Recognition: 2 theorem links
· Lean TheoremResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
Pith reviewed 2026-05-11 02:01 UTC · model grok-4.3
The pith
ResRL improves LLM reasoning by projecting negative-token representations onto a low-rank positive subspace and modulating gradients with the residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
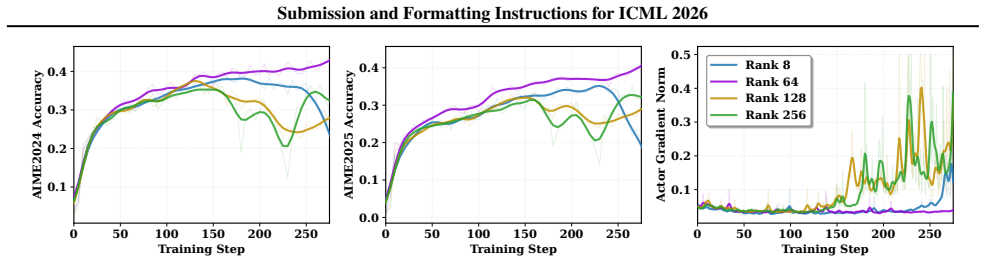
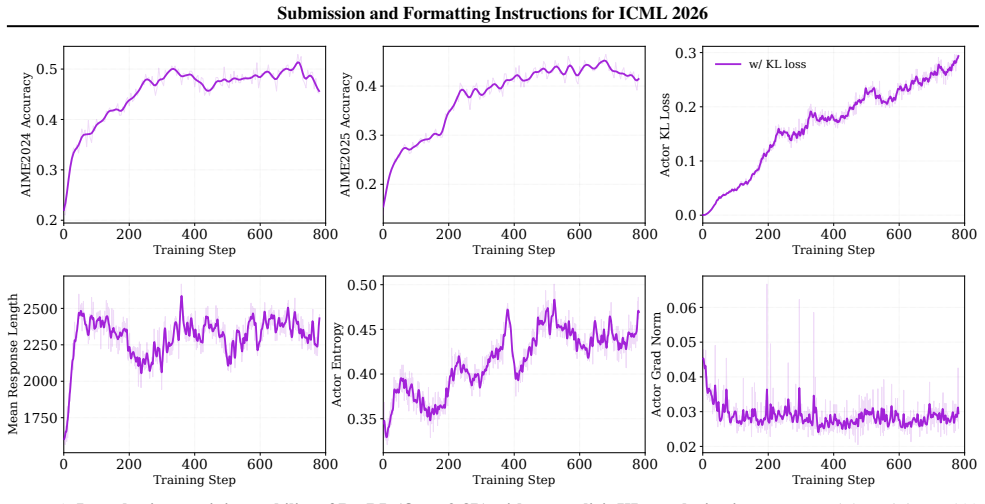
ResRL projects negative-token hidden representations onto an SVD-based low-rank positive subspace and uses projection residuals to modulate negative gradients. This decouples similar semantic distributions between positive and negative responses, improving reasoning while preserving diversity and outperforming strong baselines on average across twelve benchmarks spanning Mathematics, Code, Agent Tasks, and Function Calling.
What carries the argument
The projection of negative-token hidden representations onto an SVD-derived low-rank positive subspace, with the resulting residuals used to reweight negative advantages and reduce head-gradient interference.
If this is right
- Outperforms prior methods including NSR on average across twelve benchmarks in mathematics, code, agent tasks, and function calling.
- Surpasses NSR specifically on mathematical reasoning by 9.4% in Avg@16 and 7.0% in Pass@128.
- Preserves generation diversity by avoiding suppression of shared semantic distributions.
- Uses a single-forward proxy upper-bounding representation alignment to guide the conservative reweighting.
Where Pith is reading between the lines
- Similar projection-based decoupling could be explored in other LLM alignment techniques that balance positive and negative feedback.
- Representation-level interventions like this may help stabilize training in broader reinforcement learning from human feedback settings.
- Scalability tests on models larger than those used here would clarify whether the SVD computation remains efficient at scale.
Load-bearing premise
The SVD-based projection successfully isolates the components unique to negative responses from the shared semantic information that both positive and negative responses need for effective reasoning.
