Recognition: unknown
Agentic AI for Trip Planning Optimization Application
Pith reviewed 2026-05-09 19:42 UTC · model grok-4.3
The pith
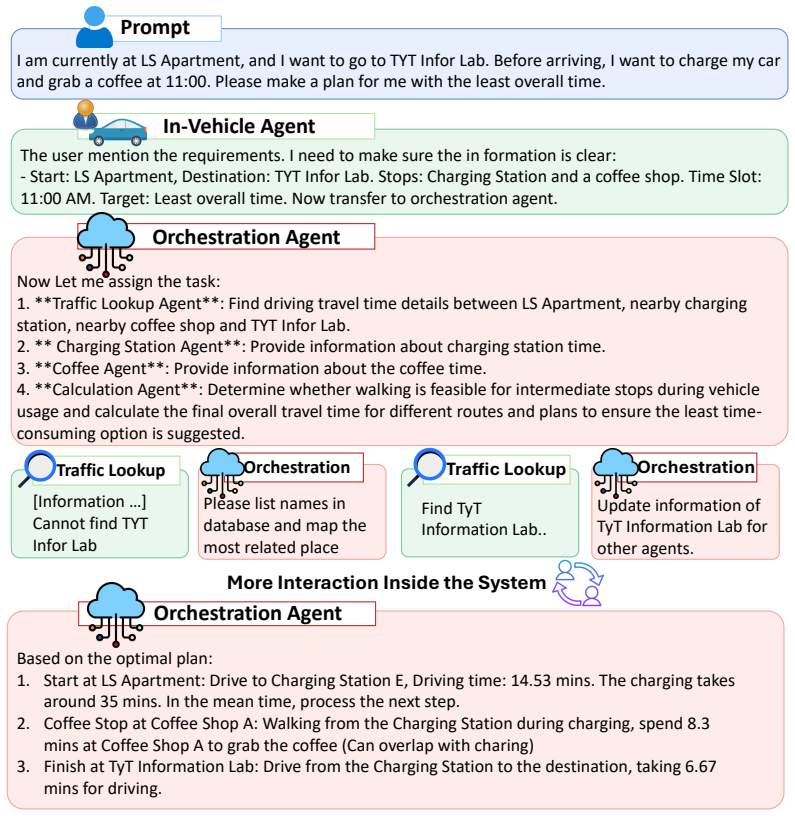
An orchestration agent coordinating traffic, charging, and interest agents reaches 77.4 percent accuracy on a trip-planning benchmark with known optimal solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that an agentic AI framework featuring an orchestration agent that coordinates specialized agents for traffic, charging, and points of interest, together with a dataset that supplies ground-truth optimal solutions, produces robust trip-planning optimization, measured at 77.4 percent accuracy on the TOP Benchmark and shown to exceed single-agent and workflow-based multi-agent baselines.
What carries the argument
The orchestration agent that dynamically coordinates specialized agents for traffic, charging, and points of interest to support iterative refinement of candidate plans.
Load-bearing premise
The Trip-planning Optimization Problems Dataset supplies definitive optimal solutions and category-level task structure that allow objective measurement of optimization quality.
What would settle it
Independent verification that the dataset optima can be improved by another solver, or direct comparison on the TOP Benchmark showing the orchestrated system performs no better than the single-agent baseline.
Figures



read the original abstract
Trip planning for intelligent vehicles increasingly requires selecting optimal routes rather than merely producing feasible itineraries, as interacting factors such as travel time, energy consumption, and traffic conditions directly affect plan quality. Yet existing systems are largely designed for feasibility-oriented planning, and current benchmarks provide only reference answers without ground truth, preventing objective evaluation of optimization performance. In our paper, we address these limitations with an agentic AI framework that enables dynamic refinement through an orchestration agent coordinating specialized agents for traffic, charging, and points of interest, and with the Trip-planning Optimization Problems Dataset, which supplies definitive optimal solutions and category-level task structure for fine-grained analysis. Experiments show that our system achieves 77.4\% accuracy on the TOP Benchmark, significantly outperforming single-agent and workflow-based multi-agent baselines, demonstrating the importance of orchestrated agentic reasoning for robust trip planning optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic AI framework for trip planning optimization that uses an orchestration agent to coordinate specialized agents handling traffic, charging, and points of interest. It introduces the Trip-planning Optimization Problems (TOP) Dataset, which is claimed to supply definitive optimal solutions along with category-level task structure. The central empirical result is that the system achieves 77.4% accuracy on the TOP Benchmark, significantly outperforming single-agent and workflow-based multi-agent baselines.
