Recognition: unknown
Beyond Gaussian Bottlenecks: Topologically Aligned Encoding of Vision-Transformer Feature Spaces
Pith reviewed 2026-05-07 07:45 UTC · model grok-4.3
The pith
A variational autoencoder using products of Power Spherical distributions preserves 3D geometry from vision transformers better than Gaussian bottlenecks under high compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
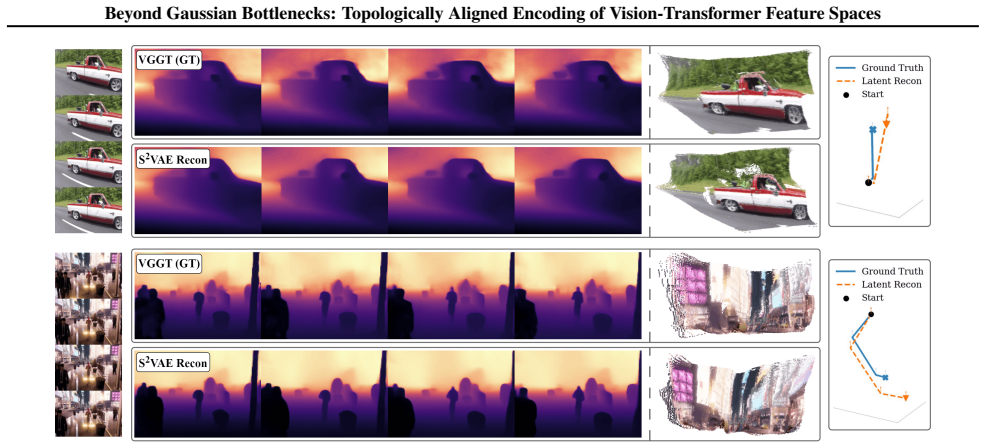
By constructing the latent space as a product of Power Spherical distributions on top of VGGT features, S²VAE produces compressed representations that maintain directional semantics and 3D geometric fidelity more effectively than conventional Gaussian bottlenecks. This leads to measurable improvements in depth prediction, pose estimation, and point-cloud reconstruction, with the largest gains appearing in high-compression regimes where standard Euclidean latents degrade.
What carries the argument
The product of Power Spherical distributions, which enforces hyperspherical geometry in the latent bottleneck to preserve directional and geometric semantics from VGGT features.
Load-bearing premise
The product of Power Spherical distributions preserves directional and geometric semantics from VGGT features under strong compression, and any performance gains are due to this topological alignment rather than other implementation details.
What would settle it
Re-running the depth, pose, and reconstruction experiments with the Power Spherical distributions replaced by Gaussians while keeping every other component identical, and finding no performance gap in the high-compression regime, would falsify the claim that hyperspherical alignment is responsible for the observed improvements.
Figures








read the original abstract
Modern visual world modeling systems increasingly rely on high-capacity architectures and large-scale data to produce plausible motion, yet they often fail to preserve underlying 3D geometry or physically consistent camera dynamics. A key limitation lies not only in model capacity, but in the latent representations used to encode geometric structure. We propose S$^2$VAE, a geometry-first latent learning framework that focuses on compressing and representing the latent 3D state of a scene, including camera motion, depth, and point-level structure, rather than modeling appearance alone. Building on representations from a Visual Geometry Grounded Transformer (VGGT), we introduce a novel type of variational autoencoder using a product of Power Spherical latent distributions, explicitly enforcing hyperspherical structure in the bottleneck to preserve directional and geometric semantics under strong compression. Across depth estimation, camera pose recovery, and point cloud reconstruction, we show that geometry-aligned hyperspherical latents consistently outperform conventional Gaussian bottlenecks, particularly in high-compression regimes. Our results highlight latent geometry as a first-class design choice for physically grounded visual and world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes S²VAE, a variational autoencoder that encodes VGGT features using a product of Power Spherical distributions in the latent bottleneck to enforce hyperspherical structure and preserve directional geometric semantics (depth, camera pose, point clouds) under compression. It claims consistent outperformance over standard Gaussian VAEs across depth estimation, pose recovery, and point-cloud reconstruction, with particular gains in high-compression regimes.
