Recognition: unknown
A PVT-Resilient Subthreshold SRAM-Based In-Memory Computing Accelerator with In-Situ Regulation for Energy-Efficient Spiking Neural Networks
Pith reviewed 2026-05-09 19:07 UTC · model grok-4.3
The pith
Subthreshold SRAM CIM with in-situ sensors and regulators enables PVT-resilient SNN acceleration at over 1000 TOPS/W.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that integrating in-situ current sensors, distributed voltage regulators, and memory-cell-based programmable neuron thresholds inside a large-scale subthreshold current-mode SRAM CIM array allows robust operation for spiking neural networks; when paired with stride-tick batching that exploits SNN sparsity and data reuse, the fabricated 28-nm design delivers 93.64% keyword-spotting accuracy, up to 1181.42 TOPS/W, and 7.24 TOPS/mm².
What carries the argument
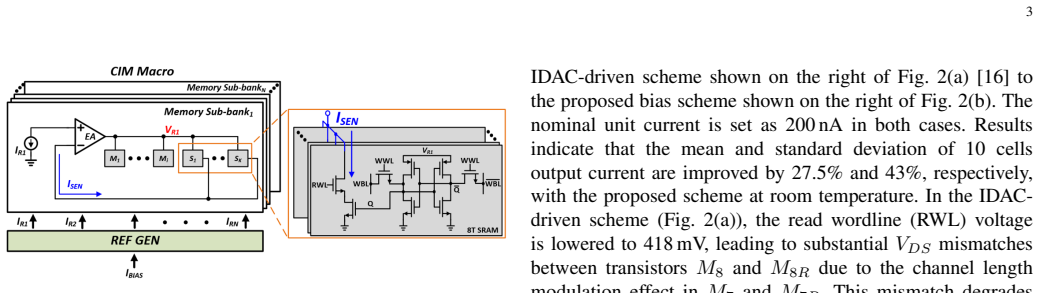
In-situ current sensors and distributed voltage regulators combined with programmable memory-cell-based neuron firing thresholds that stabilize subthreshold current-mode computation across a 1024 wordline by 1304 bitline CIM array.
If this is right
- Exploitation of SNN sparsity yields additional energy savings on top of the baseline CIM design.
- Stride-tick batching measurably cuts buffer overhead and improves input data reuse.
- Programmable neuron thresholds increase robustness to PVT variations without external calibration.
- The overall architecture provides a practical path to high-performance edge SNN hardware.
Where Pith is reading between the lines
- The same in-situ regulation approach could be ported to other low-voltage memory-based accelerators facing similar variation problems.
- The efficiency numbers imply the design might support always-on inference on battery-constrained sensors if the macro is integrated into a full system.
- Scaling the array further would reveal whether regulation overhead grows linearly or sub-linearly with size.
Load-bearing premise
The added sensors and regulators can offset PVT variations in subthreshold current-mode arrays without area or power costs large enough to erase the reported efficiency advantage.
What would settle it
Direct measurement of the fabricated chip across a wide temperature or voltage range that shows accuracy falling below 90% or efficiency below 500 TOPS/W would disprove the claimed resilience and efficiency.
Figures













read the original abstract
This paper presents a PVT-resilient, subthreshold SRAM-based computing-in-memory (CIM) macro tailored for energy-efficient spiking neural networks (SNNs). The macro integrates in-situ current sensors and distributed voltage regulators to enable robust large-scale (1024 wordlines, 1304 bitlines and 128 shared neuron cells) subthreshold current-mode CIM, mitigating energy overheads and process-voltage-temperature (PVT) sensitivity. The neuron cells adopt a programmable, memory cell-based firing threshold to enhance neuron robustness against PVT variations. The architecture uses a stride-tick batching schedule to significantly reduce buffer overhead with enhanced input data reuse. Exploiting the high sparsity of SNNs, the proposed system demonstrates significant improvements in energy efficiency and variation tolerance. Fabricated in 28-nm CMOS, the prototype attains 93.64\% accuracy on keyword spotting, delivers up to 1181.42 TOPS/W, and achieves 7.24 TOPS/mm^2, demonstrating a viable and efficient solution for high-performance edge SNN processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a fabricated 28-nm CMOS subthreshold SRAM-based CIM macro for energy-efficient SNNs. It integrates in-situ current sensors and distributed voltage regulators to mitigate PVT variations in a 1024x1304 current-mode array, uses programmable memory-cell-based neuron thresholds for robustness, and employs stride-tick batching for data reuse and sparsity exploitation. The prototype reports 93.64% accuracy on keyword spotting, peak efficiency of 1181.42 TOPS/W, and 7.24 TOPS/mm².
