Recognition: unknown
Minimal, Local, Causal Explanations for Jailbreak Success in Large Language Models
Pith reviewed 2026-05-09 20:36 UTC · model grok-4.3
The pith
LOCA finds the smallest set of representation changes that causally turn a working jailbreak into a refusal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
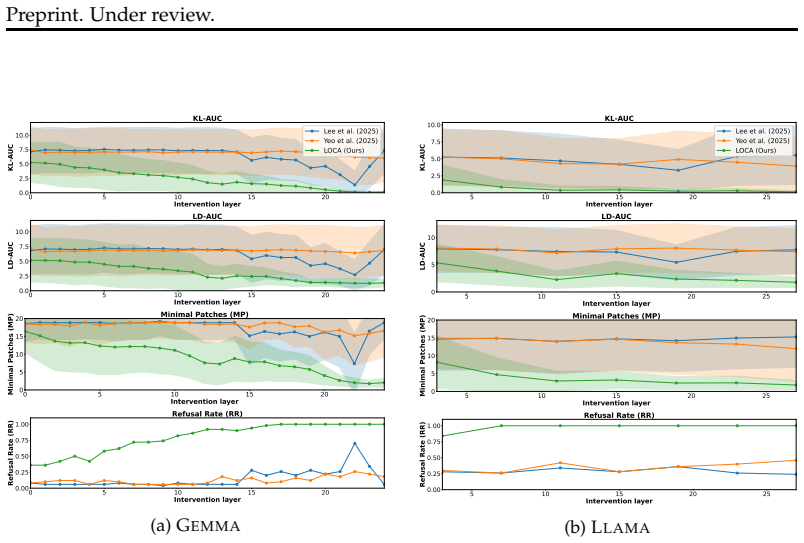
LOCA is a procedure that, given a successful jailbreak and its original harmful request, identifies a minimal set of interpretable directions in the model's intermediate representations whose targeted modification is causally sufficient to induce refusal. On Gemma and Llama chat models, this minimal set contains six directions on average and works across violence, cyberattack, and other request categories, whereas globally applied directions from earlier work require far more interventions and frequently leave the jailbreak intact.
What carries the argument
LOCA, a search procedure that isolates the smallest set of human-interpretable activation directions whose causal intervention restores refusal on a given jailbreak.
If this is right
- Safety interventions can be made local and request-specific instead of applying the same global steering vector to every prompt.
- Jailbreak strategies that succeed on different harmful topics can be distinguished by which representation directions they alter.
- A model's vulnerability to a new jailbreak can be tested by checking whether that jailbreak alters the same small set of directions.
- Mechanistic comparisons between models become possible by measuring overlap in the minimal change sets each model requires.
Where Pith is reading between the lines
- If the minimal sets remain stable across retraining runs, safety training could target those specific directions directly.
- The same local-search approach could be applied to other controllable behaviors such as honesty or bias instead of refusal alone.
- Prompt-level detectors could flag potential jailbreaks by testing whether a prompt would move activations along the same directions.
Load-bearing premise
The directions returned by the search are the true minimal causal drivers of refusal rather than artifacts of the search procedure or correlated but non-causal features.
What would settle it
Intervening on the six directions identified by LOCA fails to produce refusal on the original jailbreak prompt, or the model refuses even when those directions remain unchanged.
