Recognition: unknown
Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for AI Scientists
Pith reviewed 2026-05-07 06:37 UTC · model grok-4.3
The pith
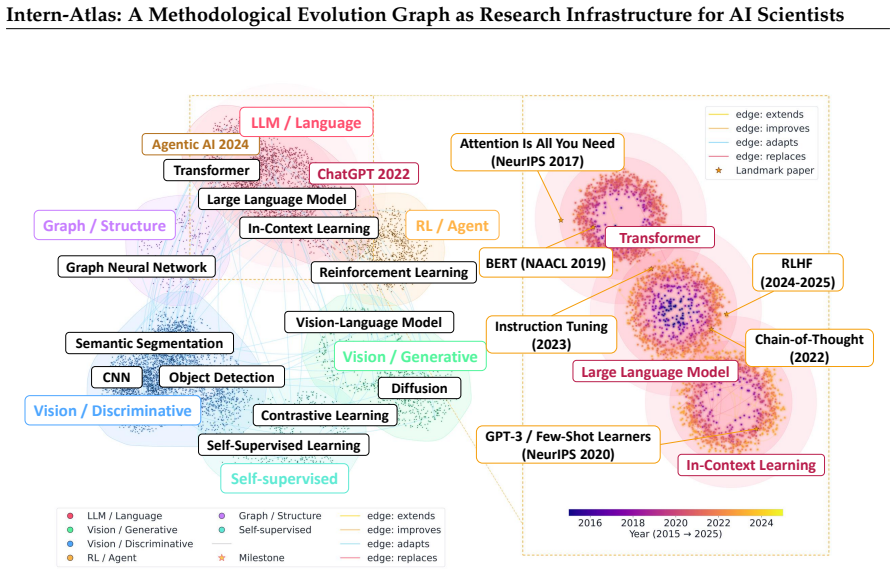
Intern-Atlas constructs a queryable graph of methodological evolution from over a million papers to represent how AI methods develop through lineages and bottlenecks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that processing the text of 1,030,314 AI papers to identify method-level entities and infer lineage and bottleneck relationships produces a methodological evolution graph with 9,410,201 semantically typed edges grounded in verbatim source evidence. This forms a queryable causal network of methodological development. A self-guided temporal tree search algorithm constructs evolution chains that show strong alignment with expert-curated ground truth. The graph further enables downstream uses in idea evaluation and automated idea generation, serving as foundational infrastructure for automated scientific discovery.
What carries the argument
The methodological evolution graph, which extracts method entities from paper text and infers their lineage relationships together with the bottlenecks that drive transitions between methods.
If this is right
- AI-driven research agents can traverse explicit topologies of method evolution instead of reconstructing them from unstructured paper text.
- The graph directly supports practical tasks such as evaluating proposed research ideas and generating new ideas automatically.
- Methodological progress becomes queryable as a causal network where each connection carries verbatim evidence from the original papers.
- Evolution chains that trace how methods advance over time can be built using the self-guided temporal tree search algorithm.
- Methodological evolution graphs provide a foundational data layer for systems that perform automated scientific discovery.
Where Pith is reading between the lines
- The same extraction approach could be extended to non-AI scientific fields to map how methods transfer or diverge across domains.
- If the graph accurately captures bottlenecks, it could surface previously unnoticed patterns in where research tends to stall or accelerate.
- AI agents might eventually query the network to propose the next method in a lineage based on recurring bottleneck types.
- Combining the evolution graph with existing citation networks would link document influence to method-level development paths.
Load-bearing premise
Large-scale natural language processing can accurately identify method entities and correctly infer their lineage and bottleneck relationships from the raw text of research papers.
What would settle it
Expert review of a sample of the graph's inferred lineages and bottlenecks that reveals frequent inaccuracies or mismatches with actual methodological history.
