Recognition: no theorem link
RTPrune: Reading-Twice Inspired Token Pruning for Efficient DeepSeek-OCR Inference
Pith reviewed 2026-05-12 03:07 UTC · model grok-4.3
The pith
RTPrune applies a two-stage pruning process to DeepSeek-OCR that first keeps high-norm visual tokens and then merges the rest with optimal transport to cut inference time while preserving OCR accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeepSeek-OCR exhibits a distinct two-stage reading trajectory during decoding in which the model initially prioritizes the majority of high-norm tokens and subsequently redistributes attention to the remaining tokens; exploiting this trajectory through a tailored two-stage prune that first prioritizes high-norm visual tokens and then pairs and merges the rest via optimal transport, together with a dynamic pruning ratio that adapts to token similarity and textual density, produces efficient feature aggregation that preserves textual fidelity for OCR tasks.
What carries the argument
The two-stage token pruning mechanism: stage one prioritizes high-norm visual tokens, stage two pairs and merges the remaining tokens according to optimal transport theory, all governed by an adaptive ratio based on similarity and textual density.
If this is right
- DeepSeek-OCR-Large reaches 99.47 percent accuracy on OmniDocBench while using only 84.25 percent of the original visual tokens.
- Prefill stage runs 1.23 times faster than the unpruned baseline under the same hardware conditions.
- The method outperforms prior token-pruning techniques that were designed for general vision-language models on text-dense OCR workloads.
- A single dynamic ratio schedule suffices to balance speed and fidelity without manual tuning per document.
Where Pith is reading between the lines
- The same high-norm-plus-optimal-transport pattern might accelerate other vision-language models whose decoding shows an early focus on salient tokens followed by attention redistribution.
- Applying the dynamic ratio to non-OCR image tasks could reveal whether textual density is the main driver or whether structural density in diagrams matters equally.
- Combining RTPrune with existing visual-text compression layers inside DeepSeek-OCR might produce further multiplicative speed-ups on very long documents.
Load-bearing premise
The two-stage reading trajectory observed in DeepSeek-OCR stays stable enough across inputs that prioritizing high-norm tokens first and then merging the rest with optimal transport will not lose the textual details needed for accurate OCR.
