Recognition: unknown
Measuring the largest coefficients of a quantum state
Pith reviewed 2026-05-09 19:55 UTC · model grok-4.3
The pith
A hierarchical algorithm identifies the largest Pauli coefficients of an n-qubit state by pruning a tree of partial weight sums estimated via Bell sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a best-first traversal of the Pauli prefix tree, guided by additive weight estimates obtained from Bell sampling, recovers the k largest squared Pauli coefficients of a sufficiently pure and sparse n-qubit state while expanding only a number of nodes polynomial in k and 1/purity, thereby avoiding the exponential cost of full Pauli tomography.
What carries the argument
A prefix tree whose nodes store partial sums of squared Pauli coefficients; node weights are estimated by Bell sampling on two copies of the state (or SWAP tests on subsystems) and the search always expands the currently heaviest estimated branches.
If this is right
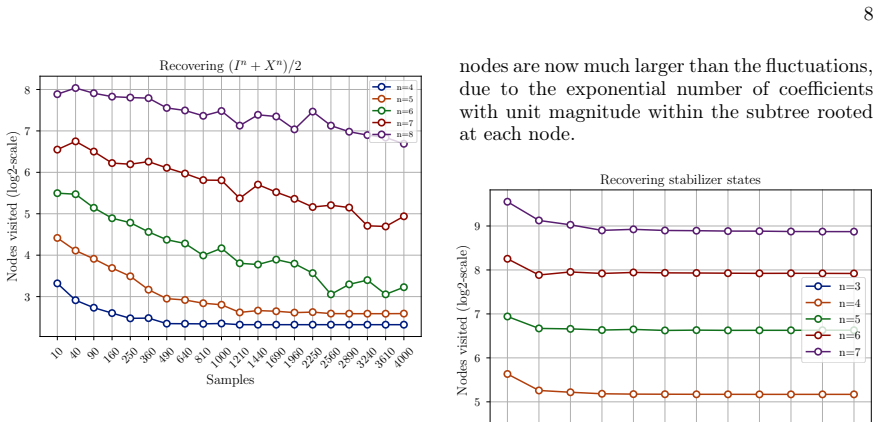
- For states whose Pauli expansion contains only k dominant terms the algorithm returns those terms with sample cost scaling with k and 1/purity rather than with 4^n.
- The same tree can be used to certify that a prepared state is close to a given sparse Pauli mixture without performing full tomography.
- Bounds on expanded nodes give an explicit trade-off between reconstruction accuracy and measurement budget for any fixed purity.
- The method directly supplies the dominant Pauli operators needed for efficient classical post-processing of stabilizer or Clifford circuits.
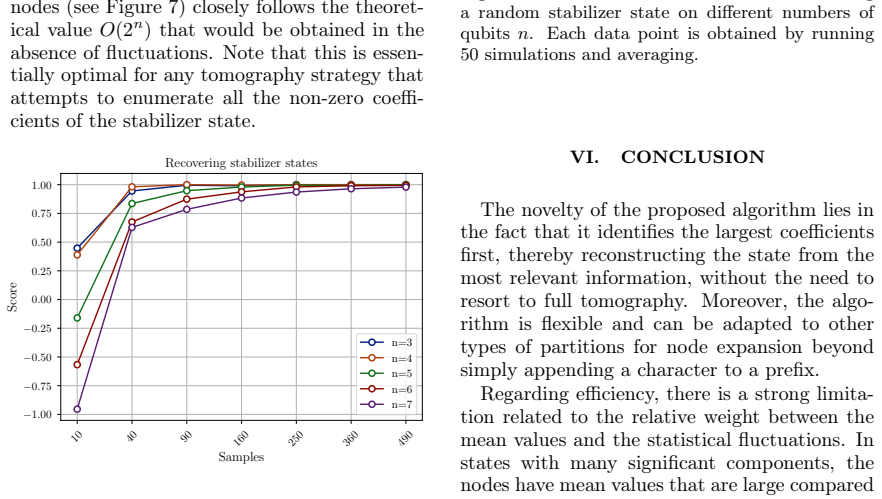
- Numerical evidence indicates the procedure remains reliable on random stabilizer states whose sparsity grows mildly with n.
Where Pith is reading between the lines
- The same pruning logic could be applied to other operator bases such as the Heisenberg-Weyl basis for qudits.
- Combining the tree estimates with classical-shadow post-processing might reduce the variance of the node weights without increasing circuit depth.
- The algorithm naturally lends itself to adaptive measurement scheduling on near-term devices where only a limited number of copies can be prepared in parallel.
- If the state is known to be a mixture of few stabilizer states the tree depth could be restricted to the Clifford subgroup, further lowering the branching factor.
Load-bearing premise
The unknown state must be sparse enough in the Pauli basis that the dominant coefficients can be isolated by ranking partial weight sums, and the Bell-sampling or SWAP estimates must be accurate enough to prune the correct branches.