Figures




read the original abstract
Existing research infrastructure is fundamentally document-centric, providing citation links between papers but lacking explicit representations of methodological evolution. In particular, it does not capture the structured relationships that explain how and why research methods emerge, adapt, and build upon one another. With the rise of AI-driven research agents as a new class of consumers of scientific knowledge, this limitation becomes increasingly consequential, as such agents cannot reliably reconstruct method evolution topologies from unstructured text. We introduce Intern-Atlas, a methodological evolution graph that automatically identifies method-level entities, infers lineage relationships among methodologies, and captures the bottlenecks that drive transitions between successive innovations. Built from 1,030,314 papers spanning AI conferences, journals, and arXiv preprints, the resulting graph comprises 9,410,201 semantically typed edges, each grounded in verbatim source evidence, forming a queryable causal network of methodological development. To operationalize this structure, we further propose a self-guided temporal tree search algorithm for constructing evolution chains that trace the progression of methods over time. We evaluate the quality of the resulting graph against expert-curated ground-truth evolution chains and observe strong alignment. In addition, we demonstrate that Intern-Atlas enables downstream applications in idea evaluation and automated idea generation. We position methodological evolution graphs as a foundational data layer for the emerging automated scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Intern-Atlas, a methodological evolution graph automatically constructed from 1,030,314 AI papers. The graph identifies method-level entities, infers directed lineage relationships and bottlenecks driving transitions, and contains 9,410,201 semantically typed edges each grounded in verbatim source text. It further proposes a self-guided temporal tree search algorithm to trace method evolution chains over time. The graph is evaluated against expert-curated ground-truth evolution chains with reported strong alignment and is demonstrated for downstream uses in idea evaluation and automated idea generation, positioning it as foundational infrastructure for AI-driven scientific discovery.
Significance. If the core extraction and inference pipeline achieves high accuracy, Intern-Atlas would represent a meaningful advance in research infrastructure by shifting from document-centric citation graphs to a queryable causal network of methodological development. The scale (over 9 million grounded edges) and the explicit support for AI research agents are notable strengths. However, the current lack of quantitative validation metrics for entity recognition, relation extraction, and bias analysis substantially weakens the ability to assess whether the claimed reliability holds at this scale.
major comments (3)
- [Abstract and Evaluation] Abstract and Evaluation section: The manuscript claims 'strong alignment' with expert-curated ground-truth evolution chains but reports no quantitative metrics (precision, recall, F1, or inter-annotator agreement) for method-entity identification or lineage/bottleneck inference. This is load-bearing for the central claim because every downstream application (temporal tree search, idea evaluation, automated generation) traverses the 9,410,201 edges; without corpus-wide error rates the 'grounded in verbatim source evidence' guarantee cannot be verified.
- [Methodology] Methodology section on inference rules: The rules used to infer directed lineage edges and bottleneck drivers are not shown to be independent of the same textual patterns employed to construct the graph. This creates a moderate circularity risk that could inflate alignment with expert-curated chains, which themselves may rely on similar surface patterns; a concrete test (e.g., held-out manual annotation of 500 random edges with reported precision/recall) is required.
- [Corpus and Data] Corpus construction and bias analysis: No analysis is provided of systematic biases in the 1,030,314-paper corpus (subfield skew, citation-popularity bias, or selection effects from conference/journal/arXiv sources). Because the graph is positioned as a general 'research infrastructure for AI scientists,' unquantified biases directly undermine claims that the extracted methodological evolution is representative.
minor comments (3)
- [Abstract] The abstract would benefit from a concise statement of the specific NLP models, thresholds, or heuristics used for entity segmentation and relation inference to support reproducibility.
- [Presentation] Include at least one concrete example (figure or table) showing a short evolution chain, the verbatim source sentences, and the extracted entities/edges to illustrate the grounding claim.
- [Notation] Clarify the exact definition of 'semantically typed edges' and provide the ontology or typology used for edge labels.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the validation and transparency of Intern-Atlas. We address each major comment point by point below, committing to revisions that directly respond to the concerns raised while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The manuscript claims 'strong alignment' with expert-curated ground-truth evolution chains but reports no quantitative metrics (precision, recall, F1, or inter-annotator agreement) for method-entity identification or lineage/bottleneck inference. This is load-bearing for the central claim because every downstream application (temporal tree search, idea evaluation, automated generation) traverses the 9,410,201 edges; without corpus-wide error rates the 'grounded in verbatim source evidence' guarantee cannot be verified.