What would settle it
If the method is applied and either reasoning accuracy does not increase or diversity metrics decline compared to NSR on the reported benchmarks, or if the proxy for representation alignment does not decrease after projection.
Figures




















read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) enhances reasoning of Large Language Models (LLMs) but usually exhibits limited generation diversity due to the over-incentivization of positive rewards. Although methods like Negative Sample Reinforcement (NSR) mitigate this issue by upweighting penalty from negative samples, they may suppress the semantic distributions shared between positive and negative responses. To boost reasoning ability without losing diversity, this paper proposes negative sample projection Residual Reinforcement Learning (ResRL) that decouples similar semantic distributions among positive and negative responses. We theoretically link Lazy Likelihood Displacement (LLD) to negative-positive head-gradient interference and derive a single-forward proxy that upper-bounds representation alignment to guide conservative advantage reweighting. ResRL then projects negative-token hidden representations onto an SVD-based low-rank positive subspace and uses projection residuals to modulate negative gradients, improving reasoning while preserving diversity and outperforming strong baselines on average across twelve benchmarks spanning Mathematics, Code, Agent Tasks, and Function Calling. Notably, ResRL surpasses NSR on mathematical reasoning by 9.4\% in Avg@16 and 7.0\% in Pass@128. Code is available at https://github.com/1229095296/ResRL.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ResRL, a reinforcement learning method for LLMs that projects negative-token hidden representations onto an SVD-derived low-rank positive subspace and modulates negative gradients via the resulting residuals. It claims this decouples shared semantic distributions between positive and negative samples (addressing limitations in NSR), theoretically links Lazy Likelihood Displacement to head-gradient interference via a single-forward alignment proxy, and empirically yields gains in reasoning diversity and performance, outperforming baselines on average across twelve benchmarks in mathematics, code, agent tasks, and function calling (notably +9.4% Avg@16 and +7.0% Pass@128 over NSR on math).
Significance. If the central mechanism holds, ResRL could meaningfully advance RLVR techniques by balancing reward optimization against diversity loss without post-hoc suppression of useful negative information. The explicit code release supports reproducibility, and the gradient-interference framing provides a potentially useful lens for future work on negative sampling in LLM alignment. However, the current support for both the theoretical proxy and the empirical robustness remains limited.
major comments (3)
- [Theoretical Analysis] Theoretical section (derivation of LLD-to-gradient-interference link and single-forward proxy): the abstract asserts an upper bound on representation alignment that guides conservative advantage reweighting, but no explicit steps, assumptions, or proof sketch are provided; this is load-bearing for the claim that the SVD projection is theoretically justified rather than heuristic.
- [Experiments] Experimental section (benchmark results and SVD rank): the reported 9.4% Avg@16 and 7.0% Pass@128 gains on mathematical reasoning are presented as direct outcomes, yet the manuscript does not specify the exact twelve benchmarks, the chosen SVD subspace rank (a free parameter), its selection criterion, or any ablation confirming no post-hoc tuning; this undermines verification that the projection residual truly preserves diversity without suppressing shared reasoning signals.
- [Method] Method section (projection residual modulation): the weakest assumption—that the low-rank positive subspace successfully decouples similar semantic distributions without losing useful shared information—is stated but not supported by any quantitative analysis of information loss or gradient interference reduction; this is central to the diversity-preservation claim.
minor comments (2)
- [Experiments] A table explicitly listing the twelve benchmarks, their categories, and the exact evaluation metrics (Avg@16, Pass@128, etc.) would improve clarity and allow direct comparison with NSR and other baselines.
- [Method] Notation for the SVD-based subspace and projection residual should be defined once with consistent symbols across equations and text to avoid ambiguity in the gradient modulation step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of ResRL to advance RLVR methods. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical section (derivation of LLD-to-gradient-interference link and single-forward proxy): the abstract asserts an upper bound on representation alignment that guides conservative advantage reweighting, but no explicit steps, assumptions, or proof sketch are provided; this is load-bearing for the claim that the SVD projection is theoretically justified rather than heuristic.
