Recognition: unknown
Q-ARE: An Evaluation Dataset for Query Based API Recommendation
Pith reviewed 2026-05-09 18:58 UTC · model grok-4.3
The pith
Q-ARE dataset shows API recommenders and LLMs weaken on deep, low-density invocation chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
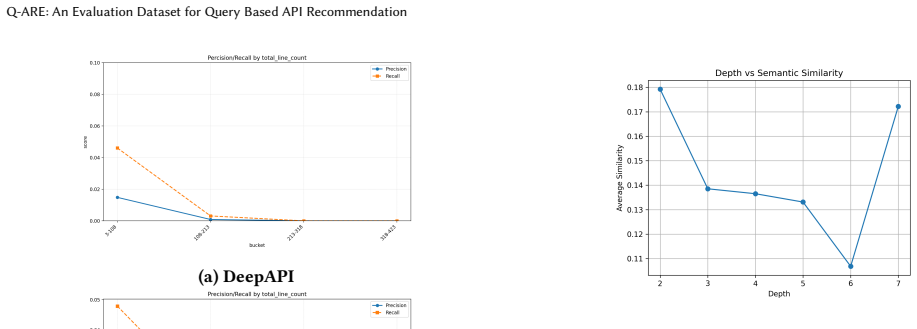
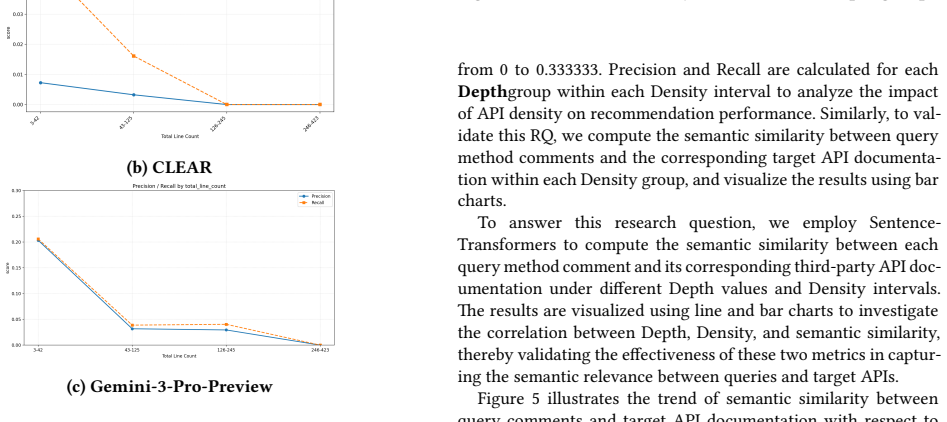
Q-ARE is built by extracting methods from open-source Java projects, analyzing their invocation chains, and recursively expanding those chains to unify all third-party APIs invoked at any level into single target sets for each query. The authors define API Call Depth as the distance in the call hierarchy from the query method to a target API and Invocation Density as the proportion of code lines in the chain tied to the target API. When several query-based recommendation methods and large language models are evaluated on the resulting dataset, their performance declines sharply with greater call depth and lower invocation density, showing that current approaches still have trouble with multi
What carries the argument
The Q-ARE dataset formed by recursive expansion of method invocation chains from GitHub Java projects, together with the two metrics API Call Depth and Invocation Density that measure the structural complexity of those chains.
If this is right
- Query-based API recommendation methods must incorporate handling of indirect, multi-level invocations to remain useful in realistic codebases.
- Large language models exhibit the same performance degradation on deep call structures as traditional specialized recommenders.
- Q-ARE provides a concrete benchmark that future algorithms can use to measure progress on hierarchical API usage.
- Developers working with complex Java libraries will continue to receive incomplete or irrelevant suggestions until depth and density are addressed.
Where Pith is reading between the lines
- Recommendation engines could add static call-graph traversal as a post-processing step to surface indirectly invoked APIs that current query matching misses.
- The recursive chain-expansion technique used to build Q-ARE could be applied to other languages or to web-service APIs to create comparable test collections.
- Training data that explicitly labels APIs by their depth and density in call chains might help models learn to prioritize the most relevant ones.
- A side-by-side comparison of Q-ARE targets against APIs actually chosen by human developers for the same tasks would test whether the automatic targets match real intent.
Load-bearing premise
The target API sets created by recursively expanding invocation chains from GitHub projects accurately reflect the semantic requirements a developer would state in a natural-language query.
What would settle it
A controlled test in which the same functional task is expressed once as a query and once as code with systematically varied call depths, showing no drop in recommendation accuracy as depth increases.
