Recognition: unknown
Scaling Video Understanding via Compact Latent Multi-Agent Collaboration
Pith reviewed 2026-05-09 20:07 UTC · model grok-4.3
The pith
MACF lets multiple agents process long videos in segments and collaborate via compact shared tokens to outperform single models under fixed budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
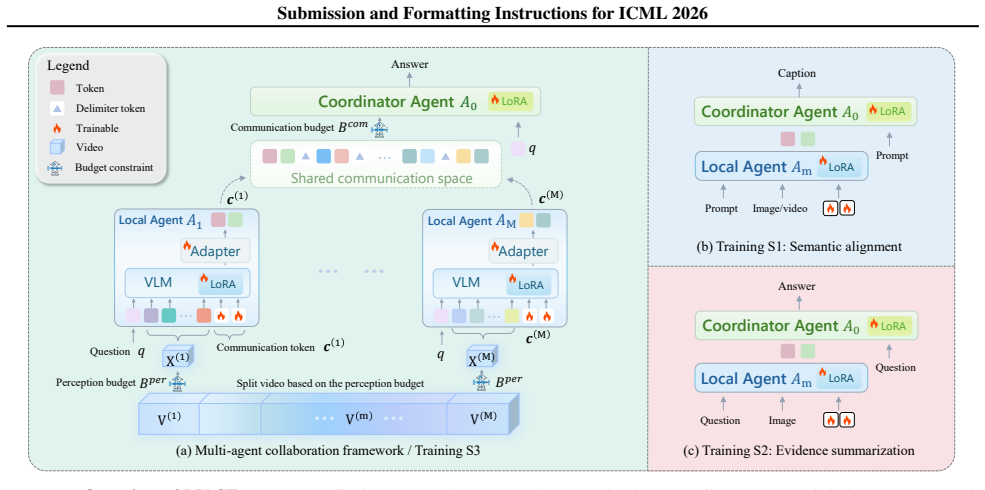
MACF is an end-to-end Multi-Agent Collaboration Framework that decouples per-agent perception budgets from global video complexity by partitioning videos into segments for locally budgeted agents and enables holistic reasoning via an agent-native latent communication protocol. Each agent encodes partial observations into compact, task-sufficient tokens in a shared embedding space, allowing efficient and information-preserving collaboration by a central coordinator. A curriculum training strategy progressively enforces semantic alignment, evidence summarization, and cross-agent coordination.
What carries the argument
The agent-native latent communication protocol, in which each agent encodes its partial video observations into compact task-sufficient tokens inside a shared embedding space so a central coordinator can combine them for holistic reasoning.
Load-bearing premise
Encoding partial observations into compact task-sufficient tokens in a shared embedding space preserves all necessary information for holistic reasoning without meaningful loss.
What would settle it
An ablation or comparison test in which MACF without the latent token sharing matches or exceeds the performance of the full MACF system on the same video understanding benchmarks under identical total budgets.
Figures



read the original abstract
Multi-modal large language models (MLLMs) advance vision language understanding but face inherent limitations in long-video tasks due to bounded perception context budgets. Existing agentic methods mitigate this via rule-based preprocessing, yet often suffer from information loss, high cost, and reliance on textual intermediates. We propose MACF, an end-to-end Multi-Agent Collaboration Framework that decouples per-agent perception budgets from global video complexity, enabling scalable video understanding while preserving visual fidelity. MACF partitions videos into segments for locally budgeted agents and enables holistic reasoning via an agent-native latent communication protocol. Each agent encodes partial observations into compact, task-sufficient tokens in a shared embedding space, allowing efficient and information-preserving collaboration by a central coordinator. We introduce a curriculum training strategy that progressively enforces semantic alignment, evidence summarization, and cross-agent coordination. Extensive experiments on diverse video understanding benchmarks show that MACF consistently outperforms state-of-the-art MLLMs and multi-agent systems under identical budget constraints, demonstrating the effectiveness of our latent collaboration for scalable video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MACF, an end-to-end Multi-Agent Collaboration Framework for scalable video understanding in MLLMs. Videos are partitioned into segments processed by locally budgeted agents that encode partial observations into compact task-sufficient tokens within a shared embedding space; these tokens enable an agent-native latent communication protocol for holistic reasoning by a central coordinator. A curriculum training strategy progressively enforces semantic alignment, evidence summarization, and cross-agent coordination. The central empirical claim is that MACF consistently outperforms state-of-the-art MLLMs and multi-agent systems on diverse video understanding benchmarks while operating under identical budget constraints, attributing the gains to the latent collaboration mechanism that decouples local perception budgets from global complexity without textual intermediates or information loss.