Authors: We agree that quantitative metrics are necessary to rigorously support the 'strong alignment' observation and to allow readers to assess reliability for downstream uses. The current manuscript presents the alignment qualitatively against expert-curated chains. In the revised version, we will expand the Evaluation section to include precision, recall, and F1 scores for method-entity identification and lineage/bottleneck inference, computed against the ground-truth chains. We will also report inter-annotator agreement on the expert annotations and discuss sampled error rates with implications for the 9.4 million edges and applications such as temporal tree search. revision: yes
-
Referee: [Methodology] Methodology section on inference rules: The rules used to infer directed lineage edges and bottleneck drivers are not shown to be independent of the same textual patterns employed to construct the graph. This creates a moderate circularity risk that could inflate alignment with expert-curated chains, which themselves may rely on similar surface patterns; a concrete test (e.g., held-out manual annotation of 500 random edges with reported precision/recall) is required.
Authors: We take the circularity concern seriously. The inference rules target explicit textual signals of lineage and bottlenecks (e.g., phrases indicating adaptation or replacement), which are distinct from the entity extraction patterns. Nevertheless, to provide concrete evidence of independence, the revised manuscript will include a held-out manual annotation study on 500 randomly sampled edges. We will report precision and recall for the inferred relations, describe the annotation protocol, and discuss how this mitigates risks of inflated alignment with expert-curated chains. revision: yes
-
Referee: [Corpus and Data] Corpus construction and bias analysis: No analysis is provided of systematic biases in the 1,030,314-paper corpus (subfield skew, citation-popularity bias, or selection effects from conference/journal/arXiv sources). Because the graph is positioned as a general 'research infrastructure for AI scientists,' unquantified biases directly undermine claims that the extracted methodological evolution is representative.
Authors: We acknowledge that positioning Intern-Atlas as general infrastructure requires explicit discussion of corpus limitations. The 1,030,314-paper corpus draws from major AI conferences, journals, and arXiv to achieve broad coverage. In the revision, we will add a dedicated subsection under Corpus Construction that quantifies subfield distributions, analyzes citation-popularity skew, and examines selection effects across sources. We will also articulate limitations and potential mitigation strategies for users, ensuring the representativeness claims are appropriately caveated. revision: yes
Circularity Check
No significant circularity: graph construction derives from external corpus and independent expert evaluation.
full rationale
The paper's central derivation extracts method entities, lineages, and bottlenecks from a large external corpus of 1,030,314 AI papers via automated NLP, then evaluates the resulting 9.4M-edge graph against separately curated expert ground-truth evolution chains. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided description; the inference pipeline operates on verbatim source text as input and produces a queryable structure as output without reducing the claimed result to its own construction rules by definition. The process remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- thresholds and heuristics for method entity identification and relationship inference
axioms (1)
- domain assumption Scientific papers contain sufficient explicit textual signals to identify distinct methods and infer their evolutionary relationships and driving bottlenecks
Reference graph
Works this paper leans on
-
[1]
Google scholar.https://scholar.google.com
-
[2]
Construction of the literature graph in semantic scholar
Waleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Crawford, Doug Downey, Jason Dunkelberger, Ahmed Elgohary, Sergey Feldman, Vu Ha, et al. Construction of the literature graph in semantic scholar. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo...