Figures





read the original abstract
Safety trained large language models (LLMs) can often be induced to answer harmful requests through jailbreak prompts. Because we lack a robust understanding of why LLMs are susceptible to jailbreaks, future frontier models operating more autonomously in higher-stakes settings may similarly be vulnerable to such attacks. Prior work has studied jailbreak success by examining the model's intermediate representations, identifying directions in this space that causally encode concepts like harmfulness and refusal. Then, they globally explain all jailbreak attacks as attempting to reduce or strengthen these concepts (e.g., reduce harmfulness). However, different jailbreak strategies may succeed by strengthening or suppressing different intermediate concepts, and the same jailbreak strategy may not work for different harmful request categories (e.g., violence vs. cyberattack); thus, we seek to give a local explanation -- i.e., why did this specific jailbreak succeed? To address this gap, we introduce LOCA, a method that gives Local, CAusal explanations of jailbreak success by identifying a minimal set of interpretable, intermediate representation changes that causally induce model refusal on an otherwise successful jailbreak request. We evaluate LOCA on harmful original-jailbreak pairs from a large jailbreak benchmark across Gemma and Llama chat models, comparing against prior methods adapted to this setting. LOCA can successfully induce refusal by making, on average, six interpretable changes; prior work routinely fails to achieve refusal even after 20 changes. LOCA is a step toward mechanistic, local explanations of jailbreak success in LLMs. Code to be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LOCA, a method for generating local causal explanations of jailbreak success in safety-trained LLMs. For a given successful jailbreak prompt, LOCA identifies a minimal set of interpretable changes to intermediate representations that, when applied as interventions, causally induce the model to refuse the request. Evaluated on harmful original-jailbreak pairs from a large benchmark using Gemma and Llama chat models, the authors report that LOCA induces refusal with an average of six changes, while adapted prior global methods routinely fail to achieve refusal even after more than twenty changes.
Significance. If the causality and minimality claims are rigorously supported, the work advances mechanistic interpretability of LLM safety by shifting from global concept directions (e.g., harmfulness) to precise, instance-specific representation edits. The quantitative gap versus prior work is potentially important for targeted defenses, and the promise of releasing code supports reproducibility.
major comments (3)
- [§3] §3 (LOCA algorithm): The search procedure for identifying the minimal set of representation changes is not shown to be exhaustive or to include controls against post-hoc selection bias. If the method is greedy or relies on the same data used to define success, the reported minimality does not follow from the intervention results.
- [§4.2] §4.2 (Intervention experiments): No random-direction or orthogonalized-direction baselines are reported. Without these, it is unclear whether refusal is induced specifically by the LOCA-selected directions or by any sufficiently large perturbation in representation space.
- [§5] §5 (Quantitative comparison): The claim that prior methods fail after 20+ changes while LOCA succeeds with six lacks detail on whether the same refusal metric, intervention magnitude, and model layers were used for the baselines. This makes the performance gap difficult to interpret as evidence of superior causal localization.
minor comments (2)
- [Abstract] The abstract states that code will be released but provides no link or repository identifier; this should be added for reproducibility.
- [§2] Notation for the representation space and intervention operator is introduced without an explicit equation; adding a compact definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (LOCA algorithm): The search procedure for identifying the minimal set of representation changes is not shown to be exhaustive or to include controls against post-hoc selection bias. If the method is greedy or relies on the same data used to define success, the reported minimality does not follow from the intervention results.
Authors: We agree that the description of the LOCA search procedure in §3 could be more explicit regarding its greedy nature and potential for post-hoc bias. The algorithm iteratively selects the most impactful representation change based on intervention effects on a development set of jailbreaks, then validates on a held-out test set. While this provides evidence of causality, we acknowledge that it does not guarantee global minimality. In the revised manuscript, we will expand §3 to include a formal description of the search, report the development set size, and add an ablation showing performance on the test set to address selection bias concerns. This will clarify that the reported average of six changes is the result of this procedure rather than an exhaustive search. revision: partial
-
Referee: [§4.2] §4.2 (Intervention experiments): No random-direction or orthogonalized-direction baselines are reported. Without these, it is unclear whether refusal is induced specifically by the LOCA-selected directions or by any sufficiently large perturbation in representation space.