What would settle it
Measuring OCR accuracy on a new document set where the model's internal attention does not follow the high-norm-first then redistribute pattern and finding that accuracy falls below 99 percent even at the reported 84 percent retention rate.
Figures

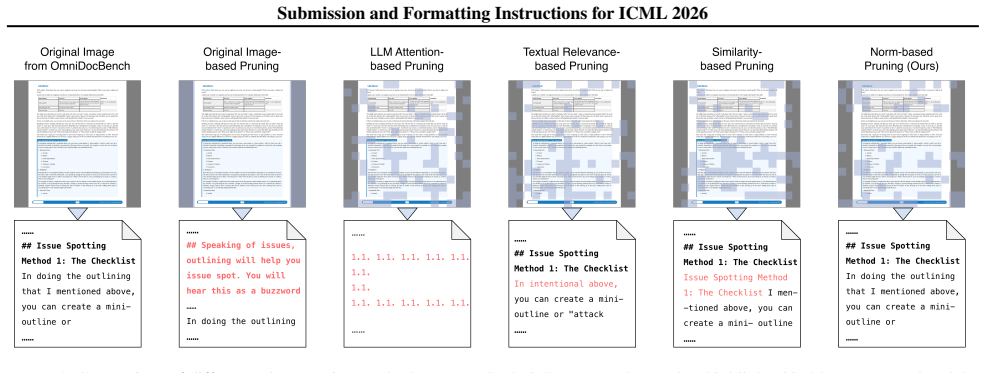
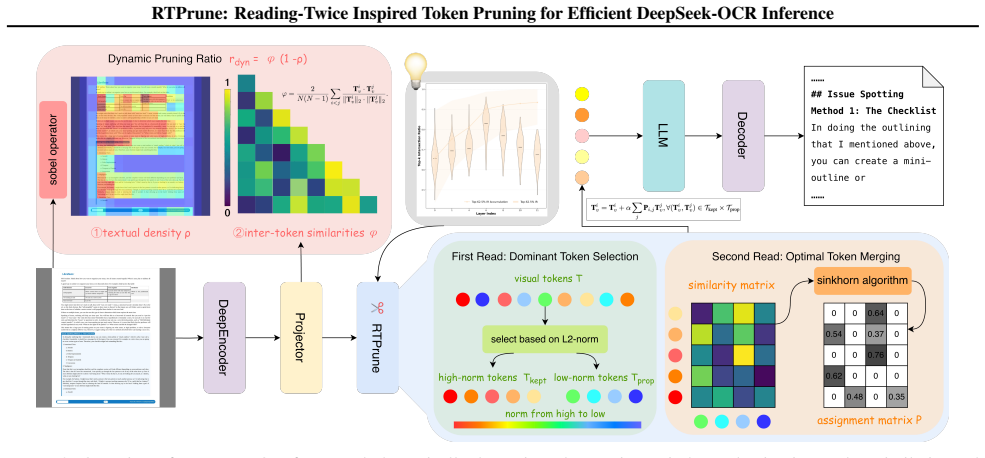

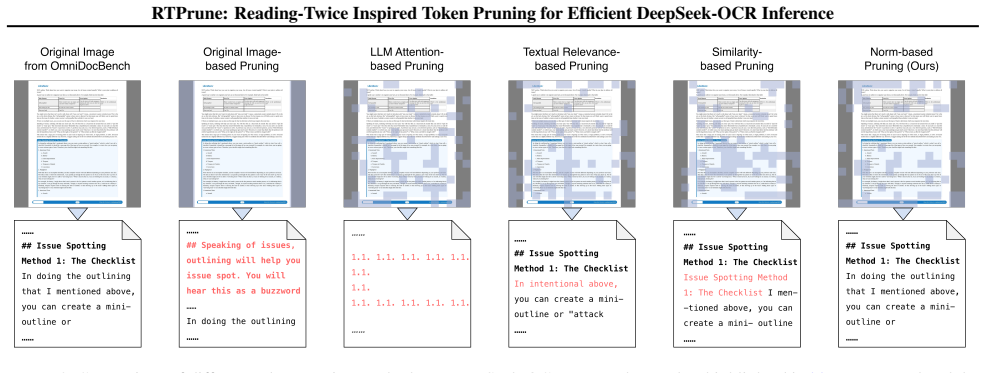







read the original abstract
DeepSeek-OCR leverages visual-text compression to reduce long-text processing costs and accelerate inference, yet visual tokens remain prone to redundant textual and structural information. Moreover, current token pruning methods for conventional vision-language models (VLMs) fail to preserve textual fidelity due to improper compression mechanisms. By analyzing the decoding process of DeepSeek-OCR, we find that a distinct two-stage reading trajectory: the model initially prioritizes the majority of high-norm tokens, then subsequently redistributes its attention to the remaining ones. Motivated by this insight, we propose RTPrune, a two-stage token pruning method tailored for DeepSeek-OCR. In the first stage, we prioritize high-norm visual tokens that capture salient textual and structural information. In the second stage, the remaining tokens are paired and merged based on optimal transport theory to achieve efficient feature aggregation. We further introduce a dynamic pruning ratio that adapts to token similarity and textual density for OCR tasks, enabling a better efficiency-accuracy trade-off. Extensive experiments demonstrate state-of-the-art performance, as evidenced by 99.47% accuracy and 1.23$\times$ faster prefill on OmniDocBench, achieved with 84.25% token retention when applied to DeepSeek-OCR-Large.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RTPrune, a two-stage token pruning method for DeepSeek-OCR. It identifies a distinct two-stage reading trajectory in which the model first prioritizes high-norm visual tokens and later redistributes attention to the remainder. Stage one prunes high-norm tokens that capture salient textual and structural information; stage two pairs and merges the remaining tokens via optimal transport for feature aggregation. A dynamic pruning ratio adapts to token similarity and textual density. The abstract reports state-of-the-art results of 99.47% accuracy and 1.23× faster prefill on OmniDocBench at 84.25% token retention when applied to DeepSeek-OCR-Large.
