Recognition: unknown
Cross-level Privacy Preserving Utility Mining
Pith reviewed 2026-05-09 21:02 UTC · model grok-4.3
The pith
Three victim-selection strategies plus a new dictionary let databases with taxonomies hide all sensitive cross-level high-utility itemsets without creating artificial ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
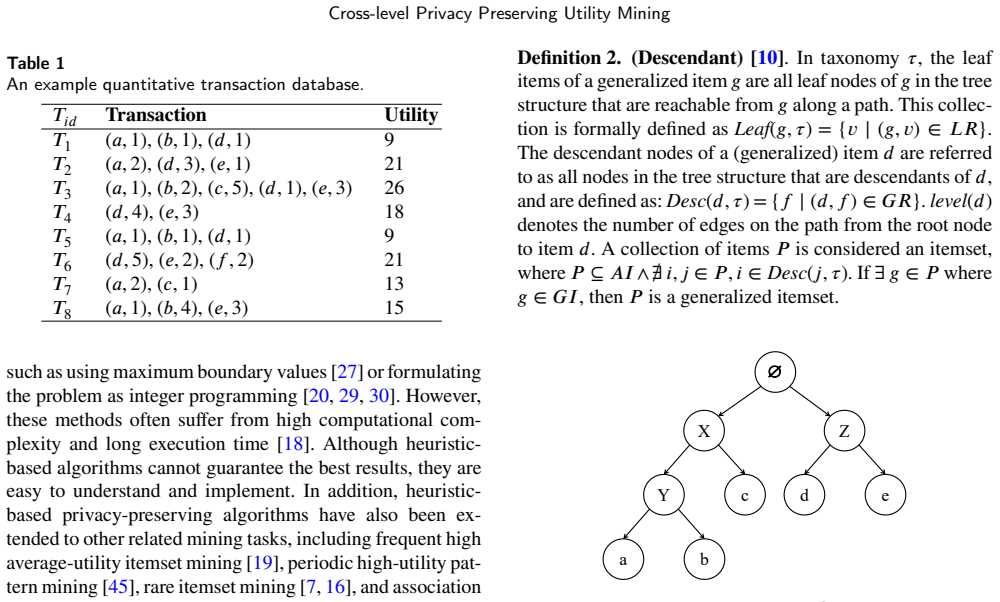
The authors develop three algorithms for the cross-level privacy-preserving utility mining (CLPPUM) task that rely on RGISU and NSC metrics to select victim items, supported by a novel GI-dic dictionary that accelerates utility-metric lookups; these algorithms sanitize the input database so that every sensitive cross-level high-utility itemset is hidden while no artificial itemsets are introduced.
What carries the argument
The GI-dic dictionary structure that stores and retrieves generalized-item utility values to support rapid victim-item selection under three ordering strategies (minimum RGISU first, maximum RGISU first, best NSC first).
If this is right
- Databases that already store category hierarchies can be sanitized for privacy while retaining their original high-utility patterns.
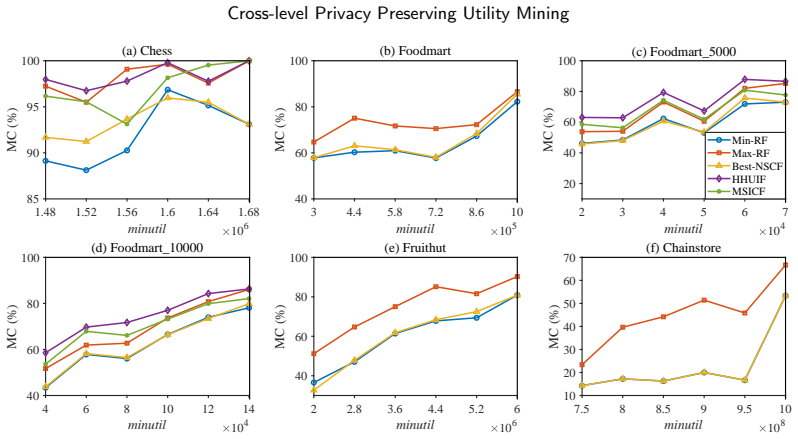
- Min-RF should be the default choice when minimum-utility thresholds are small or the data are dense.