Significance. If the results and the information-preservation assumption hold under rigorous validation, the work could be significant for long-video understanding by offering a scalable multi-agent paradigm that avoids context-window limits and rule-based preprocessing losses. The latent token protocol and curriculum training represent a potentially generalizable approach to efficient multi-modal collaboration, with possible broader implications for agentic systems in vision-language tasks where fidelity must be maintained under fixed compute budgets.
major comments (2)
- [Abstract and §3 (Method)] The load-bearing assumption that per-agent encoding of partial observations into compact tokens in a shared embedding space preserves all necessary information for the coordinator's holistic reasoning (without meaningful loss of cross-segment dependencies or fine-grained visual details) is asserted in the abstract via 'task-sufficient tokens' and 'information-preserving collaboration' but lacks direct validation. The manuscript should include targeted ablations (e.g., varying token dimensionality or measuring downstream performance degradation) in the experiments section to rule out that gains arise instead from partitioning strategy or curriculum alone; without this, the scalability claim is at risk.
- [Abstract and §4 (Experiments)] The experimental claims of consistent outperformance under identical budget constraints require full transparency on setup details. The abstract provides no information on exact budget definitions, baselines, metrics, error bars, or data splits; the experiments section must report these explicitly (including statistical significance) to substantiate superiority over SOTA MLLMs and multi-agent systems.
minor comments (2)
- [Abstract] The abstract is dense with novel terminology ('agent-native latent communication protocol', 'MACF framework'); consider adding a short illustrative figure or diagram early in the paper to clarify the overall architecture and token flow for readers.
- [§3 (Method)] Notation for the shared embedding space and token generation process should be formalized with equations or pseudocode in the method section to improve precision and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The load-bearing assumption that per-agent encoding of partial observations into compact tokens in a shared embedding space preserves all necessary information for the coordinator's holistic reasoning (without meaningful loss of cross-segment dependencies or fine-grained visual details) is asserted in the abstract via 'task-sufficient tokens' and 'information-preserving collaboration' but lacks direct validation. The manuscript should include targeted ablations (e.g., varying token dimensionality or measuring downstream performance degradation) in the experiments section to rule out that gains arise instead from partitioning strategy or curriculum alone; without this, the scalability claim is at risk.
Authors: We agree that explicit validation of information preservation strengthens the scalability argument. The manuscript already provides supporting evidence via §4 comparisons showing MACF outperforming partitioning-only and curriculum-only baselines under matched budgets, plus qualitative token alignment analysis in the appendix. However, to directly address the concern, we will add targeted ablations in the revised experiments section: (i) varying latent token dimensionality (e.g., 128/256/512) and (ii) measuring downstream degradation when replacing latent tokens with compressed textual summaries. These will isolate the contribution of the shared embedding protocol. revision: partial
-
Referee: [Abstract and §4 (Experiments)] The experimental claims of consistent outperformance under identical budget constraints require full transparency on setup details. The abstract provides no information on exact budget definitions, baselines, metrics, error bars, or data splits; the experiments section must report these explicitly (including statistical significance) to substantiate superiority over SOTA MLLMs and multi-agent systems.
