Recognition: unknown
VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
Pith reviewed 2026-05-09 19:02 UTC · model grok-4.3
The pith
VitaLLM accelerator runs 3B ternary LLM at 72 tokens per second on a 0.214 mm² edge chip.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
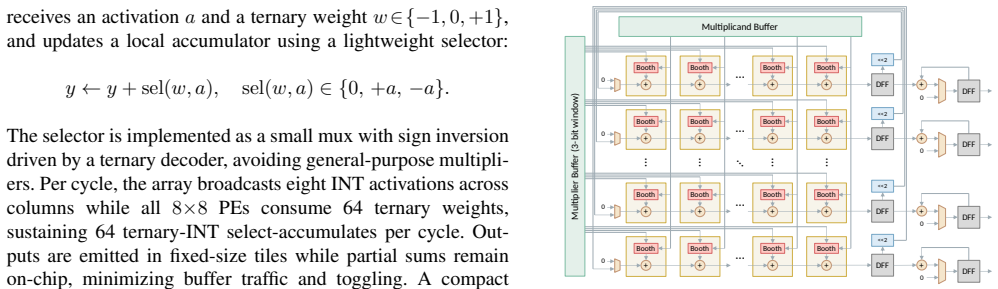
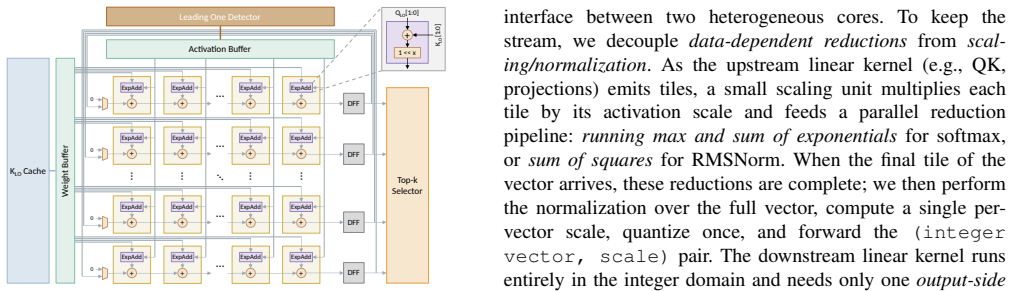
VitaLLM is a versatile and tiny accelerator for ternary-weight LLMs that pairs a multiplier-free TINT core for ternary-INT projections with a BoothFlex core that reuses a radix-4 Booth datapath for both INT8 attention and ternary-INT operations. A predictive sparse attention mechanism based on a leading-one surrogate and comparison-free top-K selector prunes KV fetches by roughly 1 minus K over M, limiting exact computation to K candidates. Head-level pipelining and an absmax quantization barrier overlap nonlinear work with linear tiles and standardize data movement. The resulting 16 nm silicon prototype at 1 GHz and 0.8 V delivers 72.46 tokens per second in decode and 0.88 seconds prefill (
What carries the argument
Dual TINT and BoothFlex cores plus leading-one surrogate predictive sparse attention that prunes KV cache traffic while preserving mixed-precision execution.
If this is right
- KV cache traffic drops by a factor of roughly 1 minus K over M while attention accuracy is preserved through the top-K selection.
- The BoothFlex core reuses existing hardware to support both INT8 and ternary workloads without extra array duplication.
- Head-level pipelining overlaps nonlinear reductions with linear tiles and keeps cross-core data movement standardized via absmax barriers.
- The achieved area of 0.214 mm² and 120 KB on-chip memory makes 3B-scale ternary inference feasible on edge-class platforms.
Where Pith is reading between the lines
- The pruning technique could be tested on other sparse attention variants or non-transformer models to see if the surrogate remains effective.
- Scaling the same dual-core approach to models larger than 3B would require checking whether memory bandwidth stays the limiting factor.
- The design choices around Booth reuse and pipelining might inform mixed-precision accelerators for vision or audio transformers.