- The approach scales to sparse data without loss of hiding power.
- No post-processing step is required to remove invented patterns.
Where Pith is reading between the lines
- The same victim-selection logic could be adapted to protect sensitive patterns at multiple depths of the taxonomy simultaneously.
- If the taxonomy itself contains errors, the hiding guarantee would no longer hold for patterns that rely on those erroneous generalizations.
- Integrating GI-dic with incremental mining algorithms might allow privacy protection to be maintained under streaming updates.
Load-bearing premise
The supplied taxonomic hierarchy is accurate and complete, and choosing victims according to RGISU or NSC scores will not unintentionally damage non-sensitive patterns when generalized items are involved.
What would settle it
Run the three algorithms on a new dataset that contains a known taxonomy and at least one sensitive cross-level high-utility itemset; if any sensitive pattern remains or any artificial itemset appears in the output, the central claim fails.
Figures












read the original abstract
Privacy-preserving utility mining (PPUM) aims to hide sensitive high-utility patterns while preserving the utility of the sanitized database. In practice, however, many datasets are associated with taxonomic information, which makes the identification and processing of generalized items more challenging. To address this, we investigate the cross-level privacy-preserving utility mining (CLPPUM) problem and propose a method for protecting generalized items. Based on different victim item selection strategies, we develop three CLPPUM algorithms: minimum RGISU first (Min-RF), maximum RGISU first (Max-RF), and best NSC first (Best-NSCF). Furthermore, to enable efficient victim item identification, a novel dictionary structure named GI-dic is designed to accelerate the computation of required utility metrics. Experimental results on multiple datasets demonstrate that the proposed algorithms successfully hide all sensitive cross-level high-utility itemsets without introducing artificial itemsets. The results also show that our method performs well on sparse datasets, and both Min-RF and Best-NSCF consistently outperform Max-RF. Overall, Min-RF achieves the best performance, particularly when the minimum utility threshold is low and the dataset is dense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the cross-level privacy-preserving utility mining (CLPPUM) problem for datasets with taxonomic information. It proposes three algorithms (Min-RF, Max-RF, Best-NSCF) that use RGISU and NSC victim-selection strategies together with a new GI-dic dictionary structure to hide sensitive cross-level high-utility itemsets while avoiding the creation of artificial itemsets. Experiments on multiple datasets are reported to show that all sensitive patterns are hidden, that the approach works well on sparse data, and that Min-RF and Best-NSCF outperform Max-RF (with Min-RF best overall, especially at low utility thresholds on dense data).
Significance. If the experimental claims are substantiated, the work extends privacy-preserving utility mining to the practically relevant setting of hierarchical taxonomies and supplies an efficient auxiliary structure (GI-dic) for metric computation. The performance differentiation among the three victim-selection heuristics on sparse versus dense data supplies a concrete basis for algorithm choice. These contributions would be of interest to the data-mining and privacy communities provided the sanitization guarantees can be verified.
major comments (2)
- [Experimental Results] Experimental Results section: the central claim that the algorithms 'successfully hide all sensitive cross-level high-utility itemsets without introducing artificial itemsets' is stated without reporting the concrete success metrics used (utility-loss thresholds, number of sensitive patterns per dataset, side-effect counts), error bars, or any sensitivity analysis on taxonomy completeness. This absence prevents independent verification of the headline result.
- [Problem Definition and Algorithm] Problem Definition and Algorithm sections: the sanitization correctness rests on the unvalidated assumption that the supplied taxonomy is accurate and complete and that RGISU/NSC victim selection never raises the utility of any non-sensitive generalized or cross-level itemset above threshold. No proof sketch or empirical stress test on overlapping patterns is supplied, leaving the side-effect-free guarantee unsupported.
minor comments (2)
- [Abstract] Abstract: the statement 'performs well on sparse datasets' is not accompanied by the names or sparsity statistics of the datasets used, making the claim difficult to interpret.