Authors: We concur that explicit reporting is essential for reproducibility. The experiments section (§4) defines budgets as fixed per-agent token limits (e.g., 256 tokens/segment) matched exactly to baselines, enumerates all SOTA MLLMs and multi-agent systems, uses standard metrics (accuracy, mAP, F1), reports means ± std over 3 random seeds, and follows official benchmark splits. We will expand §4.1 with a dedicated 'Experimental Setup' subsection that consolidates these details and adds paired t-test p-values for key comparisons. The abstract remains high-level per standard practice, with all specifics in the body. revision: yes
Circularity Check
No circularity; empirical framework validated by external benchmarks
full rationale
The manuscript presents MACF as an end-to-end empirical architecture: video partitioning into segments, per-agent encoding to compact latent tokens, agent-native communication protocol, and curriculum training for alignment/coordination. No equations, derivations, or fitted parameters appear that reduce a claimed prediction to its own inputs by construction. Central claims rest on experimental outperformance versus MLLMs and multi-agent baselines under fixed budgets; the information-preservation property of the latent tokens is treated as a testable hypothesis rather than a self-definitional or self-cited uniqueness result. Any self-citations are incidental and non-load-bearing for the core method.
Axiom & Free-Parameter Ledger
invented entities (2)
-
MACF framework
no independent evidence
-
agent-native latent communication protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y ., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y ., Xu, S., Chen, C., Zhu, D., et al. Llava- onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661,
work page internal anchor Pith review arXiv
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The (r) evolution of multimodal large language models: A survey
Caffagni, D., Cocchi, F., Barsellotti, L., Moratelli, N., Sarto, S., Baraldi, L., Cornia, M., and Cucchiara, R. The rev- olution of multimodal large language models: a survey. arXiv preprint arXiv:2402.12451,
-
[5]
Videollm: Modeling video sequence with large language models
Chen, G., Zheng, Y .-D., Wang, J., Xu, J., Huang, Y ., Pan, J., Wang, Y ., Wang, Y ., Qiao, Y ., Lu, T., et al. Videollm: Modeling video sequence with large language models. arXiv preprint arXiv:2305.13292,
-
[6]
Chen, L., Wei, X., Li, J., Dong, X., Zhang, P., Zang, Y ., Chen, Z., Duan, H., Tang, Z., Yuan, L., et al. Sharegpt4video: Improving video understanding and gen- eration with better captions.Advances in Neural Infor- mation Processing Systems, 37:19472–19495, 2024a. Chen, Z., Wang, W., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z...
work page internal anchor Pith review arXiv
-
[7]
9 Submission and Formatting Instructions for ICML 2026 Clark, C., Zhang, J., Ma, Z., Park, J. S., Salehi, M., Tri- pathi, R., Lee, S., Ren, Z., Kim, C. D., Yang, Y ., et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611,
-
[8]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y ., Peng, T., Wu, J., Zhang, X., Wang, B., and Yue, X. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review arXiv
-
[9]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre- trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review arXiv
-
[10]
Cache-to-Cache: Direct Semantic Communication Between Large Language Models
Fu, C., Dai, Y ., Luo, Y ., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y ., Zhang, M., et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 24108–24118, 2025a. Fu, T., Min, Z., Zhang, H., Yan, J., Dai, G., Ouyang, W...