Significance. If the reported gains can be isolated to the choice of latent family rather than upstream features or training details, the work would usefully highlight latent topology as a first-class design choice for geometric vision models, potentially influencing how directional inductive biases are incorporated in world-modeling architectures.
major comments (2)
- [Experimental Evaluation] The central claim attributes performance gains specifically to the product-of-Power-Spherical bottleneck preserving geometry. No ablation is described that holds the VGGT encoder, compression schedule, reconstruction losses, and optimization fixed while swapping only the latent distribution family (Gaussian vs. product of Power Spherical). Without this isolation, the topological-alignment explanation remains untested.
- [Abstract] The abstract states that geometry-aligned hyperspherical latents 'consistently outperform' Gaussian bottlenecks but supplies no quantitative metrics, baseline tables, error measures (e.g., AbsRel, RMSE for depth; rotation/translation error for pose), number of runs, or statistical tests. This information is load-bearing for evaluating the magnitude and reliability of the claimed improvements.
minor comments (2)
- [Method] The notation for the product of Power Spherical distributions would benefit from an explicit density formula and a clear statement of how concentration parameters are learned or fixed.
- [Figures] Figure captions and axis labels in the results section should explicitly state the compression ratio or latent dimensionality used in each high-compression regime comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important aspects of experimental rigor and clarity that we will address in the revision. Below we respond point by point.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central claim attributes performance gains specifically to the product-of-Power-Spherical bottleneck preserving geometry. No ablation is described that holds the VGGT encoder, compression schedule, reconstruction losses, and optimization fixed while swapping only the latent distribution family (Gaussian vs. product of Power Spherical). Without this isolation, the topological-alignment explanation remains untested.
Authors: We agree that a controlled ablation isolating only the latent distribution family is necessary to substantiate the claim that gains arise from the hyperspherical topology rather than other factors. The current manuscript compares S²VAE against a Gaussian VAE baseline using the same VGGT features and reconstruction objectives, but does not explicitly freeze every other hyper-parameter and training detail. In the revised version we will add a dedicated ablation subsection that trains both models with identical VGGT encoder weights, identical compression ratios, identical reconstruction losses, and identical optimization settings, differing solely in the choice of latent distribution (standard Gaussian versus product of Power Spherical). This will directly test the topological-alignment hypothesis. revision: yes
-
Referee: [Abstract] The abstract states that geometry-aligned hyperspherical latents 'consistently outperform' Gaussian bottlenecks but supplies no quantitative metrics, baseline tables, error measures (e.g., AbsRel, RMSE for depth; rotation/translation error for pose), number of runs, or statistical tests. This information is load-bearing for evaluating the magnitude and reliability of the claimed improvements.
Authors: We accept that the abstract should contain concrete quantitative evidence. In the revision we will expand the abstract to report the principal metrics: absolute relative error (AbsRel) and RMSE for depth estimation, rotation and translation errors for camera pose recovery, and Chamfer distance or similar for point-cloud reconstruction. We will also state the number of independent runs and note any statistical significance tests performed. These numbers will be drawn from the results already presented in the experimental section. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent task evaluations
full rationale
The paper introduces S²VAE as a modeling choice (product of Power Spherical distributions on VGGT features) and validates it via direct empirical comparisons against Gaussian baselines on depth estimation, pose recovery, and point-cloud reconstruction. No derivation chain is presented that reduces a claimed result to fitted parameters or self-citations by construction. The performance gains are reported as experimental outcomes rather than predictions forced by the model definition itself. VGGT is used as an upstream feature source; any self-citation to it is not load-bearing for the bottleneck comparison, which is isolated in the reported experiments. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Concentration parameters of the Power Spherical distributions
axioms (2)
- standard math The product of Power Spherical distributions constitutes a valid probability distribution suitable for the VAE bottleneck.