- [Algorithm Description] Algorithm description: a small worked example or pseudocode for the GI-dic structure would clarify how the dictionary accelerates RGISU and NSC calculations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating where we agree that revisions are needed to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central claim that the algorithms 'successfully hide all sensitive cross-level high-utility itemsets without introducing artificial itemsets' is stated without reporting the concrete success metrics used (utility-loss thresholds, number of sensitive patterns per dataset, side-effect counts), error bars, or any sensitivity analysis on taxonomy completeness. This absence prevents independent verification of the headline result.
Authors: We agree that the Experimental Results section would benefit from more explicit quantitative details to support independent verification. While the manuscript demonstrates success through direct before-and-after comparisons on multiple datasets (showing all sensitive patterns hidden and no artificial itemsets created), we will revise this section to add tables explicitly reporting the number of sensitive patterns per dataset, utility-loss values, side-effect counts, and the utility thresholds applied. We will also include error bars for averaged results where applicable and add a short sensitivity analysis on taxonomy completeness. revision: yes
-
Referee: [Problem Definition and Algorithm] Problem Definition and Algorithm sections: the sanitization correctness rests on the unvalidated assumption that the supplied taxonomy is accurate and complete and that RGISU/NSC victim selection never raises the utility of any non-sensitive generalized or cross-level itemset above threshold. No proof sketch or empirical stress test on overlapping patterns is supplied, leaving the side-effect-free guarantee unsupported.
Authors: The taxonomy is supplied as input data, which is the standard assumption in cross-level and hierarchical utility mining. The RGISU and NSC strategies are constructed to reduce utilities only for sensitive itemsets by selecting victim items that minimize collateral impact. Our experiments on multiple datasets confirm that no non-sensitive generalized or cross-level itemsets exceed the threshold after sanitization. To strengthen the presentation, we will add a concise argument in the Algorithm section explaining why the victim-selection process cannot increase utilities of non-sensitive itemsets, together with an additional empirical stress test on datasets containing overlapping patterns. revision: partial
Circularity Check
No circularity: algorithmic methods validated empirically on external data
full rationale
The paper proposes three algorithms (Min-RF, Max-RF, Best-NSCF) and a GI-dic structure for cross-level privacy-preserving utility mining. No equations, derivations, or first-principles results are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Claims rest on experimental outcomes using provided external datasets and taxonomies rather than internal redefinitions or predictions forced by inputs. The work is self-contained as an algorithmic contribution with no load-bearing steps that equate outputs to inputs by design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mining association rulesbetweensetsofitemsinlargedatabases,in:TheACMSIGMOD International Conference on Management of Data, pp
Agrawal, R., Imieliński, T., Swami, A., 1993. Mining association rulesbetweensetsofitemsinlargedatabases,in:TheACMSIGMOD International Conference on Management of Data, pp. 207–216
1993
-
[2]
Privacy-preserving data mining, in: The ACM SIGMOD International Conference on Management of Data, pp
Agrawal, R., Srikant, R., 2000. Privacy-preserving data mining, in: The ACM SIGMOD International Conference on Management of Data, pp. 439–450
2000
-
[3]