Figures




read the original abstract
As software systems grow in scale, developers face increasing difficulty in selecting appropriate Application Programming Interfaces (APIs) from numerous options. Efficiently identifying APIs that satisfy functional requirements has become a key challenge. To evaluate the semantic understanding of existing query-based API recommendation methods, this paper constructs Q-ARE (Query-based API Recommendation Evaluation), a dataset based on open-source Java projects from GitHub. Methods and their invocation chains are analyzed to identify third-party APIs directly or indirectly invoked by target methods, recursively expanding multi-level invocations to unify hierarchical call structures into API recommendation target sets. Furthermore, we introduce two metrics: API Call Depth, measuring the invocation distance between a query method and a target API, and Invocation Density, quantifying the proportion of code lines associated with the target API in the invocation chain. Based on Q-ARE, we systematically evaluate several query-based API recommendation methods and general Large Language Models (LLMs). Results show that performance drops significantly as API Call Depth increases and invocation density decreases, indicating that existing methods still struggle with multi-level method invocation structures. Q-ARE and its metrics provide a new benchmark for assessing semantic understanding in API recommendation and offer insights for improving future algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Q-ARE, a new evaluation dataset for query-based API recommendation constructed from GitHub Java projects. Target sets are formed by recursively expanding invocation chains of methods to include directly and indirectly invoked third-party APIs. New metrics API Call Depth and Invocation Density are introduced to characterize the complexity of these chains. Evaluations of existing recommendation methods and LLMs on Q-ARE demonstrate significant performance degradation with increasing call depth and decreasing density, suggesting limitations in handling multi-level invocations.
Significance. Should the target sets prove to align with genuine developer query intents, the dataset would provide an important benchmark for testing semantic understanding in API recommendation, highlighting areas where current methods and LLMs fall short on complex code structures. The metrics offer quantifiable ways to assess invocation complexity, which could drive targeted improvements in the field.
major comments (2)
- [§3] §3 (Dataset Construction): The recursive expansion of invocation chains to form target sets includes all third-party APIs appearing anywhere in the chain without any described validation step (e.g., manual audit, developer ratings, or usage-log comparison) to confirm semantic alignment with the natural-language query. This assumption is load-bearing for the central claim that performance drops indicate struggles with semantic understanding of multi-level structures rather than inclusion of incidental APIs.
- [§5] §5 (Evaluation): The reported performance drops as API Call Depth increases and Invocation Density decreases are presented at a high level with no error analysis, failure-mode breakdown, or qualitative examples of queries where targets include non-intended APIs. This makes it difficult to attribute the drops specifically to limitations in semantic handling of hierarchical invocations.
minor comments (1)
- The abstract and construction description would benefit from a concrete example showing a sample query, its target method, and the resulting recursively expanded target set to illustrate the unification process.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the opportunity to address the concerns raised regarding dataset construction and evaluation. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The recursive expansion of invocation chains to form target sets includes all third-party APIs appearing anywhere in the chain without any described validation step (e.g., manual audit, developer ratings, or usage-log comparison) to confirm semantic alignment with the natural-language query. This assumption is load-bearing for the central claim that performance drops indicate struggles with semantic understanding of multi-level structures rather than inclusion of incidental APIs.
Authors: The Q-ARE dataset is constructed by extracting invocation chains directly from real GitHub Java projects, where the target APIs are those actually invoked by the methods associated with each query. This data-driven approach grounds the targets in observable code behavior rather than curated intent. We acknowledge that the manuscript does not describe an explicit validation step such as manual audit, and that incidental APIs could be included in longer chains. In the revised manuscript we will add a dedicated subsection in §3 discussing this assumption, its implications for the central claims, and illustrative examples of chain expansion to clarify semantic alignment where possible. revision: partial
-
Referee: [§5] §5 (Evaluation): The reported performance drops as API Call Depth increases and Invocation Density decreases are presented at a high level with no error analysis, failure-mode breakdown, or qualitative examples of queries where targets include non-intended APIs. This makes it difficult to attribute the drops specifically to limitations in semantic handling of hierarchical invocations.
Authors: We agree that the current evaluation would be strengthened by more granular analysis. In the revised manuscript we will expand §5 to include error analysis across methods and LLMs, a breakdown of failure modes stratified by call depth and density, and qualitative examples of queries (including cases where target sets may contain APIs that are not the most direct match for the query). These additions will better support attribution of performance degradation to challenges with multi-level invocation structures. revision: yes
Circularity Check
No circularity: dataset construction and empirical evaluation are self-contained
full rationale
The paper describes construction of Q-ARE by extracting methods and recursively collecting third-party APIs from their invocation chains in GitHub Java projects, followed by evaluation of existing API recommendation methods and LLMs using two new metrics (API Call Depth, Invocation Density). No equations, parameter fitting, predictions derived from fits, or load-bearing self-citations appear in the provided text. The central claim (performance drop with increasing depth and decreasing density) is an empirical observation on the constructed dataset rather than a derivation that reduces to its own inputs by construction. The work is therefore independent of the circularity patterns listed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recursive expansion of multi-level method invocations produces accurate and complete sets of third-party APIs that satisfy the functional requirements implied by a query method.