- domain assumption VGGT features already encode camera motion, depth, and point-level structure.
invented entities (2)
-
S²VAE
no independent evidence
-
Product of Power Spherical latent distributions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
H., Bond, A., Karacan, L., Birdal, T., Erdem, E., Ceylan, D., and Erdem, A
Ali, M. H., Bond, A., Karacan, L., Birdal, T., Erdem, E., Ceylan, D., and Erdem, A. Vidstyleode: Disen- tangled video editing via stylegan and neuralodes. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 7489–7500. IEEE, October
2023
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
doi: 10.1109/iccv51070.2023.00692. URL http://dx. doi.org/10.1109/iccv51070.2023.00692. Calvo-Gonz´alez, R. and Fleuret, F. Laminating representa- tion autoencoders for efficient diffusion.arXiv preprint arXiv:2602.04873,
-
[3]
R., Falorsi, L., De Cao, N., Kipf, T., and Tom- czak, J
Davidson, T. R., Falorsi, L., De Cao, N., Kipf, T., and Tom- czak, J. M. Hyperspherical variational auto-encoders. In34th Conference on Uncertainty in Artificial Intelli- gence 2018, UAI 2018, pp. 856–865. Association For Uncertainty in Artificial Intelligence (AUAI),
2018
-
[4]
De Cao, N. and Aziz, W. The power spherical distribution. arXiv preprint arXiv:2006.04437,
-
[5]
How contextual are contextualized word rep- resentations? comparing the geometry of bert, elmo, and gpt-2 embeddings
Ethayarajh, K. How contextual are contextualized word rep- resentations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 55–65,
2019
-
[6]
R., De Cao, N., Weiler, M., Forr´e, P., and Cohen, T
Falorsi, L., De Haan, P., Davidson, T. R., De Cao, N., Weiler, M., Forr´e, P., and Cohen, T. S. Explorations in homeomorphic variational auto-encoding.arXiv preprint arXiv:1807.04689,
-
[7]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.CoRR, abs/1312.6114,
work page internal anchor Pith review arXiv
-
[8]
On the sentence embeddings from pre-trained language mod- els
Li, B., Zhou, H., He, J., Wang, M., Yang, Y ., and Li, L. On the sentence embeddings from pre-trained language mod- els. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pp. 9119–9130,
2020
-
[9]
Styleclip: Text-driven manipulation of stylegan imagery
Patashnik, O., Wu, Z., Shechtman, E., Cohen-Or, D., and Lischinski, D. Styleclip: Text-driven manipulation of stylegan imagery. InProceedings of the IEEE/CVF inter- national conference on computer vision, pp. 2085–2094,
2085
-
[10]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., and Xie, S. Diffusion trans- formers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025a. Zheng, G., Li, T., Zhou, X., and Li, X. Realcam- vid: High-resolution video dataset with dynamic scenes and metric-scale camera movements.arXiv preprint arXiv:2504.08212, 2025b. Zhou, K., Wang, Y ., Chen, G., Chang, X....
work page internal anchor Pith review arXiv
-
[11]
To do this, the CLIP model has two separate encoders (one for images, one for text)
is a widely used text-image model, trained on unifying image and text representations in a single latent space. To do this, the CLIP model has two separate encoders (one for images, one for text). However, the text encoder is the most widely used, found in a wide range of generative models (Patashnik et al., 2021; Ali et al., 2023; Rombach et al., 2022), ...
2021
-
[12]
We seek to understand how well our V AE architecture is able to reconstruct the CLIP textual features and apply them for a downstream task
and open-vocabulary segmentation (Kirillov et al., 2023). We seek to understand how well our V AE architecture is able to reconstruct the CLIP textual features and apply them for a downstream task. Specifically, we want to use these reconstructed textual features for text-to-image generation, via the Stable Diffusion (Rombach et al.,
2023
-
[13]
Thus, this is again a very different training objective than DINO or VGGT
backbone, a self-supervised ViT trained on the masked image modeling objective to understand 3d geometry. Thus, this is again a very different training objective than DINO or VGGT. To test our reconstruction quality on the DUSt3R model, we focus on reconstructing the features of the CroCo backbone. Specifically, we take two images of a scene, and pass the...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.