Recognition: no theorem link
Towards Neuro-symbolic Causal Rule Synthesis, Verification, and Evaluation Grounded in Legal and Safety Principles
Pith reviewed 2026-05-12 05:31 UTC · model grok-4.3
The pith
A neuro-symbolic pipeline uses large language models to turn high-level human goals into minimal necessary and sufficient first-order logical rules that pass syntax, consistency, and safety checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
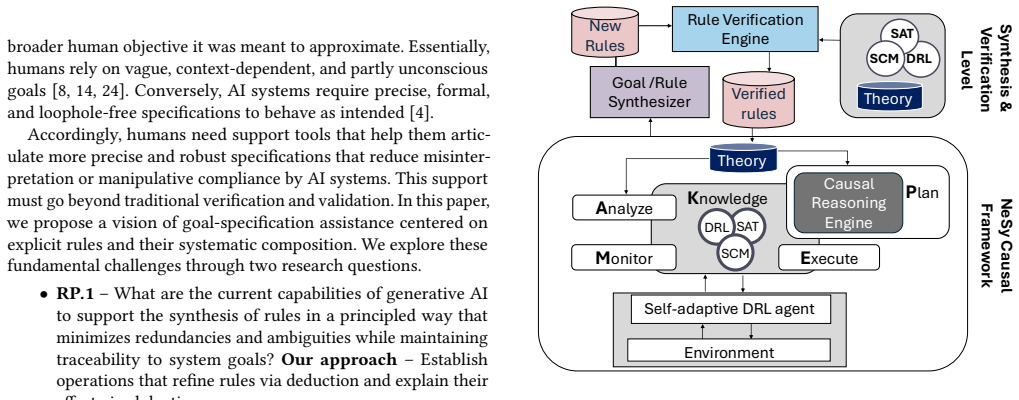
Given human-specified goals and principles, the pipeline can successfully derive minimal necessary and sufficient rule sets and formalize them as logical constraints. The synthesis pipeline employs large language models to decompose goals into candidate causes, consolidate semantics to remove redundancies, translate them into candidate first-order rules, and compose necessary and sufficient causal sets. The verification pipeline then performs syntax and schema validation, logical consistency analysis, and safety and invariant checks before integrating verified rules into the knowledge base. This process was shown to work in two autonomous driving scenarios.
What carries the argument
The meta-level layer consisting of a Goal/Rule Synthesizer that chains LLM steps for goal decomposition, semantic consolidation, first-order rule translation, and causal-set composition, together with a Rule Verification Engine that runs syntax validation, consistency analysis, and safety checks.
If this is right
- The pipeline supports incremental, modular, and traceable rule synthesis grounded in legal and safety principles.
- It mitigates goal misspecification that can produce reward hacking or verification failures.
- Verified rules can be integrated into an existing MAPE-K loop to enable explainable adaptations under distribution shifts.
- The same synthesis-plus-verification process can be repeated as new goals or principles are supplied by experts.
Where Pith is reading between the lines
- If the verification steps prove reliable, the same pipeline could be applied to other safety-critical domains such as medical protocols or financial compliance rules.
- Quantitative measurement of rule minimality and coverage in simulation could be added to strengthen the evaluation beyond the two qualitative driving cases.
- Linking the synthesized rules more tightly to the structural causal models already present in the framework might allow forward simulation of rule effects before deployment.
Load-bearing premise
Large language models can reliably decompose goals, remove semantic redundancies, and produce logically sound first-order rules without introducing errors that the subsequent verification steps fail to catch.
What would settle it
A new autonomous-driving scenario in which the pipeline outputs a rule set that violates a stated safety invariant or contains a logical inconsistency yet passes all three verification stages.