Significance. If the efficiency and resilience claims hold after isolating overheads and providing full measurement details, this would be a meaningful contribution to edge SNN hardware by demonstrating a viable subthreshold CIM solution with integrated PVT mitigation. The use of a fabricated prototype with concrete metrics is a strength, though the current presentation limits assessment of net gains.
major comments (2)
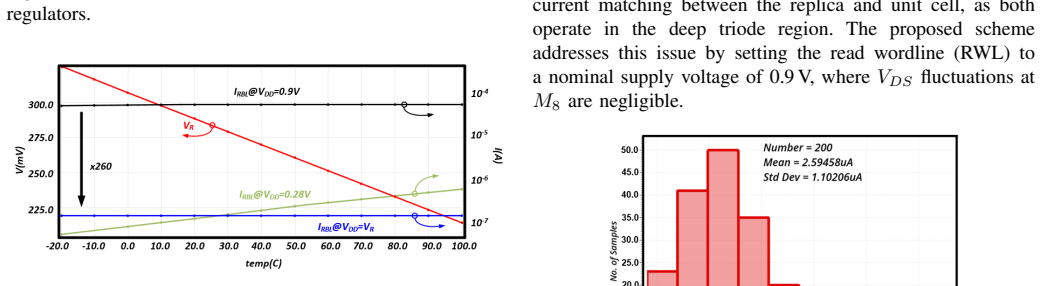
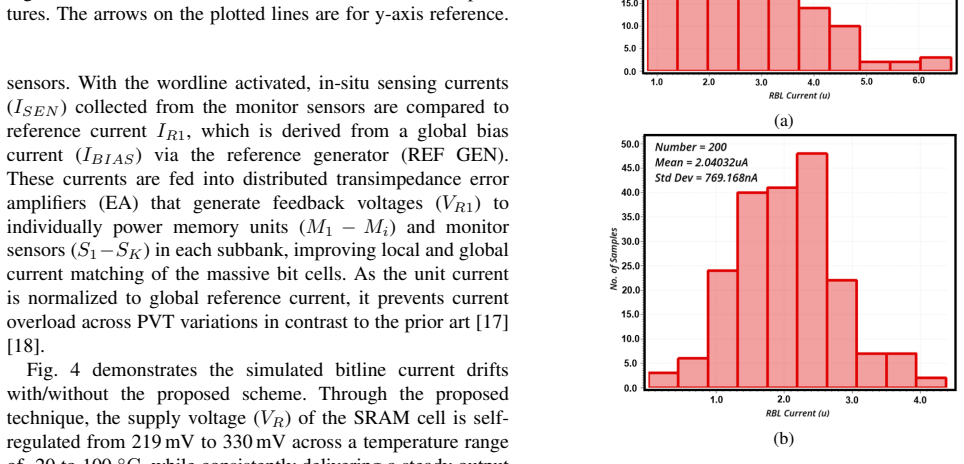
- [Results] Results section: The headline figures of 1181.42 TOPS/W and 7.24 TOPS/mm² are reported for the overall macro without a power or area breakdown that isolates the static and dynamic overheads of the in-situ current sensors, distributed voltage regulators, and programmable neuron thresholds. These blocks are central to the PVT-resilience claim; without separation, it is impossible to confirm that the core CIM efficiency is preserved rather than offset by auxiliary circuitry.
