Recognition: unknown
CleanBase: Detecting Malicious Documents in RAG Knowledge Databases
Pith reviewed 2026-05-09 19:38 UTC · model grok-4.3
The pith
CleanBase detects malicious documents in RAG knowledge bases by identifying cliques of semantically similar documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
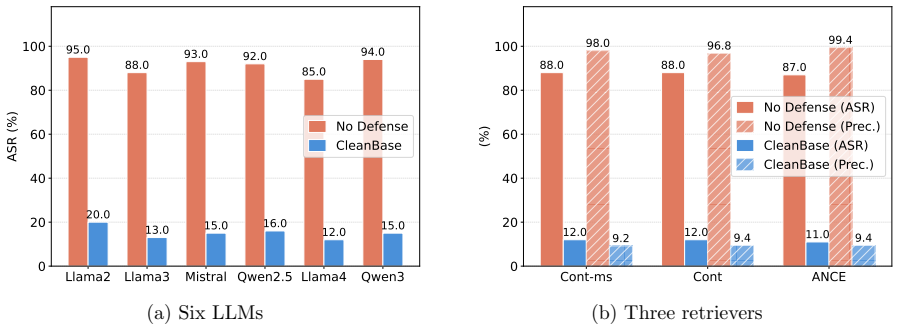
CleanBase constructs a similarity graph over the knowledge database, where each node is a document and an edge exists between two nodes when their semantic similarity, computed by an embedding model, exceeds a statistically determined threshold. Because attackers make malicious documents consistent to raise attack success, those documents form cliques; CleanBase flags the documents in detected cliques as malicious. The method supplies upper bounds on its false-positive and false-negative rates and is shown to work across multiple datasets and prompt-injection attacks.
What carries the argument
A semantic similarity graph whose edges are defined by an embedding-model score above a statistical threshold, with clique detection used to isolate malicious document groups.
If this is right
- RAG systems can remove the flagged documents before any user query reaches them, preserving answer integrity.
- The derived bounds let operators choose a threshold that guarantees an upper limit on error rates.
- The detector works against multiple known prompt-injection techniques without requiring knowledge of the exact injected text.
- It applies to any knowledge base that stores retrievable documents, independent of the underlying language model.
Where Pith is reading between the lines
- The same clique-finding idea could be applied to spot coordinated low-quality or misleading content in other large document collections, such as web indexes or corporate wikis.
- Efficient approximate clique algorithms would be needed for knowledge bases with millions of documents, an aspect left for future scaling work.
- Pairing the similarity-graph step with lightweight content checks could reduce false positives when benign documents happen to cluster by topic.
Load-bearing premise
Malicious documents crafted for the same targeted questions share enough semantic similarity to form cliques that a statistical threshold cleanly separates from the connections among benign documents.
What would settle it
Inserting effective malicious documents that are deliberately written with low mutual semantic similarity for the same questions, or observing large cliques formed only by ordinary benign documents on a real knowledge base, would show whether detection fails or produces excessive false alarms.
Figures




read the original abstract
Retrieval-augmented generation (RAG) is vulnerable to prompt injection attacks, in which an adversary inserts malicious documents containing carefully crafted injected prompts into the knowledge database. When a user issues a question targeted by the attack, the RAG system may retrieve these malicious documents, whose injected prompts mislead it into generating attacker-specified answers, thereby compromising the integrity of the RAG system. In this work, we propose CleanBase, a method to detect malicious documents within a knowledge database. Our key insight is that malicious documents crafted for the same attack-targeted questions often exhibit high semantic similarity, as attackers deliberately make them consistent to improve attack success rates. Accordingly, CleanBase constructs a similarity graph over the knowledge database, where each node represents a document and an edge connects two nodes if their semantic similarity--computed using an embedding model--exceeds a statistically determined threshold. Due to their inherent similarity, malicious documents tend to form cliques within this graph. CleanBase detects such cliques and flags the corresponding documents as malicious. We theoretically derive upper bounds on CleanBase's false positive and false negative rates and empirically validate its effectiveness. Experimental results across multiple datasets and prompt injection attacks demonstrate that CleanBase accurately detects malicious documents and effectively safeguards RAG systems. Our source code is available at https://github.com/WeifeiJin/CleanBase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CleanBase to detect malicious documents inserted into RAG knowledge bases for prompt injection attacks. It constructs a similarity graph over documents using an external embedding model, connects nodes whose similarity exceeds a statistically chosen threshold, and flags documents belonging to cliques as malicious on the grounds that attack documents for the same target are deliberately made semantically consistent. The authors derive theoretical upper bounds on false-positive and false-negative rates and report empirical results across multiple datasets and attack types, with source code released.
