Recognition: unknown
Stereo Multistage Spatial Attention for Real-Time Mobile Manipulation Under Visual Scale Variation and Disturbances
Pith reviewed 2026-05-09 19:19 UTC · model grok-4.3
The pith
Stereo multistage spatial attention with recurrent prediction enables robust closed-loop mobile manipulation despite visual scale changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
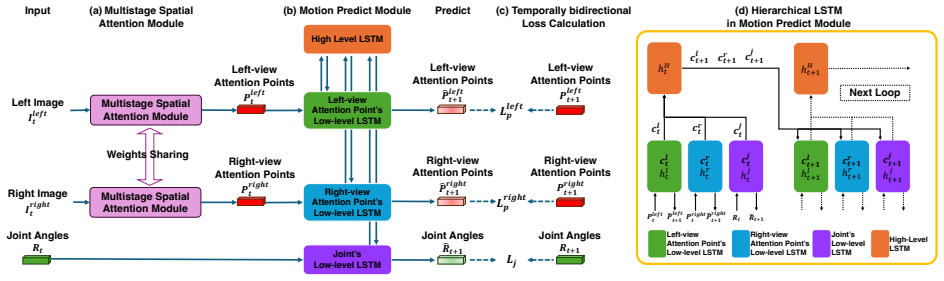
The central claim is that extracting multistage task-relevant spatial attention points from stereo images, then integrating them with robot states inside a hierarchical recurrent architecture, yields accurate closed-loop action predictions that maintain high success rates on mobile manipulation tasks even when initial positions are randomized and visual disturbances are present.
What carries the argument
Stereo multistage spatial attention that identifies task-relevant points from image pairs, passed through a hierarchical recurrent network for temporal action prediction.
If this is right
- Task success rates increase under randomized initial positions and visual disturbances compared with imitation learning and vision-language baselines.
- The same architecture supports rigid placement, articulated object manipulation, and deformable object interaction.
- Real-time closed-loop control remains feasible on a mobile manipulator platform.
- Structured stereo attention plus predictive temporal modeling provides robustness within the tested mobile manipulation scenarios.
Where Pith is reading between the lines
- The method could reduce reliance on precise camera calibration by focusing attention on relative stereo features rather than absolute scale.
- Similar multistage attention might help other closed-loop control problems where viewpoint changes occur, such as navigation or inspection.
- Extending the recurrent hierarchy to longer time horizons could address tasks requiring more steps or recovery from larger errors.
Load-bearing premise
Task-relevant spatial attention points extracted from stereo images can be reliably integrated with robot states via the hierarchical recurrent architecture to produce accurate closed-loop action predictions across varied visual conditions and tasks.
What would settle it
Conducting the four real-world tasks with randomized starts and added visual disturbances and measuring no statistically significant gain in success rate relative to the imitation-learning baseline under identical control settings.
Figures








read the original abstract
Robots operating in open, unstructured real-world environments must rely on onboard visual perception while autonomously moving across different locations. Continuous changes in onboard camera viewpoints cause significant visual scale variations in target objects, affecting vision-based motion generation. In this work, we present a stereo multistage spatial attention-based deep predictive learning method for real-time mobile manipulation. The proposed methods extracts task-relevant spatial attention points from stereo images and integrates them with robot states through a hierarchical recurrent architecture for closed-loop action prediction. We evaluate the system on four real-world mobile manipulation tasks using a mobile manipulator, including rigid placement, articulated object manipulation, and deformable object interaction. Experiments under randomized initial positions and visual disturbance conditions demonstrate improved robustness and task success rates compared to representative imitation learning and vision-language-action baselines under identical control settings. The results indicate that structured stereo spatial attention combined with predictive temporal modeling provides an effective solution within the evaluated mobile manipulation scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a stereo multistage spatial attention-based deep predictive learning method for real-time mobile manipulation. Task-relevant spatial attention points are extracted from stereo images and integrated with robot states via a hierarchical recurrent architecture to enable closed-loop action prediction. The approach is evaluated on four real-world mobile manipulation tasks (rigid placement, articulated object manipulation, and deformable object interaction) using a mobile manipulator, with experiments under randomized initial positions and visual disturbance conditions claiming higher task success rates and robustness than representative imitation learning and vision-language-action baselines under identical control settings.