- [Experimental validation] Experimental validation: The abstract and results claim 93.64% accuracy and the efficiency metrics from silicon, yet provide no details on measurement conditions (supply voltage, temperature, clocking), number of dies characterized, error bars, or performance across PVT corners. This omission directly undermines verification of the variation-tolerance claims for the large subthreshold array.
minor comments (1)
- [Abstract] The abstract introduces the array size (1024 wordlines, 1304 bitlines, 128 neurons) late; moving this detail to the opening sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our results and experimental validation. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where possible.
read point-by-point responses
-
Referee: [Results] Results section: The headline figures of 1181.42 TOPS/W and 7.24 TOPS/mm² are reported for the overall macro without a power or area breakdown that isolates the static and dynamic overheads of the in-situ current sensors, distributed voltage regulators, and programmable neuron thresholds. These blocks are central to the PVT-resilience claim; without separation, it is impossible to confirm that the core CIM efficiency is preserved rather than offset by auxiliary circuitry.
Authors: We agree that isolating the overheads of the auxiliary circuits is valuable for rigorously validating the net benefits of our PVT-resilience techniques. The reported figures represent the complete fabricated macro, including all supporting blocks, as this is the relevant system-level performance for edge SNN deployment. In the revised manuscript, we will add a detailed power and area breakdown (both estimated and measured where available) that separates the contributions of the in-situ current sensors, distributed voltage regulators, and programmable neuron thresholds from the core 1024x1304 current-mode array. This will enable readers to assess whether the core CIM efficiency is preserved. revision: yes
-
Referee: [Experimental validation] Experimental validation: The abstract and results claim 93.64% accuracy and the efficiency metrics from silicon, yet provide no details on measurement conditions (supply voltage, temperature, clocking), number of dies characterized, error bars, or performance across PVT corners. This omission directly undermines verification of the variation-tolerance claims for the large subthreshold array.
Authors: We acknowledge that additional experimental details are needed to fully substantiate the variation-tolerance claims. In the revised version, we will expand the results section with the available measurement conditions, including the specific supply voltages, temperature ranges, clocking schemes, number of dies characterized, and any statistical metrics such as error bars from repeated measurements. For PVT corner performance, we will report all data obtained during silicon characterization; where full corner coverage was limited by testing resources, we will explicitly note the scope and any observed trends in resilience. revision: partial
Circularity Check
No significant circularity; experimental hardware prototype with measured results
full rationale
This is a fabricated 28-nm CMOS prototype paper reporting silicon measurements for accuracy (93.64% on keyword spotting), energy efficiency (up to 1181.42 TOPS/W), and area efficiency (7.24 TOPS/mm²). No mathematical derivations, equations, predictive models, or fitted parameters are present that could reduce to inputs by construction. Claims rest on direct experimental benchmarks rather than analytical chains, self-citations, or ansatzes. The report is self-contained against external benchmarks with no load-bearing self-citation or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NIMBLE: A neuromorphic learning scheme and memristor based computing-in- memory engine for EMG based hand gesture recognition,