Authors: This is a fair criticism. Our current experiments control for the number and magnitude of changes but do not compare against random or orthogonal directions. To demonstrate specificity, we will include additional baseline experiments in the revision: (1) random selection of the same number of directions with matched intervention strength, and (2) directions orthogonal to the LOCA-selected ones. We expect these to show lower refusal induction rates, supporting that the effect is due to the specific causal features identified by LOCA rather than generic perturbations. revision: yes
-
Referee: [§5] §5 (Quantitative comparison): The claim that prior methods fail after 20+ changes while LOCA succeeds with six lacks detail on whether the same refusal metric, intervention magnitude, and model layers were used for the baselines. This makes the performance gap difficult to interpret as evidence of superior causal localization.
Authors: We apologize for the lack of detail in the comparison. The baselines were implemented using the same refusal detection metric (keyword-based and model-based refusal classifiers on generated outputs), applied to the same set of model layers (middle layers where representations are most interpretable), and with intervention magnitudes scaled to match the average change size used in LOCA. However, to make this transparent, we will revise §5 to include a detailed methods subsection for the baselines, specifying these parameters, and add a table comparing the exact settings. This will allow readers to better assess the performance gap. revision: yes
Circularity Check
No circularity: LOCA's minimal-change identification relies on empirical intervention testing rather than definitional equivalence or self-referential fitting.
full rationale
The paper's core claim is that LOCA identifies a small set of representation changes via search over observed jailbreak pairs and then validates them through targeted interventions that induce refusal. This process is not self-definitional because the reported success (refusal after ~6 changes) is measured by an external outcome metric on held-out or intervened activations, not by construction from the same data used to select the directions. No equations or steps reduce the result to a fitted parameter renamed as prediction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The derivation chain remains self-contained against external benchmarks of intervention success versus prior methods.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Jailbroken: How Does
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , booktitle=. Jailbroken: How Does. 2023 , url=
2023
-
[3]
ArXiv , year=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. ArXiv , year=
-
[4]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[5]
Forty-second International Conference on Machine Learning , year=
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
2025 , url=
Jiachen Zhao and Jing Huang and Zhengxuan Wu and David Bau and Weiyan Shi , booktitle=. 2025 , url=
2025
-
[7]
International Conference on Computational Linguistics , year=
Revisiting Jailbreaking for Large Language Models: A Representation Engineering Perspective , author=. International Conference on Computational Linguistics , year=
-
[8]
Annual Meeting of the Association for Computational Linguistics , year=
Mechanistic Interpretability of Emotion Inference in Large Language Models , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[9]
ArXiv , year=
Persona Vectors: Monitoring and Controlling Character Traits in Language Models , author=. ArXiv , year=
-
[10]
USENIX Security Symposium , year=
JBShield: Defending Large Language Models from Jailbreak Attacks through Activated Concept Analysis and Manipulation , author=. USENIX Security Symposium , year=
-
[11]
ArXiv , year=
Understanding Jailbreak Success: A Study of Latent Space Dynamics in Large Language Models , author=. ArXiv , year=
-
[12]
ArXiv , year=
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations , author=. ArXiv , year=
-
[13]
Gradient cuff: Detecting jailbreak attacks on large language models by exploring refusal loss landscapes , author=
-
[14]
ArXiv , year=
Detecting Language Model Attacks with Perplexity , author=. ArXiv , year=
-
[15]
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
Jailbreak and guard aligned language models with only few in-context demonstrations , author=. arXiv preprint arXiv:2310.06387 , year=
-
[16]
SafeDe- coding: Defending against Jailbreak Attacks via Safety-Aware Decoding
Safedecoding: Defending against jailbreak attacks via safety-aware decoding , author=. arXiv preprint arXiv:2402.08983 , year=
-
[17]