Significance. If the reported experimental gains hold under scrutiny, the work offers a practical demonstration that structured stereo spatial attention combined with predictive temporal modeling can address visual scale variation and disturbances in onboard-camera mobile manipulation. The real-world validation across multiple task types with baseline comparisons under randomized conditions provides concrete evidence of improved closed-loop performance, which could inform designs for robust vision-based policies in unstructured environments.
minor comments (2)
- [Abstract] Abstract: the claim of 'improved robustness and task success rates' is stated without any quantitative metrics, error bars, statistical tests, or numerical comparisons, which limits immediate assessment of the magnitude and reliability of the gains.
- [Method] The description of multistage spatial attention extraction from stereo images and its precise fusion into the hierarchical recurrent policy lacks sufficient implementation-level detail (e.g., attention point selection criteria, dimensionality of the fused state, or training procedure) to support full reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on stereo multistage spatial attention for real-time mobile manipulation, the recognition of its significance in addressing visual scale variation and disturbances, and the recommendation for minor revision. We appreciate the acknowledgment of the real-world experiments across multiple tasks with baseline comparisons.
Circularity Check
No significant circularity
full rationale
The paper is an empirical robotics contribution that proposes a stereo multistage spatial attention architecture integrated with a hierarchical recurrent policy for mobile manipulation. Its central claims rest on real-world task success rates measured against external imitation learning and VLA baselines under randomized initial conditions and visual disturbances. No equations, derivations, or parameter-fitting steps are described that would reduce reported performance gains to quantities defined by construction within the paper itself. The method is presented as a design choice evaluated experimentally rather than derived from self-referential premises or self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ international con- ference on intelligent robots and systems (IROS). IEEE, 2017, pp. 23–30
2017
-
[2]
Learning generalizable manip- ulation policies with object-centric 3d representations,
Y . Zhu, Z. Jiang, P. Stone, and Y . Zhu, “Learning generalizable manip- ulation policies with object-centric 3d representations,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, vol. 229. PMLR, 2023, pp. 3418–3433
2023
-
[3]
Distinctive image features from scale-invariant key- points,
D. G. Lowe, “Distinctive image features from scale-invariant key- points,”International journal of computer vision, vol. 60, pp. 91–110, 2004
2004
-
[4]
Artag, a fiducial marker system using digital techniques,
M. Fiala, “Artag, a fiducial marker system using digital techniques,” in2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2. IEEE, 2005, pp. 590–596
2005
-
[5]
Apriltag 2: Efficient and robust fiducial detection,
J. Wang and E. Olson, “Apriltag 2: Efficient and robust fiducial detection,” in2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 4193–4198
2016
-
[6]
Deep learning for detecting robotic grasps,
I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,”The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 705–724, 2015
2015
-
[7]
Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection,
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection,”The International journal of robotics research, vol. 37, no. 4-5, pp. 421–436, 2018
2018
-
[8]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” inConference on robot learning. PMLR, 2020, pp. 1094–1100
2020
-
[9]
Learning dexterous in-hand manipulation,
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. Mc- Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Rayet al., “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020
2020
-
[10]
Deep predictive learning: Motion learning concept inspired by cognitive robotics,
K. Suzuki, H. Ito, T. Yamada, K. Kase, and T. Ogata, “Deep predictive learning: Motion learning concept inspired by cognitive robotics,” arXiv preprint arXiv:2306.14714, 2023
-
[11]
Repeatable folding task by humanoid robot worker using deep learning,
P.-C. Yang, K. Sasaki, K. Suzuki, K. Kase, S. Sugano, and T. Ogata, “Repeatable folding task by humanoid robot worker using deep learning,”IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 397–403, 2016
2016
-
[12]
