Recognition: unknown
Hypergraph and Latent ODE Learning for Multimodal Root Cause Localization in Microservices
Pith reviewed 2026-05-09 20:14 UTC · model grok-4.3
The pith
HyperODE RCA combines hypergraph attention, latent ODEs, and multimodal fusion to localize root causes more accurately in microservice systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that their unified HyperODE RCA framework, which learns higher-order service interactions through differentiable hyperedge construction, captures continuous anomaly evolution from irregular observations with an ODE RNN encoder, and adaptively fuses logs, traces, metrics, entities, and events using context-aware modality routing, produces clear gains over strong baselines in ranking and classification performance for root cause localization while preserving interpretability through learned hypergraph attention, with further robustness from a variational information bottleneck, temporal causal regularization, and invariant risk constraints.
What carries the argument
HyperODE RCA framework that performs differentiable hyperedge construction for hypergraph attention, latent ODE encoding for continuous temporal dynamics, and adaptive multimodal cross-attention fusion.
If this is right
- Higher-order service dependencies beyond simple pairwise graphs can be captured differentiably to support finer-grained root cause ranking.
- Continuous-time modeling via latent ODEs handles irregular observation times better than discrete recurrent approaches for anomaly evolution.
- Context-aware routing across logs, traces, metrics, entities, and events yields more robust predictions than single-modality methods.
- Variational information bottleneck combined with temporal causal regularization and invariant risk constraints improves generalization while retaining interpretability.
- Learned hypergraph attention weights provide direct explanations for which service interactions drive each diagnosis.
Where Pith is reading between the lines
- The same combination of hypergraph structure and continuous dynamics could be tested on other networked systems that produce irregular time-series observations, such as sensor networks or distributed computing clusters.
- The adaptive modality routing mechanism might extend naturally to incorporate additional signals like user feedback or external alerts without retraining the core encoder.
- If the gains hold on production traces, monitoring platforms could shift from snapshot-based alerts toward continuous latent-state tracking for earlier fault detection.
- Systematic ablations across multiple benchmarks would clarify whether the hypergraph or the ODE component contributes more to the observed improvements.
Load-bearing premise
The reported performance gains on the Tianchi AIOps benchmark arise primarily from the hypergraph, latent ODE, and multimodal fusion components rather than from implementation choices, hyperparameter tuning, or dataset-specific artifacts, and that the gains will generalize to other microservice deployments.
What would settle it
Ablating the hypergraph attention or latent ODE components and finding no drop in ranking or classification metrics on the same benchmark, or observing comparable or worse results when the model is applied to a different microservice trace dataset, would challenge the central claim.
Figures



read the original abstract
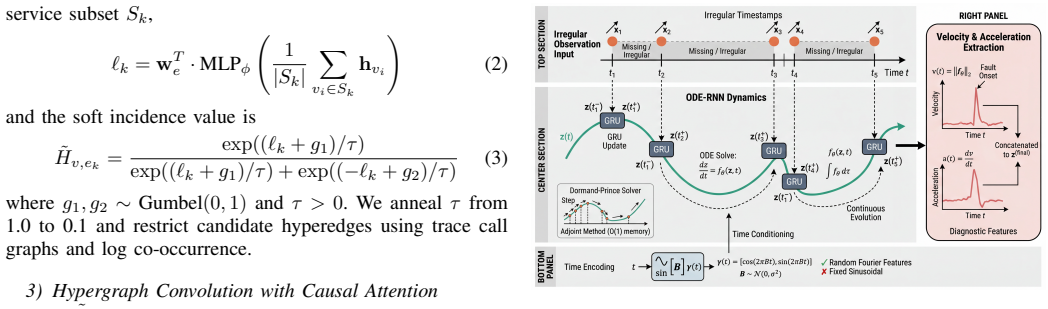
Root cause localization in cloud native microservice systems requires modeling complex service dependencies, irregular temporal dynamics, and heterogeneous observability data. We present HyperODE RCA, a unified framework that combines hypergraph attention learning, latent ordinary differential equations, and multimodal cross attention fusion for fine grained root cause analysis. The method learns higher order service interactions through differentiable hyperedge construction, captures continuous anomaly evolution from irregular observations with an ODE RNN encoder, and adaptively fuses logs, traces, metrics, entities, and events using context aware modality routing. We further improve robustness with a variational information bottleneck, temporal causal regularization, and invariant risk constraints. Experiments on the Tianchi AIOps benchmark show clear gains over strong baselines in ranking and classification performance, while preserving interpretability through learned hypergraph attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperODE RCA, a unified framework for root cause localization in microservice systems that integrates hypergraph attention learning with differentiable hyperedge construction to model higher-order service interactions, a latent ODE-RNN encoder to capture continuous anomaly evolution from irregular observations, and context-aware multimodal cross-attention fusion to integrate logs, traces, metrics, entities, and events. Additional robustness is provided via a variational information bottleneck, temporal causal regularization, and invariant risk constraints. Experiments on the Tianchi AIOps benchmark are reported to show clear gains over strong baselines in ranking and classification performance while preserving interpretability via learned hypergraph attention.