Significance. If the two-stage trajectory observation holds and the pruning/merging steps preserve textual fidelity, the approach could meaningfully accelerate OCR inference in VLMs while maintaining high accuracy. The use of optimal transport for merging and a task-specific dynamic ratio are potentially useful ideas. However, the abstract supplies no baselines, ablations, error bars, or implementation details, so the practical significance and reproducibility cannot be evaluated from the provided text.
major comments (1)
- [Abstract] Abstract: the abstract states strong numerical results (99.47% accuracy, 1.23× faster prefill) but supplies no baselines, error bars, ablation studies, or implementation details; without these it is impossible to verify whether the claimed accuracy and speedup are supported by the data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states strong numerical results (99.47% accuracy, 1.23× faster prefill) but supplies no baselines, error bars, ablation studies, or implementation details; without these it is impossible to verify whether the claimed accuracy and speedup are supported by the data.
Authors: We agree that the abstract, due to strict length limits, does not include explicit baselines, error bars, ablations, or implementation details. These elements are fully detailed in the Experiments section of the manuscript, including comparisons to prior token-pruning methods on OmniDocBench, ablation studies on the two-stage trajectory and dynamic ratio, results with standard deviations across runs, and implementation specifics in the appendix. To improve verifiability from the abstract alone, we will revise it to briefly note that the reported accuracy and speedup are achieved relative to existing pruning baselines while retaining 84.25% of tokens. This change will be made in the next version. revision: yes
Circularity Check
No significant circularity detected from abstract
full rationale
The abstract presents a high-level motivation from an observed two-stage reading trajectory in DeepSeek-OCR, followed by a proposed two-stage pruning method (high-norm prioritization then optimal-transport merging) and a dynamic ratio adapting to token similarity and density. No equations, parameter-fitting procedures, self-citations, or derivations are provided that could reduce the claimed method or performance results to inputs by construction. The reported accuracy and speedup are experimental outcomes, not predictions forced by the pruning rule itself. With only the abstract available, no load-bearing circular steps of any enumerated kind are identifiable; the derivation chain remains self-contained at the level of description.
Axiom & Free-Parameter Ledger
free parameters (1)
- dynamic pruning ratio
axioms (1)
- domain assumption DeepSeek-OCR exhibits a distinct two-stage reading trajectory that first prioritizes high-norm tokens.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2501.15558 , year=
Chen, S., Guo, X., Li, Y ., Zhang, T., Lin, M., Kuang, D., Zhang, Y ., Ming, L., Zhang, F., Wang, Y ., et al. Ocean-ocr: Towards general ocr application via a vision-language model.arXiv preprint arXiv:2501.15558,
-
[3]
PaddleOCR 3.0 Technical Report
Cui, C., Sun, T., Lin, M., Gao, T., Zhang, Y ., Liu, J., Wang, X., Zhang, Z., Zhou, C., Liu, H., et al. Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595,
work page internal anchor Pith review arXiv
-
[4]
Vision transformers need registers
Darcet, T., Oquab, M., Mairal, J., and Bojanowski, P. Vision transformers need registers. InInternational Conference on Learning Representations, volume 2024, pp. 2632– 2652,
work page 2024
-
[5]
Deng, J., Li, W., Zhou, J. T., and He, Y . Scope: Saliency- coverage oriented token pruning for efficient multimodel llms.arXiv preprint arXiv:2510.24214,
-
[6]
Glm-ocr technical report.arXiv preprint arXiv:2603.10910,
Duan, S., Xue, Y ., Wang, W., Su, Z., Liu, H., Yang, S., Gan, G., Wang, G., Wang, Z., Yan, S., et al. Glm-ocr technical report.arXiv preprint arXiv:2603.10910,
-
[7]
Huang, Y ., Ma, F., Shao, Y ., Guo, J., Yu, Z., Cui, L., and Tian, Q. N \” uwa: Mending the spatial integrity torn by vlm token pruning.arXiv preprint arXiv:2602.02951,
-
[8]
Dcp: Dual-cue pruning for efficient large vision-language models
Jiang, L., Zhang, Z., Zeng, Y ., Xie, C., Liu, T., Li, Z., Cheng, L., and Xu, X. Dcp: Dual-cue pruning for efficient large vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 21202–21215, 2025a. Jiang, Y ., Wu, Q., Lin, W., Yu, W., and Zhou, Y . What kind of visual tokens do we need? traini...
work page 2025
-
[9]
Lappe, A. and Giese, M. A. Register and cls tokens yield a decoupling of local and global features in large vits. arXiv preprint arXiv:2505.05892,
-
[10]
Li, K., Chen, X., Gao, C., Li, Y ., and Chen, X. Bal- anced token pruning: Accelerating vision language models beyond local optimization.arXiv preprint arXiv:2505.22038, 2025a. Li, Y ., Yang, G., Liu, H., Wang, B., and Zhang, C. dots. ocr: Multilingual document layout parsing in a single vision-language model.arXiv preprint arXiv:2512.02498, 2025b. Liu, H...
