Recognition: unknown
LIMSSR: LLM-Driven Sequence-to-Score Reasoning under Training-Time Incomplete Multimodal Observations
Pith reviewed 2026-05-09 20:12 UTC · model grok-4.3
The pith
Large language models can drive effective multimodal sequence-to-score reasoning even when training data lacks complete modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
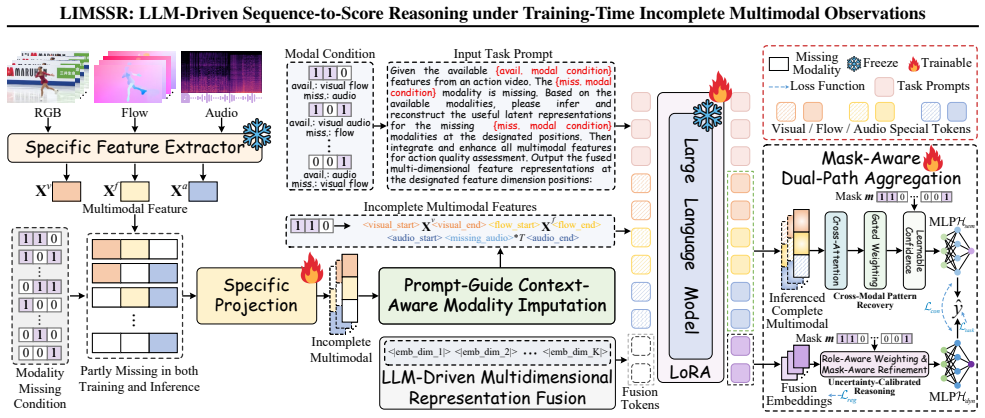
LIMSSR reformulates training-time incomplete multimodal learning as a conditional sequence-to-score reasoning problem. It applies prompt-guided context-aware modality imputation and multidimensional representation fusion to let an LLM infer latent semantics directly from whatever modalities are observed, then uses mask-aware dual-path aggregation to calibrate uncertainty and limit hallucinations. Experiments on three action quality assessment datasets show the approach outperforms state-of-the-art baselines that still rely on complete training observations.
What carries the argument
LLM-driven sequence-to-score reasoning, which turns partial multimodal inputs into a conditional reasoning task solved by prompt-guided imputation and fusion instead of explicit reconstruction.
If this is right
- Multimodal models can be trained directly on datasets that contain missing modalities at training time rather than requiring imputation or reconstruction supervision first.
- Sequence-to-score tasks such as action quality assessment become feasible in settings where some sensors or views are unavailable throughout data collection.
- LLM prompting plus dual-path calibration provides an alternative to traditional cross-modal priors when a complete training view is absent.
- Data-efficient multimodal learning no longer needs the unrealistic assumption of full-modal availability during training.
Where Pith is reading between the lines
- The same framing could be tested on other sequence prediction problems such as future frame forecasting or medical time-series scoring where modalities drop out irregularly.
- If the LLM component generalizes, practitioners could reduce the cost of synchronizing multiple sensors by accepting partial recordings and relying on reasoning to fill gaps.
- The method implicitly suggests that prompting strategies may substitute for learned cross-modal mappings in low-data regimes.
Load-bearing premise
Large language models can reliably extract latent semantics from partial multimodal contexts via prompting, and the mask-aware dual-path step is sufficient to keep those inferences from introducing damaging hallucinations.
What would settle it
On a new action quality assessment dataset collected with training-time modality dropout, measure whether LIMSSR still beats the strongest baseline that assumes complete training data; if it does not, or if manual inspection shows frequent uncalibrated hallucinations, the central claim fails.