Significance. If the reported performance gains can be rigorously attributed to the proposed components through ablations and detailed comparisons, the work would offer a meaningful advance in multimodal root cause analysis for cloud-native systems. The integration of hypergraphs for higher-order dependencies and latent ODEs for irregular temporal dynamics addresses limitations in prior pairwise GNN or discrete RNN approaches, with potential for broader applicability in anomaly detection and system diagnostics.
major comments (2)
- [Experiments] Experiments section: the abstract asserts 'clear gains over strong baselines' in ranking and classification on the Tianchi AIOps benchmark, yet no baseline descriptions, exact metrics (e.g., Hit@K, MRR, precision), standard deviations, statistical significance tests, or ablation studies are referenced. Without component-isolation experiments (e.g., replacing hypergraph attention with a standard pairwise GNN, swapping the latent ODE encoder for a discrete GRU/LSTM, or removing the multimodal router), it is impossible to confirm that gains arise from the hypergraph, ODE, and fusion elements rather than hyperparameter tuning, data preprocessing, or the regularizers alone.
- [Method] Method section (hypergraph and ODE components): the differentiable hyperedge construction and ODE-RNN encoder are central to the claims, but the manuscript provides insufficient mathematical detail on the hyperedge parameterization (e.g., how the incidence matrix or attention weights are learned differentiably) and the exact latent ODE formulation (e.g., the neural ODE solver and integration with the RNN encoder). This prevents verification that the approach is parameter-free or reproducible as implied.
minor comments (2)
- [Abstract] Abstract: specify the precise evaluation metrics and the number of runs or cross-validation procedure used to support the 'clear gains' claim.
- [Method] Notation: ensure consistent use of symbols for hyperedges, latent states, and modality-specific embeddings across equations and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of integrating hypergraph learning with latent ODEs for multimodal root cause localization in microservices. We address the major comments below and will revise the manuscript to enhance experimental rigor and methodological detail.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract asserts 'clear gains over strong baselines' in ranking and classification on the Tianchi AIOps benchmark, yet no baseline descriptions, exact metrics (e.g., Hit@K, MRR, precision), standard deviations, statistical significance tests, or ablation studies are referenced. Without component-isolation experiments (e.g., replacing hypergraph attention with a standard pairwise GNN, swapping the latent ODE encoder for a discrete GRU/LSTM, or removing the multimodal router), it is impossible to confirm that gains arise from the hypergraph, ODE, and fusion elements rather than hyperparameter tuning, data preprocessing, or the regularizers alone.
Authors: We agree that additional experimental details and analyses are needed to rigorously attribute performance gains. In the revised manuscript, we will expand the experiments section to include full descriptions of all baselines, report exact metrics (Hit@K, MRR, precision) with standard deviations across runs, perform statistical significance tests, and present ablation studies that isolate the hypergraph attention (vs. pairwise GNN), latent ODE encoder (vs. discrete GRU/LSTM), and multimodal fusion components. This will strengthen the evidence that improvements stem from the proposed elements. revision: yes
-
Referee: [Method] Method section (hypergraph and ODE components): the differentiable hyperedge construction and ODE-RNN encoder are central to the claims, but the manuscript provides insufficient mathematical detail on the hyperedge parameterization (e.g., how the incidence matrix or attention weights are learned differentiably) and the exact latent ODE formulation (e.g., the neural ODE solver and integration with the RNN encoder). This prevents verification that the approach is parameter-free or reproducible as implied.
