Recognition: 2 theorem links
· Lean TheoremAEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
Pith reviewed 2026-05-11 00:50 UTC · model grok-4.3
The pith
AEM rescales advantages with a response-level entropy proxy to improve credit assignment in multi-turn LLM agent RL without added supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
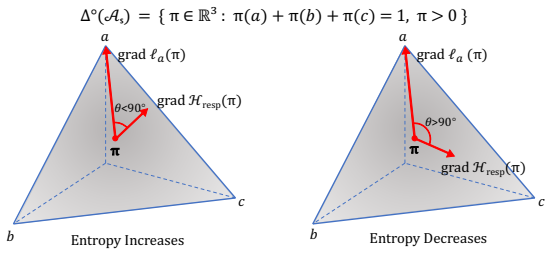
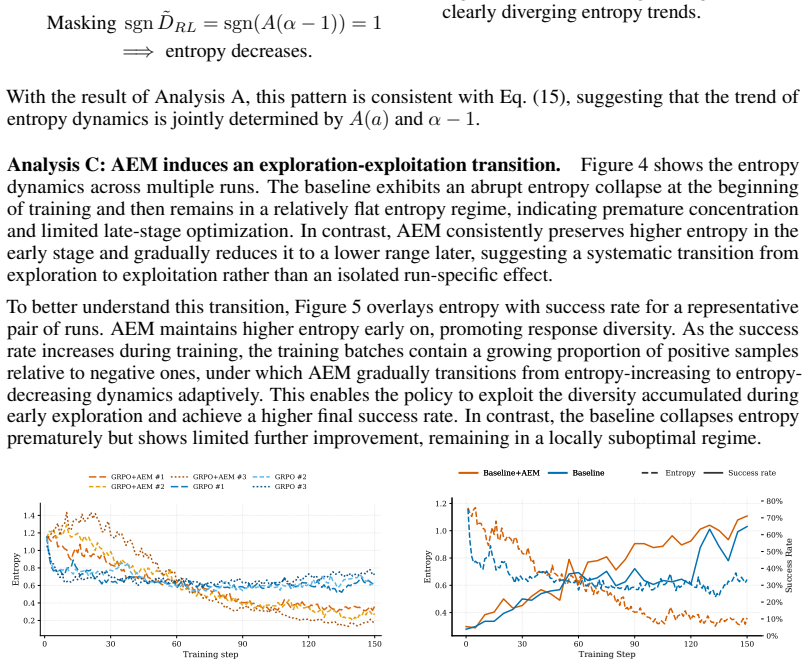
AEM lifts entropy dynamics from token to response level to match the effective action scale of LLM agents. Under natural-gradient updates, entropy drift is shown to be governed by the interaction between the sampled-response advantage and its relative surprisal. This relation yields a practical response-level uncertainty proxy that rescales advantages, allowing the training process to leverage the changing ratio of positive to negative samples for an automatic exploration-to-exploitation transition.
What carries the argument
Response-level uncertainty proxy derived from advantage-surprisal interaction, used to rescale advantages during RL updates.
If this is right
- Credit assignment in long agent trajectories can proceed without process reward models or extra self-supervised objectives.
- The exploration-exploitation balance emerges automatically from sample statistics rather than requiring separate schedules or hyperparameters.