Efficient treestructuresforhighutilitypatternmininginincrementaldatabases
Ahmed, C.F., Tanbeer, S.K., Jeong, B.S., Lee, Y.K., 2009. Efficient treestructuresforhighutilitypatternmininginincrementaldatabases. IEEE Transactions on Knowledge and Data Engineering 21, 1708– 1721
2009
-
[4]
Preservingprivacyinassociationrule mining using multi-threshold particle swarm optimization
Aljehani,S.,Alotaibi,Y.,2025. Preservingprivacyinassociationrule mining using multi-threshold particle swarm optimization. Informa- tion Sciences 692, 121673
2025
-
[5]
Computers & Security 132, 103360
Ashraf,M.,Rady,S.,Abdelkader,T.,Gharib,T.F.,2023.Efficientpri- vacy preserving algorithms for hiding sensitive high utility itemsets. Computers & Security 132, 103360
2023
-
[6]
Discovering high-utility itemsets at multiple abstraction levels, in: New Trends in Databases and Information Systems, Springer
Cagliero,L.,Chiusano,S.,Garza,P.,Ricupero,G.,2017. Discovering high-utility itemsets at multiple abstraction levels, in: New Trends in Databases and Information Systems, Springer. pp. 224–234
2017
-
[7]
Rare yet critical: Algorithms for privacy preserving rare itemset mining
Chen, C.M., Li, W., Lv, J., Kumari, S., 2025. Rare yet critical: Algorithms for privacy preserving rare itemset mining. Information Sciences , 122572
2025
-
[8]
An effi- cientutility-listbasedhigh-utilityitemsetminingalgorithm
Cheng, Z., Fang, W., Shen, W., Lin, J.C.W., Yuan, B., 2023. An effi- cientutility-listbasedhigh-utilityitemsetminingalgorithm. Applied Intelligence 53, 6992–7006
2023
-
[9]
Efficienthighutilityitemsetminingusingbufferedutility- lists
Duong,Q.H.,Fournier-Viger,P.,Ramampiaro,H.,Nørvåg,K.,Dam, T.L.,2018. Efficienthighutilityitemsetminingusingbufferedutility- lists. Applied Intelligence 48, 1859–1877
2018
-
[10]
Fournier-Viger, P., Wang, Y., Lin, J.C.W., Luna, J.M., Ventura, S.,
-
[11]
Mining cross-level high utility itemsets, in: 33rd International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Springer. pp. 858–871. Jiahong Cai et al.:Preprint submitted to Elsevier Page 16 of 17 Cross-level Privacy Preserving Utility Mining
-
[12]
FHM: Faster high-utility itemset mining using estimated utility co- occurrence pruning, in: Foundations of Intelligent Systems: 21st International Symposium, Springer
Fournier-Viger, P., Wu, C.W., Zida, S., Tseng, V.S., 2014. FHM: Faster high-utility itemset mining using estimated utility co- occurrence pruning, in: Foundations of Intelligent Systems: 21st International Symposium, Springer. pp. 83–92
2014
-
[13]
Privacy preservingutilitymining:asurvey,in:IEEEInternationalConference on Big Data, IEEE
Gan,W.,Lin,J.C.W.,Chao,H.C.,Wang,S.L.,Yu,P.S.,2018. Privacy preservingutilitymining:asurvey,in:IEEEInternationalConference on Big Data, IEEE. pp. 2617–2626
2018
-
[14]
Data mining in distributed environment: a survey
Gan, W., Lin, J.C.W., Chao, H.C., Zhan, J., 2017. Data mining in distributed environment: a survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 7, e1216
2017
-
[15]
A survey of utility-oriented pattern mining
Gan, W., Lin, J.C.W., Fournier-Viger, P., Chao, H.C., Tseng, V.S., Yu, P.S., 2021. A survey of utility-oriented pattern mining. IEEE Transactions on Knowledge and Data Engineering 33, 1306–1327
2021
-
[16]
HUOPM:High-utilityoccupancypatternmining
Gan, W., Lin, J.C.W., Fournier-Viger, P., Chao, H.C., Yu, P.S., 2020. HUOPM:High-utilityoccupancypatternmining. IEEETransactions on Cybernetics 50, 1195–1208
2020
-
[17]
Privacy preserving rare itemset mining
Gui, Y., Gan, W., Wu, Y., Yu, P.S., 2024. Privacy preserving rare itemset mining. Information Sciences 662, 120262
2024
-
[18]
Mining top- k constrained cross-level high-utility itemsets over data streams
Han, M., Liu, S., Gao, Z., Mu, D., Li, A., 2024. Mining top- k constrained cross-level high-utility itemsets over data streams. Knowledge and Information Systems 66, 2885–2924
2024
-
[19]