What would settle it
Prepare a known Pauli eigenstate or low-weight stabilizer state, run the algorithm with a modest number of samples, and check whether it returns the exact dominant coefficients while expanding far fewer than 4^n nodes; failure to recover the known large terms would falsify the pruning guarantee.
Figures




read the original abstract
We introduce a hierarchical algorithm for identifying the largest Pauli coefficients of an unknown $n$-qubit quantum state. The algorithm traverses a prefix-based tree whose nodes represent partial sums of squared Pauli coefficients, always expanding branches with the largest estimated weight and discarding the rest. Node weights are estimated using Bell sampling on two copies of the state, or alternatively via SWAP tests on subsystems. We analyze the sample complexity of each node estimation and derive bounds on the total number of nodes expanded as a function of the desired number of coefficients and the state's purity. For states admitting a sparse representation in the Pauli basis, the algorithm achieves a good reconstruction of the dominant components without requiring full state tomography. We validate the method with numerical simulations on Pauli-singleton states and random stabilizer states, showing that the algorithm's performance is competitive with other methods for structured states. Our work addresses an open problem in Pauli sampling and provides a practical tool for the targeted characterization of structured quantum states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a hierarchical prefix-tree algorithm for identifying the largest Pauli coefficients of an n-qubit quantum state. The algorithm expands nodes representing partial sums of squared coefficients by always selecting the branch with the largest estimated weight (via Bell sampling on two copies or SWAP tests on subsystems) and prunes the rest. Sample complexity per node is analyzed and bounds on the total number of expanded nodes are derived as a function of the target number of coefficients and the state's purity. The method is validated through numerical simulations on Pauli-singleton states and random stabilizer states, claiming competitiveness with other approaches for structured states without requiring full tomography.
Significance. If the estimator concentration guarantees correct pruning order, the work provides a targeted, sample-efficient tool for characterizing Pauli-sparse quantum states, directly addressing an open problem in Pauli sampling. Strengths include the explicit dependence of the node-expansion bound on purity and sparsity, the use of standard estimation primitives (Bell sampling, SWAP tests), and the numerical validation on concrete state families that demonstrates practical performance.
major comments (1)
- [Sample complexity analysis] The sample-complexity analysis and node-expansion bounds (described in the abstract and presumably detailed in the main text) assume that node-weight estimates from Bell sampling or SWAP tests preserve the true ranking sufficiently well to avoid pruning branches containing large coefficients. No explicit union bound or concentration analysis over the full tree depth and multiple sibling comparisons is referenced, leaving open whether the total sample budget remains favorable when coefficients near the cutoff have comparable magnitudes and estimation variance can flip rankings.
minor comments (2)
- The claim of 'good reconstruction' in the abstract would benefit from a precise error metric (e.g., l2 or l-infinity distance to the true dominant coefficients) rather than a qualitative statement.
- Clarify whether the purity bound is assumed known a priori or estimated on the fly, as this affects the practical applicability of the node-expansion bound.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying a point that strengthens the rigor of our sample-complexity claims. We address the concern below and will incorporate the suggested analysis in the revised version.
read point-by-point responses
-
Referee: [Sample complexity analysis] The sample-complexity analysis and node-expansion bounds (described in the abstract and presumably detailed in the main text) assume that node-weight estimates from Bell sampling or SWAP tests preserve the true ranking sufficiently well to avoid pruning branches containing large coefficients. No explicit union bound or concentration analysis over the full tree depth and multiple sibling comparisons is referenced, leaving open whether the total sample budget remains favorable when coefficients near the cutoff have comparable magnitudes and estimation variance can flip rankings.
Authors: We agree that an explicit union bound over the sequence of estimation and comparison steps is a useful addition for completeness. The current analysis (detailed in the sections on Bell sampling and SWAP-test estimators) already supplies per-node concentration: for any fixed node, O(1/ε² log(1/δ)) samples suffice to estimate its weight to additive accuracy ε with probability 1-δ. The node-expansion bound (Theorem on tree size) limits the total number of nodes visited to a quantity linear in the target sparsity k and inversely proportional to the purity. In the revision we will add a global failure-probability argument that takes a union bound over all nodes expanded and all sibling comparisons performed at each level. Because the number of such events is bounded by the node-expansion result, the per-node sample count increases by only an additive O(log(k/δ)) factor. This keeps the overall sample complexity favorable. When coefficients near the cutoff are close in magnitude, the same argument shows that the algorithm correctly retains all sufficiently large coefficients provided the per-node precision ε is chosen smaller than the minimum gap of interest; the bounds therefore continue to hold with high probability. revision: yes
Circularity Check
No significant circularity; algorithmic bounds derived independently
full rationale
The paper introduces a hierarchical prefix-tree algorithm that estimates node weights via Bell sampling or SWAP tests, then derives analytical sample-complexity bounds per node and limits on total nodes expanded as explicit functions of target sparsity and purity. These bounds are obtained by standard concentration analysis on the estimators and tree-pruning rules; they do not reduce by construction to any fitted parameter, self-referential definition, or self-citation chain. Validation proceeds via external numerical simulations on Pauli-singleton and stabilizer states rather than tautological predictions. No load-bearing step matches the enumerated circularity patterns, so the derivation remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of largest coefficients to recover
- purity bound
axioms (2)
- standard math Any n-qubit state has a unique expansion in the Pauli operator basis
- domain assumption Bell sampling on two copies yields unbiased estimates of partial sums of squared Pauli coefficients
Reference graph
Works this paper leans on
-
[1]
Measuring the largest coefficients of a quantum state
andclassical shadows[2], a full characteri- zation is generally inefficient due to the expo- nential growth of the Hilbert space dimension with the number of qubits. Consequently, most methods focus on extracting relevant informa- tionfromthequantumstate[3–8]oronperform- ing tomography for restricted families of states [9–15]. It has been shown that by us...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
First, we consider the proba- bility (over the randomness of the sampling pro- cedure) of identifying the coefficient associated withX ⊗n, the only nontrivial nonzero one
We study two figures of merit that allow us to assess the performance of the algorithm for different numbers of sam- ples and qubits. First, we consider the proba- bility (over the randomness of the sampling pro- cedure) of identifying the coefficient associated withX ⊗n, the only nontrivial nonzero one. In Figure 4, we observe that the success probabil- ...
