Recognition: unknown
Embodied Interpretability: Linking Causal Understanding to Generalization in Vision-Language-Action Models
Pith reviewed 2026-05-09 19:41 UTC · model grok-4.3
The pith
Interventional attribution reveals when vision-language-action models depend on spurious features rather than true causes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate visual-action attribution as an interventional estimation problem. Accordingly, we introduce the Interventional Significance Score (ISS), an interventional masking procedure for estimating the causal influence of visual regions on action predictions, and the Nuisance Mass Ratio (NMR), a scalar measure of attribution to task-irrelevant features. We analyze the statistical properties of ISS and show that it admits unbiased estimation, and we characterize conditions under which action prediction error provides a valid proxy for causal influence. Experiments across diverse manipulation tasks indicate that NMR predicts generalization behavior and that ISS yields more faithful explana
What carries the argument
The interventional masking procedure that computes the Interventional Significance Score (ISS) by measuring the effect on action predictions when specific visual regions are masked out, along with the Nuisance Mass Ratio (NMR) that aggregates attribution to irrelevant features.
Load-bearing premise
The interventional masking procedure yields unbiased estimates of causal influence on actions and action prediction error serves as a valid proxy for causal influence under the characterized conditions.
What would settle it
Running the experiments and finding no correlation between NMR values and actual generalization performance on new tasks, or finding that ISS explanations do not outperform baselines when compared to ground-truth causal interventions.
Figures











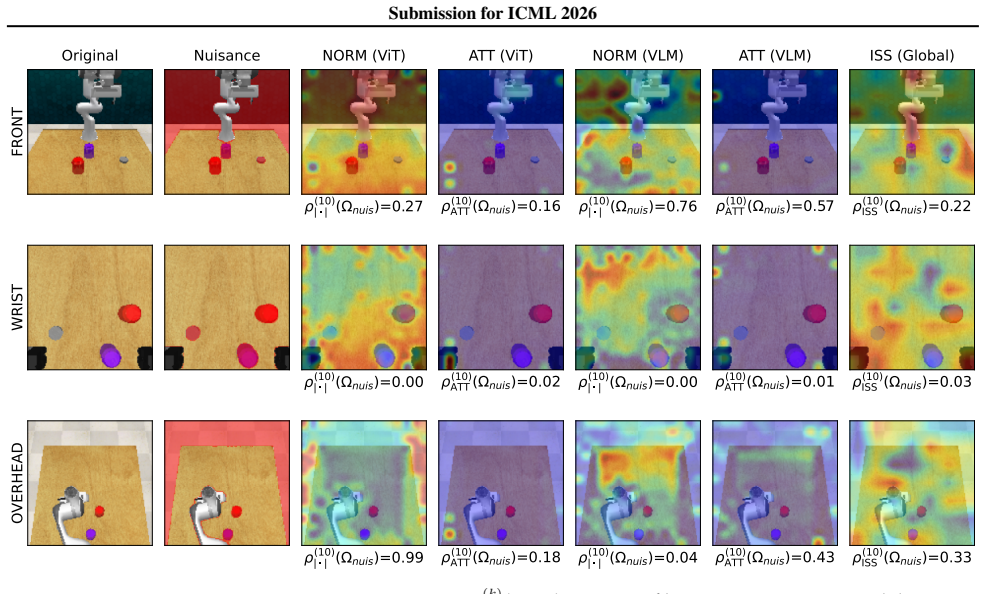

read the original abstract
Vision-Language-Action (VLA) policies often fail under distribution shift, suggesting that decisions may depend on spurious visual correlations rather than task-relevant causes. We formulate visual-action attribution as an interventional estimation problem. Accordingly, we introduce the Interventional Significance Score (ISS), an interventional masking procedure for estimating the causal influence of visual regions on action predictions, and the Nuisance Mass Ratio (NMR), a scalar measure of attribution to task-irrelevant features. We analyze the statistical properties of ISS and show that it admits unbiased estimation, and we characterize conditions under which action prediction error provides a valid proxy for causal influence. Experiments across diverse manipulation tasks indicate that NMR predicts generalization behavior and that ISS yields more faithful explanations than existing interpretability methods. These results suggest that interventional attribution provides a simple diagnostic approach for identifying causal misalignment in embodied policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates visual-action attribution in Vision-Language-Action (VLA) policies as an interventional estimation problem. It introduces the Interventional Significance Score (ISS), an interventional masking procedure claimed to estimate causal influence of visual regions on actions with unbiased statistical properties, and the Nuisance Mass Ratio (NMR), a scalar quantifying attribution to task-irrelevant features. The work characterizes conditions under which action prediction error serves as a valid proxy for causal influence, and reports experiments on diverse manipulation tasks showing that NMR predicts generalization behavior while ISS produces more faithful explanations than existing interpretability methods.