Efficient algorithms for victim item selection in privacy-preserving utility mining
Jangra, S., Toshniwal, D., 2022. Efficient algorithms for victim item selection in privacy-preserving utility mining. Future Generation Computer Systems 128, 219–234
2022
-
[20]
H-FHAUI:Hidingfrequenthighaverageutilityitemsets
Le, B., Truong, T., Duong, H., Fournier-Viger, P., Fujita, H., 2022. H-FHAUI:Hidingfrequenthighaverageutilityitemsets. Information Sciences 611, 408–431
2022
-
[21]
A novel algorithm for privacy preserving utility mining based on integer linear programming
Li, S., Mu, N., Le, J., Liao, X., 2019. A novel algorithm for privacy preserving utility mining based on integer linear programming. En- gineering Applications of Artificial Intelligence 81, 300–312
2019
-
[22]
Efficient hiding of confidential high-utility itemsets with minimalsideeffects
Lin,J.C.W.,Hong,T.P.,Fournier-Viger,P.,Liu,Q.,Wong,J.W.,Zhan, J., 2017. Efficient hiding of confidential high-utility itemsets with minimalsideeffects. JournalofExperimental&TheoreticalArtificial Intelligence 29, 1225–1245
2017
-
[23]
Fast algorithms for hiding sensitive high-utility itemsets in privacy-preserving utility mining
Lin, J.C.W., Wu, T.Y., Fournier-Viger, P., Lin, G., Zhan, J., Voznak, M., 2016. Fast algorithms for hiding sensitive high-utility itemsets in privacy-preserving utility mining. Engineering Applications of Artificial Intelligence 55, 269–284
2016
-
[24]
Privacy preserving data mining, in: Annual international cryptology conference, Springer
Lindell, Y., Pinkas, B., 2000. Privacy preserving data mining, in: Annual international cryptology conference, Springer. pp. 36–54
2000
-
[25]
Mining high utility patterns in one phase without generating candidates
Liu, J., Wang, K., Fung, B.C., 2015. Mining high utility patterns in one phase without generating candidates. IEEE Transactions on Knowledge and Data Engineering 28, 1245–1257
2015
-
[26]
Mining high utility itemsets without candidate generation, in: The 21st ACM International Conference on Informa- tion and Knowledge Management, pp
Liu, M., Qu, J., 2012. Mining high utility itemsets without candidate generation, in: The 21st ACM International Conference on Informa- tion and Knowledge Management, pp. 55–64
2012
-
[27]
Animprovedsanitization algorithm in privacy-preserving utility mining
Liu,X.,Chen,G.,Wen,S.,Song,G.,2020. Animprovedsanitization algorithm in privacy-preserving utility mining. Mathematical Prob- lems in Engineering 2020, 7489045
2020
-
[28]
A novel approach for hiding sensitive utility and frequent itemsets
Liu, X., Xu, F., Lv, X., 2018. A novel approach for hiding sensitive utility and frequent itemsets. Intelligent Data Analysis 22, 1259– 1278
2018
-
[29]
A two-phase algorithm forfastdiscoveryofhighutilityitemsets,in:AdvancesinKnowledge Discovery and Data Mining: 9th Pacific-Asia Conference, Springer
Liu, Y., Liao, W.k., Choudhary, A., 2005. A two-phase algorithm forfastdiscoveryofhighutilityitemsets,in:AdvancesinKnowledge Discovery and Data Mining: 9th Pacific-Asia Conference, Springer. pp. 689–695
2005
-
[30]
Novel stochastic algorithms for privacy- preserving utility mining
Nguyen, D., Le, B., 2024. Novel stochastic algorithms for privacy- preserving utility mining. Applied Intelligence 54, 12725–12741
2024
-
[31]
A new algorithm using inte- ger programming relaxation for privacy-preserving in utility mining
Nguyen, D., Tran, M.T., Le, B., 2023. A new algorithm using inte- ger programming relaxation for privacy-preserving in utility mining. Applied Intelligence 53, 25106–25118
2023
-
[32]
Nouioua, M., Wang, Y., Fournier-Viger, P., Lin, J.C.W., Wu, J.M.T.,
-
[33]
TKC: Mining top-k cross-level high utility itemsets, in: InternationalConferenceonDataMiningWorkshops,IEEE.pp.673– 682
-
[34]
Mining high utility itemsets using prefix trees and utility vectors