Figures


read the original abstract
Rule-based systems remain central in safety-critical domains but often struggle with scalability, brittleness, and goal misspecification. These limitations can lead to reward hacking and failures in formal verification, as AI systems tend to optimize for narrow objectives. In previous research, we developed a neuro-symbolic causal framework that integrates first-order logic abduction trees, structural causal models, and deep reinforcement learning within a MAPE-K loop to provide explainable adaptations under distribution shifts. In this paper, we extend that framework by introducing a meta-level layer designed to mitigate goal misspecification and support scalable rule maintenance. This layer consists of a Goal/Rule Synthesizer and a Rule Verification Engine, which iteratively refine a formal rule theory from high-level natural-language goals and principles provided by human experts. The synthesis pipeline employs large language models (LLMs) to: (1) decompose goals into candidate causes, (2) consolidate semantics to remove redundancies, (3) translate them into candidate first-order rules, and (4) compose necessary and sufficient causal sets. The verification pipeline then performs (1) syntax and schema validation, (2) logical consistency analysis, and (3) safety and invariant checks before integrating verified rules into the knowledge base. We evaluated our approach with a proof-of-concept implementation in two autonomous driving scenarios. Results indicate that, given human-specified goals and principles, the pipeline can successfully derive minimal necessary and sufficient rule sets and formalize them as logical constraints. These findings suggest that the pipeline supports incremental, modular, and traceable rule synthesis grounded in established legal and safety principles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the authors' prior neuro-symbolic causal framework (MAPE-K loop with FOL abduction trees, structural causal models, and deep RL) by adding a meta-level layer consisting of a Goal/Rule Synthesizer (LLM-driven decomposition of natural-language goals into candidate causes, redundancy removal, translation to FOL rules, and composition of necessary/sufficient sets) and a Rule Verification Engine (syntax/schema validation, logical consistency, safety/invariant checks). A proof-of-concept implementation is reported to successfully derive minimal necessary and sufficient rule sets formalized as logical constraints in two autonomous driving scenarios, grounded in legal and safety principles.
Significance. If the pipeline's reliability can be established with quantitative evidence, the work would contribute a modular, traceable method for mitigating goal misspecification in safety-critical rule-based systems, bridging LLM flexibility with formal verification and causal reasoning. This could support incremental rule maintenance in domains like autonomous driving where brittleness and reward hacking are concerns.
major comments (3)
- [Abstract / Evaluation] The abstract and evaluation claim that the pipeline 'can successfully derive' minimal necessary and sufficient rule sets in two scenarios, yet no quantitative metrics (e.g., success rates, number of rules generated per scenario, verification pass/fail rates, or error counts), failure cases, or baseline comparisons are reported. This renders the central empirical claim an unelaborated proof-of-concept without visible derivation details or statistics.
- [Rule Verification Engine] The Rule Verification Engine is described as performing logical consistency analysis and safety/invariant checks, but first-order logic consistency is undecidable in general. The manuscript provides no specification of the FOL fragment used, completeness proof, model-checking procedure, or tool (e.g., theorem prover) employed, leaving open whether the engine can reliably detect subtle causal or quantifier errors in LLM outputs.
- [Goal/Rule Synthesizer] The Goal/Rule Synthesizer relies on LLMs for goal decomposition, semantic consolidation, and FOL translation, with the claim that verification ensures soundness. However, no analysis or evidence is given on how post-hoc checks catch LLM-specific issues such as incorrect quantifier scope, missing edge cases, or causal misrepresentations, nor on redundancy removal producing true minimality (e.g., via counterfactual checks).
minor comments (1)
- [Abstract] The abstract would benefit from briefly naming the two autonomous driving scenarios and the high-level legal/safety principles used, to make the POC more concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript while remaining faithful to the proof-of-concept nature of the work.
read point-by-point responses
-
Referee: [Abstract / Evaluation] The abstract and evaluation claim that the pipeline 'can successfully derive' minimal necessary and sufficient rule sets in two scenarios, yet no quantitative metrics (e.g., success rates, number of rules generated per scenario, verification pass/fail rates, or error counts), failure cases, or baseline comparisons are reported. This renders the central empirical claim an unelaborated proof-of-concept without visible derivation details or statistics.
Authors: We agree that the evaluation section would benefit from greater elaboration to make the derivation process more transparent. In the revised manuscript we will expand the evaluation to report concrete details from the two autonomous-driving scenarios, including the number of candidate causes and rules generated by the LLM at each stage, the number retained after semantic consolidation, verification pass/fail counts for each check (syntax, consistency, safety/invariants), and any failure cases or edge cases observed during the runs. While the work remains a proof-of-concept and does not include formal baseline comparisons, we will add a brief discussion of how the pipeline could be compared against purely manual rule authoring or unverified LLM outputs in future extensions. revision: yes
-
Referee: [Rule Verification Engine] The Rule Verification Engine is described as performing logical consistency analysis and safety/invariant checks, but first-order logic consistency is undecidable in general. The manuscript provides no specification of the FOL fragment used, completeness proof, model-checking procedure, or tool (e.g., theorem prover) employed, leaving open whether the engine can reliably detect subtle causal or quantifier errors in LLM outputs.