Significance. If the unbiased estimation property of ISS and the predictive link from NMR to generalization hold under realistic conditions, the work supplies a practical diagnostic for causal misalignment in embodied policies. This could help identify when VLA models rely on spurious visual correlations, informing more robust training regimes or architectures in robotics. The explicit formulation as interventional estimation and the introduction of NMR as a generalization predictor are concrete contributions that tie interpretability directly to a key failure mode in the field.
major comments (1)
- [Abstract / statistical properties of ISS] Abstract and statistical properties section: the claim that ISS 'admits unbiased estimation' and that action prediction error is a valid proxy under 'characterized conditions' does not explicitly bound the degree of feature dependence or account for nonlinear feature extraction in VLA models. In manipulation datasets, visual regions (e.g., gripper pose and object position) are typically correlated; masking one region can implicitly alter encodings of correlated task-relevant features, potentially biasing the interventional estimates even when the stated proxy conditions hold. This directly affects both the NMR-generalization link and the claim of greater faithfulness versus baselines.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the precise proxy conditions (e.g., independence assumptions or error bounds) rather than referring only to 'characterized conditions.'
- [Experiments] Experiments section: clarify how the diverse manipulation tasks were selected and whether they include controlled distribution shifts that isolate spurious correlations versus genuine causal features.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on the statistical properties of ISS. The concern regarding unaddressed feature dependence and nonlinear extraction is well-taken and points to a place where the manuscript can be strengthened. We respond to the major comment below and will incorporate revisions to make the assumptions and their limitations more explicit.
read point-by-point responses
-
Referee: [Abstract / statistical properties of ISS] Abstract and statistical properties section: the claim that ISS 'admits unbiased estimation' and that action prediction error is a valid proxy under 'characterized conditions' does not explicitly bound the degree of feature dependence or account for nonlinear feature extraction in VLA models. In manipulation datasets, visual regions (e.g., gripper pose and object position) are typically correlated; masking one region can implicitly alter encodings of correlated task-relevant features, potentially biasing the interventional estimates even when the stated proxy conditions hold. This directly affects both the NMR-generalization link and the claim of greater faithfulness versus baselines.
Authors: We appreciate the referee highlighting this subtlety. In the statistical properties section, unbiasedness of ISS is derived by treating the VLA model as a black-box mapping from masked inputs to actions; the intervention is realized by zeroing out selected visual regions and measuring the resulting change in prediction error. Because the error is evaluated after the model's full (nonlinear) feature extraction pipeline, the derivation already incorporates arbitrary nonlinearities in the encoder. However, the stated conditions for the proxy do assume that the masked region is the dominant causal variable and do not explicitly quantify allowable correlations between regions. The referee is correct that, in typical manipulation data, gripper and object features are correlated, so masking one region can indirectly affect the encoding of the other and thereby introduce bias. We will revise the manuscript to (i) add an explicit bound on feature dependence (e.g., a correlation-coefficient threshold under which the bias remains below a stated tolerance), (ii) include a short limitations paragraph discussing the interaction of nonlinear extraction with correlated inputs, and (iii) note the consequent implications for the NMR-generalization correlation and for comparisons against baseline attribution methods. These additions will be placed in the statistical properties section and the experimental discussion without changing the core claims or experimental results. revision: yes
Circularity Check
No circularity: definitions and claims remain independent of fitted outputs
full rationale
The paper formulates visual-action attribution as an interventional estimation problem, defines ISS via masking, proves unbiasedness from statistical properties of that procedure, and separately characterizes conditions for the prediction-error proxy. NMR is then defined as a derived scalar from those attributions. None of these steps reduce by construction to the experimental outcomes or to self-referential fitting; the generalization link is presented as an empirical observation rather than a definitional identity. No self-citation chains or ansatz smuggling appear in the provided derivation outline.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Action prediction error provides a valid proxy for causal influence under characterized conditions
