Recognition: unknown
Making Every Verified Token Count: Adaptive Verification for MoE Speculative Decoding
Pith reviewed 2026-05-09 19:49 UTC · model grok-4.3
The pith
A cost-aware truncation rule for draft trees lets every verified token in MoE speculative decoding advance the output productively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
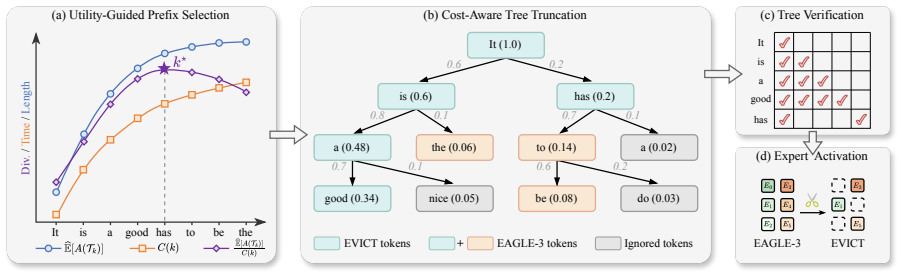
EVICT is a training-free, hyperparameter-free, and lossless adaptive verification method for MoE speculative decoding. It truncates the draft tree before target verification by leveraging fine-grained drafter signals to estimate candidate benefit and combining them with offline-profiled verification cost, retaining only the cost-effective prefix so that every verified token contributes meaningfully to speedup.
What carries the argument
EVICT, the adaptive truncation step that uses drafter signals plus offline cost profiles to select the longest still-profitable prefix of the draft tree before running target-model verification.
Load-bearing premise
Fine-grained signals from the drafter model plus pre-measured verification costs can reliably identify a prefix whose benefit exceeds its cost without discarding any token the full tree would have kept or violating the lossless guarantee.
What would settle it
Apply the truncation rule to a new MoE model and benchmark; if the resulting generation is slower than standard speculative decoding or produces any token error that the uncut tree would have avoided, the central claim is false.
Figures






read the original abstract
Tree-based speculative decoding accelerates autoregressive generation by verifying multiple draft candidates in parallel, but this advantage weakens for sparse Mixture-of-Experts (MoE) models. As the draft tree grows, different branches activate different experts, expanding the union of activated experts and substantially increasing target-side verification cost. We propose EVICT, a training-free, hyperparameter-free, and lossless adaptive verification method for MoE speculative decoding. EVICT makes every verified token count by truncating the draft tree before target verification and retaining only the cost-effective prefix. It leverages fine-grained drafter signals to estimate candidate benefit, combines them with offline-profiled verification cost, and remains highly compatible with the high-performance graph-based serving framework SGLang. Extensive experiments on diverse MoE backbones and benchmarks show that EVICT achieves up to 2.35x speedup over autoregressive decoding and an average 1.21x speedup over the state-of-the-art baseline EAGLE-3, while significantly reducing unnecessary expert activations during verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EVICT, an adaptive verification technique for tree-based speculative decoding in Mixture-of-Experts (MoE) models. By leveraging fine-grained signals from the drafter and offline-profiled verification costs, EVICT truncates the draft tree to keep only cost-effective prefixes before performing target verification. The method is presented as training-free, hyperparameter-free, and lossless, with experimental results showing up to 2.35× speedup over standard autoregressive decoding and 1.21× over EAGLE-3 on average, along with reduced expert activations, and compatibility with the SGLang serving framework.
Significance. Should the lossless guarantee and the robustness of the offline cost profiling hold, this work could meaningfully advance efficient inference for large sparse MoE models by reducing unnecessary computations in speculative decoding setups. The practical integration with high-performance serving systems like SGLang enhances its potential impact in real-world deployment scenarios. The reported speedups on diverse benchmarks provide initial evidence of its utility.
major comments (3)
- [§3.3] §3.3: The lossless property is asserted via truncation of the draft tree, but no derivation or proof is supplied showing that the cost-benefit truncation (using drafter signals plus profiled costs) preserves the exact output distribution of full verification; if drafter signals are noisy, truncation risks altering accepted tokens.
- [§4.2, Table 1] §4.2, Table 1: The hyperparameter-free claim rests on offline profiling, yet the manuscript does not specify the exact set of configurations (batch sizes, sequence lengths, hardware) profiled or demonstrate invariance to runtime variations in expert activation patterns; this leaves open the possibility that the profiling step introduces implicit choices that affect generalization and the claimed lossless behavior.