Authors: We acknowledge that the current manuscript presents the link between Lazy Likelihood Displacement and head-gradient interference along with the single-forward proxy but does not include a full step-by-step derivation or explicit list of assumptions. In the revised version, we will expand the theoretical section with a detailed proof sketch, including all assumptions and the mathematical steps deriving the upper bound on representation alignment. This will clarify the theoretical justification for the SVD projection. revision: yes
-
Referee: [Experiments] Experimental section (benchmark results and SVD rank): the reported 9.4% Avg@16 and 7.0% Pass@128 gains on mathematical reasoning are presented as direct outcomes, yet the manuscript does not specify the exact twelve benchmarks, the chosen SVD subspace rank (a free parameter), its selection criterion, or any ablation confirming no post-hoc tuning; this undermines verification that the projection residual truly preserves diversity without suppressing shared reasoning signals.
Authors: We agree that explicit details are required for reproducibility and verification. The revised manuscript will list all twelve benchmarks by name and category. We will also specify the SVD rank employed, describe its selection criterion, and add an ablation study across multiple ranks to demonstrate robustness and confirm that performance improvements are not the result of post-hoc tuning while preserving diversity. revision: yes
-
Referee: [Method] Method section (projection residual modulation): the weakest assumption—that the low-rank positive subspace successfully decouples similar semantic distributions without losing useful shared information—is stated but not supported by any quantitative analysis of information loss or gradient interference reduction; this is central to the diversity-preservation claim.
Authors: We recognize that the central assumption would be strengthened by quantitative evidence. In the revision, we will add an analysis subsection reporting metrics such as projection error norms and gradient interference reduction (via pre- and post-modulation comparisons) to demonstrate that shared semantic information is largely retained while decoupling is achieved. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation begins with a theoretical connection between Lazy Likelihood Displacement (LLD) and negative-positive head-gradient interference, followed by derivation of a single-forward alignment proxy. This proxy then motivates an SVD-based low-rank projection of negative-token hidden states onto the positive subspace, with residuals used to modulate gradients. No step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the projection and residual modulation are introduced as new mechanisms grounded in the stated theory rather than tautological re-use of prior NSR quantities. Empirical results on the twelve benchmarks are reported as direct outcomes of this construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- SVD subspace rank
axioms (2)
- domain assumption Lazy Likelihood Displacement links to negative-positive head-gradient interference
- domain assumption Single-forward proxy upper-bounds representation alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearprojects negative-token hidden representations onto an SVD-based low-rank positive subspace and uses projection residuals to modulate negative gradients
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclearorthogonal-complement energy e(x) ≜ 1/d ∥(I−PS)x∥²₂
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[10]
The Surprising Effectiveness of Negative Reinforcement in
Xinyu Zhu and Mengzhou Xia and Zhepei Wei and Wei-Lin Chen and Danqi Chen and Yu Meng , booktitle=. The Surprising Effectiveness of Negative Reinforcement in. 2025 , url=
work page 2025
-
[11]
SR-GRPO: Stable Rank as an Intrinsic Geometric Reward for Large Language Model Alignment , author=. 2025 , eprint=
work page 2025
-
[12]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Geometry of Decision Making in Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[13]
Do We Really Need All Those Dimensions? An Intrinsic Evaluation Framework for Compressed Embeddings
Inkiriwang, Nathan and B. Do We Really Need All Those Dimensions? An Intrinsic Evaluation Framework for Compressed Embeddings. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.717
-
[14]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[15]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings , author=. arXiv preprint arXiv:1909.00512 , year=
-
[16]
Zero: Memory optimizations toward training trillion parameter models , author=. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , pages=. 2020 , organization=
work page 2020
-
[17]
Advances in neural information processing systems , volume=
Gradient surgery for multi-task learning , author=. Advances in neural information processing systems , volume=
-
[18]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[19]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [20]
- [21]
-
[22]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training , author=. arXiv preprint arXiv:2505.10978 , year=