Qu, J.F., Fournier-Viger, P., Liu, M., Hang, B., Hu, C., 2023. Mining high utility itemsets using prefix trees and utility vectors. IEEE TransactionsonKnowledgeandDataEngineering35,10224–10236
2023
-
[35]
Efficient mining of top-k cross-level high utility itemsets, in: International Conference on Future Data and Security Engineering, Springer
Truong, N.T., Tue, N.K., Chinh, N.D., Huynh, L.D., Diep, V.T., Hung, P.D., 2023. Efficient mining of top-k cross-level high utility itemsets, in: International Conference on Future Data and Security Engineering, Springer. pp. 118–131
2023
-
[36]
IEEE Transactions on Knowledge and Data Engineering 25, 1772–1786
Tseng,V.S.,Shie,B.E.,Wu,C.W.,Yu,P.S.,2012.Efficientalgorithms for mining high utility itemsets from transactional databases. IEEE Transactions on Knowledge and Data Engineering 25, 1772–1786
2012
-
[37]
UP-Growth: an efficient algorithm for high utility itemset mining, in: The 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp
Tseng, V.S., Wu, C.W., Shie, B.E., Yu, P.S., 2010. UP-Growth: an efficient algorithm for high utility itemset mining, in: The 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 253–262
2010
-
[38]
Information Sciences 587, 41– 62
Tung, N., Nguyen, L.T., Nguyen, T.D., Fourier-Viger, P., Nguyen, N.T.,Vo,B.,2022.Efficientminingofcross-levelhigh-utilityitemsets in taxonomy quantitative databases. Information Sciences 587, 41– 62
2022
-
[39]
Miningcross-levelhighutilityitemsetsinunstableand negativeprofitdatabases
Tung, N., Nguyen, T.D., Nguyen, L.T., Vu, D.L., Fournier-Viger, P., Vo,B.,2025. Miningcross-levelhighutilityitemsetsinunstableand negativeprofitdatabases. IEEETransactionsonKnowledgeandData Engineering 37, 5420–5435
2025
-
[40]
Wu,J.M.T.,Srivastava,G.,Jolfaei,A.,Fournier-Viger,P.,Lin,J.C.W.,
-
[41]
Future Generation Computer Systems 117, 169–180
Hiding sensitive information in ehealth datasets. Future Generation Computer Systems 117, 169–180
-
[42]
UBP- Miner: An efficient bit-based high utility itemset mining algorithm
Wu,P.,Niu,X.,Fournier-Viger,P.,Huang,C.,Wang,B.,2022. UBP- Miner: An efficient bit-based high utility itemset mining algorithm. Knowledge-Based Systems 248, 108865
2022
-
[43]
Yan, Y., Niu, X., Zhang, Z., Fournier-Viger, P., Ye, L., Min, F.,
-
[44]
Information Sciences 681, 121218
Efficienthighutilityitemsetminingwithoutthejoinoperation. Information Sciences 681, 121218
-
[45]
Afoundationalapproachto mining itemset utilities from databases, in: The SIAM International Conference on Data Mining, SIAM
Yao,H.,Hamilton,H.J.,Butz,C.J.,2004. Afoundationalapproachto mining itemset utilities from databases, in: The SIAM International Conference on Data Mining, SIAM. pp. 482–486
2004
-
[46]
HHUIFandMSICF:Novelalgorithmsfor privacy preserving utility mining
Yeh,J.S.,Hsu,P.C.,2010. HHUIFandMSICF:Novelalgorithmsfor privacy preserving utility mining. Expert Systems with Applications 37, 4779–4786
2010
-
[47]
Fastprivacy-preservingutilityminingalgorithm based on utility-list dictionary
Yin,C.,Li,Y.,2023. Fastprivacy-preservingutilityminingalgorithm based on utility-list dictionary. Applied Intelligence 53, 29363– 29377
2023
-
[48]
A fast perturbation algorithm using tree structure for privacy preserving utility mining
Yun, U., Kim, J., 2015. A fast perturbation algorithm using tree structure for privacy preserving utility mining. Expert Systems with Applications 42, 1149–1165
2015
-
[49]
Utility-based privacy- preserving data mining
Zhou, Q., Gan, W., Qi, Z., Yu, P.S., 2025. Utility-based privacy- preserving data mining. IEEE Internet of Things Journal 13, 2067– 2084
2025
-
[50]
Efim: a fast and memory efficient algorithm for high-utility itemset mining
Zida,S.,Fournier-Viger,P.,Lin,J.C.W.,Wu,C.W.,Tseng,V.S.,2017. Efim: a fast and memory efficient algorithm for high-utility itemset mining. Knowledge and Information Systems 51, 595–625. Jiahong Cai et al.:Preprint submitted to Elsevier Page 17 of 17
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.