Figures






read the original abstract
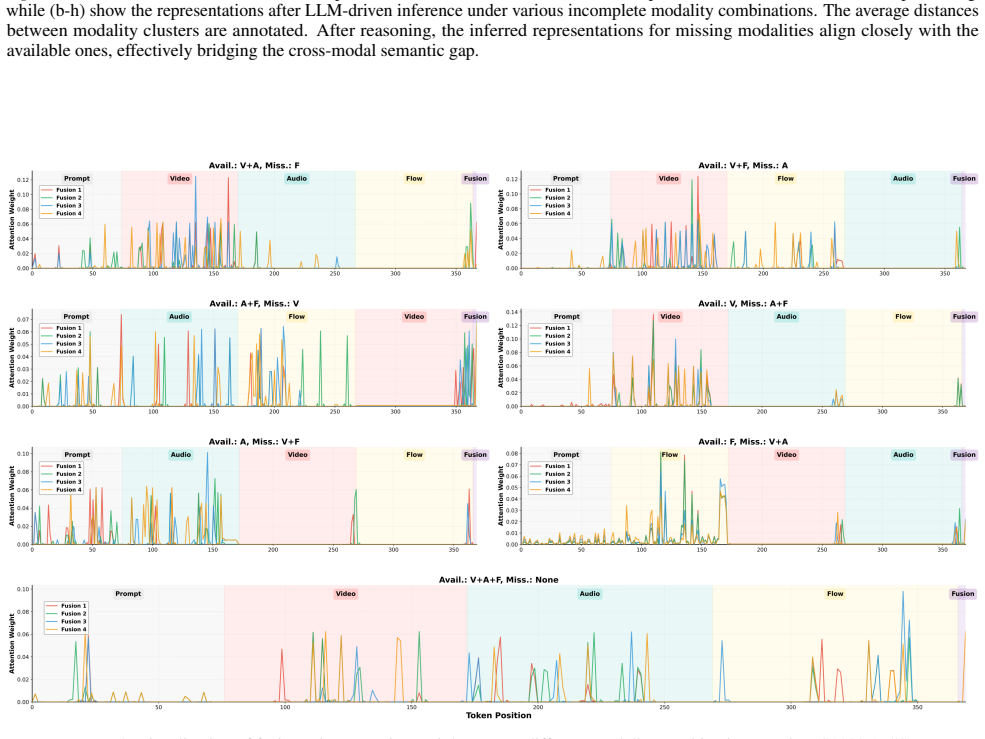
Real-world multimodal learning is often hindered by missing modalities. While Incomplete Multimodal Learning (IML) has gained traction, existing methods typically rely on the unrealistic assumption of full-modal availability during training to provide reconstruction supervision or cross-modal priors. This paper tackles the more challenging setting of IML under training-time incomplete observations, which precludes reliance on a ``God's eye view'' of complete data. We propose LIMSSR (LLM-Driven Incomplete Multimodal Sequence-to-Score Reasoning), a framework that reformulates this challenge as a conditional sequence reasoning task. LIMSSR leverages the semantic reasoning capabilities of Large Language Models via Prompt-Guided Context-Aware Modality Imputation and Multidimensional Representation Fusion to infer latent semantics from available contexts without direct reconstruction. To mitigate hallucinations, we introduce a Mask-Aware Dual-Path Aggregation to dynamically calibrate inference uncertainty. Extensive experiments on three Action Quality Assessment datasets demonstrate that LIMSSR significantly outperforms state-of-the-art baselines without relying on complete training data, establishing a new paradigm for data-efficient multimodal learning. Code is available at https://github.com/XuHuangbiao/LIMSSR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LIMSSR, a framework for incomplete multimodal learning under the realistic but challenging setting of training-time incomplete observations (no complete modalities available for supervision or priors). It reformulates the task as conditional sequence-to-score reasoning, using Prompt-Guided Context-Aware Modality Imputation and Multidimensional Representation Fusion via LLMs to infer latent semantics, plus a Mask-Aware Dual-Path Aggregation module to dynamically calibrate uncertainty and mitigate hallucinations. Extensive experiments on three Action Quality Assessment datasets are claimed to show significant outperformance over state-of-the-art baselines without relying on complete training data, with code released.
Significance. If the results and hallucination mitigation hold under scrutiny, this would represent a meaningful advance by relaxing the common IML assumption of full-modal training data, enabling more practical data-efficient multimodal systems in domains like action quality assessment. The LLM-driven imputation without reconstruction and the dual-path aggregation are original contributions that could influence future work on reasoning under partial observations.
major comments (3)
- [Abstract] Abstract: the central claim of significant outperformance on three datasets is asserted without any quantitative metrics, error bars, ablation results, or baseline numbers supplied in the text. This is load-bearing for the paper's main contribution and prevents evaluation of whether the gains are substantial or merely incremental.