Significance. If the central modeling assumption holds, the work supplies a lightweight, attack-agnostic detection layer with explicit error-rate bounds and reproducible code, which would be a useful addition to RAG security tooling. The open-source release is a clear strength that permits independent verification of the empirical claims.
major comments (2)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): The upper bound on the false-positive rate is derived under an implicit model in which benign-document pairwise similarities are low enough or sufficiently independent that they do not exceed the chosen threshold and form cliques. This modeling choice is load-bearing for the claimed guarantees, yet the manuscript provides no justification or sensitivity analysis for the case of realistic corpora that contain large topical clusters of benign documents whose embeddings will exceed the same threshold. Consequently the stated FP bound does not necessarily transfer to the structured knowledge bases the method is intended to protect.
- [§5 (Experimental Evaluation)] §5 (Experimental Evaluation): The reported experiments use standard benchmark corpora but do not include controlled tests on knowledge bases deliberately seeded with topical clusters of benign documents at varying densities. Without such controls it is impossible to confirm that the observed false-positive rates remain within the derived bounds once the benign-similarity assumption is relaxed, leaving the empirical validation incomplete for the central claim.
minor comments (2)
- [§3] The precise statistical procedure used to set the similarity threshold (mentioned in the abstract and §3) should be stated explicitly, including any distributional assumptions or quantile estimation method.
- Figure captions and legends should explicitly indicate the embedding model, the numerical threshold value, and the clique-size parameter used in each plotted result.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where the manuscript can be strengthened regarding the modeling assumptions and empirical validation. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: The upper bound on the false-positive rate is derived under an implicit model in which benign-document pairwise similarities are low enough or sufficiently independent that they do not exceed the chosen threshold and form cliques. This modeling choice is load-bearing for the claimed guarantees, yet the manuscript provides no justification or sensitivity analysis for the case of realistic corpora that contain large topical clusters of benign documents whose embeddings will exceed the same threshold. Consequently the stated FP bound does not necessarily transfer to the structured knowledge bases the method is intended to protect.
Authors: We acknowledge that the false-positive bound relies on the assumption that benign pairwise similarities remain below the threshold with high probability and do not form cliques, which is implicit in the statistical threshold selection and concentration-based analysis in §4. The manuscript does not provide explicit justification or sensitivity analysis for dense topical clusters in benign data. In the revised version we will expand §4 to state this assumption clearly, justify it via typical properties of embedding models on RAG corpora, and add a sensitivity analysis under a clustered similarity model (e.g., mixture of intra- and inter-cluster distributions) to delineate when the bound continues to hold. revision: yes
-
Referee: The reported experiments use standard benchmark corpora but do not include controlled tests on knowledge bases deliberately seeded with topical clusters of benign documents at varying densities. Without such controls it is impossible to confirm that the observed false-positive rates remain within the derived bounds once the benign-similarity assumption is relaxed, leaving the empirical validation incomplete for the central claim.
Authors: We agree that the current experiments on standard benchmarks leave the robustness to benign topical clusters untested. We will add a new controlled experiment subsection in §5 that constructs knowledge bases by seeding documents from the same topic/category at varying densities (10–50 %) while preserving the original attack documents, then reports the resulting false-positive rates and their relation to the theoretical bounds. These results will be included in the revision to complete the empirical validation. revision: yes
Circularity Check
No circularity: bounds derived from external embedding and graph assumptions
full rationale
The paper constructs a similarity graph using an external embedding model, applies a statistically determined threshold, and detects cliques as malicious documents. It claims theoretical upper bounds on FP/FN rates derived from these graph properties. No equations, self-citations, or steps in the abstract reduce the bounds or detection output to a fitted parameter or input by construction. The load-bearing assumption (malicious documents form cliques while benign do not) is an empirical modeling choice, not a self-definitional or self-citation loop. The approach is self-contained against external benchmarks like standard embedding models and clique detection algorithms.