F. Tian, J. Jiang, J. Liang, Z. Zhang, J. Shi, C. Fanget al., “NIMBLE: A neuromorphic learning scheme and memristor based computing-in- memory engine for EMG based hand gesture recognition,” inIEEE International Symposium on Circuits and Systems (ISCAS), 2022, pp. 2695–2699
2022
-
[2]
A reconfigurable 1T1C eDRAM-based spiking neural network computing-in-memory processor for high system-level efficiency,
S. Kim, S. Kim, S. Um, S. Kim, Z. Li, S. Kimet al., “A reconfigurable 1T1C eDRAM-based spiking neural network computing-in-memory processor for high system-level efficiency,” inIEEE International Sym- posium on Circuits and Systems (ISCAS), 2023, pp. 1–5
2023
-
[3]
An 82nw 0.53pJ/SOP clock-free spiking neural network with 40µs latency for AloT wake-up functions using ultimate-event-driven bionic architecture and computing-in-memory technique,
Y . Liu, Z. Wang, W. He, L. Shen, Y . Zhang, P. Chenet al., “An 82nw 0.53pJ/SOP clock-free spiking neural network with 40µs latency for AloT wake-up functions using ultimate-event-driven bionic architecture and computing-in-memory technique,” inIEEE International Solid-State Circuits Conference (ISSCC), 2022, pp. 372–374
2022
-
[4]
Neuro-CIM: Adc-less neuromorphic computing-in-memory processor with operation gating/stopping and digital-analog networks,
S. Kim, S. Kim, S. Um, S. Kim, K. Kim, and H.-J. Yoo, “Neuro-CIM: Adc-less neuromorphic computing-in-memory processor with operation gating/stopping and digital-analog networks,”IEEE Journal of Solid- State Circuits, vol. 58, no. 10, pp. 2931–2945, 2023
2023
-
[5]
30.2 a 22nm 0.26nw/synapse spike-driven spiking neural network processing unit using time-step-first dataflow and sparsity-adaptive in-memory com- puting,
Y . Liu, Y . Ma, N. Shang, T. Zhao, P. Chen, M. Wuet al., “30.2 a 22nm 0.26nw/synapse spike-driven spiking neural network processing unit using time-step-first dataflow and sparsity-adaptive in-memory com- puting,” inIEEE International Solid-State Circuits Conference (ISSCC), 2024, pp. 484–486
2024
-
[6]
Spinalflow: An architecture and dataflow tailored for spiking neural networks,
S. Narayanan, K. Taht, R. Balasubramonian, E. Giacomin, and P.- E. Gaillardon, “Spinalflow: An architecture and dataflow tailored for spiking neural networks,” in2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 349– 362
2020
-
[7]
Spikesim: An end-to-end compute-in-memory hardware eval- uation tool for benchmarking spiking neural networks,
A. Moitra, A. Bhattacharjee, R. Kuang, G. Krishnan, Y . Cao, and P. Panda, “Spikesim: An end-to-end compute-in-memory hardware eval- uation tool for benchmarking spiking neural networks,”IEEE Transac- tions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 11, pp. 3815–3828, 2023
2023
-
[8]
A 65-nm 8T SRAM compute-in-memory macro with column ADCs for processing neural networks,
C. Yu, T. Yoo, K. T. C. Chai, T. T.-H. Kim, and B. Kim, “A 65-nm 8T SRAM compute-in-memory macro with column ADCs for processing neural networks,”IEEE Journal of Solid-State Circuits, vol. 57, no. 11, pp. 3466–3476, 2022
2022
-
[9]
A 65 nm 73 Kb SRAM-based computing-in-memory macro with dynamic-sparsity controlling,
X. Qiao, J. Song, X. Tang, H. Luo, N. Pan, X. Cuiet al., “A 65 nm 73 Kb SRAM-based computing-in-memory macro with dynamic-sparsity controlling,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 6, pp. 2977–2981, 2022
2022
-
[10]
4b/4b/8b precision charge-domain 8T-SRAM based cim for CNN processing,
Q. Zang, W. L. Goh, Y . S. Chong, and A. T. Do, “4b/4b/8b precision charge-domain 8T-SRAM based cim for CNN processing,” inIEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), 2023, pp. 1–5
2023
-
[11]
A charge domain SRAM compute-in-memory macro with C-2C ladder- based 8-bit MAC unit in 22-nm FinFET process for edge inference,