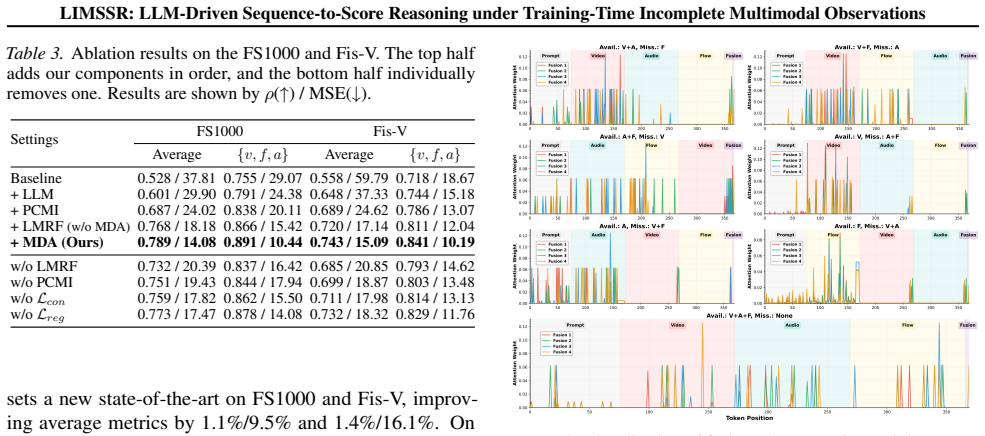
- [Method] Method (Prompt-Guided Context-Aware Modality Imputation and Mask-Aware Dual-Path Aggregation): no explicit equations, algorithmic steps, or derivation are given for how the dual-path mechanism weights or flags LLM inferences, nor how it prevents error propagation when training occurs entirely without complete observations. The claim that this reliably recovers actionable semantics therefore rests on unverified assumptions about LLM faithfulness.
- [Experiments] Experiments: no ablation isolating the contribution of the mask-aware aggregation, no analysis of hallucination rates or uncertainty calibration, and no comparison to reconstruction-based IML methods under the same incomplete-training protocol. Without such evidence, the skeptic concern that LLM biases propagate directly into scores remains unaddressed and undermines the data-efficient paradigm claim.
minor comments (2)
- [Introduction] The term 'sequence-to-score reasoning' is introduced without a formal definition or diagram showing the exact input-output mapping from partial multimodal sequences to scalar scores.
- [Related Work] Related work could more explicitly contrast the training-time incomplete setting against prior IML methods that assume full modalities at train time, to better motivate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each of the major comments by providing clarifications and committing to revisions that strengthen the paper's presentation and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of significant outperformance on three datasets is asserted without any quantitative metrics, error bars, ablation results, or baseline numbers supplied in the text. This is load-bearing for the paper's main contribution and prevents evaluation of whether the gains are substantial or merely incremental.
Authors: We agree that including quantitative support in the abstract would better substantiate our claims. In the revised manuscript, we will update the abstract to include key performance metrics from our experiments, such as the reported improvements over baselines on the three Action Quality Assessment datasets, to allow readers to evaluate the significance of the results. revision: yes
-
Referee: [Method] Method (Prompt-Guided Context-Aware Modality Imputation and Mask-Aware Dual-Path Aggregation): no explicit equations, algorithmic steps, or derivation are given for how the dual-path mechanism weights or flags LLM inferences, nor how it prevents error propagation when training occurs entirely without complete observations. The claim that this reliably recovers actionable semantics therefore rests on unverified assumptions about LLM faithfulness.
Authors: We acknowledge the need for more formal details in the method section. The original manuscript describes the components in detail, but to address this, we will add explicit equations for the mask-aware weighting and aggregation process in the revision. These will illustrate how the dual-path mechanism uses available masks to calibrate uncertainty and reduce error propagation, providing a clearer derivation without assuming unverified LLM properties. revision: yes
-
Referee: [Experiments] Experiments: no ablation isolating the contribution of the mask-aware aggregation, no analysis of hallucination rates or uncertainty calibration, and no comparison to reconstruction-based IML methods under the same incomplete-training protocol. Without such evidence, the skeptic concern that LLM biases propagate directly into scores remains unaddressed and undermines the data-efficient paradigm claim.