-
[11]
Liu, H., Li, C., Li, Y ., and Lee, Y . J. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 26296–26306, 2024a. Liu, H., Li, C., Li, Y ., Li, B., Zhang, Y ., Shen, S., and Lee, Y . J. Llava-next: Improved reason- ing, ocr, and world knowledge, January 2024b. 10 RTPru...
-
[12]
Poznanski, J., Rangapur, A., Borchardt, J., Dunkelberger, J., Huff, R., Lin, D., Wilhelm, C., Lo, K., and Soldaini, L. olmocr: Unlocking trillions of tokens in pdfs with vi- sion language models.arXiv preprint arXiv:2502.18443, 2025a. Poznanski, J., Soldaini, L., and Lo, K. olmocr 2: Unit test rewards for document ocr, 2025b. URL https: //arxiv.org/abs/25...
-
[13]
Sobel, I., Feldman, G., et al. A 3x3 isotropic gradient operator for image processing.a talk at the Stanford Artificial Project in, 1968:271–272,
work page 1968
-
[14]
Taghadouini, S., Cavaill`es, A., and Aubertin, B. Lightonocr: A 1b end-to-end multilingual vision-language model for state-of-the-art ocr.arXiv preprint arXiv:2601.14251,
-
[15]
DeepSeek-OCR: Contexts Optical Compression
URL https://arxiv.org/ abs/2510.18234. Wei, H., Sun, Y ., and Li, Y . Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552,
work page internal anchor Pith review arXiv
-
[16]
Stop looking for important tokens in multimodal language models: Duplication matters more
Wen, Z., Gao, Y ., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., and Zhang, L. Stop looking for important tokens in multimodal language models: Duplication matters more. arXiv preprint arXiv:2502.11494,
-
[17]
Yao, L., Xing, L., Shi, Y ., Li, S., Liu, Y ., Dong, Y ., Zhang, Y .-F., Li, L., Dong, Q., Dong, X., et al. Towards efficient multimodal large language models: A survey on token compression.TechRxiv, 2026(0112),
work page 2026
-
[18]
URL https://www.techrxiv.org/doi/abs/10
doi: 10.36227/techrxiv.176823010.07236701/v1. URL https://www.techrxiv.org/doi/abs/10. 36227/techrxiv.176823010.07236701/v1. Ye, W., Wu, Q., Lin, W., and Zhou, Y . Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 39, pp. 22128– 22136,
-
[19]
Zhang, K., Li, B., Zhang, P., Pu, F., Cahyono, J. A., Hu, K., Liu, S., Zhang, Y ., Yang, J., Li, C., et al. Lmms- eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 881–916, 2025a. Zhang, Q., Liu, M., Li, L., Lu, M., Zhang, Y ., Pan, J., She, Q., and Zhang, S. Beyo...
-
[20]
models. Following visualization in CDPruner (Zhang et al., 2025b), Figure 7 visualizes the correlation between the input prompt text and the image embeddings processed by different CLIP. Compared to CLIP- ViT-L/14-336px, CLIP-ViT-B/16 inherently exhibits weaker multi-modal alignment. This alignment is further attenuated as the CLIP model within DeepEncode...
work page 2025
-
[21]
and a shared expert (intermediate dimension 1792), activating only 570M parameters per inference to balance capacity and efficiency. A core optimization lies in dynamic token adaptation: aligned with DeepEncoder’s compression ratio, the decoder adjusts token counts layer-wise during decoding, reducing self-attention’s n2 complexity. Combined with graph-ba...
work page 2025
-
[22]
:Ocean-OCR is a state-of-the-art OCR benchmark tailored for evaluating advanced document understanding capabilities, including complex layout parsing, multi-modal content recognition (e.g., charts, diagrams, and handwritten text), and cross-language OCR performance. The benchmark features a diverse dataset of documents from various domains (e.g., academia...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.