- domain assumption Interventional masking yields unbiased estimation of causal influence
invented entities (2)
-
Interventional Significance Score (ISS)
no independent evidence
-
Nuisance Mass Ratio (NMR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Forty-Second
Chen, Letian and Moorman, Nina Marie and Gombolay, Matthew Craig , year =. Forty-Second
-
[2]
Forty-Second
Huang, Huang and Liu, Fangchen and Fu, Letian and Wu, Tingfan and Mukadam, Mustafa and Malik, Jitendra and Goldberg, Ken and Abbeel, Pieter , year =. Forty-Second
-
[3]
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models , booktitle =
Shi, Lucy Xiaoyang and Equi, Michael Robert and Ke, Liyiming and Pertsch, Karl and Vuong, Quan and Tanner, James and Walling, Anna and Wang, Haohuan and Fusai, Niccolo and. Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models , booktitle =
-
[4]
Forty-Second
Zhang, Hongyin and Zhuang, Zifeng and Zhao, Han and Ding, Pengxiang and Lu, Hongchao and Wang, Donglin , year =. Forty-Second
-
[5]
Forty-Second
Zhang, Jianke and Guo, Yanjiang and Hu, Yucheng and Chen, Xiaoyu and Zhu, Xiang and Chen, Jianyu , year =. Forty-Second
-
[6]
Proceedings of the 41st
Zhen, Haoyu and Qiu, Xiaowen and Chen, Peihao and Yang, Jincheng and Yan, Xin and Du, Yilun and Hong, Yining and Gan, Chuang , year =. Proceedings of the 41st
-
[7]
Counterfactual
Peng, Zhenghao and Ding, Wenhao and You, Yurong and Chen, Yuxiao and Luo, Wenjie and Tian, Thomas and Cao, Yulong and Sharma, Apoorva and Xu, Danfei and Ivanovic, Boris , year =. Counterfactual
-
[8]
The 25th International Conference on Autonomous Agents and Multi-Agent Systems , year=
Don’t Blind Your VLA: Aligning Visual Representations for OOD Generalization , author=. The 25th International Conference on Autonomous Agents and Multi-Agent Systems , year=
-
[9]
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective,
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective , author=. Arxiv Preprint Arxiv:2507.01925 , year=
-
[10]
Arxiv Preprint Arxiv:2511.18617 , year=
AutoFocus-IL: VLM-based Saliency Maps for Data-Efficient Visual Imitation Learning without Extra Human Annotations , author=. Arxiv Preprint Arxiv:2511.18617 , year=
-
[11]
arXiv preprint arXiv:2512.11921 , year =
Towards Accessible Physical AI: LoRA-Based Fine-Tuning of VLA Models for Real-World Robot Control , author=. Arxiv Preprint Arxiv:2512.11921 , year=
-
[12]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models , author=. Arxiv Preprint Arxiv:2510.13626 , year=
work page internal anchor Pith review arXiv
-
[13]
Arxiv Preprint Arxiv:2601.16065 , year=
DTP: A Simple yet Effective Distracting Token Pruning Framework for Vision-Language Action Models , author=. Arxiv Preprint Arxiv:2601.16065 , year=
-
[14]
2025 , journal =
Mechanistic Finetuning of Vision-Language-Action Models via Few-Shot Demonstrations , author =. 2025 , journal =
2025
-
[15]
2022 , journal =
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks , author =. 2022 , journal =
2022
-
[16]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author=. Arxiv Preprint Arxiv:2502.19645 , year=
work page internal anchor Pith review arXiv
-
[17]
Arxiv Preprint Arxiv:2505.13888 , year=
InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning , author=. Arxiv Preprint Arxiv:2505.13888 , year=
-
[18]
Ruijie Zheng and Yongyuan Liang and Shuaiyi Huang and Jianfeng Gao and Hal Daum. Trace. The Thirteenth International Conference on Learning Representations , year=
-
[19]
Arxiv Preprint Arxiv:2510.16281 , year=
Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment Verification , author=. Arxiv Preprint Arxiv:2510.16281 , year=
-
[20]
2022 , journal =
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author =. 2022 , journal =
2022
-
[21]
2025 , journal =
Towards Reliable Code-as-Policies: A Neuro-Symbolic Framework for Embodied Task Planning , author =. 2025 , journal =
2025
-
[22]
2025 , journal =
Mechanistic Interpretability for Steering Vision-Language-Action Models , author =. 2025 , journal =
2025
-
[23]
2023 , journal =
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models , author =. 2023 , journal =
2023
-
[24]
2025 , journal =
Probing a Vision-Language-Action Model for Symbolic States and Integration into a Cognitive Architecture , author =. 2025 , journal =
2025
-
[25]
Emergent World Representations in
Molinari, Marco and Nevali, Leonardo and Navani, Saharsha and Younis, Omar G , year =. Emergent World Representations in
-
[26]
2024 , journal =