Reference graph
Works this paper leans on
-
[1]
Chi Chen, Xin Peng, Zhenchang Xing, Jun Sun, Xin Wang, Yifan Zhao, and Wenyun Zhao. 2021. Holistic combination of structural and textual code infor- mation for context based API recommendation. IEEE Transactions on Software Engineering 48, 8 (2021), 2987–3009
2021
-
[2]
Yujia Chen, Cuiyun Gao, Muyijie Zhu, Qing Liao, Yong Wang, and Guoai Xu
-
[3]
In 2024 IEEE Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER)
APIGen: Generative API method recommendation. In 2024 IEEE Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER) . IEEE, 171–182
2024
-
[4]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages. In Findings of the association for computational linguistics: EMNLP 2020 . 1536–1547
2020
-
[5]
Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. In Proceedings of the 40th international conference on software engineering. 933–944
2018
-
[6]
Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2016. Deep API learning. In Proceedings of the 2016 24th ACM SIGSOFT international sympo- sium on foundations of software engineering . 631–642
2016
-
[7]
Qiao Huang, Xin Xia, Zhenchang Xing, David Lo, and Xinyu Wang. 2018. API method recommendation without worrying about the task-API knowledge gap. Wu et al. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Soft- ware Engineering. 293–304
2018
-
[8]
Ivana Clairine Irsan, Ting Zhang, Ferdian Thung, Kisub Kim, and David Lo. 2023. Picaso: enhancing api recommendations with relevant stack overflow posts. In 2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR). IEEE, 92–103
2023
-
[9]
Yuning Kang, Zan Wang, Hongyu Zhang, Junjie Chen, and Hanmo You. 2021. Apirecx: Cross-library api recommendation via pre-trained language model. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 3425–3436
2021
- [10]
-
[11]
Chun-Yang Ling, Yan-Zhen Zou, Ze-Qi Lin, and Bing Xie. 2019. Graph embed- ding based API graph search and recommendation. Journal of Computer Science and Technology 34, 5 (2019), 993–1006
2019
-
[12]
Jiaxin Liu, Yating Zhang, Deze Wang, Yiwei Li, and Wei Dong. 2025. THINK: Tackling API Hallucinations in LLMs via Injecting Knowledge. In2025 IEEE Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER) . IEEE, 229–240
2025
- [13]
-
[14]
Yun Peng, Shuqing Li, Wenwei Gu, Yichen Li, Wenxuan Wang, Cuiyun Gao, and Michael R Lyu. 2022. Revisiting, benchmarking and exploring API recommen- dation: How far are we? IEEE Transactions on Software Engineering 49, 4 (2022), 1876–1897
2022
-
[15]
Mohammad Masudur Rahman, Chanchal K Roy, and David Lo. 2016. Rack: Automatic api recommendation using crowdsourced knowledge. In 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Vol. 1. IEEE, 349–359
2016
-
[16]
Shanghai AI Lab. 2024. OpenCompass. Retrieved March 12, 2026 from https: //rank.opencompass.org.cn/home AI
2024
-
[17]
Yewei Song, Xunzhu Tang, Cedric Lothritz, Saad Ezzini, Jacques Klein, Tegawendé Bissyande, Andrey Boytsov, Ulrick Ble, and Anne Goujon. 2025. Callnavi, a challenge and empirical study on llm function calling and routing. In Proceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering. 114–125
2025
-
[18]
Chaozheng Wang, Shuzheng Gao, Cuiyun Gao, Wenxuan Wang, Chun Yong Chong, Shan Gao, and Michael R Lyu. 2024. A systematic evaluation of large code models in api suggestion: When, which, and how. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering . 281– 293
2024
-
[19]
Ying Wang, Bihuan Chen, Kaifeng Huang, Bowen Shi, Congying Xu, Xin Peng, Yijian Wu, and Yang Liu. 2020. An empirical study of usages, updates and risks of third-party libraries in java projects. In 2020 IEEE International conference on software maintenance and evolution (ICSME) . IEEE, 35–45
2020
-
[20]
Moshi Wei, Nima Shiri Harzevili, Yuchao Huang, Junjie Wang, and Song Wang
-
[21]
In Proceedings of the 44th International Conference on Software Engineering
Clear: contrastive learning for api recommendation. In Proceedings of the 44th International Conference on Software Engineering . 376–387
-
[22]
Yu Zhou, Xinying Yang, Taolue Chen, Zhiqiu Huang, Xiaoxing Ma, and Harald Gall. 2021. Boosting API recommendation with implicit feedback. IEEE Trans- actions on Software Engineering 48, 6 (2021), 2157–2172
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.