- [§5.3] §5.3: Speedup results (e.g., 1.21× average over EAGLE-3) are reported without error bars, multiple random seeds, or ablation on profiling mismatch; this weakens confidence that the gains are robust when expert activation patterns differ from the offline profiles.
minor comments (2)
- [Abstract] Abstract: The phrase 'significantly reducing unnecessary expert activations' lacks a concrete metric (e.g., percentage reduction or average experts saved); adding one would strengthen the claim.
- [§2] §2: Background notation for draft trees and per-token verification cost would benefit from an early equation or diagram to clarify the cost-benefit estimation before the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and indicate revisions to be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3: The lossless property is asserted via truncation of the draft tree, but no derivation or proof is supplied showing that the cost-benefit truncation (using drafter signals plus profiled costs) preserves the exact output distribution of full verification; if drafter signals are noisy, truncation risks altering accepted tokens.
Authors: We appreciate this observation. The manuscript's lossless claim follows from performing truncation prior to target verification: only prefixes whose estimated benefit (drafter signal) exceeds profiled verification cost are retained, so the verification step on the reduced tree produces identical acceptance decisions for all kept candidates. We acknowledge that an explicit derivation was omitted. In the revision we will add to §3.3 a concise proof sketch establishing that the selected prefix set yields the same accepted sequence distribution as the full tree under the drafter's token probabilities, together with a short discussion of robustness when drafter signals contain noise (supported by the empirical results already reported). revision: yes
-
Referee: [§4.2, Table 1] §4.2, Table 1: The hyperparameter-free claim rests on offline profiling, yet the manuscript does not specify the exact set of configurations (batch sizes, sequence lengths, hardware) profiled or demonstrate invariance to runtime variations in expert activation patterns; this leaves open the possibility that the profiling step introduces implicit choices that affect generalization and the claimed lossless behavior.
Authors: We agree that additional detail on the offline profiling procedure is required. The current manuscript states only that costs were profiled once; it does not enumerate the concrete configurations. In the revised §4.2 we will list the exact ranges used (batch sizes 1–32, sequence lengths up to 2048 tokens, and the hardware platforms) and add a short invariance experiment showing that the resulting cost tables remain stable under moderate changes in expert activation patterns at runtime. This will make explicit that the profiling step is a fixed, one-time preprocessing step and does not constitute a runtime hyperparameter. revision: yes
-
Referee: [§5.3] §5.3: Speedup results (e.g., 1.21× average over EAGLE-3) are reported without error bars, multiple random seeds, or ablation on profiling mismatch; this weakens confidence that the gains are robust when expert activation patterns differ from the offline profiles.
Authors: The reported speedups were obtained from single deterministic runs to control for the high cost of large MoE inference. We recognize that statistical reporting strengthens the claims. In the revision we will augment §5.3 with error bars computed over at least three random seeds for the primary benchmarks and will include a new ablation that deliberately mismatches the offline profiles (by scaling or shifting cost values) to quantify sensitivity of both speedup and output fidelity. These additions will directly address concerns about robustness to profile mismatch. revision: yes
Circularity Check
No circularity: method uses external signals and offline profiling without self-referential reduction
full rationale
The paper describes EVICT as a training-free, hyperparameter-free truncation method that combines fine-grained drafter signals with offline-profiled verification costs to select cost-effective prefixes. No equations, claims, or self-citations in the abstract or described derivation reduce the lossless guarantee, speedup figures, or expert-activation savings to a quantity defined by the same inputs or fitted parameters. The offline profiling step is presented as an independent external measurement, and the central results are framed as empirical outcomes on diverse backbones rather than tautological consequences of the method's own definitions. This satisfies the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Machine Learning , pages =
Fast Inference from Transformers via Speculative Decoding , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[2]
2023 , eprint=
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
2023
-
[3]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Eagle: Speculative sampling requires rethinking feature uncertainty , author=. arXiv preprint arXiv:2401.15077 , year=
work page internal anchor Pith review arXiv
-
[4]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration framework with multiple decoding heads , author=. arXiv preprint arXiv:2401.10774 , year=