Axiom & Free-Parameter Ledger
free parameters (1)
- similarity threshold
axioms (1)
- domain assumption Malicious documents for the same attack-targeted questions exhibit high semantic similarity and form cliques
Reference graph
Works this paper leans on
-
[1]
Simon Willison , year=
-
[2]
2022 , journal=
Evaluating the Susceptibility of Pre-Trained Language Models via Handcrafted Adversarial Examples , author=. 2022 , journal=
2022
-
[3]
NeurIPS ML Safety Workshop , year =
Perez, Fábio and Ribeiro, Ian , title =. NeurIPS ML Safety Workshop , year =
-
[4]
Journal of machine learning research , volume=
Visualizing data using t-SNE , author=. Journal of machine learning research , volume=
-
[5]
ACM CCS , year=
Secalign: Defending against prompt injection with preference optimization , author=. ACM CCS , year=
-
[6]
USENIX Security Symposium , year=
\ StruQ \ : Defending against prompt injection with structured queries , author=. USENIX Security Symposium , year=
-
[7]
LaMDA: Language Models for Dialog Applications
Lamda: Language models for dialog applications , author=. arXiv preprint arXiv:2201.08239 , year=
-
[8]
International conference on machine learning , year=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , year=
-
[9]
EMNLP , year=
Dense Passage Retrieval for Open-Domain Question Answering , author=. EMNLP , year=
-
[10]
Advances in neural information processing systems , year=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , year=
-
[11]
USENIX Security Symposium , year=
Formalizing and benchmarking prompt injection attacks and defenses , author=. USENIX Security Symposium , year=
-
[12]
ACM workshop on artificial intelligence and security , year=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. ACM workshop on artificial intelligence and security , year=
-
[13]
Transactions of the Association for Computational Linguistics , year=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , year=
-
[15]
Companion proceedings of the the web conference , year=
Www'18 open challenge: financial opinion mining and question answering , author=. Companion proceedings of the the web conference , year=
-
[16]
Annual Meeting of the Association for Computational Linguistics , year=
Retrieval of the best counterargument without prior topic knowledge , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[18]
NAACL-HLT , year =
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit , title =. NAACL-HLT , year =
-
[19]
Communications of the ACM , year=
Algorithm 457: finding all cliques of an undirected graph , author=. Communications of the ACM , year=
-
[21]
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=
-
[25]
See https://vicuna
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
2023
-
[26]
Conference on Empirical Methods in Natural Language Processing , year=
Webinject: Prompt injection attack to web agents , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[28]
ACM Conference on Computer and Communications Security , year=
Optimization-based prompt injection attack to llm-as-a-judge , author=. ACM Conference on Computer and Communications Security , year=
-
[29]
ACM Conference on Computer and Communications Security , year=
Pleak: Prompt leaking attacks against large language model applications , author=. ACM Conference on Computer and Communications Security , year=
-
[30]
USENIX Security Symposium , year=
\ PoisonedRAG \ : Knowledge corruption attacks to \ Retrieval-Augmented \ generation of large language models , author=. USENIX Security Symposium , year=
-
[32]
IEEE Symposium on Security and Privacy (SP) , year=
Poisoning web-scale training datasets is practical , author=. IEEE Symposium on Security and Privacy (SP) , year=
-
[34]
USENIX Security Symposium , year=
Machine Against the \ RAG \ : Jamming \ Retrieval-Augmented \ Generation with Blocker Documents , author=. USENIX Security Symposium , year=
-
[35]
CPA-RAG: Covert poisoning attacks on retrieval- augmented generation in large language models,
CPA-RAG: Covert Poisoning Attacks on Retrieval-Augmented Generation in Large Language Models , author=. arXiv preprint arXiv:2505.19864 , year=
-
[36]
PromptGuard , howpublished =
-
[37]
IEEE Symposium on Security and Privacy , year=
DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks , author=. IEEE Symposium on Security and Privacy , year=
-
[38]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[39]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[40]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[42]
Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples,
Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples , author=. arXiv preprint arXiv:2209.02128 , year=
-
[43]
IEEE transactions on information forensics and security , year=
Sybilbelief: A semi-supervised learning approach for structure-based sybil detection , author=. IEEE transactions on information forensics and security , year=
-
[44]
arXiv e-prints , pages=
Trustrag: Enhancing robustness and trustworthiness in rag , author=. arXiv e-prints , pages=
-
[49]
NDSS , year=
Graph-based security and privacy analytics via collective classification with joint weight learning and propagation , author=. NDSS , year=
-
[50]
Findings of the Association for Computational Linguistics , year=
Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers , author=. Findings of the Association for Computational Linguistics , year=
-
[51]
International workshop on approximation algorithms for combinatorial optimization , pages=
Greedy approximation algorithms for finding dense components in a graph , author=. International workshop on approximation algorithms for combinatorial optimization , pages=. 2000 , organization=
2000
-
[52]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
Gasliteing the retrieval: Exploring vulnerabilities in dense embedding-based search , author=. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
2025
-
[53]
https://huggingface.co/meta-llama/Prompt-Guard-86M, 2024
Promptguard. https://huggingface.co/meta-llama/Prompt-Guard-86M, 2024
2024
-
[54]
The llama 4 herd: The beginning of a new era of natively multimodal intelligence
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal intelligence. Meta AI Blog, 2025. URL https://ai.meta.com/blog/llama-4-multimodal-intelligence/
2025
-
[55]
Gasliteing the retrieval: Exploring vulnerabilities in dense embedding-based search
Matan Ben-Tov and Mahmood Sharif. Gasliteing the retrieval: Exploring vulnerabilities in dense embedding-based search. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 4364--4378, 2025
2025
-
[56]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, 2022
2022
-
[57]
Algorithm 457: finding all cliques of an undirected graph
Coen Bron and Joep Kerbosch. Algorithm 457: finding all cliques of an undirected graph. Communications of the ACM, 1973
1973
-
[58]
Poisoning web-scale training datasets is practical
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tram \`e r. Poisoning web-scale training datasets is practical. In IEEE Symposium on Security and Privacy (SP), 2024
2024
-
[59]
Greedy approximation algorithms for finding dense components in a graph
Moses Charikar. Greedy approximation algorithms for finding dense components in a graph. In International workshop on approximation algorithms for combinatorial optimization, pages 84--95. Springer, 2000
2000
-
[60]
Phantom: General trigger attacks on retrieval augmented language generation,
Harsh Chaudhari, Giorgio Severi, John Abascal, Matthew Jagielski, Christopher A Choquette-Choo, Milad Nasr, Cristina Nita-Rotaru, and Alina Oprea. Phantom: General trigger attacks on retrieval augmented language generation. arXiv preprint arXiv:2405.20485, 2024
-
[61]
\ StruQ \ : Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. \ StruQ \ : Defending against prompt injection with structured queries. In USENIX Security Symposium, 2025 a
2025
-
[62]
Secalign: Defending against prompt injection with preference optimization
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimization. In ACM CCS, 2025 b
2025
-
[63]
Meta secalign: A secure foundation llm against prompt injection attacks,
Sizhe Chen, Arman Zharmagambetov, David Wagner, and Chuan Guo. Meta secalign: A secure foundation llm against prompt injection attacks. arXiv preprint arXiv:2507.02735, 2025 c
-
[64]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
The llama 3 herd of models
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407, 2024
2024
-
[66]
Sybilbelief: A semi-supervised learning approach for structure-based sybil detection
Neil Zhenqiang Gong, Mario Frank, and Prateek Mittal. Sybilbelief: A semi-supervised learning approach for structure-based sybil detection. IEEE transactions on information forensics and security, 2014
2014
-
[67]
Yuyang Gong, Zhuo Chen, Miaokun Chen, Fengchang Yu, Wei Lu, Xiaofeng Wang, Xiaozhong Liu, and Jiawei Liu. Topic-fliprag: Topic-orientated adversarial opinion manipulation attacks to retrieval-augmented generation models. arXiv preprint arXiv:2502.01386, 2025
-
[68]