Authors: The referee correctly notes that unrestricted FOL consistency is undecidable. Our implementation restricts the rule language to a decidable fragment consisting of Horn clauses with limited universal and existential quantification over a finite domain of objects and predicates relevant to the driving scenarios. We will revise the manuscript to (1) explicitly define this fragment, (2) describe the model-checking procedure that enumerates ground instances within the scenario bounds and uses an SMT solver (Z3) for satisfiability checks, and (3) list the concrete safety and invariant properties verified. We do not claim a completeness proof for arbitrary FOL; the checks are sound for the fragment and sufficient to catch the classes of LLM-induced errors encountered in our experiments (e.g., scope violations and contradictory literals). revision: yes
-
Referee: [Goal/Rule Synthesizer] The Goal/Rule Synthesizer relies on LLMs for goal decomposition, semantic consolidation, and FOL translation, with the claim that verification ensures soundness. However, no analysis or evidence is given on how post-hoc checks catch LLM-specific issues such as incorrect quantifier scope, missing edge cases, or causal misrepresentations, nor on redundancy removal producing true minimality (e.g., via counterfactual checks).
Authors: We acknowledge that the current text does not provide a detailed error-analysis of the LLM stage. In the revision we will add a subsection that walks through representative LLM outputs from the two scenarios, showing how syntax/schema validation and the subsequent consistency and safety checks caught specific issues such as incorrect quantifier scope and missing edge-case literals. For redundancy removal and minimality we will clarify that the consolidation step uses semantic similarity followed by logical entailment checks within the restricted fragment; we will note that this yields a minimal set relative to the provided goals and principles, while acknowledging that exhaustive counterfactual minimality testing lies outside the present proof-of-concept scope. revision: partial
Circularity Check
No significant circularity in neuro-symbolic causal rule synthesis pipeline
full rationale
The paper presents a system architecture extending prior work with a new meta-layer for LLM-assisted goal decomposition and rule synthesis, followed by verification steps, and demonstrates it in a proof-of-concept for two autonomous driving scenarios. The claimed success in deriving minimal necessary and sufficient rule sets is based on the empirical performance of this pipeline rather than any mathematical derivation or prediction that reduces to the inputs by construction. Although the authors reference their previous neuro-symbolic causal framework and MAPE-K loop, this serves as background for the extension and does not bear the load of the new results, which are independently evaluated. No self-definitional, fitted prediction, or other circular patterns are identified in the described process.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can decompose high-level goals into candidate causes, consolidate semantics, and translate them into first-order rules with sufficient accuracy for safety-critical use.
- domain assumption The verification engine's syntax, logical consistency, and safety/invariant checks are sufficient to guarantee that only correct rules enter the knowledge base.
invented entities (2)
-
Goal/Rule Synthesizer
no independent evidence
-
Rule Verification Engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Christian Medeiros Adriano, Sona Ghahremani, Finn Kaiser, and Holger Giese
-
[2]
In2025 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS)
Neuro-symbolic causal reasoning for cautious self-adaptation under distri- bution shifts. In2025 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS). IEEE, 88–99
- [3]
-
[4]
Alicia Aliseda. 2017. The Logic of Abduction: An Introduction. InSpringer Handbook of Model-Based Science. Springer, Cham, 1–24. Chapter on abduction and hypothesis generation
work page 2017
-
[5]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. 2016. Concrete Problems in AI Safety.arXiv preprint arXiv:1606.06565 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
HPI System Analysis and Modeling Group. 2026. Goal-Based Rule Synthesis. https://github.com/hpi-sam/goal-based-rule-synthesis. GitHub repository
work page 2026
-
[7]
Christoph Beierle, Lars-Phillip Spiegel, Jonas Haldimann, Marco Wilhelm, Jesse Heyninck, and Gabriele Kern-Isberner. 2024. Conditional splittings of belief bases and nonmonotonic inference with c-representations. InProceedings of the 21st International Conference on Principles of Knowledge Representation and Reasoning (Hanoi, Vietnam)(KR ’24). Article 10,...