- Real-world power measurements on the prototype would clarify whether the reported speed translates to battery-friendly operation in actual devices.
Load-bearing premise
The leading-one surrogate in the sparse attention prunes KV fetches without hurting LLM output accuracy and the mixed-precision cores stay correct across all model layers.
What would settle it
Measure end-to-end accuracy of the full BitNet b1.58 3B model when running on the prototype versus the same model in full-precision software; a drop beyond typical quantization tolerance would falsify the claim.
Figures






read the original abstract
We present VitaLLM, a mixed precision accelerator that enables ternary weight large language models to run efficiently on edge devices. The design combines two compute cores, a multiplier free TINT core for ternary-INT projections and a BoothFlex core that reuses a radix-4 Booth datapath for both INT8$\times$INT8 attention and ternary-INT-sustaining utilization without duplicating arrays. A predictive sparse attention mechanism employs a leading-one (LO) surrogate with a comparison-free top-$K$ selector to prune key/value (KV) fetches by roughly $1-K/M$ for $M$ cached tokens, confining exact attention to $K$ candidates. System-level integration uses head-level pipelining and an absmax-based quantization barrier to standardize cross-core interfaces and overlap nonlinear reductions with linear tiles. A 16 nm silicon prototype at 1 GHz/0.8 V achieves 72.46 tokens/s in decode and 0.88 s prefill (64 tokens) within 0.214 mm^2 and 120 KB on-chip memory, while reducing KV traffic and improving utilization in ablations. These results demonstrate practical BitNet b1.58 (3B) inference on edge-class platforms and provide a compact blueprint for future mixed-precision LLM accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VitaLLM, a mixed-precision accelerator for ternary-weight LLMs (e.g., BitNet b1.58 3B) on edge devices. It integrates a multiplier-free TINT core for ternary-INT projections and a BoothFlex core reusing radix-4 Booth datapath for INT8 attention and mixed operations. A predictive sparse attention employs a leading-one surrogate with comparison-free top-K to prune KV fetches by ~1-K/M. Head-level pipelining and absmax quantization standardize interfaces. A 16 nm silicon prototype at 1 GHz/0.8 V reports 72.46 tokens/s decode and 0.88 s prefill (64 tokens) in 0.214 mm² with 120 KB on-chip memory, plus ablations on traffic and utilization.
Significance. If the functional correctness of the sparse attention holds, the work offers a compact, measured silicon blueprint for practical edge LLM inference that combines mixed-precision cores with predictive pruning. The physical 16 nm prototype with concrete performance, area, and power metrics is a notable strength, providing reproducible hardware evidence rather than simulation-only claims.
major comments (2)
- [Abstract] Abstract and results: the central claim of 'practical BitNet b1.58 (3B) inference' depends on the leading-one surrogate + top-K pruning preserving model quality. No perplexity, zero-shot, or layer-wise accuracy deltas are reported for the pruned attention versus dense at the operating K/M ratio; ablations address only traffic and utilization.
- [Sparse attention description] Sparse attention mechanism: the assumption that the LO surrogate prunes KV fetches without unacceptable quality loss is load-bearing for the 'practical' qualifier, yet no end-to-end accuracy validation or comparison to dense attention is supplied, leaving the functional-correctness claim unverified.
minor comments (2)
- Clarify the exact K and M values used in the prototype experiments and how they map to the reported 1-K/M traffic reduction.
- [Abstract] The abstract states 'reducing KV traffic and improving utilization in ablations' but does not specify the baseline dense configuration or the number of runs for the silicon measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the 16 nm silicon prototype. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the central claim of 'practical BitNet b1.58 (3B) inference' depends on the leading-one surrogate + top-K pruning preserving model quality. No perplexity, zero-shot, or layer-wise accuracy deltas are reported for the pruned attention versus dense at the operating K/M ratio; ablations address only traffic and utilization.