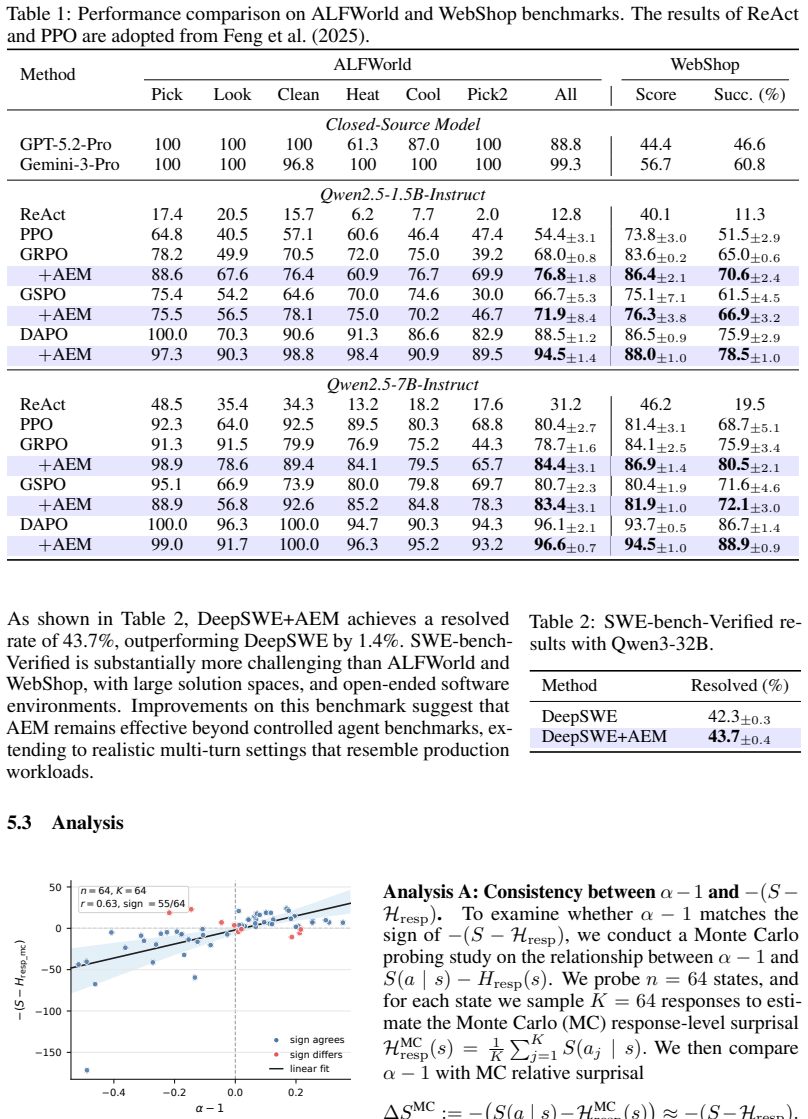
- Training remains effective across model scales from 1.5B to 32B on navigation, web, and software-engineering benchmarks.
- Supervision complexity stays constant while performance rises relative to unmodified RL baselines.
Where Pith is reading between the lines
- The same response-level proxy might reduce the need for hand-crafted dense rewards in other sequential agent settings where actions are extended outputs.
- Token-level entropy signals could systematically understate uncertainty when the environment only observes complete responses.
- The method's reliance on natural sample balance suggests it could adapt to changing task distributions during training without explicit detection.
Load-bearing premise
Lifting entropy analysis from tokens to full responses correctly captures uncertainty at the granularity that actually affects the environment, and this proxy reliably tracks the advantage-surprisal dynamic without being disrupted by token sampling noise.
What would settle it
Run standard RL and AEM side-by-side on a multi-turn task and check whether the AEM version fails to improve final success rate or shows no measurable reduction in entropy drift after the positive-negative sample balance stabilizes.
Figures






read the original abstract
Reinforcement learning (RL) has substantially improved the ability of large language model (LLM) agents to interact with environments and solve multi-turn tasks. However, effective agentic RL remains challenging: sparse outcome-only rewards provide limited guidance for assigning credit to individual steps within long interaction trajectories. Existing approaches often introduce dense intermediate supervision, such as process reward models or auxiliary self-supervised signals, which increases supervision and tuning complexity and may limit generalization across tasks and domains. We present AEM, a supervision-free credit assignment method that adaptively modulates entropy dynamics during RL training to improve the exploration-exploitation trade-off. Since in agentic RL the environment is typically affected by a complete response, rather than an individual token, our analysis lifts entropy dynamics from the token level to the response level, aligning uncertainty estimation with the effective action granularity of LLM agents and reducing sensitivity to token-level sampling noise. We further show that entropy drift under natural-gradient updates is governed by the interaction between the sampled-response advantage and its relative surprisal. Motivated by this result, AEM derives a practical response-level uncertainty proxy and uses it to rescale advantages, leveraging the evolving balance between positive and negative samples to naturally transition from exploration to exploitation. Extensive experiments on ALFWorld, WebShop, and SWE-bench-Verified with models ranging from 1.5B to 32B demonstrate that AEM consistently improves strong RL baselines, including a +1.4\% gain when integrated into a state-of-the-art software-engineering RL training framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AEM, a supervision-free credit-assignment method for multi-turn agentic RL with LLMs. It lifts entropy dynamics from token to response level to align with the granularity at which the environment is affected by complete responses, derives that entropy drift under natural-gradient updates is governed by the interaction between sampled-response advantage and relative surprisal, obtains a practical response-level uncertainty proxy from this analysis, and uses the proxy to rescale advantages so that the balance between positive and negative samples drives a natural transition from exploration to exploitation. Experiments on ALFWorld, WebShop, and SWE-bench-Verified with models from 1.5B to 32B report consistent gains over strong RL baselines, including a +1.4% improvement when integrated into a state-of-the-art software-engineering RL framework.