Words in Motion: Extracting Interpretable Control Vectors for Motion Transformers , author =. 2024 , journal =
2024
-
[27]
Wang, Zhihao and Li, Jianxiong and Zheng, Jinliang and Zhang, Wencong and Liu, Dongxiu and Zheng, Yinan and Niu, Haoyi and Yu, Junzhi and Zhan, Xianyuan , year =
-
[28]
Concept-Based Dictionary Learning for Inference-Time Safety in Vision
Siqi Wen and Shu Yang and Shaopeng Fu and Jingfeng Zhang and Lijie Hu and Di Wang , year=. Concept-Based Dictionary Learning for Inference-Time Safety in Vision
-
[29]
Towards Reliable
Yin, Shiyuan and Bai, Chenjia and Zhang, Zihao and Jin, Junwei and Zhang, Xinxin and Zhang, Chi and Li, Xuelong , year =. Towards Reliable
-
[30]
Zhang, Dapeng and Shen, Fei and Zhao, Rui and Chen, Yinda and Zhi, Peng and Li, Chenyang and Zhou, Rui and Zhou, Qingguo , year =
-
[31]
Pure Vision Language Action (
Zhang, Dapeng and Sun, Jin and Hu, Chenghui and Wu, Xiaoyan and Yuan, Zhenlong and Zhou, Rui and Shen, Fei and Zhou, Qingguo , year =. Pure Vision Language Action (
-
[32]
, year =
Zhao, Et Al. , year =. Proceedings of the
-
[33]
Robotics: Science and Systems XIX , year=
RT-1: Robotics Transformer for Real-World Control at Scale , author=. Robotics: Science and Systems XIX , year=
-
[34]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[35]
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and Ted Xiao and Ashwin Balakrishna and Suraj Nair and Rafael Rafailov and Ethan P Foster and Pannag R Sanketi and Quan Vuong and Thomas Kollar and Benjamin Burchfiel and Russ Tedrake and Dorsa Sadigh and Sergey Levine and Percy Liang and Chelsea Finn , booktitle=. Open. 2024 , url=
2024
-
[36]
First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024 , year=
Octo: An Open-Source Generalist Robot Policy , author=. First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024 , year=
2024
-
[37]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. Arxiv Preprint Arxiv:2410.24164 , year=
work page internal anchor Pith review arXiv
-
[38]
Vision-language-action model with open- world embodied reasoning from pretrained knowledge
Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge , author=. Arxiv Preprint Arxiv:2505.21906 , year=
-
[39]
Advances in neural information processing systems , volume=
Decision Transformer: Reinforcement Learning via Sequence Modeling , author=. Advances in neural information processing systems , volume=
-
[40]
2014 , publisher=
Probabilistic reasoning in intelligent systems: networks of plausible inference , author=. 2014 , publisher=
2014
-
[41]
1988 , publisher=
Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference , author=. 1988 , publisher=
1988
-
[42]
Probabilistic and causal inference: The works of Judea Pearl , pages=
Equivalence and Synthesis of Causal Models , author=. Probabilistic and causal inference: The works of Judea Pearl , pages=. 2022 , publisher =
2022
-
[43]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Exploring the Limits of Vision-Language-Action Manipulation in Cross-task Generalization , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[44]
International Conference on Machine Learning , pages=
Certified Adversarial Robustness via Randomized Smoothing , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[45]
Advances in neural information processing systems , volume=
Provably Robust Deep Learning via Adversarially Trained Smoothed Classifiers , author=. Advances in neural information processing systems , volume=
-
[46]
IEEE Robotics and Automation Letters , volume=
Rlbench: The robot learning benchmark & learning environment , author=. IEEE Robotics and Automation Letters , volume=. 2020 , publisher=
2020
-
[47]
Causality , publisher=
Pearl, Judea , year=. Causality , publisher=
-
[48]
The Do-Calculus Revisited , booktitle =
Judea Pearl , editor =. The Do-Calculus Revisited , booktitle =
-
[49]
Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Palma, Steven and Kooijmans, Pepijn and Aractingi, Michel and Shukor, Mustafa and Aubakirova, Dana and Russi, Martino and Capuano, Francesco and Pascal, Caroline and Choghari, Jade and Moss, Jess and Wolf, Thomas , title =
-
[50]
RISE: Randomized Input Sampling for Explanation of Black-box Models
Rise: Randomized input sampling for explanation of black-box models , author=. Arxiv Preprint Arxiv:1806.07421 , year=
-
[51]
2016 , publisher=
Information geometry and its applications , author=. 2016 , publisher=
2016
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
PaliGemma: A versatile 3B VLM for transfer
Paligemma: A versatile 3b vlm for transfer , author=. arXiv preprint arXiv:2407.07726 , year=
work page internal anchor Pith review arXiv
-
[54]
Neural computation , volume=
A learning algorithm for continually running fully recurrent neural networks , author=. Neural computation , volume=. 1989 , publisher=
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.