2018
-
[3]
Jason Priem, Heather Piwowar, and Richard Orr. Openalex: A fully-open index of scholarly works, authors, venues, institutions, and concepts.arXiv preprint arXiv:2205.01833, 2022
-
[4]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Spark: A system for scientifically creative idea generation.arXiv preprint arXiv:2504.20090, 2025
Aishik Sanyal, Samuel Schapiro, Sumuk Shashidhar, Royce Moon, Lav R Varshney, and Dilek Hakkani-Tur. Spark: A system for scientifically creative idea generation.arXiv preprint arXiv:2504.20090, 2025
-
[6]
Deepinnovator: Triggering the innovative capabilities of llms.arXiv preprint arXiv:2602.18920, 2026
Tianyu Fan, Fengji Zhang, Yuxiang Zheng, Bei Chen, Xinyao Niu, Chengen Huang, Junyang Lin, and Chao Huang. Deepinnovator: Triggering the innovative capabilities of llms.arXiv preprint arXiv:2602.18920, 2026
-
[7]
The protein data bank.Nucleic acids research, 28(1):235–242, 2000
Helen M Berman, John Westbrook, Zukang Feng, Gary Gilliland, Talapady N Bhat, Helge Weissig, Ilya N Shindyalov, and Philip E Bourne. The protein data bank.Nucleic acids research, 28(1):235–242, 2000
2000
-
[8]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
2021
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[10]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[11]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[12]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[13]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[14]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[15]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Un- terthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[16]
Transformers in vision: A survey.ACM computing surveys (CSUR), 54(10s):1–41, 2022
Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey.ACM computing surveys (CSUR), 54(10s):1–41, 2022
2022
-
[17]
A survey on vision transformer.IEEE transactions on pattern analysis and machine intelligence, 45(1):87–110, 2022
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, et al. A survey on vision transformer.IEEE transactions on pattern analysis and machine intelligence, 45(1):87–110, 2022
2022
-
[18]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020. 13 Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for AI Scientists
2020
-
[19]
Connectivity in a citation network: The development of dna theory.Social networks, 11(1):39–63, 1989
Norman P Hummon and Patrick Dereian. Connectivity in a citation network: The development of dna theory.Social networks, 11(1):39–63, 1989
1989
-
[20]
Chaomei Chen. Citespace ii: Detecting and visualizing emerging trends and transient patterns in scientific literature.Journal of the American Society for information Science and Technology, 57(3):359–377, 2006
2006
-
[21]
S2orc: The semantic scholar open research corpus
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel S Weld. S2orc: The semantic scholar open research corpus. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4969–4983, 2020
2020
-
[22]
Nanoresearch, 2026
OpenRaiser. Nanoresearch, 2026
2026
-
[23]
Si, C., Hashimoto, T., and Yang, D
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers.arXiv preprint arXiv:2409.04109, 2024
-
[24]
Alina Beygelzimer, Yann N Dauphin, Percy Liang, and Jennifer Wortman Vaughan. Has the machine learning review process become more arbitrary as the field has grown? the neurips 2021 consistency experiment. arXiv preprint arXiv:2306.03262, 2023
-
[25]
Chris Latimer, Nicoló Boschi, Andrew Neeser, Chris Bartholomew, Gaurav Srivastava, Xuan Wang, and Naren Ramakrishnan. Hindsight is 20/20: Building agent memory that retains, recalls, and reflects.arXiv preprint arXiv:2512.12818, 2025
-
[26]
Xuemei Gu and Mario Krenn. Interesting scientific idea generation using knowledge graphs and llms: Evaluations with 100 research group leaders.arXiv:2405.17044, 2024
-
[27]
Ai idea bench 2025: Ai research idea generation benchmark.arXiv preprint arXiv:2504.14191, 2025
Yansheng Qiu, Haoquan Zhang, Zhaopan Xu, Ming Li, Diping Song, Zheng Wang, and Kaipeng Zhang. Ai idea bench 2025: Ai research idea generation benchmark.arXiv preprint arXiv:2504.14191, 2025
-
[28]
Ideabench: Benchmarking large language models for research idea generation