work page internal anchor Pith review arXiv
-
[23]
arXiv preprint arXiv:2509.09265 , year=
Harnessing uncertainty: Entropy-modulated policy gradients for long-horizon llm agents , author=. arXiv preprint arXiv:2509.09265 , year=
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2509.15207 , year=
Flowrl: Matching reward distributions for llm reasoning , author=. arXiv preprint arXiv:2509.15207 , year=
-
[27]
The surprising effectiveness of negative reinforcement in LLM reasoning , author=. arXiv preprint arXiv:2506.01347 , year=
-
[28]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[29]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[30]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [31]
-
[32]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
-
[34]
American Invitational Mathematics Examination - AIME , author =
-
[35]
American Mathematics Competitions - AMC , author =. 2023 , howpublished=
work page 2023
-
[36]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[37]
Solving Quantitative Reasoning Problems with Language Models , volume =
Lewkowycz, Aitor and Andreassen, Anders and Dohan, David and Dyer, Ethan and Michalewski, Henryk and Ramasesh, Vinay and Slone, Ambrose and Anil, Cem and Schlag, Imanol and Gutman-Solo, Theo and Wu, Yuhuai and Neyshabur, Behnam and Gur-Ari, Guy and Misra, Vedant , booktitle =. Solving Quantitative Reasoning Problems with Language Models , volume =
-
[38]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review arXiv
-
[39]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Hugging Face repository , howpublished =
CodeForces , author=. Hugging Face repository , howpublished =. 2025 , publisher =
work page 2025
-
[41]
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
work page 2021
-
[42]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
work page internal anchor Pith review arXiv 2010
-
[44]
DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level , author=
-
[45]
ToolACE: Winning the Points of LLM Function Calling , author=. 2025 , eprint=
work page 2025
-
[46]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2509.21826 , year=
ResT: Reshaping Token-Level Policy Gradients for Tool-Use Large Language Models , author=. arXiv preprint arXiv:2509.21826 , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review arXiv
-
[50]
On GRPO Collapse in Search-R1: The Lazy Likelihood-Displacement Death Spiral , author=. arXiv preprint arXiv:2512.04220 , year=
-
[51]
arXiv preprint arXiv:2508.03772 , year=
GTPO: Stabilizing Group Relative Policy Optimization via Gradient and Entropy Control , author=. arXiv preprint arXiv:2508.03772 , year=
-
[52]
2nd AI for Math Workshop@ ICML 2025 , year=
Token Hidden Reward: Steering Exploration-Exploitation in GRPO Training , author=. 2nd AI for Math Workshop@ ICML 2025 , year=
work page 2025
-
[53]
Token-level direct preference optimization, 2024
Token-level direct preference optimization , author=. arXiv preprint arXiv:2404.11999 , year=
-
[54]
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers , author=. arXiv preprint arXiv:2505.19439 , year=
-
[55]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Learning to reason without external rewards , author=. arXiv preprint arXiv:2505.19590 , year=
-
[56]
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947,
Spurious rewards: Rethinking training signals in rlvr , author=. arXiv preprint arXiv:2506.10947 , year=
-
[57]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Simko: Simple pass@ k policy optimization.arXiv preprint arXiv:2510.14807, 2025
Simko: Simple pass@ k policy optimization , author=. arXiv preprint arXiv:2510.14807 , year=
-
[59]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models , author=. arXiv preprint arXiv:2508.10751 , year=
-
[61]
DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search , author=. arXiv preprint arXiv:2509.25454 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
arXiv preprint arXiv:2508.07534 , year=
From trial-and-error to improvement: A systematic analysis of llm exploration mechanisms in rlvr , author=. arXiv preprint arXiv:2508.07534 , year=
-
[63]
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Depth-breadth synergy in rlvr: Unlocking llm reasoning gains with adaptive exploration , author=. arXiv preprint arXiv:2508.13755 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Pass@ K Policy Optimization: Solving Harder Reinforcement Learning Problems , author=. arXiv preprint arXiv:2505.15201 , year=
-
[65]
arXiv preprint arXiv:2511.16231 , year=
Pass@ k Metric for RLVR: A Diagnostic Tool of Exploration, But Not an Objective , author=. arXiv preprint arXiv:2511.16231 , year=
-
[66]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Position information emerges in causal transformers without positional encodings via similarity of nearby embeddings , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[67]
Transactions of the association for computational linguistics , volume=
A primer in BERTology: What we know about how BERT works , author=. Transactions of the association for computational linguistics , volume=
-
[68]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.