H. Wang, R. Liu, R. Dorrance, D. Dasalukunte, D. Lake, and B. Carlton, “A charge domain SRAM compute-in-memory macro with C-2C ladder- based 8-bit MAC unit in 22-nm FinFET process for edge inference,” IEEE Journal of Solid-State Circuits, vol. 58, no. 4, pp. 1037–1050, 2023
2023
-
[12]
A 8-b-precision 6T SRAM computing-in-memory macro using segmented- bitline charge-sharing scheme for AI edge chips,
J.-W. Su, Y .-C. Chou, R. Liu, T.-W. Liu, P.-J. Lu, P.-C. Wuet al., “A 8-b-precision 6T SRAM computing-in-memory macro using segmented- bitline charge-sharing scheme for AI edge chips,”IEEE Journal of Solid- State Circuits, vol. 58, no. 3, pp. 877–892, 2023
2023
-
[13]
C3SRAM: An in- memory-computing SRAM macro based on robust capacitive coupling computing mechanism,
Z. Jiang, S. G. Yin, J. sun Seo, M. Seoket al., “C3SRAM: An in- memory-computing SRAM macro based on robust capacitive coupling computing mechanism,”IEEE Journal of Solid-State Circuits, vol. 55, no. 7, pp. 1888–1897, 2020
2020
-
[14]
A 22nm 832Kb hybrid-domain floating-point SRAM in-memory- compute macro with 16.2–70.2 TFLOPS/W for high-accuracy AI-edge devices,
P.-C. Wu, J.-W. Su, L.-Y . Hong, J.-S. Ren, C.-H. Chien, H.-Y . Chen et al., “A 22nm 832Kb hybrid-domain floating-point SRAM in-memory- compute macro with 16.2–70.2 TFLOPS/W for high-accuracy AI-edge devices,” inIEEE International Solid-State Circuits Conference (ISSCC), 2023, pp. 126–128
2023
-
[15]
34.3 a 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs,
A. Guo, F. Dong, J. Chen, Z. Yuan, X. Huet al., “34.3 a 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs,” in IEEE International Solid-State Circuits Conference (ISSCC), 2024, pp. 570–572
2024
-
[16]
A machine-learning classifier implemented in a standard 6T SRAM array,
J. Zhang, Z. Wang, N. Vermaet al., “A machine-learning classifier implemented in a standard 6T SRAM array,” inProceedings of VLSI Symposium on Technology and Circuits, 2016, pp. 1–2
2016
-
[17]
A compilation framework for sram computing-in-memory systems with optimized weight mapping and error correction,
Y . Bai, Y . Li, H. Zhang, A. Jiang, Y . Du, and L. Du, “A compilation framework for sram computing-in-memory systems with optimized weight mapping and error correction,”IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems, vol. 43, no. 8, pp. 2379–2392, 2024
2024
-
[18]
A 28-nm 50.1-tops/w p-8t sram compute- in-memory macro design with bl charge-sharing-based in-sram dac/adc operations,
K. Lee, J. Kim, and J. Park, “A 28-nm 50.1-tops/w p-8t sram compute- in-memory macro design with bl charge-sharing-based in-sram dac/adc operations,”IEEE Journal of Solid-State Circuits, vol. 59, no. 6, pp. 1926–1937–1667, 2024
1926
-
[19]
One timestep is all you need: Training spiking neural networks with ultra low latency,
S. S. Chowdhury, N. Rathi, K. Royet al., “One timestep is all you need: Training spiking neural networks with ultra low latency,”arXiv preprint arXiv:2110.05929, 2021. Shih-Hang Kaoreceived the B. S. and M. S. de- grees in electronics engineering from National Yang Ming Chiao Tung University, Hsinchu, Taiwan, in 2021 and 2024. He is currently working at R...
-
[20]
Since 2004, he has been a Professor with the Electronics Engineering Department, National Chiao Tung University, and served as the Chairperson from 2006 to 2009. From January 2016 to December 2017, he was appointed as the Director General of the Science Education and International Cooperation Department, Ministry of Science and Technology, Taiwan. He was ...
2004
-
[21]
He served as the Institute director from 2015-2018
He is a professor at the Institute of Electronics and Department of Electronics and Electrical Engi- neering, National Yang Ming Chiao Tung University (NYCU). He served as the Institute director from 2015-2018. He was the Deputy Executive Director of the National SoC Program and the Principal Investigator of the National Project on Intelligent Electronics...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.