Efficient multitask learning with an embodied predictive model for door opening and entry with whole-body control,
H. Ito, K. Yamamoto, H. Mori, and T. Ogata, “Efficient multitask learning with an embodied predictive model for door opening and entry with whole-body control,”Science Robotics, vol. 7, no. 65, p. eaax8177, 2022
2022
-
[13]
Contact- rich manipulation of a flexible object based on deep predictive learning using vision and tactility,
H. Ichiwara, H. Ito, K. Yamamoto, H. Mori, and T. Ogata, “Contact- rich manipulation of a flexible object based on deep predictive learning using vision and tactility,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 5375–5381
2022
-
[14]
Spatial attention point network for deep-learning-based robust autonomous robot motion generation,
——, “Spatial attention point network for deep-learning-based robust autonomous robot motion generation,”arXiv preprint arXiv:2103.01598, 2021
-
[15]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[16]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[17]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafiotiet al., “Smolvla: A vision-language-action model for affordable and efficient robotics,”arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571
2011
-
[20]
Kinematically-decoupled impedance control for fast object visual servoing and grasping on quadruped manipulators,
R. Parosi, M. Risiglione, D. G. Caldwell, C. Semini, and V . Barasuol, “Kinematically-decoupled impedance control for fast object visual servoing and grasping on quadruped manipulators,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 1–8
2023
-
[21]
Visual servoing architecture of mobile manipulators for precise industrial operations on moving objects,
J. Gonz ´alez Huarte and A. Ibarguren, “Visual servoing architecture of mobile manipulators for precise industrial operations on moving objects,”Robotics, vol. 13, no. 5, p. 71, 2024
2024
-
[22]
Deep rl at scale: Sorting waste in office buildings with a fleet of mobile manipulators,
A. Herzog, K. Rao, K. Hausman, Y . Lu, P. Wohlhart, M. Yan, J. Lin, M. Gonzalez Arenas, T. Xiao, D. Kappleret al., “Deep rl at scale: Sorting waste in office buildings with a fleet of mobile manipulators,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[23]
Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,
J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg, “Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,” inProceedings of Robotics: Science and Systems (RSS), 2017
2017
-
[24]
A theory of cortical responses,
K. Friston, “A theory of cortical responses,”Philosophical transactions of the Royal Society B: Biological sciences, vol. 360, no. 1456, pp. 815–836, 2005
2005
-
[25]
How to select and use tools?: Active perception of target objects using multimodal deep learning,
N. Saito, T. Ogata, S. Funabashi, H. Mori, and S. Sugano, “How to select and use tools?: Active perception of target objects using multimodal deep learning,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2517–2524, 2021
2021
-
[26]
Deep active visual atten- tion for real-time robot motion generation: Emergence of tool-body assimilation and adaptive tool-use,
H. Hiruma, H. Ito, H. Mori, and T. Ogata, “Deep active visual atten- tion for real-time robot motion generation: Emergence of tool-body assimilation and adaptive tool-use,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 8550–8557, 2022
2022
-
[27]
Keypose: Multi-view 3d labeling and keypoint estimation for transparent ob- jects,
X. Liu, R. Jonschkowski, A. Angelova, and K. Konolige, “Keypose: Multi-view 3d labeling and keypoint estimation for transparent ob- jects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 602–11 610
2020
-
[28]
3d space perception via disparity learning using stereo images and an attention mechanism: Real-time grasping motion generation for transparent objects,
X. Cai, H. Ito, H. Hiruma, and T. Ogata, “3d space perception via disparity learning using stereo images and an attention mechanism: Real-time grasping motion generation for transparent objects,”IEEE Robotics and Automation Letters, 2024
2024
-
[29]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[30]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024
2024
-
[31]
Dense monocular depth estimation for stereoscopic vision based on pyramid transformer and multi-scale feature fusion,
Z. Xia, T. Wu, Z. Wang, M. Zhou, B. Wu, C. Chan, and L. B. Kong, “Dense monocular depth estimation for stereoscopic vision based on pyramid transformer and multi-scale feature fusion,”Scientific Reports, vol. 14, no. 1, p. 7037, 2024
2024
-
[32]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.