What Features in Prompts Jailbreak LLM s? Investigating the Mechanisms Behind Attacks
Kirch, Nathalie Maria and Weisser, Constantin Niko and Field, Severin and Yannakoudakis, Helen and Casper, Stephen. What Features in Prompts Jailbreak LLM s? Investigating the Mechanisms Behind Attacks. Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2025. doi:10.18653/v1/2025.blackboxnlp-1.28
-
[18]
Personality and Social Psychology Bulletin , year=
The Big Five Personality Factors and Personal Values , author=. Personality and Social Psychology Bulletin , year=
-
[19]
Advances in experimental social psychology , volume=
Moral foundations theory: The pragmatic validity of moral pluralism , author=. Advances in experimental social psychology , volume=. 2013 , publisher=
2013
-
[20]
Journal of Personality and Social Psychology , volume=
The Situational Eight DIAMONDS: A taxonomy of major dimensions of situation characteristics , author=. Journal of Personality and Social Psychology , volume=. 2014 , publisher=
2014
-
[21]
Social Science Information , year=
A psychoevolutionary theory of emotions , author=. Social Science Information , year=
-
[22]
Towards Understanding Jailbreak Attacks in LLM s: A Representation Space Analysis
Lin, Yuping and He, Pengfei and Xu, Han and Xing, Yue and Yamada, Makoto and Liu, Hui and Tang, Jiliang. Towards Understanding Jailbreak Attacks in LLM s: A Representation Space Analysis. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.401
-
[23]
Understanding Refusal in Language Models with Sparse Autoencoders
Yeo, Wei Jie and Prakash, Nirmalendu and Neo, Clement and Satapathy, Ranjan and Lee, Roy Ka-Wei and Cambria, Erik. Understanding Refusal in Language Models with Sparse Autoencoders. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.338
-
[24]
2025 , month = jan, howpublished =
Finding Features Causally Upstream of Refusal , author =. 2025 , month = jan, howpublished =
2025
-
[25]
misaligned persona
Finding "misaligned persona" features in open-weight models , author =. 2025 , month = sep, howpublished =
2025
-
[26]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[27]
ArXiv , year=
How to use and interpret activation patching , author=. ArXiv , year=
-
[28]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[29]
ArXiv , year=
Gemma 2: Improving Open Language Models at a Practical Size , author=. ArXiv , year=
-
[30]
2024 , url=
The Llama 3 Herd of Models , author=. 2024 , url=
2024
-
[31]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramar, Janos and Dragan, Anca and Shah, Rohin and Nanda, Neel. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP....
-
[32]
2024 , month = jul, howpublished =
Connor Kissane and robertzk and Arthur Conmy and Neel Nanda , title =. 2024 , month = jul, howpublished =
2024
-
[33]
ArXiv , year=
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. ArXiv , year=
-
[34]
J ailbreak R adar: Comprehensive Assessment of Jailbreak Attacks Against LLM s
Chu, Junjie and Liu, Yugeng and Yang, Ziqing and Shen, Xinyue and Backes, Michael and Zhang, Yang. J ailbreak R adar: Comprehensive Assessment of Jailbreak Attacks Against LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1045
-
[35]
Current Directions in Psychological Science , year=
The Magical Mystery Four , author=. Current Directions in Psychological Science , year=
-
[36]
, author=
The magical number seven plus or minus two: some limits on our capacity for processing information. , author=. Psychological review , year=
-
[37]
Frontiers of Computer Science , year=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , year=
-
[38]
ArXiv , year=
On the Opportunities and Risks of Foundation Models , author=. ArXiv , year=
-
[39]
2024 , eprint=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
2024
-
[40]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[41]
ArXiv , year=
Toy Models of Superposition , author=. ArXiv , year=
-
[42]
The Thirteenth International Conference on Learning Representations , year=
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[43]
The Fourteenth International Conference on Learning Representations , year=
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. The Fourteenth International Conference on Learning Representations , year=
-
[44]
ArXiv , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. ArXiv , year=
-
[45]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[46]
2023 , url=
Steering Language Models With Activation Engineering , author=. 2023 , url=
2023
-
[47]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[48]
Neuronpedia: Interactive Reference and Tooling for Analyzing Neural Networks , year =
-
[49]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. Auto. 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.