Sikun Guo, Amir Hassan Shariatmadari, Guangzhi Xiong, Albert Huang, Myles Kim, Corey M Williams, Stefan Bekiranov, and Aidong Zhang. Ideabench: Benchmarking large language models for research idea generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5888–5899, 2025
2025
-
[29]
Chenglei Si, Tatsunori Hashimoto, and Diyi Yang. The ideation-execution gap: Execution outcomes of llm-generated versus human research ideas.arXiv preprint arXiv:2506.20803, 2025
-
[30]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
International Conference on Learning Representations (ICLR) , year =
Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. Cycleresearcher: Improving automated research via automated review.arXiv preprint arXiv:2411.00816, 2024
-
[32]
Dolphin: Closed-loop open-ended auto-research through thinking, practice, and feedback.arXiv e-prints, pages arXiv–2501, 2025
Jiakang Yuan, Xiangchao Yan, Botian Shi, Tao Chen, Wanli Ouyang, Bo Zhang, Lei Bai, Yu Qiao, and Bowen Zhou. Dolphin: Closed-loop open-ended auto-research through thinking, practice, and feedback.arXiv e-prints, pages arXiv–2501, 2025
2025
-
[33]
Zijun Liu, Kaiming Liu, Yiqi Zhu, Xuanyu Lei, Zonghan Yang, Zhenhe Zhang, Peng Li, and Yang Liu. Aigs: Generating science from ai-powered automated falsification.arXiv preprint arXiv:2411.11910, 2024
-
[34]
Long Li, Weiwen Xu, Jiayan Guo, Ruochen Zhao, Xingxuan Li, Yuqian Yuan, Boqiang Zhang, Yuming Jiang, Yifei Xin, Ronghao Dang, et al. Chain of ideas: Revolutionizing research via novel idea development with llm agents.arXiv preprint arXiv:2410.13185, 2024
-
[35]
Xiang Hu, Hongyu Fu, Jinge Wang, Yifeng Wang, Zhikun Li, Renjun Xu, Yu Lu, Yaochu Jin, Lili Pan, and Zhenzhong Lan. Nova: An iterative planning and search approach to enhance novelty and diversity of llm generated ideas.arXiv preprint arXiv:2410.14255, 2024
-
[36]
Scimon: Scientific inspiration machines optimized for novelty
Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. Scimon: Scientific inspiration machines optimized for novelty. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 279–299, 2024
2024
-
[37]
The probabilistic relevance framework: Bm25 and beyond.Found
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond.Found. Trends Inf. Retr., 3(4):333–389, April 2009. 14 Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for AI Scientists
2009
-
[38]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InEuropean conference on machine learning, pages 282–293. Springer, 2006
2006
-
[39]
GPT” matching inside “lgpto
Hao Liu, Zhengren Wang, Xi Chen, Zhiyu Li, Feiyu Xiong, Qinhan Yu, and Wentao Zhang. Hoprag: Multi- hop reasoning for logic-aware retrieval-augmented generation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 1897–1913, 2025. 15 Intern-Atlas: A Methodological Evolution Graph as Research Infrastructure for AI Scientists Append...
2025
-
[40]
NMR measures the fraction of survey methods matched to Intern-Atlas nodes
Static Graph Coverage.Given a survey-derived graph G∗ and Intern-Atlas graph G, we report Node Match Ratio (NMR), Edge Reachable Ratio (ERR), and Path Semantic Correctness (PSC). NMR measures the fraction of survey methods matched to Intern-Atlas nodes. ERR measures the fraction of reference edges that can be recovered as directed paths in G. PSC measures...
-
[41]
We report Node Recall (NR), Edge Recall (ER), and Chain Alignment Score (CAS)
Lineage Reconstruction.For each reference chain, every search method starts from the same seed and returns a candidate chain. We report Node Recall (NR), Edge Recall (ER), and Chain Alignment Score (CAS). NR measures how many reference methods are recovered. ER measures how many adjacent reference transitions are recovered. CAS measures how well the retri...
2026
-
[42]
In retrieval-augmented generation
All texts and metadata were obtained from OpenReview and publicly available proceedings. Venue and outcome labels are used only for aggregate analysis and are not provided to the evaluator. Human-Rated Subset.For human-alignment evaluation, we sample 100 idea profiles from the Strata Dataset and ask 10 AI PhD researchers to rate each profile on a 1-10 sca...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.