Significance. If the response-level entropy-drift derivation holds without unstated approximations and the empirical gains are robust to proper controls, AEM would supply a lightweight, supervision-free mechanism for modulating exploration-exploitation in agentic RL that avoids the overhead of process reward models or auxiliary self-supervised signals. The alignment of uncertainty estimation with response-level actions rather than token-level noise is a conceptually attractive feature for multi-turn settings with sparse outcome rewards. The breadth of evaluation across three distinct environments and a wide range of model scales constitutes a positive empirical contribution.
major comments (2)
- [analysis of entropy dynamics] The central claim that entropy drift under natural-gradient updates is governed by the interaction between the sampled-response advantage and its relative surprisal (and that this interaction directly motivates a practical response-level uncertainty proxy) is load-bearing for the entire supervision-free credit-assignment mechanism. The manuscript summarizes this analysis at a high level without providing the explicit update equations, the natural-gradient derivation steps, or the approximations employed (e.g., neglect of higher-order terms or assumptions about unbiased advantage estimates at response granularity). Without these details it is impossible to verify whether the proxy truly reduces sensitivity to token-level sampling noise or whether it introduces circularity with fitted parameters.
- [experimental evaluation] The experimental claims of consistent improvement, including the reported +1.4% gain on SWE-bench-Verified, rest on comparisons whose details are not visible in the provided description. No information is given on the precise baselines, number of random seeds, statistical significance tests, or ablation controls that isolate the contribution of the advantage-rescaling step from other implementation choices. This absence makes it difficult to assess whether the observed gains are attributable to AEM or to uncontrolled variance.
minor comments (2)
- [method] The notation used for the response-level uncertainty proxy and the advantage-rescaling operation should be introduced with an explicit formula (ideally an equation) rather than a prose description, to facilitate reproducibility.
- The abstract and introduction would benefit from a short statement of the precise functional form of the proxy (e.g., whether it is a normalized surprisal term or an advantage-weighted entropy estimate) so that readers can immediately grasp the computational overhead.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below, providing clarifications on the theoretical derivation and committing to expanded experimental reporting in the revision.
read point-by-point responses
-
Referee: [analysis of entropy dynamics] The central claim that entropy drift under natural-gradient updates is governed by the interaction between the sampled-response advantage and its relative surprisal (and that this interaction directly motivates a practical response-level uncertainty proxy) is load-bearing for the entire supervision-free credit-assignment mechanism. The manuscript summarizes this analysis at a high level without providing the explicit update equations, the natural-gradient derivation steps, or the approximations employed (e.g., neglect of higher-order terms or assumptions about unbiased advantage estimates at response granularity). Without these details it is impossible to verify whether the proxy truly reduces sensitivity to token-level sampling noise or whether it introduces circularity with fitted parameters.
Authors: We agree that the high-level presentation in the main text requires expansion for verifiability. Appendix B of the manuscript contains the full natural-gradient derivation, starting from the policy gradient and deriving the entropy drift equation under the first-order approximation (neglecting higher-order terms) with the assumption of unbiased advantage estimates at response granularity. We will move the key update equations and steps into the main text. The proxy follows directly from the advantage-surprisal interaction using only quantities already present in standard RL (no additional fitted parameters), eliminating circularity while aligning modulation with response-level actions to reduce token noise sensitivity. revision: yes
-
Referee: [experimental evaluation] The experimental claims of consistent improvement, including the reported +1.4% gain on SWE-bench-Verified, rest on comparisons whose details are not visible in the provided description. No information is given on the precise baselines, number of random seeds, statistical significance tests, or ablation controls that isolate the contribution of the advantage-rescaling step from other implementation choices. This absence makes it difficult to assess whether the observed gains are attributable to AEM or to uncontrolled variance.