Significance. If the optimality of the TOP Dataset reference solutions is independently verified through documented solvers or exhaustive methods and the experimental protocols are fully specified with statistical analysis, the work would provide concrete evidence that orchestrated multi-agent reasoning improves optimization performance over simpler agentic or workflow approaches in multi-objective problems such as vehicle trip planning. This could strengthen the case for dynamic coordination mechanisms in agentic AI systems applied to real-world logistics and intelligent transportation.
major comments (2)
- [Abstract] Abstract: The 77.4% accuracy claim and the assertion of outperformance over baselines are load-bearing for the paper's demonstration of orchestrated agentic reasoning. However, the manuscript provides no details on how the 'definitive optimal solutions' in the TOP Dataset were computed (e.g., no ILP formulation, solver such as Gurobi/CPLEX, optimality gaps, or exhaustive enumeration for small instances), reducing the metric to agreement with an author-constructed reference rather than verified optimality.
- [Experiments] The experimental evaluation lacks any description of dataset construction, validation of optimality, experimental protocols, or statistical significance testing. Without these, the performance numbers cannot be assessed for reproducibility or robustness, directly undermining the central claim that the framework demonstrates the importance of orchestrated reasoning.
minor comments (2)
- [Abstract] The abstract uses 'significantly outperforming' without accompanying p-values, confidence intervals, or variance measures; adding these would improve clarity of the results presentation.
- Ensure consistent terminology for the benchmark (TOP Benchmark vs. TOP Dataset) across the manuscript to avoid potential reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in transparency regarding the TOP Dataset and experimental methodology. We agree that these details are essential for supporting the claims of verified optimality and reproducible performance gains from orchestrated agentic reasoning. We will revise the manuscript to address both points fully.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 77.4% accuracy claim and the assertion of outperformance over baselines are load-bearing for the paper's demonstration of orchestrated agentic reasoning. However, the manuscript provides no details on how the 'definitive optimal solutions' in the TOP Dataset were computed (e.g., no ILP formulation, solver such as Gurobi/CPLEX, optimality gaps, or exhaustive enumeration for small instances), reducing the metric to agreement with an author-constructed reference rather than verified optimality.
Authors: We agree that the manuscript lacks explicit details on computing the reference solutions. In the revised version, we will add a new subsection in the Dataset section that presents the full Integer Linear Programming (ILP) formulation of the multi-objective trip planning problem (minimizing time, energy, and traffic penalties subject to constraints on charging and POI visits), specifies the solver (Gurobi 10.0 with default optimality gap of 0.01%), and describes verification via exhaustive enumeration on small instances (up to 10 locations) to confirm zero optimality gap. This will demonstrate that the 77.4% accuracy measures agreement with independently verifiable optima rather than author-defined references. revision: yes
-
Referee: [Experiments] The experimental evaluation lacks any description of dataset construction, validation of optimality, experimental protocols, or statistical significance testing. Without these, the performance numbers cannot be assessed for reproducibility or robustness, directly undermining the central claim that the framework demonstrates the importance of orchestrated reasoning.
Authors: We acknowledge the absence of these elements. The revised Experiments section will include: (i) complete dataset construction details, specifying data sources (real-world traffic APIs, charging station registries, and POI databases), instance generation procedure, and size distribution (e.g., 500 instances across 5 categories); (ii) optimality validation steps cross-referenced to the new ILP subsection; (iii) full protocols covering agent hyperparameters, orchestration logic, baseline implementations, and evaluation procedure (exact match to reference solution); and (iv) statistical analysis with 10 independent runs per method, reporting means, standard deviations, and paired t-test p-values against baselines. These additions will enable reproducibility assessment and strengthen the evidence for the value of dynamic orchestration. revision: yes
Circularity Check
No circularity: empirical accuracy measured against newly introduced benchmark
full rationale
