-probability idea to stochastic sequence lengths in policy optimization, with performance validated directly by experiments on 1.5B and 8B LLMs rather than by any fitted parameter or self-citation chain. No equation reduces a claimed prediction to an input by construction, and no load-bearing premise rests on prior work by the same authors. The empirical token-reduction claim is therefore falsifiable outside the derivation itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The finite-sum objective is convex.
- domain assumption Sampling costs for each component are known and fixed in advance.
Reference graph
Works this paper leans on
-
[1]
Variance reduction in sgd by distributed importance sampling.arXiv preprint arXiv:1511.06481,
Guillaume Alain, Alex Lamb, Chinnadhurai Sankar, Aaron Courville, and Yoshua Bengio. Variance reduction in sgd by distributed importance sampling.arXiv preprint arXiv:1511.06481,
-
[2]
Amc problems and solutions.https://artofproblemsolving.com/wiki/index
Art of Problem Solving. Amc problems and solutions.https://artofproblemsolving.com/wiki/index. php/AMC_Problems_and_Solutions, n.d. Accessed: 2026-01-28. Alina Beygelzimer, Sanjoy Dasgupta, and John Langford. Importance weighted active learning. InProceedings of the 26th annual international conference on machine learning, pages 49–56,
2026
-
[3]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review arXiv
-
[4]
arXiv preprint arXiv:2307.08701 , year=
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, et al. Alpagasus: Training a better alpaca with fewer data.arXiv preprint arXiv:2307.08701, 2023a. Xiangyi Chen, Sijia Liu, Ruoyu Sun, and Mingyi Hong. On the convergence of a class of adam-type algorithms for non-convex optimi...
-
[5]
Training Verifiers to Solve Math Word Problems
Ziang Chen, Jianfeng Lu, Huajie Qian, Xinshang Wang, and Wotao Yin. Hetersgd: Tackling heterogeneous sampling costs via optimal reweighted stochastic gradient descent. In Francisco Ruiz, Jennifer Dy, and Jan- Willem van de Meent, editors,Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of...
work page internal anchor Pith review arXiv
-
[6]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773,
work page internal anchor Pith review arXiv
-
[7]
Concise reasoning via reinforcement learning
MehdiFatemi, BanafshehRafiee, MingjieTang, andKartikTalamadupula. Concisereasoningviareinforcement learning.arXiv preprint arXiv:2504.05185,
-
[8]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347,
work page internal anchor Pith review arXiv
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
URLhttps://proceedings.mlr.press/v99/harvey19a.html. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review arXiv
-
[10]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms.arXiv preprint arXiv:2510.13786,
-
[11]
Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886, 2025
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886,
-
[12]
Penghui Qi, Zichen Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788,
-
[13]
Alexander Rakhlin, Ohad Shamir, and Karthik Sridharan. Making gradient descent optimal for strongly convex stochastic optimization.arXiv preprint arXiv:1109.5647,
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[16]
neurips.cc/paper_files/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf
URLhttps://proceedings. neurips.cc/paper_files/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf. Hemish Veeraboina. Aime problem set 1983-2024,
1999
-
[17]
Reinforcement learning for reasoning in large language models with one training example, 2025
URL https://www.kaggle.com/datasets/ hemishveeraboina/aime-problem-set-1983-2024. Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv:2504.20571,
-
[18]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Yixuan Even Xu, Yash Savani, Fei Fang, and Zico Kolter. Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning.arXiv preprint arXiv:2504.13818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
18 An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review arXiv
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review arXiv
-
[22]
Why gradient clipping accelerates training: A theoretical justification for adaptivity
URLhttps://arxiv.org/abs/1905.11881. Peilin Zhao and Tong Zhang. Stochastic optimization with importance sampling for regularized loss mini- mization. Ininternational conference on machine learning, pages 1–9. PMLR,
-
[23]
Haizhong Zheng, Yang Zhou, Brian R Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts.arXiv preprint arXiv:2506.02177,
-
[24]
Secrets of rlhf in large language models part i: Ppo.arXiv preprint arXiv:2307.04964, 2023
Rui Zheng, Shihan Dou, Songyang Gao, Yuan Hua, Wei Shen, Binghai Wang, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, et al. Secrets of rlhf in large language models part i: Ppo.arXiv preprint arXiv:2307.04964,
-
[25]
information density
Substituting the upper bound from Eq. (34) yields the condition: n∑ i=1 qi∆ 2 i≥G2 16.(35) Step 4: Optimizing the lower bound.From Eq. (35), any algorithm solving the problem must satisfy the information constraint∑n i=1qi∆ 2 i≥G2/16. Since the total expected query costC (under the mixture distributionD) is lower bounded by half times the expected cost un...
2013
-
[26]
We report Scale-RL hyperparameters in Table 5, largely influenced by the findings of [Khatri et al., 2025]. Hyperparameter Value Base ModelQwen/Qwen2.5-Math-1.5B-Instruct Algorithm GRPO Learning Rate1×10 −6 Weight Decay 0.1 Train Batch Size 256 Rollout Samples per Prompt (n) 16 Rollout Temperature 1.0 PPO Mini-Batch Size 64 KL Loss Coefficient 0.001 Clip ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.