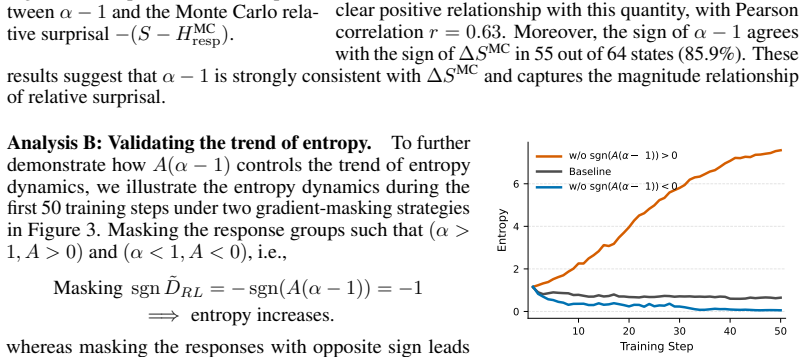
Authors: We acknowledge that the summary description omitted key controls. Section 4 and Appendix C detail the baselines (PPO, GRPO, and SOTA software-engineering RL framework), use of 5 random seeds with mean/std reporting, paired t-tests for significance, and ablations that isolate the advantage-rescaling component while holding all other hyperparameters fixed. The +1.4% gain on SWE-bench-Verified is from controlled integration into the SOTA framework. We will add a summary table of these controls to the main text to make attribution to AEM explicit. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper claims to derive a response-level uncertainty proxy by first showing mathematically that entropy drift under natural-gradient updates is governed by the interaction between sampled-response advantage and relative surprisal, then using that result to motivate the proxy for rescaling advantages. This is presented as an analysis lifted from token to response level to align with agentic action granularity, without evidence of self-definition (e.g., defining the proxy in terms of itself), renaming a fitted input as a prediction, or load-bearing self-citation chains that reduce the central claim to unverified prior work by the same authors. The derivation is self-contained against the stated RL assumptions and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Environment is affected by a complete response rather than an individual token
invented entities (1)
-
response-level uncertainty proxy
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearentropy drift under natural-gradient updates is governed by the interaction between the sampled-response advantage and its relative surprisal... Dresp_RL(a;s) := <gradF Hresp(π), gradF ℓa(π)>_Fisher-Rao = A(a,s)(S(a|s) - Hresp(s))
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[2]
2024 , booktitle =
Huang, Jiangyong and Yong, Silong and Ma, Xiaojian and Linghu, Xiongkun and Li, Puhao and Wang, Yan and Li, Qing and Zhu, Song-Chun and Jia, Baoxiong and Huang, Siyuan , title =. 2024 , booktitle =
2024
-
[3]
How to Train Your
Dheeraj Vattikonda and Santhoshi Ravichandran and Emiliano Penaloza and Hadi Nekoei and Thibault Le Sellier de Chezelles and Megh Thakkar and Nicolas Gontier and Miguel Mu. How to Train Your. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[4]
Silver, David and Huang, Aja and Maddison, Chris J. and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal =. Mastering the Game of
-
[5]
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , journal=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[7]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Asynchronous Methods for Deep Reinforcement Learning , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[8]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[9]
International Conference on Learning Representations (ICLR) , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[10]
Transactions on Machine Learning Research , year=
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey , author=. Transactions on Machine Learning Research , year=
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
WebEvolver: Enhancing Web Agent Self-Improvement with Co-evolving World Model , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[12]
The Fourteenth International Conference on Learning Representations , year =
Test-Time Adaptation for LLM Agents via Environment Interaction , author=. The Fourteenth International Conference on Learning Representations , year =
-
[13]
Advances in Neural Information Processing Systems , volume=
Avatar: Optimizing llm agents for tool usage via contrastive reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
ICML 2025 Workshop on Computer Use Agents , year=
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment , author=. ICML 2025 Workshop on Computer Use Agents , year=
2025
-
[15]
International Conference on Learning Representations (ICLR) , year =
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents , author =. International Conference on Learning Representations (ICLR) , year =
-
[16]
WebGPT: Browser-assisted question-answering with human feedback
WebGPT: Browser-assisted Question-answering with Human Feedback , author =. arXiv preprint arXiv:2112.09332 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author =. arXiv preprint arXiv:2307.13854 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Conference on Robot Learning (CoRL) , year =
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author =. Conference on Robot Learning (CoRL) , year =
-
[19]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
STaR: Bootstrapping Reasoning with Reasoning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
Training language models to follow instructions with human feedback
Training language models to follow instructions with human feedback , author =. arXiv preprint arXiv:2203.02155 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2021 , url =
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre C\^ot\'e and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle =. 2021 , url =
2021
-
[24]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[26]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