The paper introduces the TOP Benchmark and its associated dataset, asserting that it supplies definitive optimal solutions for objective scoring. The central result (77.4% accuracy with outperformance over single-agent and workflow baselines) is presented as a direct empirical measurement of how closely the orchestrated agentic system matches those reference solutions. No equations, fitted parameters, self-definitions, or self-citation chains appear in the provided text that would reduce this accuracy figure to a tautology or input by construction. The evaluation structure remains independent of the proposed method itself, satisfying the criteria for a self-contained empirical claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Use of the internet for trip planning: A generational analysis,
H. Kim, Z. Xiang, and D. R. Fesenmaier, “Use of the internet for trip planning: A generational analysis,”Journal of travel & tourism marketing, vol. 32, no. 3, pp. 276–289, 2015
2015
-
[2]
Trip planning functionalities: state of the art and future,
P. Vansteenwegen and W. Souffriau, “Trip planning functionalities: state of the art and future,”Information Technology & Tourism, vol. 12, no. 4, pp. 305–315, 2010
2010
-
[3]
Revisiting pathfinder routing algorithm,
Y . Zha and J. Li, “Revisiting pathfinder routing algorithm,” inPro- ceedings of the 2022 ACM/SIGDA International Symposium on Field- Programmable Gate Arrays, 2022, pp. 24–34
2022
-
[4]
Adapting to the internet: trends in travelers’ use of the web for trip planning,
Z. Xiang, D. Wang, J. T. O’Leary, and D. R. Fesenmaier, “Adapting to the internet: trends in travelers’ use of the web for trip planning,” Journal of travel research, vol. 54, no. 4, pp. 511–527, 2015
2015
-
[5]
Travelagent: An ai assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024
A. Chen, X. Ge, Z. Fu, Y . Xiao, and J. Chen, “Travelagent: An ai assistant for personalized travel planning,”arXiv preprint arXiv:2409.08069, 2024
-
[6]
S. Chaudhuri, P. Purkar, R. Raghav, S. Mallick, M. Gupta, A. Jana, and S. Ghosh, “Tripcraft: A benchmark for spatio-temporally fine grained travel planning,”arXiv preprint arXiv:2502.20508, 2025
-
[7]
Triptailor: A real-world benchmark for personalized travel planning,
Y . Shen, K. Wang, C. Lv, X. Zheng, and X. Huang, “Triptailor: A real-world benchmark for personalized travel planning,”arXiv preprint arXiv:2508.01432, 2025
-
[8]
A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y . Wu, and Y . Yang, “A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, vol. 1, no. 1, p. 9, 2024
2024
-
[9]
A survey on point-of-interest rec- ommendations leveraging heterogeneous data,
Z. Wang, W. H¨opken, and D. Jannach, “A survey on point-of-interest rec- ommendations leveraging heterogeneous data,”Information Technology & Tourism, vol. 27, no. 1, pp. 29–73, 2025
2025
-
[10]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Smart city by multi- agent systems,
M. Roscia, M. Longo, and G. C. Lazaroiu, “Smart city by multi- agent systems,” in2013 International Conference on Renewable Energy Research and Applications (ICRERA). IEEE, 2013, pp. 371–376
2013
-
[12]
Llm agents for smart city management: Enhancing decision support through multi-agent ai systems
A. Kalyuzhnaya, S. Mityagin, E. Lutsenko, A. Getmanov, Y . Aksenkin, K. Fatkhiev, K. Fedorin, N. O. Nikitin, N. Chichkova, V . V oronaet al., “Llm agents for smart city management: Enhancing decision support through multi-agent ai systems.”Smart Cities (2624-6511), vol. 8, no. 1, 2025
2025
-
[13]
Orchestrating agents: Routines and handoffs,
O. Cookbook, “Orchestrating agents: Routines and handoffs,” Web tutorial, 2024. [Online]. Available: https://cookbook.openai.com/ examples/orchestrating agents
2024
-
[14]
Hello gpt-4o,
OpenAI, “Hello gpt-4o,” https://openai.com/index/hello-gpt-4o/, May 2024, accessed: 2025-10-13
2024
-
[15]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst Conference on Language Modeling, 2024
2024
-
[16]
J. Xie, K. Zhang, J. Chen, T. Zhu, R. Lou, Y . Tian, Y . Xiao, and Y . Su, “Travelplanner: A benchmark for real-world planning with language agents,”arXiv preprint arXiv:2402.01622, 2024
-
[17]
The electric vehicle routing problem and its variations: A literature review,
I. Kucukoglu, R. Dewil, and D. Cattrysse, “The electric vehicle routing problem and its variations: A literature review,”Computers & Industrial Engineering, vol. 161, p. 107650, 2021
2021
-
[18]
The electric vehicle-routing problem with time windows and recharging stations,
M. Schneider, A. Stenger, and D. Goeke, “The electric vehicle-routing problem with time windows and recharging stations,”Transportation science, vol. 48, no. 4, pp. 500–520, 2014
2014
-
[19]
Personal llm agents: Insights and sur- vey about the capability, efficiency and security,
Y . Li, H. Wen, W. Wang, X. Li, Y . Yuan, G. Liu, J. Liu, W. Xu, X. Wang, Y . Sunet al., “Personal llm agents: Insights and survey about the capability, efficiency and security,”arXiv preprint arXiv:2401.05459, 2024
-
[20]
Travellm: Could you plan my new public transit route in face of a network disruption?
B. Fang, Z. Yang, S. Wang, and X. Di, “Travellm: Could you plan my new public transit route in face of a network disruption?”arXiv preprint arXiv:2407.14926, 2024
-
[21]
Y . Tang, Z. Wang, A. Qu, Y . Yan, Z. Wu, D. Zhuang, J. Kai, K. Hou, X. Guo, H. Zhenget al., “Itinera: Integrating spatial optimization with large language models for open-domain urban itinerary planning,”arXiv preprint arXiv:2402.07204, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.