Authors: We acknowledge the need for greater mathematical precision to support reproducibility. The manuscript outlines differentiable hyperedge construction via a learnable incidence matrix and attention mechanism, along with the latent ODE-RNN encoder for continuous dynamics. In the revision, we will add explicit equations detailing the hyperedge parameterization (including how the incidence matrix and attention weights are optimized differentiably), the latent ODE formulation (e.g., the neural network f(z, t; θ) and solver integration), and the precise RNN-ODE coupling. We will also clarify that the approach is not claimed to be parameter-free. revision: yes
Circularity Check
No circularity: paper presents empirical ML framework without load-bearing derivation chain
full rationale
The provided abstract and description contain no mathematical derivation, equations, or first-principles claims that reduce to fitted inputs or self-citations. The work describes a composite architecture (hypergraph attention, latent ODE encoder, multimodal fusion) and reports benchmark gains, but offers no chain of the form 'X derives Y' where Y is definitionally equivalent to X. Absence of ablations is a methodological concern, not a circularity reduction. Per rules, honest non-finding applies when no quoted reduction exists.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural controlled differential equations for irregular time series,
P. Kidger, J. Morrill, J. Foster, and T. Lyons, “Neural controlled differential equations for irregular time series,”Advances in neural information processing systems, vol. 33, pp. 6696–6707, 2020
2020
-
[2]
E. Chien, C. Pan, J. Peng, and O. Milenkovic, “You are allset: A multiset function framework for hypergraph neural networks,”arXiv preprint arXiv:2106.13264, 2021
-
[3]
Attention bottlenecks for multimodal fusion,
A. Nagrani, S. Yang, A. Arnab, A. Jansen, C. Schmid, and C. Sun, “Attention bottlenecks for multimodal fusion,”Advances in neural information processing systems, vol. 34, pp. 14 200–14 213, 2021
2021
-
[4]
arXiv preprint arXiv:2601.13632
Z. Xue, S. Zhao, Y . Qi, X. Zeng, and Z. Yu, “Resilient routing: Risk- aware dynamic routing in smart logistics via spatiotemporal graph learning,”arXiv preprint arXiv:2601.13632, 2026
-
[5]
Dynotears: Structure learning from time-series data,
R. Pamfil, N. Sriwattanaworachai, S. Desai, P. Pilgerstorfer, K. Geor- gatzis, P. Beaumont, and B. Aragam, “Dynotears: Structure learning from time-series data,” inInternational conference on artificial intelli- gence and statistics. Pmlr, 2020, pp. 1595–1605
2020
-
[6]
Differentiable causal discovery from interventional data,
P. Brouillard, S. Lachapelle, A. Lacoste, S. Lacoste-Julien, and A. Drouin, “Differentiable causal discovery from interventional data,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 865–21 877, 2020
2020
-
[7]
Self-destructive language model,
Y . Wang, R. Zhu, and T. Wang, “Self-destructive language model,”arXiv preprint arXiv:2505.12186, 2025
-
[8]
Leveraging large lan- guage models: Enhancing retrieval-augmented generation with scann and gemma for superior ai response,
M. Gao, P. Lu, Z. Zhao, X. Bi, and F. Wang, “Leveraging large lan- guage models: Enhancing retrieval-augmented generation with scann and gemma for superior ai response,” in2024 5th International Conference on Machine Learning and Computer Application (ICMLCA). IEEE, 2024, pp. 619–622
2024
-
[9]
Bowen Jing, Bonnie Berger, and Tommi Jaakkola
A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhameret al., “Perceiver io: A general architecture for structured inputs & outputs,”arXiv preprint arXiv:2107.14795, 2021
-
[10]
An integrated machine learning and deep learning framework for credit card approval prediction,
K. Tong, Z. Han, Y . Shen, Y . Long, and Y . Wei, “An integrated machine learning and deep learning framework for credit card approval prediction,” in2024 IEEE 6th International Conference on Power, Intelligent Computing and Systems (ICPICS). IEEE, 2024, pp. 853–858
2024
-
[11]
Garg,Learning Apache Kafka
N. Garg,Learning Apache Kafka. Packt Publishing, 2015
2015
-
[12]
arXiv preprint arXiv:1612.00410 , year=
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy, “Deep variational information bottleneck,”arXiv preprint arXiv:1612.00410, 2016
-
[13]
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovic, and Yonatan Belinkov
Y . Wang, C. Li, G. Chen, J. Liang, and T. Wang, “Reasoning or retrieval? a study of answer attribution on large reasoning models,”arXiv preprint arXiv:2509.24156, 2025
-
[14]
Enhancing educational content matching using transformer models and infonce loss,
Y . Long, D. Gu, X. Li, P. Lu, and J. Cao, “Enhancing educational content matching using transformer models and infonce loss,” in2024 IEEE 7th International Conference on Information Systems and Computer Aided Education (ICISCAE). IEEE, 2024, pp. 11–15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.