SWE-smith: Scaling Data for Software Engineering Agents , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Taskbench: Benchmarking large language models for task automation , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[30]
NeurIPS 2024 , year=
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making , author=. NeurIPS 2024 , year=
2024
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Embodied multi-modal agent trained by an llm from a parallel textworld , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Forty-second International Conference on Machine Learning , year=
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
Advances in Neural Information Processing Systems , year=
A-Mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , year=
-
[34]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agent-pro: Learning to evolve via policy-level reflection and optimization , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[35]
The Fourteenth International Conference on Learning Representations , year=
ATPO: ADAPTIVE TREE POLICY OPTIMIZATION FOR MULTI-TURN MEDICAL DIALOGUE , author=. The Fourteenth International Conference on Learning Representations , year=
-
[36]
The Fourteenth International Conference on Learning Representations , year=
TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[37]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[38]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[40]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
The entropy mechanism of reinforcement learning for reasoning language models , author=. arXiv preprint arXiv:2505.22617 , year=
work page internal anchor Pith review arXiv
-
[41]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
On Entropy Control in
Han Shen , booktitle=. On Entropy Control in
-
[43]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[44]
arXiv preprint arXiv:2502.01600 , year=
Reinforcement learning for long-horizon interactive llm agents , author=. arXiv preprint arXiv:2502.01600 , year=
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[46]
arXiv preprint arXiv:2509.09265 , year=
Harnessing uncertainty: Entropy-modulated policy gradients for long-horizon llm agents , author=. arXiv preprint arXiv:2509.09265 , year=
-
[47]
Junbo Li, Peng Zhou, Rui Meng, Meet P
Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training , author=. arXiv preprint arXiv:2602.19225 , year=
-
[48]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
MobileUse: A Hierarchical Reflection-Driven GUI Agent for Autonomous Mobile Operation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[51]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
SE-GUI: Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[52]
Hindsight credit assignment for long-horizon llm agents, 2026
Hindsight Credit Assignment for Long-Horizon LLM Agents , author=. arXiv preprint arXiv:2603.08754 , year=
-
[53]
The Fourteenth International Conference on Learning Representations , year=
Hierarchy-of-Groups Policy Optimization for Long-Horizon Agentic Tasks , author=. The Fourteenth International Conference on Learning Representations , year=
-
[54]
Epo: Entropy-regularized policy optimization for llm agents reinforcement learning , author=. arXiv preprint arXiv:2509.22576 , year=
-
[55]
2025 , howpublished=
rLLM: A Framework for Post-Training Language Agents , author=. 2025 , howpublished=
2025
-
[56]
arXiv preprint arXiv:2505.20732 , year=
Spa-rl: Reinforcing llm agents via stepwise progress attribution , author=. arXiv preprint arXiv:2505.20732 , year=
-
[57]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Group-in-Group Policy Optimization for LLM Agent Training , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[58]
DeepSWE: Training a State-of-the-Art Coding Agent from Scratch by Scaling RL , author =
-
[59]
ICML 2024 , year =
R2E: Turning any Github Repository into a Programming Agent Environment , author=. ICML 2024 , year =
2024
-
[60]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
2026 , booktitle =
Dong, Guanting and Bao, Licheng and Wang, Zhongyuan and Zhao, Kangzhi and Li, Xiaoxi and Jin, Jiajie and Yang, Jinghan and Mao, Hangyu and Zhang, Fuzheng and Gai, Kun and Zhou, Guorui and Zhu, Yutao and Wen, Ji-Rong and Dou, Zhicheng , title =. 2026 , booktitle =
2026
-
[62]
The Fourteenth International Conference on Learning Representations , year=
Agentic Reinforced Policy Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
-
[63]
2026 , eprint=
Flexible Entropy Control in RLVR with Gradient-Preserving Perspective , author=. 2026 , eprint=
2026
-
[64]
2000 , publisher =
Methods of Information Geometry , author =. 2000 , publisher =
2000
-
[65]
2020 , publisher =
An Elementary Introduction to Information Geometry , author =. 2020 , publisher =
2020
-
[66]
Advances in neural information processing systems , volume=
A natural policy gradient , author=. Advances in neural information processing systems , volume=
-
[67]
The Fourteenth International Conference on Learning Representations , year=
Entropy-preserving reinforcement learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[68]
Actor-Critic Algorithms , url =
Konda, Vijay and Tsitsiklis, John , booktitle =. Actor-Critic Algorithms , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.