Authors: We agree that the manuscript does not report perplexity, zero-shot, or layer-wise accuracy comparisons between the pruned and dense attention at the operating K/M ratios. The presented ablations quantify only the hardware-level benefits (KV traffic reduction and utilization). To support the 'practical' qualifier, we will add end-to-end model-quality evaluations (perplexity and zero-shot tasks) for the relevant K/M operating points in the revised manuscript. revision: yes
-
Referee: [Sparse attention description] Sparse attention mechanism: the assumption that the LO surrogate prunes KV fetches without unacceptable quality loss is load-bearing for the 'practical' qualifier, yet no end-to-end accuracy validation or comparison to dense attention is supplied, leaving the functional-correctness claim unverified.
Authors: The leading-one surrogate is introduced to approximate attention scores for comparison-free top-K selection and thereby reduce KV fetches. While the hardware implementation and traffic savings are measured on silicon, we acknowledge that no direct accuracy validation against dense attention is supplied. We will incorporate such end-to-end and layer-wise accuracy results in the revision to verify that quality degradation remains acceptable. revision: yes
Circularity Check
No circularity: hardware implementation with measured silicon results
full rationale
The paper describes a mixed-precision accelerator design and reports empirical performance numbers from a fabricated 16 nm prototype (1 GHz/0.8 V, 72.46 tokens/s decode, 0.88 s prefill). No mathematical derivation chain, predictive equations, or self-referential fitting steps exist; the central claims rest on physical measurements and ablations of traffic/utilization rather than any quantity that reduces to its own inputs by construction. The sparse-attention mechanism is presented as a design choice whose quality impact is asserted but not derived mathematically within the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard digital VLSI design and fabrication processes in 16nm technology are reliable and follow established rules.
invented entities (2)
-
TINT core
no independent evidence
-
BoothFlex core
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Ma, H. Wang, L. Ma, L. Wang, W. Wang, S. Huang, L. Dong, R. Wang, J. Xue, and F. Wei, “The era of 1-bit LLMs: All large language models are in 1.58 bits,”arXiv preprint arXiv:2402.17764v1, 2024
-
[2]
Bitnet b1.58 2b4t technical report,
S. Ma, H. Wang, S. Huang, X. Zhang, Y . Hu, T. Song, Y . Xia, and F. Wei, “BitNet b1.58 2b4t technical report,”arXiv preprint arXiv:2504.12285v2, 2024
-
[3]
Slim-Llama: A 4.69mw large-language- model processor with binary/ternary weights for billion-parameter llama model,
S. Kim, J. Lee, and H.-J. Yoo, “Slim-Llama: A 4.69mw large-language- model processor with binary/ternary weights for billion-parameter llama model,” in2025 IEEE International Solid-State Circuits Conference (ISSCC), 2025, pp. 422–423
2025
-
[4]
TerEffic: Highly efficient ternary LLM inference on FPGA,
C. Yin, Z. Bai, P. Venkatram, S. Aggarval, Z. Li, and T. Mitra, “Ter- Effic: Highly efficient ternary LLM inference on FPGA,”arXiv preprint arXiv:2502.16473v2, 2025
-
[5]
TeLLMe: An energy-efficient ternary LLM accelerator for prefill and decode on edge FPGAs,
Y . Qiao, Z. Chen, Y . Zhang, Y . Wang, and S. Huang, “TeLLMe: An energy-efficient ternary LLM accelerator for prefill and decode on edge FPGAs,”arXiv preprint arXiv:2504.16266v2, 2025
-
[6]
k-degree parallel comparison-free hardware sorter for complete sorting,
S. S. Ray and S. Ghosh, “k-degree parallel comparison-free hardware sorter for complete sorting,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 5, pp. 1438–1449, May 2023
2023
-
[8]
Systolicattention: Fus- ing flashattention within a single systolic array,
[Online]. Available: https://arxiv.org/abs/2507.11331
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.