Authors: This comment highlights important gaps in the experimental validation. While our experiments show overall superiority, we agree that targeted analyses are necessary. In the revised paper, we will include an ablation study on the mask-aware aggregation, report on hallucination mitigation through empirical consistency measures, and provide comparisons against reconstruction-based methods in the training-time incomplete setting. This will directly address concerns about bias propagation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes LIMSSR as an original framework that reformulates incomplete multimodal learning as a conditional sequence reasoning task, using Prompt-Guided Context-Aware Modality Imputation, Multidimensional Representation Fusion, and Mask-Aware Dual-Path Aggregation. These components are presented as novel contributions without any quoted equations or steps that reduce by construction to fitted parameters, self-definitions, or prior self-citations. Central claims rest on empirical outperformance on three Action Quality Assessment datasets under training-time incomplete observations, not on tautological renaming or load-bearing self-references. External reliance on pretrained LLMs is acknowledged but does not create internal circularity, as no derivation step equates outputs to inputs via the paper's own mechanisms.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hyperparameters for representation fusion and aggregation
axioms (1)
- domain assumption Large language models possess sufficient semantic reasoning capabilities to impute missing modalities from available context via prompting
invented entities (1)
-
Mask-Aware Dual-Path Aggregation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Multi-modal multi-action video recognition , author=
-
[2]
ICML , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. ICML , pages=
-
[3]
ICML , pages=
Learning transferable visual models from natural language supervision , author=. ICML , pages=. 2021 , organization=
2021
-
[4]
Learning spatiotemporal features with 3d convolutional networks , author=
-
[5]
Quo vadis, action recognition? a new model and the kinetics dataset , author=
-
[6]
MICCAI , pages=
Automated assessment of surgical skills using frequency analysis , author=. MICCAI , pages=
-
[7]
Relative hidden markov models for video-based evaluation of motion skills in surgical training , author=
-
[8]
Prashant Pandey and Prathosh AP and Manu Kohli and Josh Pritchard , title =
-
[9]
MMAR , pages=
Video-based motion expertise analysis in simulation-based surgical training using hierarchical dirichlet process hidden markov model , author=. MMAR , pages=
-
[10]
IJCARS , volume=
Video and accelerometer-based motion analysis for automated surgical skills assessment , author=. IJCARS , volume=
-
[11]
IPCAI , pages=
Pairwise comparison-based objective score for automated skill assessment of segments in a surgical task , author=. IPCAI , pages=
-
[12]
Attention is all you need , author=
-
[13]
The pros and cons: Rank-aware temporal attention for skill determination in long videos , author=
-
[14]
Logo: A long-form video dataset for group action quality assessment , author=
-
[15]
Finediving: A fine-grained dataset for procedure-aware action quality assessment , author=
-
[16]
What and how well you performed? a multitask learning approach to action quality assessment , author=
-
[17]
Group-aware contrastive regression for action quality assessment , author=
-
[18]
Action quality assessment with temporal parsing transformer , author=
-
[19]
Action assessment by joint relation graphs , author=
-
[20]
Tsa-net: Tube self-attention network for action quality assessment , author=
-
[21]
Learning to score olympic events , author=
-
[22]
2019 , publisher=
Learning to score figure skating sport videos , author=. 2019 , publisher=
2019
-
[23]
Uncertainty-aware score distribution learning for action quality assessment , author=
-
[24]
Hierarchical graph convolutional networks for action quality assessment , author=
-
[25]
Zhou, Kanglei and Cai, Ruizhi and Ma, Yue and Tan, Qingqing and Wang, Xinning and Li, Jianguo and Shum, Hubert P. H. and Li, Frederick W. B. and Jin, Song and Liang, Xiaohui , journal=TVCG, title=. 2023 , volume=
2023
-
[26]
Action quality assessment using siamese network-based deep metric learning , author=
-
[27]
Pairwise Contrastive Learning Network for Action Quality Assessment , author=
-
[28]
AI-ED , volume=
Automated video assessment of human performance , author=. AI-ED , volume=
-
[29]
IEEE TNSRE , volume=
A deep learning framework for assessing physical rehabilitation exercises , author=. IEEE TNSRE , volume=
-
[30]
2024 , publisher=
EGCN++: A new fusion strategy for ensemble learning in skeleton-based rehabilitation exercise assessment , author=. 2024 , publisher=
2024
-
[31]
Assessing the quality of actions , author=
-
[32]
Am I a baller? basketball performance assessment from first-person videos , author=
-
[33]