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In ACM workshop on artificial intelligence and security, 2023
2023
-
[69]
Pleak: Prompt leaking attacks against large language model applications
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, and Yinzhi Cao. Pleak: Prompt leaking attacks against large language model applications. In ACM Conference on Computer and Communications Security, 2024
2024
-
[70]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021
work page internal anchor Pith review arXiv 2021
-
[72]
A critical evaluation of defenses against prompt injection attacks,
Yuqi Jia, Zedian Shao, Yupei Liu, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. A critical evaluation of defenses against prompt injection attacks. arXiv preprint arXiv:2505.18333, 2025
-
[73]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023
2023
-
[74]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In EMNLP, 2020
2020
-
[75]
Natural questions: a benchmark for question answering research
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 2019
2019
-
[76]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 2020
2020
-
[77]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In USENIX Security Symposium, 2024
2024
-
[78]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. In IEEE Symposium on Security and Privacy, 2025
2025
-
[79]
Visualizing data using t-sne
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9 0 (Nov): 0 2579--2605, 2008
2008
-
[80]
Www'18 open challenge: financial opinion mining and question answering
Macedo Maia, Siegfried Handschuh, Andr \'e Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. Www'18 open challenge: financial opinion mining and question answering. In Companion proceedings of the the web conference, 2018
2018
-
[81]
Ignore previous prompt: Attack techniques for language models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. In NeurIPS ML Safety Workshop, 2022
2022
-
[82]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[83]
Machine against the \ RAG \ : Jamming \ Retrieval-Augmented \ generation with blocker documents
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. Machine against the \ RAG \ : Jamming \ Retrieval-Augmented \ generation with blocker documents. In USENIX Security Symposium, 2025
2025
-
[84]
Reliabilityrag: Effective and provably robust defense for rag-based web-search
Zeyu Shen, Basileal Imana, Tong Wu, Chong Xiang, Prateek Mittal, and Aleksandra Korolova. Reliabilityrag: Effective and provably robust defense for rag-based web-search. arXiv preprint arXiv:2509.23519, 2025
-
[85]
Optimization-based prompt injection attack to llm-as-a-judge
Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. Optimization-based prompt injection attack to llm-as-a-judge. In ACM Conference on Computer and Communications Security, 2024
2024
-
[86]
Prompt injection attack to tool selection in llm agents,
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. Prompt injection attack to tool selection in llm agents. arXiv preprint arXiv:2504.19793, 2025
-
[87]
FEVER : a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER : a large-scale dataset for fact extraction and VERification . In NAACL-HLT, 2018
2018
-
[88]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[89]
Retrieval of the best counterargument without prior topic knowledge
Henning Wachsmuth, Shahbaz Syed, and Benno Stein. Retrieval of the best counterargument without prior topic knowledge. In Annual Meeting of the Association for Computational Linguistics, 2018
2018
-
[90]
Fact or fiction: Verifying scientific claims.ArXiv, abs/2004.14974,
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. arXiv preprint arXiv:2004.14974, 2020
-
[91]
Graph-based security and privacy analytics via collective classification with joint weight learning and propagation
Binghui Wang, Jinyuan Jia, and Neil Zhenqiang Gong. Graph-based security and privacy analytics via collective classification with joint weight learning and propagation. In NDSS, 2019
2019
-
[92]
Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers. In Findings of the Association for Computational Linguistics, 2021
2021
-
[93]
Webinject: Prompt injection attack to web agents
Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhenqiang Gong. Webinject: Prompt injection attack to web agents. In Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[94]
Prompt injection attacks against GPT-3
Simon Willison. Prompt injection attacks against GPT-3 . https://simonwillison.net/2022/Sep/12/prompt-injection/, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.