-
[8]
Sascha Brodsky. 2025. The mathematicians teaching AI to reason.IBM Think (October 2025). https://www.ibm.com/think/news/mathematicians-teaching-ai- to-reason Published 13 October 2025, updated 23 October 2025
work page 2025
-
[9]
Jaime J Castrellon, Jacob S Young, Linh C Dang, Christopher T Smith, Ronald L Cowan, David H Zald, and Gregory R Samanez-Larkin. 2021. Dopamine biases sensitivity to personal goals and social influence in self-control over everyday desires.bioRxiv(2021), 2021–09
work page 2021
-
[10]
Erika F. de Almeida, Marcio V. Vieira, and Rogério de Lemos. 2017. MAPE- K based guidelines for designing reactive and proactive self-adaptive systems. InProceedings of the 12th International Symposium on Software Engineering for Adaptive and Self-Managing Systems. IEEE, 97–107
work page 2017
-
[11]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An efficient SMT solver. In International conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 337–340
work page 2008
-
[12]
Thomas Eiter, Michael Fink, Giovambattista Ianni, Thomas Krennwallner, Christoph Redl, and Peter Schüller. 2016. A model building framework for answer set programming with external computations.Theory and Practice of Logic Programming16, 4 (2016), 418–464
work page 2016
-
[13]
Klemens Esterle, Luis Gressenbuch, and Alois Knoll. 2020. Formalizing Traffic Rules for Machine Interpretability. InProceedings of the 3rd IEEE Connected and Automated Vehicles Symposium (CA VS). Institute of Electrical and Electronics Engineers (IEEE), Victoria, B.C., Canada. https://doi.org/10.1109/CAVS51000.20 20.9334599
- [14]
-
[15]
Klaus Fiedler and Mandy Hütter. 2014. The Limits of Human Information Process- ing in Goal Pursuit: Motivational Influences on Judgment and Decision Making. Current Directions in Psychological Science23, 3 (2014), 163–170
work page 2014
-
[16]
Sona Ghahremani, Christian Medeiros Adriano, and Holger Giese. 2018. Training Prediction Models for Rule-Based Self-Adaptive Systems. InInternational Confer- ence on Autonomic Computing (ICAC). 187–192. https://doi.org/10.1109/ICAC.2 018.00031
-
[17]
Sona Ghahremani and Holger Giese. 2021. Hybrid planning with receding hori- zon: A case for meta-self-awareness. In2021 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C). IEEE, 131–138
work page 2021
-
[18]
Omid Gheibi and Danny Weyns. 2024. Dealing with Drift of Adaptation Spaces in Learning-based Self-Adaptive Systems Using Lifelong Self-Adaptation.ACM Trans. Auton. Adapt. Syst.19, 1, Article 5 (feb 2024), 57 pages. https://doi.org/10 .1145/3636428
work page 2024
-
[19]
Omid Gheibi, Danny Weyns, and Federico Quin. 2021. Applying machine learning in self-adaptive systems: A systematic literature review.ACM Transactions on Autonomous and Adaptive Systems (TAAS)15, 3 (2021), 1–37
work page 2021
-
[20]
David Perry Greene. 1987. Automated knowledge acquisition: Overcoming the expert system bottleneck. InProceedings of the Eighth International Conference on Information Systems (ICIS 1987). Association for Information Systems, 155–167
work page 1987
-
[21]
Joachim Haensel, Christian Medeiros Adriano, Johannes Dyck, and Holger Giese
-
[22]
Collective risk minimization via a bayesian model for statistical software testing. InProceedings of the IEEE/ACM 15th International Symposium on Software Engineering for Adaptive and Self-Managing Systems(Seoul, Republic of Korea) (SEAMS ’20). ACM, 45–56. https://doi.org/10.1145/3387939.3388616
-
[23]
Frederick Hayes-Roth. 1983. Rule-based systems.Commun. ACM26, 9 (1983), 921–932
work page 1983
- [24]
-
[25]