Localization-assisted Uncertainty Score Disentanglement Network for Action Quality Assessment , author=
-
[34]
Fine-tuned clip models are efficient video learners , author=
-
[35]
Bidirectional cross-modal knowledge exploration for video recognition with pre-trained vision-language models , author=
-
[36]
Likert scoring with grade decoupling for long-term action assessment , author=
-
[37]
Two-path target-aware contrastive regression for action quality assessment , author=. Inf. Sci. , volume=
-
[38]
2024 , pages=
Xu, Huangbiao and Ke, Xiao and Li, Yuezhou and Xu, Rui and Wu, Huanqi and Lin, Xiaofeng and Guo, Wenzhong , title=. 2024 , pages=
2024
-
[39]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. Proc. NAACL-HLT , pages=
-
[40]
Ast: Audio spectrogram transformer,
Ast: Audio spectrogram transformer , author=. arXiv preprint arXiv:2104.01778 , year=
-
[41]
Multimodal Action Quality Assessment , journal = TIP, volume =
Ling. Multimodal Action Quality Assessment , journal = TIP, volume =
-
[42]
2024 , pages =
Kanglei Zhou and Junlin Li and Ruizhi Cai and Liyuan Wang and Xingxing Zhang and Xiaohui Liang , title =. 2024 , pages =
2024
-
[43]
Learning Semantics-Guided Representations for Scoring Figure Skating , author=
-
[44]
Skating-mixer: Long-term sport audio-visual modeling with mlps , author=
-
[45]
Interpretable Long-term Action Quality Assessment , author=
-
[46]
Scientific reports , volume=
Integrated deep visual and semantic attractor neural networks predict fMRI pattern-information along the ventral object processing pathway , author=. Scientific reports , volume=
-
[47]
Narrative Action Evaluation with Prompt-Guided Multimodal Interaction , author=
-
[48]
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment , author=
-
[49]
Parameter Efficient Multimodal Transformers for Video Representation Learning , author=
-
[50]
WACV , pages=
Action quality assessment across multiple actions , author=. WACV , pages=
-
[51]
Hybrid dynamic-static context-aware attention network for action assessment in long videos , author=
-
[52]
Video swin transformer , author=
-
[53]
and Salamon, Justin and Nieto, Oriol and Russell, Bryan and Saenko, Kate , title =
Tan, Reuben and Ray, Arijit and Burns, Andrea and Plummer, Bryan A. and Salamon, Justin and Nieto, Oriol and Russell, Bryan and Saenko, Kate , title =. 2023 , pages =
2023
-
[54]
ICCVW , year =
Hsiao, Jenhao and Li, Yikang and Ho, Chiuman , title =. ICCVW , year =
-
[55]
arXiv preprint arXiv:2410.07463 , year=
Language-Guided Joint Audio-Visual Editing via One-Shot Adaptation , author=. arXiv preprint arXiv:2410.07463 , year=
-
[56]
Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization , author=
-
[57]
Zero-shot temporal action detection via vision-language prompting , author=
-
[58]
Prompting visual-language models for efficient video understanding , author=
-
[59]
CLIP-guided prototype modulating for few-shot action recognition , author=
-
[60]
Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization , author=
-
[61]
Ada-dqa: Adaptive diverse quality-aware feature acquisition for video quality assessment , author=
-
[62]
Blind image quality assessment via vision-language correspondence: A multitask learning perspective , author=
-
[63]
Exploring clip for assessing the look and feel of images , author=
-
[64]
Deep residual learning for image recognition , author=
- [65]
-
[66]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:
-
[67]
Audio set: An ontology and human-labeled dataset for audio events , author=
-
[68]
NAACL-HLT , pages=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. NAACL-HLT , pages=
-
[69]
ICML , volume =
Gedas Bertasius and Heng Wang and Lorenzo Torresani , title =. ICML , volume =
-
[70]
Inductive representation learning on large graphs , author=
-
[71]
Subjective and objective audio-visual quality assessment for user generated content , author=
-
[72]
WACV , pages=
Mm-vit: Multi-modal video transformer for compressed video action recognition , author=. WACV , pages=
-
[73]
Exploring Cross-Video and Cross-Modality Signals for Weakly-Supervised Audio-Visual Video Parsing , booktitle = NIPS, pages =
Yan. Exploring Cross-Video and Cross-Modality Signals for Weakly-Supervised Audio-Visual Video Parsing , booktitle = NIPS, pages =
-
[74]
WACV , pages =
Yating Xu and Conghui Hu and Gim Hee Lee , title =. WACV , pages =
-
[75]
ICCVW , pages =
Lu Chi and Guiyu Tian and Yadong Mu and Qi Tian , title =. ICCVW , pages =
-
[76]
arXiv preprint arXiv:2211.09623 , year=
Cross-modal adapter for text-video retrieval , author=. arXiv preprint arXiv:2211.09623 , year=
-
[77]
Adaptive stage-aware assessment skill transfer for skill determination , author=
-
[78]
Towards unified surgical skill assessment , author=
-
[79]
MICCAI , pages=
SEDSkill: Surgical Events Driven Method for Skill Assessment from Thoracoscopic Surgical Videos , author=. MICCAI , pages=
-
[80]
Learnable irrelevant modality dropout for multimodal action recognition on modality-specific annotated videos , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.