-
[3]
Paris and J
M. Paris and J. Rehacek,Quantum state esti- mation, Vol. 649 (Springer Science & Business Media, 2004)
2004
-
[4]
Huang, R
H.-Y. Huang, R. Kueng, and J. Preskill, Nature Physics16, 1050 (2020)
2020
-
[5]
Aaronson, Proceedings of the Royal Soci- ety A: Mathematical, Physical and Engineering Sciences463, 3089 (2007)
S. Aaronson, Proceedings of the Royal Soci- ety A: Mathematical, Physical and Engineering Sciences463, 3089 (2007)
2007
-
[6]
Ohliger, V
M. Ohliger, V. Nesme, and J. Eisert, New Jour- nal of Physics15, 015024 (2013)
2013
-
[7]
S. Chen, W. Yu, P. Zeng, and S. T. Flammia, PRX Quantum2, 030348 (2021)
2021
-
[8]
Huang, S
H.-Y. Huang, S. Chen, and J. Preskill, PRX quantum4, 040337 (2023)
2023
-
[9]
K. Wan, W. J. Huggins, J. Lee, and R. Babbush, Communications in Mathematical Physics404, 629 (2023)
2023
-
[10]
A. A. Akhtar, H.-Y. Hu, and Y.-Z. You, Quan- tum7, 1026 (2023)
2023
-
[11]
Gross, Y.-K
D. Gross, Y.-K. Liu, S. T. Flammia, S. Becker, and J. Eisert, Physical review letters105, 150401 (2010)
2010
-
[12]
C. H. Baldwin, I. H. Deutsch, and A. Kalev, Physical Review A93, 052105 (2016)
2016
-
[13]
Cramer, M
M. Cramer, M. B. Plenio, S. T. Flammia, R.Somma, D.Gross, S.D.Bartlett, O.Landon- Cardinal, D. Poulin, and Y.-K. Liu, Nature communications1, 149 (2010)
2010
-
[14]
Hempel, P
B.P.Lanyon, C.Maier, M.Holzäpfel, T.Baum- gratz, C. Hempel, P. Jurcevic, I. Dhand, A. Buyskikh, A. J. Daley, M. Cramer,et al., Nature Physics13, 1158 (2017)
2017
-
[15]
G. Tóth, W. Wieczorek, D. Gross, R. Krischek, C. Schwemmer, and H. Weinfurter, Physical re- view letters105, 250403 (2010)
2010
-
[16]
F. J. Schreiber, J. Eisert, and J. J. Meyer, PRX Quantum6, 020346 (2025)
2025
-
[17]
An Exponential Advantage for Adaptive Tomography of Structured States under Pauli Basis Measurements
A. Goldar, Z. Qin, Z. Zhu, Z.-X. Gong, and M. B. Wakin, An exponential advan- tage for adaptive tomography of structured states under pauli basis measurements (2026), arXiv:2604.26043 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Bendersky, J
A. Bendersky, J. P. Paz, and M. T. Cunha, Physical review letters103, 040404 (2009)
2009
-
[19]
Hinsche, M
M. Hinsche, M. Ioannou, S. Jerbi, L. Leone, J. Eisert, and J. Carrasco, PRX Quantum6, 030354 (2025)
2025
-
[20]
Gottesman, The Heisenberg Representation of Quantum Computers, arXiv:quant- ph/9807006
D. Gottesman, arXiv preprint quant- ph/9807006 (1998)
-
[21]
A. Y. Kitaev, Annals of physics303, 2 (2003)
2003
-
[22]
Bravyi and D
S. Bravyi and D. Gosset, Physical review letters 116, 250501 (2016)
2016
-
[23]
Aaronson and D
S. Aaronson and D. Gottesman, Physical Review A—Atomic, Molecular, and Optical Physics70, 052328 (2004)
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.