-
[11]
Self-adaptive sampling for accurate video question answering on image text models
Han, W., Chen, H., Kan, M.-Y ., and Poria, S. Self-adaptive sampling for accurate video question answering on image text models. InFindings of the Association for Computa- tional Linguistics: NAACL 2024, pp. 2522–2534,
2024
-
[12]
He, J., Bai, R. H., Williamson, S., Pan, J. Z., Jaitly, N., and Zhang, Y . Clara: Bridging retrieval and genera- tion with continuous latent reasoning.arXiv preprint arXiv:2511.18659,
-
[13]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Kugo, N., Li, X., Li, Z., Gupta, A., Khatua, A., Jain, N., Patel, C., Kyuragi, Y ., Ishii, Y ., Tanabiki, M., et al. Video- multiagents: A multi-agent framework for video question answering.arXiv preprint arXiv:2504.20091,
-
[15]
Liang, J., Meng, X., Wang, Y ., Liu, C., Liu, Q., and Zhao, D. End-to-end video question answering with frame scor- ing mechanisms and adaptive sampling.arXiv preprint arXiv:2407.15047,
-
[16]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee
Liu, J., Wang, Y ., Ma, H., Wu, X., Ma, X., Wei, X., Jiao, J., Wu, E., and Hu, J. Kangaroo: A powerful video- language model supporting long-context video input. arXiv preprint arXiv:2408.15542,
-
[17]
arXiv preprint arXiv:2512.20618 (2025)
Liu, R., Liu, Z., Tang, J., Ma, Y ., Pi, R., Zhang, J., and Chen, Q. Longvideoagent: Multi-agent reasoning with long videos.arXiv preprint arXiv:2512.20618,
-
[18]
Long, L., He, Y ., Ye, W., Pan, Y ., Lin, Y ., Li, H., Zhao, J., and Li, W. Seeing, listening, remembering, and reason- ing: A multimodal agent with long-term memory.arXiv preprint arXiv:2508.09736,
-
[19]
Luo, Y ., Zheng, X., Li, G., Yin, S., Lin, H., Fu, C., Huang, J., Ji, J., Chao, F., Luo, J., et al. Video-rag: Visually-aligned retrieval-augmented long video comprehension.arXiv preprint arXiv:2411.13093,
- [20]
-
[21]
10 Submission and Formatting Instructions for ICML 2026 Pang, Z. and Wang, Y .-X. Mr. video:” mapreduce” is the principle for long video understanding.arXiv preprint arXiv:2504.16082,
-
[22]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Su, Z., Xia, P., Guo, H., Liu, Z., Ma, Y ., Qu, X., Liu, J., Li, Y ., Zeng, K., Yang, Z., et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918,
work page internal anchor Pith review arXiv
-
[23]
URL https: //arxiv.org/abs/2505.09388. Wang, W., He, Z., Hong, W., Cheng, Y ., Zhang, X., Qi, J., Ding, M., Gu, X., Huang, S., Xu, B., et al. Lvbench: An extreme long video understanding benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22958–22967,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Wu, C., Yin, S., Qi, W., Wang, X., Tang, Z., and Duan, N. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671,
work page internal anchor Pith review arXiv
-
[25]
Kwai keye-vl 1.5 technical report.arXiv preprint arXiv:2509.01563, 2025
Wu, H., Li, D., Chen, B., and Li, J. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Process- ing Systems, 37:28828–28857, 2024a. Wu, Q., Bansal, G., Zhang, J., Wu, Y ., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al. Autogen: Enabling next-gen llm applications via mult...
-
[26]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Yang, Z., Li, L., Wang, J., Lin, K., Azarnasab, E., Ahmed, F., Liu, Z., Liu, C., Zeng, M., and Wang, L. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381,
work page internal anchor Pith review arXiv
-
[27]
A survey on agentic multimodal large language models.arXiv preprint arXiv:2510.10991,
Yao, H., Zhang, R., Huang, J., Zhang, J., Wang, Y ., Fang, B., Zhu, R., Jing, Y ., Liu, S., Li, G., et al. A survey on agentic multimodal large language models.arXiv preprint arXiv:2510.10991,
-
[28]
Yu, S., Jin, C., Wang, H., Chen, Z., Jin, S., Zuo, Z., Xu, X., Sun, Z., Zhang, B., Wu, J., et al. Frame-voyager: Learning to query frames for video large language models. arXiv preprint arXiv:2410.03226,
-
[29]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y ., Chen, G., Leng, S., Jiang, Y ., Zhang, H., Li, X., et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025a. Zhang, D., Yu, Y ., Dong, J., Li, C., Su, D., Chu, C., and Yu, D. Mm-llms: Recent advances in multimodal large lan- guage mo...
work page internal anchor Pith review arXiv
-
[30]
Zhang, X., Jia, Z., Guo, Z., Li, J., Li, B., Li, H., and Lu, Y . Deep video discovery: Agentic search with tool use for long-form video understanding.arXiv preprint arXiv:2505.18079, 2025b. Zhang, Y ., Li, B., Liu, h., Lee, Y . j., Gui, L., Fu, D., Feng, J., Liu, Z., and Li, C. Llava-next: A strong zero-shot video understanding model, April 2024b. URL htt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.