work page internal anchor Pith review arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Sequoia: Scalable and robust speculative decoding , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Eagle-2: Faster inference of language models with dynamic draft trees , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[7]
Advances in neural information processing systems , volume=
Sglang: Efficient execution of structured language model programs , author=. Advances in neural information processing systems , volume=
-
[8]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review arXiv 2006
-
[10]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[11]
International conference on machine learning , pages=
Glam: Efficient scaling of language models with mixture-of-experts , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[12]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review arXiv
-
[14]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review arXiv
-
[15]
Qwen3-coder-next technical report , author=. arXiv preprint arXiv:2603.00729 , year=
-
[16]
Proceedings of Machine Learning and Systems , volume=
Megablocks: Efficient sparse training with mixture-of-experts , author=. Proceedings of Machine Learning and Systems , volume=
-
[17]
UCCL-EP: Portable Expert-Parallel Communication.arXiv preprint arXiv:2512.19849, 2025
UCCL-EP: Portable Expert-Parallel Communication , author=. arXiv preprint arXiv:2512.19849 , year=
-
[18]
Grace-moe: Grouping and replication with locality-aware routing for efficient distributed moe inference , author=. arXiv preprint arXiv:2509.25041 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ACM Computing Surveys , volume=
A survey on inference optimization techniques for mixture of experts models , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[20]
Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 , pages=
Specinfer: Accelerating large language model serving with tree-based speculative inference and verification , author=. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 , pages=
-
[21]
Transactions of the Association for Computational Linguistics , volume=
Opt-tree: Speculative decoding with adaptive draft tree structure , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[22]
arXiv preprint arXiv:2601.07353 , year=
TALON: Confidence-Aware Speculative Decoding with Adaptive Token Trees , author=. arXiv preprint arXiv:2601.07353 , year=
-
[23]
ECHO: Elastic Speculative Decoding with Sparse Gating for High-Concurrency Scenarios
ECHO: Elastic Speculative Decoding with Sparse Gating for High-Concurrency Scenarios , author=. arXiv preprint arXiv:2604.09603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2508.21706 , year=
Accelerating Mixture-of-Experts Inference by Hiding Offloading Latency with Speculative Decoding , author=. arXiv preprint arXiv:2508.21706 , year=
-
[25]
IEEE INFOCOM 2025-IEEE Conference on Computer Communications , pages=
SP-MoE: Expediting mixture-of-experts training with optimized pipelining planning , author=. IEEE INFOCOM 2025-IEEE Conference on Computer Communications , pages=. 2025 , organization=
2025
-
[26]
arXiv preprint arXiv:2505.19645 , year=
MoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE , author=. arXiv preprint arXiv:2505.19645 , year=
-
[27]
Utility-driven spec- ulative decoding for mixture-of-experts.arXiv preprint arXiv:2506.20675, 2025
Utility-Driven Speculative Decoding for Mixture-of-Experts , author=. arXiv preprint arXiv:2506.20675 , year=
-
[28]
arXiv preprint arXiv:2602.16052 , year=
MoE-Spec: Expert Budgeting for Efficient Speculative Decoding , author=. arXiv preprint arXiv:2602.16052 , year=
-
[29]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation , author=. 2025 , eprint=
2025
-
[31]
arXiv preprint arXiv:2603.18567 , year=
SpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding , author=. arXiv preprint arXiv:2603.18567 , year=
-
[32]
2025 , month = dec, note =
SpecBundle & SpecForge v0.2: Production-Ready Speculative Decoding Models and Framework , author =. 2025 , month = dec, note =
2025
-
[33]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Lookahead: An inference acceleration framework for large language model with lossless generation accuracy , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[34]
arXiv preprint arXiv:2409.00142 , year=
Dynamic depth decoding: Faster speculative decoding for llms , author=. arXiv preprint arXiv:2409.00142 , year=
-
[35]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[36]
2023 , eprint=
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. 2023 , eprint=
2023
-
[37]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[38]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[39]
Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond , url=
Nallapati, Ramesh and Zhou, Bowen and dos Santos, Cicero and G. Abstractive Text Summarization using Sequence-to-sequence. Proceedings of the 20th. 2016 , month = aug, address =. doi:10.18653/v1/K16-1028 , pages =
-
[40]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title =
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title...
2019
-
[41]
2025 , eprint=
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test , author=. 2025 , eprint=
2025
-
[42]
Llm inference unveiled: Survey and roofline model insights,
Llm inference unveiled: Survey and roofline model insights , author=. arXiv preprint arXiv:2402.16363 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.