P Hitzler, MK Sarker, TR Besold, AD Garcez, S Bader, H Bowman, P Domingos, KU Kühnberger, LC Lamb, et al. 2022. Neural-symbolic learning and reasoning: A survey and interpretation.Frontiers in artificial intelligence and applications 342 (2022), 1–51
work page 2022
-
[26]
Yi-Fei Hu, Joseph Heffner, Apoorva Bhandari, and Oriel FeldmanHall. 2025. Goals bias face perception.Journal of Experimental Psychology: General(2025)
work page 2025
-
[27]
Utkarshani Jaimini, Cory Henson, and Amit Sheth. 2024. Causal neuro-symbolic AI for root cause analysis in smart manufacturing. InInternational Semantic Web Conference
work page 2024
-
[28]
Jeffrey O. Kephart and David M. Chess. 2003. The Vision of Autonomic Computing. Computer36, 1 (2003), 41–50
work page 2003
-
[29]
Gabriele Kern-Isberner, Christoph Beierle, and Gerhard Brewka. 2020. Syntax Splitting = Relevance + Independence: New Postulates for Nonmonotonic Rea- soning From Conditional Belief Bases. InProceedings of the 17th International Conference on Principles of Knowledge Representation and Reasoning. 560–571. https://doi.org/10.24963/kr.2020/56
-
[30]
Kathrin Korte, Christian Medeiros Adriano, Sona Ghahremani, and Holger Giese
-
[31]
Causal knowledge transfer for multi-agent reinforcement learning in dynamic environments. In2025 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C). IEEE, 154–159
-
[32]
Douglas B Lenat, Mayank Prakash, and Mary Shepherd. 1990. CYC: Using common sense knowledge to overcome brittleness and knowledge acquisition bottlenecks.AI Magazine11, 2 (1990), 65–85
work page 1990
-
[33]
LessWrong Community. 2023. AI Safety 101: Reward Misspecification. https: //www.lesswrong.com/posts/mMBoPnFrFqQJKzDsZ/ai-safety-101-reward- misspecification. Accessed 2026-02-12
work page 2023
-
[34]
Hu Liu, Alexander Gegov, and Mihaela Cocea. 2016. Rule-based systems: a granular computing perspective.Granular Computing1, 4 (2016), 259–274
work page 2016
-
[35]
Yuchen Liu, Luigi Palmieri, Sebastian Koch, Ilche Georgievski, and Marco Aiello
-
[36]
In2025 IEEE International Conference on Robotics and Automation (ICRA)
Delta: Decomposed efficient long-term robot task planning using large lan- guage models. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 10995–11001
-
[37]
Adithya Murali, Lucas Peña, Christof Löding, and P. Madhusudan. 2023. A First- order Logic with Frames.ACM Trans. Program. Lang. Syst.45, 2, Article 7 (May 2023), 44 pages. https://doi.org/10.1145/3583057
-
[38]
Mark A Musen. 1989. Automating knowledge acquisition for expert systems. Methods of Information in Medicine28, 4 (1989), 237–244
work page 1989
-
[39]
2006.Modular Answer Set Programming
Emilia Oikarinen. 2006.Modular Answer Set Programming. Technical Report Research Report A106. Helsinki University of Technology, Laboratory for Theo- retical Computer Science
work page 2006
-
[40]
OpenAI. 2025. OpenAI developer platform. https://platform.openai.com/ Last visited 16.05.2025
work page 2025
-
[41]
Gabriele Paul. 1993. Approaches to abductive reasoning: an overview.Artificial intelligence review7, 2 (1993), 109–152
work page 1993
-
[42]
2008.Statistical Relational Learning and Inductive Logic Programming
Luc De Raedt and Kristian Kersting. 2008.Statistical Relational Learning and Inductive Logic Programming. Springer, Berlin. Bridging statistical learning and symbolic rule induction
work page 2008
-
[43]
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. Defining and characterizing reward gaming.Advances in Neural Information Processing Systems35 (2022), 9460–9471
work page 2022
- [44]
-
[45]
Lilian Weng. 2024. Reward Hacking in Reinforcement Learning. https://lilianwe ng.github.io/posts/2024-11-28-reward-hacking/. Accessed 2026-02-12
work page 2024
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.